提速的Hash表
Hash表(也叫Hash函数)是一种的数据结构。它是加速算法里最常见的工具。在一些场景下,用这个数据结构可以提速。
如果说 O (log N )已经很不错了,但你学习 哈希表 这种结构后,你会发现它可以在 O(1)时间内查找数据、O(1)时间内插入数据。这个速度,基本上很难超越了。
学习哈希表的工作原理和适用场景后,你可以在许多地方发挥它的速度优势。如果你要构建高效的软件,Hash是不可避免的。
Hash表的起源
哈希表(Hash table,也被译为散列表)是计算机科学中最重要,也是最常用的数据结构之一,它的提出是为了解决“查找问题”。所谓查找问题,就是从一堆数据里面,查询某个特定数据是否存在;如果它存在的话,它是否关联某一个特定的值。在计算机应用中,查找问题无处不在,毫不夸张地讲,我们手机、电脑上所有常用的软件,每次使用都会涉及各种各样的查找。这里很多是程序内部数据的查找,也有许多和用户直接相关,譬如在微信中根据微信号查找好友,银行App中根据用户id找到其账户余额,浏览器中查找某个页面的资源是否被缓存,等等。
那计算机系统是如何实现查找的呢?与我们人类在图书馆里找书、在快递货架上找快递的方式一样,计算机实现查找的最简单方法,其实就是挨个找:从数据开始的地方,一直查到数据结束的地方,逐个对比,看看它是不是想找的那个。当数据不多的时候,这样挨个查找没什么问题,甚至还挺快的,我们在生活中也常常这样找东西。但是当数据量很大时,这样进行遍历查找的效率就不高了。试想,我们要从一个巨大且无序的放着100万件快递的仓库里面,一件一件地找到自己的那一件,势必如大海捞针。对计算机而言也是一样的,纵使现代计算机的速度非常快,但是当数据量较大时,这样的线性查找过程很可能会成为整个程序的性能瓶颈。哈希表的提出,就是为了计算机中能够更高效地进行查找,相比上述的线性查找(或者称为挨个遍历),使用哈希表查找,可是快得多得多。事实上,使用哈希表可以在常数时间内完成查找。所谓常数时间,是指查找时间不随数据量变大而变大——哪怕数据量变得很大,查找也能快速地完成。
哈希表最早由IBM工程师汉斯·彼得·卢恩(Hans Peter Luhn)发明。卢恩于1896年出生于德国巴门,早年在印刷业和纺织业工作,他学识渊博、热爱发明,对登山、美食、风景画都颇为在行。20世纪30年代,卢恩已拥有众多专利,包括一件可折叠雨衣,以及“鸡尾酒神谕”(一种可以告诉用户用现有原料可以调制哪些饮品的指南)。卢恩尤其对文本信息的存储、通信和检索感兴趣,他最终加入IBM从事相关研究。1950年代,计算机技术正蓬勃发展,计算机处理的数据量也越来越大,线性的搜索方法已经不再适用于巨大的数据量。1953年1月,卢恩撰写了一份 IBM 内部备忘录,其中使用了链式的哈希方法来进行更高效的数据检索,这就是如今哈希表的原型。
总结:Hash Table的发明就是为了解决大数量下的查找速度慢问题。
Hash表的别名
- 这样的表又称为字典(dictionary)
- 关联数组(associative array)
- Map
- Hash Map
The working principle
插入操作
先做一个字母和数字的映射表:
A=1
B=2
C=3
D=4
E=5
......
基于这个字母和数字的映射表,设计一个简单的Hash函数,我们使用求积的方式:
- BAD 变成 214.
- 计算各位数字的积, 214 = 8
现实的hash函数要复杂很多,上面我们只是教学用。
注意:hash函数必须要满足对同样字符串使用hash函数得到的值必须永远相同:

插入的过程:

查找操作
Hash表的查找原理

hash表只能单向查找

解决键冲突问题
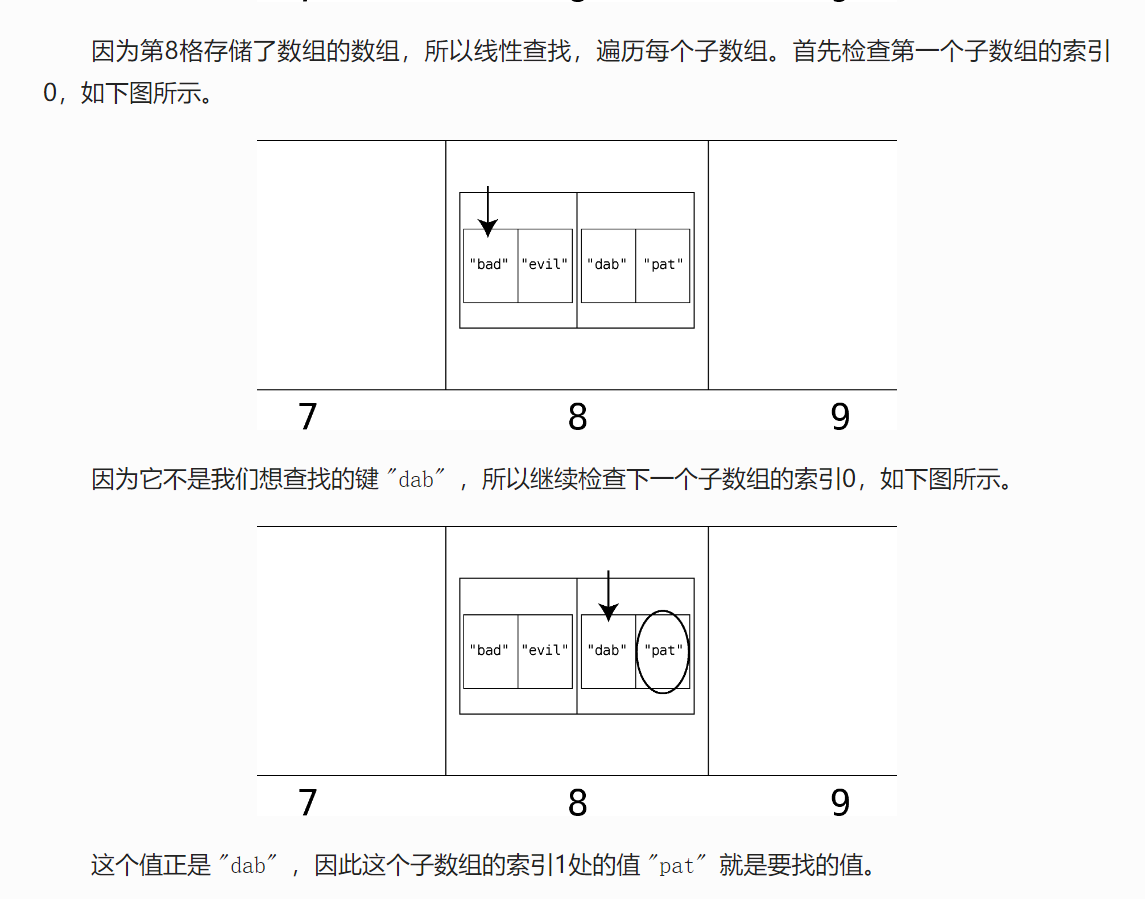
有一个问题,上面的Hash函数,DAB也会转换为8。这里有一个巨大的问题,
另外插入一个问题,hash表,把键存在哪里?
不同语言有不同的设计。....
现在回答一下,bad和dab两个hash值重复,该怎么解决?
- 了解拉链法

遍历的时候:
Hash表 的本质其实就是利用空间对冲时间。
通过建立一个很大的表,那么大的表,索引很关键,表的索引是用数学方式计算出来。
Hash的应用场景
-
数据本身就是成对的,非常适合用Hash
- 菜单中的菜品和价格
- 积分表
- 候选人和得票数
- ...
-
简化逻辑

-
对象的属性

-
快速查找场景

-
去重场景
Hash的键有重复项不能存入,达到去重的效果;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号