利用python爬取深圳证券交易所财报
开始爬取前需要安装一下 pandas 和 request 库,我用的是 pip 安装。代码如下:
pip install pandas pip install requests
安装完成后就要正式开始爬取数据了。
打开深圳证券交易所官网:
http://www.szse.cn/
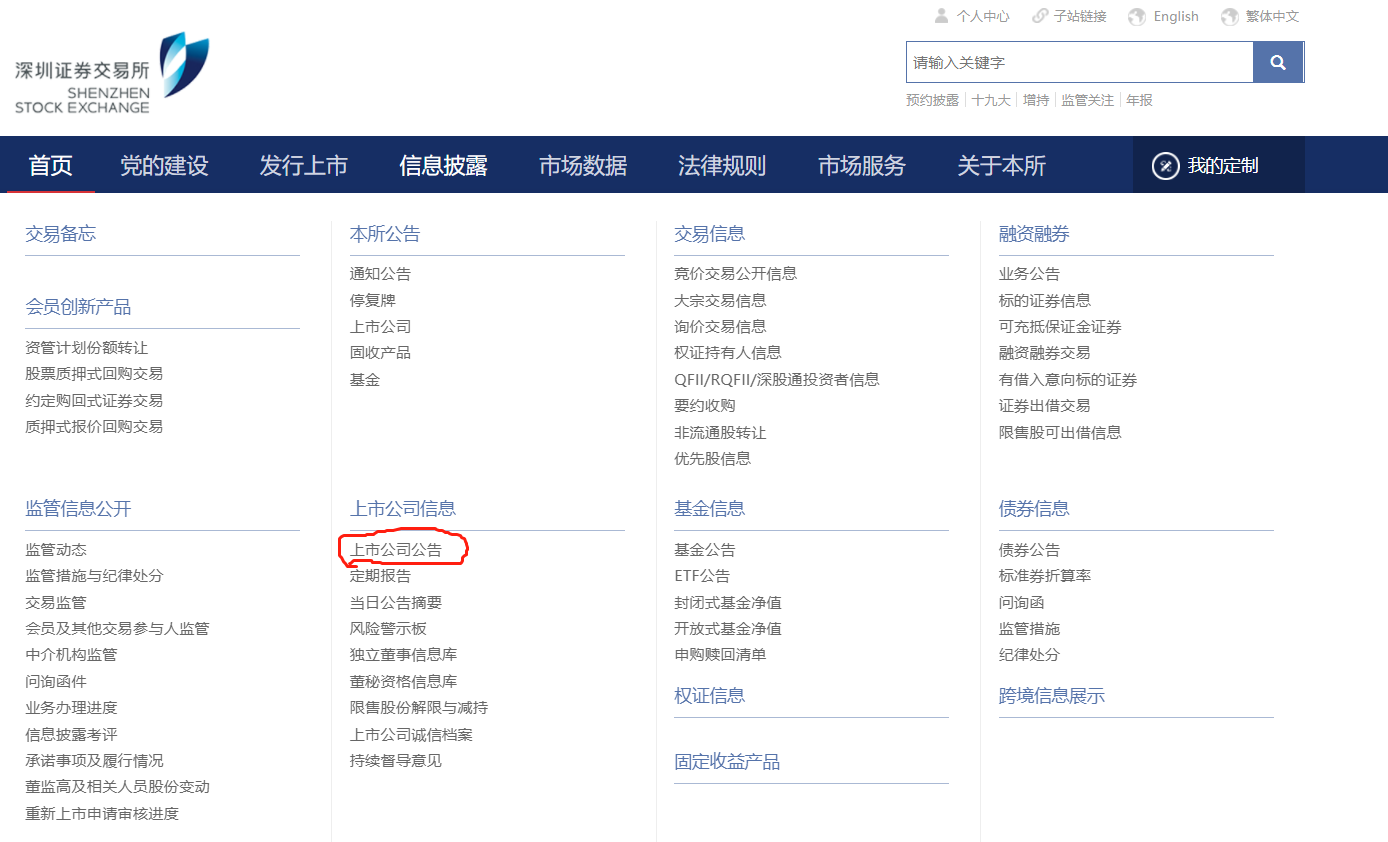
在信息披露->上市公司信息->上市公司公告这里可以找到所有上市公司的财报,也可以加上一些筛选条件,比如我这次爬取的就是2020.1.1-2020.12.31日之间的所有半年报。按F12打开开发者调试工具(我用的是chrome)。输入筛选条件。
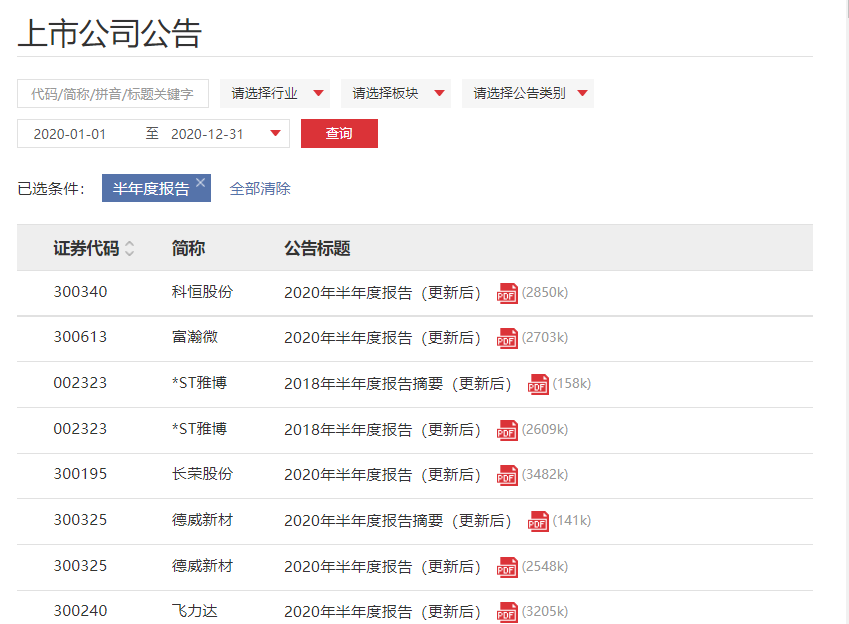
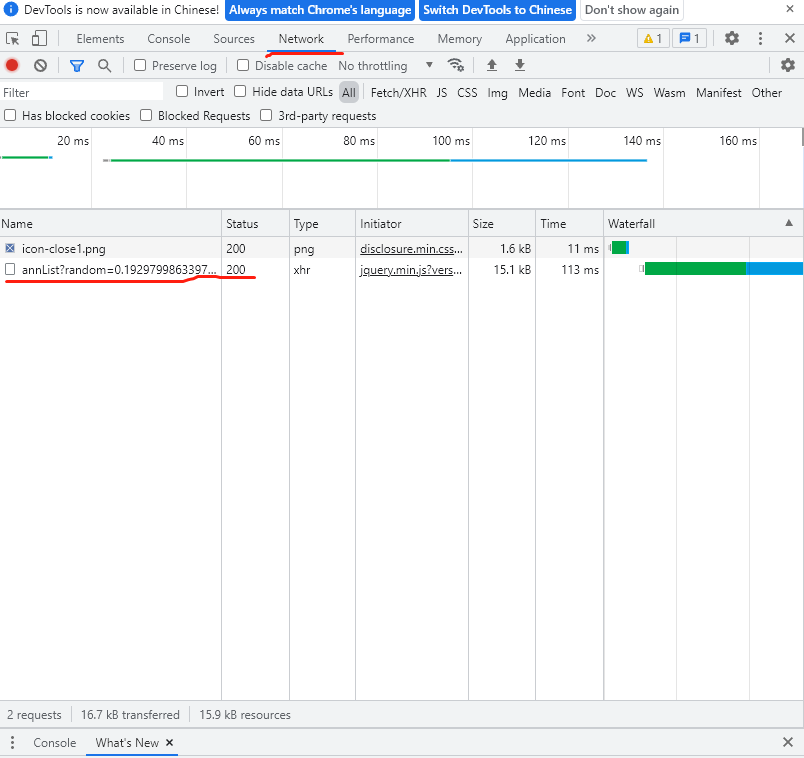
点查询后就可以看到浏览器向服务器发送的请求了,点开红线画出来的地方,如下。可以看到浏览器请求了一个Payload,里面有seDate等内容,多尝试几次可以发现一些规律。seDate里就是筛选的时间范围,bigCategoryId里面就是筛选的类别,可以是年度报告,季度报告等等。半年财报就是‘010303’。随便找到一个财报下载下来,可以在开发者调试工具里看到下载的链接,多找几个数据就可以发现他们有一个共同的头:‘http://disc.static.szse.cn/download/’。


接下来只需要简简单单的写一个程序就好了。
# 定义爬取函数,参数为爬取第几页数据
def get_pdf_address(pageNum):
url = 'http://www.szse.cn/api/disc/announcement/annList?random=%s' % random.random()
#headers= {'User-Agent':str(UserAgent().random)}
headers = {'Accept': 'application/json, text/javascript, */*; q=0.01'
,'Accept-Encoding': 'gzip, deflate'
,'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8'
,'Content-Type': 'application/json'
,'Host': 'www.szse.cn'
,'Origin': 'http://www.szse.cn'
,'Proxy-Connection': 'close'
,'Referer': 'http://www.szse.cn/disclosure/listed/fixed/index.html'
,'User-Agent': 'Mozilla/5.0(Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/74.0.3729.169 Safari/537.36'
,'X-Request-Type': 'ajax'
,'X-Requested-With': 'XMLHttpRequest'}
pagenum = int(pageNum)
payload = {"seDate":["2020-01-01","2020-12-31"],"channelCode":["fixed_disc"],"bigCategoryId":["010303"],"pageSize":30,"pageNum":pagenum}
response = requests.post(url,headers =headers,data = json.dumps(payload)) #使用json格式
result = response.json()
return result
具体爬取下来的内容可以尝试打印出来,这里就不放图了。我们需要把获得的数据整理一下,我用了pandas库,它可以直接写到excel里面,很方便。调用at()方法可以往里面加数据。这样我们就可以把股票代码,名称,下载链接等数据整理出来保存在excel里了。直接上完整版的代码。
'''
爬取深圳证券交易所财报地址
每一页有30个财报
每10页手动保存一次,防止被发现
'''
import requests
import time
import pandas as pd
import random
import os
import json
# 定义爬取函数
def get_pdf_address(pageNum):
url = 'http://www.szse.cn/api/disc/announcement/annList?random=%s' % random.random()
#headers= {'User-Agent':str(UserAgent().random)}
headers = {'Accept': 'application/json, text/javascript, */*; q=0.01'
,'Accept-Encoding': 'gzip, deflate'
,'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8'
,'Content-Type': 'application/json'
,'Host': 'www.szse.cn'
,'Origin': 'http://www.szse.cn'
,'Proxy-Connection': 'close'
,'Referer': 'http://www.szse.cn/disclosure/listed/fixed/index.html'
,'User-Agent': 'Mozilla/5.0(Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/74.0.3729.169 Safari/537.36'
,'X-Request-Type': 'ajax'
,'X-Requested-With': 'XMLHttpRequest'}
pagenum = int(pageNum)
payload = {"seDate":["2020-01-01","2020-12-31"],"channelCode":["fixed_disc"],"bigCategoryId":["010303"],"pageSize":30,"pageNum":pagenum}
response = requests.post(url,headers =headers,data = json.dumps(payload)) #使用json格式
result = response.json()
return result
#创建一个DataFrame储存爬取信息
pdf_infor= pd.DataFrame(columns =['secCode','secName','url','title','publishTime'])
# 下载域名的前缀
count = 0
url_head ='http://disc.static.szse.cn/download/'
#起始页数时page_a,我一次只爬了10页,所以截至页数是page_b = page_a + 10
page_a = 150
page_b = page_a + 10
path_xlsx = 'download_url_' + str(page_a) + '_' + str(page_b-1) + '.xlsx' #保存为excel的文件名
for i in range(page_a,page_b):
print("爬取深交所年报下载地址第{}页".format(i))
result = get_pdf_address(i)
num = len(result['data'])
for each in range(num):
#each = 1
pdf_infor.at[count,'secCode'] = result['data'][each]['secCode'][0]
pdf_infor.at[count,'secName'] = result['data'][each]['secName'][0]
pdf_infor.at[count,'url'] = url_head + result['data'][each]['attachPath']
pdf_infor.at[count,'title'] = result['data'][each]['title']
pdf_infor.at[count,'publishTime'] = result['data'][each]['publishTime']
count += 1
print('获取完成')
time.sleep(random.uniform(2,3)) #控制访问速度
# 提取title中字符串获取年份
pdf_infor['Year'] = pdf_infor['title'].str.extract('([0-9]{4})')
pdf_infor.to_excel(path_xlsx) #保存为excel
手动改一改page_a的值就可以得到所有的urli链接了,当然也可以写一个循环自动去十页十页的爬。我分开处理是为了防止出现问题,方便调试。在爬取url链接的时候还是很顺利的,服务器一次也没有拒绝我的请求。
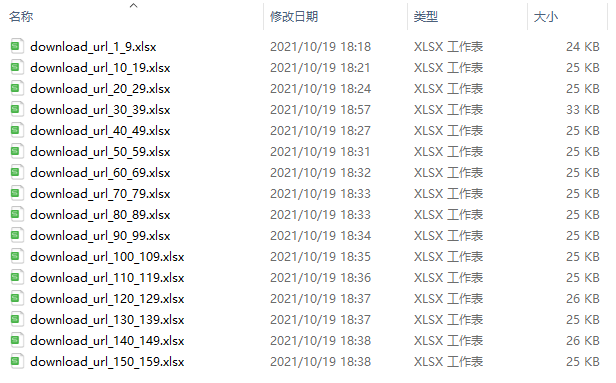
随便打开一个excel,可以看到密密麻麻的全是url链接。但是仔细看就会发现里面不止是财报,还有年度报告的摘要,所以我们小小的处理一下。

# pandsa删除摘要
#保存的时候会默认把股票代码开头的0去掉
import pandas as pd
file_list = os.listdir()
path_xlsx = '1_delete.xlsx'
pdf_infor = pd.read_excel('1.xlsx')
#print(type(pdf_infor.at[2,'title']))
for i in range(pdf_infor.shape[0]):
zhaiyao = pdf_infor.at[i,'title']
if zhaiyao.find('摘要') != -1:
pdf_infor = pdf_infor.drop(i)
pdf_infor.to_excel(path_xlsx)
处理完成后会发现所有的股票代码前面的0都不见了,我是在所有财报下载完成后统一修改文件名的。处理方法有很多种,这也不是什么大问题。
最后就是下载了,下载的时候会偶尔遇到服务器拒绝我的请求,所以只能用try方法,被拒绝的时候把没有成功下载的文件序号记下来,等全部跑完了再单独处理就好了。话不多说,上代码。
'''
pandas 读取数据批量下载
无法下载的保存在txt中,晚点单独下载
'''
import requests
import time
import pandas as pd
import random
import os
import json
file_path= "pdf_1/"
pdf_infor = pd.read_excel('1.xlsx')
headers ={'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'}
#下载列表里第i个url
def download(i,f_url):
f_url = pdf_infor.at[i,'url']
return requests.get(f_url,headers = headers)
for each in range(pdf_infor.shape[0]):
Stkcd = pdf_infor.at[each,'secCode']
firm_name = pdf_infor.at[each,'secName'].replace("*","")
Year = pdf_infor.at[each,'Year']
pdf_url = pdf_infor.at[each,'url']
file_name = "{}{}{}.pdf".format(Stkcd,firm_name,Year)
file_full_name = os.path.join(file_path,file_name)
print("开始下载{},股票代码{}的{}年报".format(firm_name,Stkcd,Year))
try:
time.sleep(random.uniform(4,6)) #控制访问速度
rs = download(each,pdf_url)
with open(file_full_name, "wb") as fp:
for chunk in rs.iter_content(chunk_size=10240):
if chunk:
fp.write(chunk)
except Exception as e:
with open('log.txt', "a") as f:
f.write(str(each)+'\n') #当然也可以直接把url给保存到错误日志里
print(e)
print("===================下载完成==========================")
最后看一下爬取的效果吧,这里就只剩下股票代码有点问题了。我干脆就全部给加上吧。代码如下
#因为之前去掉excel里摘要url的时候把所有股票代码开头的0都去掉了,现在补上 import os import re i = 'test'#保存pdf的路径 #补全开头的0 def fix_name(name): for i in range(6-len(name)): name = '0' + name return name file_path = os.listdir(i) for file in file_path: #print(file) stock_num_wrong = re.findall(r'\d+',file)#去掉年份提出数字 rest_file = file[len(stock_num_wrong[0]):]#去掉提取出的数字 stock_num_new = fix_name(str(stock_num_wrong[0]))#第一个是股票代码第二个是年份 file_name_new = stock_num_new + rest_file os.rename(os.path.join(i,file),os.path.join(i,file_name_new)) print(rest_file)
补全以后就大功告成了。当然这个方法有挺多地方可以整合改进的,但是我太懒了,反正数据也有了,就这样吧!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号