使用python读取视频中的指定数字(二):pytesseract 识别图片
书接上回:https://www.cnblogs.com/mysteriouspavilion/articles/15389927.html
我们手上有了视频中截取下来的图片,那么如何识别呢?我选择了 pytesseract. 这个库安装起来没那么容易,但是使用起来就很简单。
首先我们需要用 pip 安装 pillow 和 pytesseract:
pip install pytesseract
pip install pillow
但是此时还不能使用 pytesseract。还需要下载 pytesseract 的安装包,地址如下:
https://github.com/UB-Mannheim/tesseract/wiki
下载安装完成后需要配置环境变量。我是 win10 的系统,步骤仅供参考。
点击 ”我的电脑“ - ”属性“ - ”高级系统设置“ - ”高级“ - ”环境变量“。在系统变量中找到 Path。
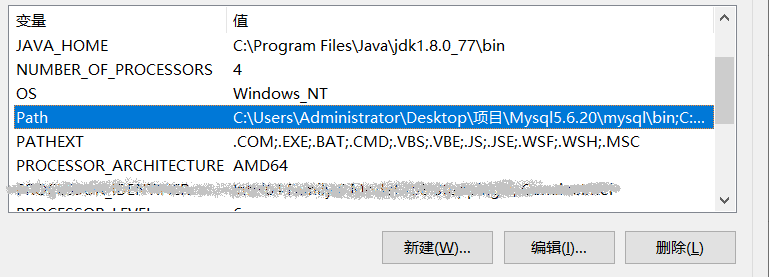
点击编辑,新建。将刚才安装的 pytesseract 路径复制进来并保存就可以了。

到这里我们用 pip 安装的 pytesseract 还不能使用,需要找到 python 安装库的文件夹,并打开 pytesseract.py 。下面是我的路径,找不到的同学可以尝试在这里面找。插一句题外话,我电脑上装了 listary, 它是一个很棒的搜索软件,可以快速搜索你电脑上的文件,我就是用 listary 找到的 pytesseract.py。 在我朋友的电脑上找了半天才找到。

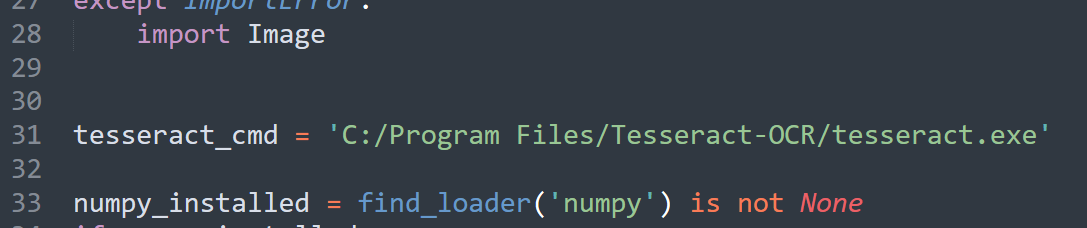
打开 pytesseract.py 之后找到 tesseract_cmd 变量(在开头),把它的值改为安装 pytesseract.exe 的路径,也就是上一步环境变量的值加上 pytesseract.exe.
------------------------分割线------------------------
随便找一张带文字的图片简单测试一下:
import pytesseract from PIL import Image image = Image.open('1.jpg') result = pytesseract.image_to_string(image) print(result)
如果英文和数字符号能正确识别就完成了第一步。接下来我们要用 pytesseract 处理数据了。
因为我们只需要数字,所以我们只用将结果过滤一下,只提取数字就好了(因为结果里面总会混入一些奇奇怪怪的东西)。
import pytesseract from PIL import Image image = Image.open('1.jpg') result = pytesseract.image_to_string(image) result = ''.join(filter(str.isdigit,result))#只保留数字 print(result)
测试运行后就会得到最终的数据了(小数点也被干掉了~~),整合之前的代码,并调试。增加了容错机制,即,如果识别不出来结果,本次识别结果采用上一次的数据。增加了可以控制多少帧识别一次的变量,最终结果会被保存在一个 txt 中。具体内容都在代码和注释中。
''' 将需要识别的视频和这个代码放在同一个文件夹下,文件名可以 在video_path变量中更改,interval变量控制每多少帧视频读 取一次数据,数据保存在result.txt中,仅有数字,不识别小数点 和负号等 使用截取视频的代码确定正确的截取区间后,替换掉box变量,可 以先用较大的interval测试是否可以正确 ''' import cv2#视频转图片 import pytesseract import numpy from PIL import Image name_of_result_file = 'result'#保存截图结果的图片文件名,可修改 box = (35, 300, 180, 460)#左边的数据,根据实际情况修改 result = ''#保存结果的字符串 #旧变量用于识别出错时替代错误结果,默认第一个识别结果不出错 text,text_old = '','' video_path = 'test_2.mp4' # 视频地址 interval = 10 #每多少帧截一次数据 num_of_data = 0 #一共多少数据 n = 0 vid = cv2.VideoCapture(video_path)#打开视频 while vid.isOpened(): is_read, frame = vid.read() if is_read : n = n+1 if n == interval: n = 1 num_of_data = num_of_data + 1 #数据个数记录 image_org = Image.fromarray(cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)).convert('L') text_old = text #保存上一次识别结果 text = pytesseract.image_to_string(image_org.crop(box)) #截取区间并识别图片 text = ''.join(filter(str.isdigit,text))#用filter提取出数字 if text == '': text = text #如果没有识别出来就采用上一次数据并保存 result = result + text + '\n' #保存并换行 else: break print('一共有这么多数据: ',num_of_data,'个/n') f = open(name_of_result_file + '.txt', "w+") f.write(str(result)) f.close()
最后的结果展示一下
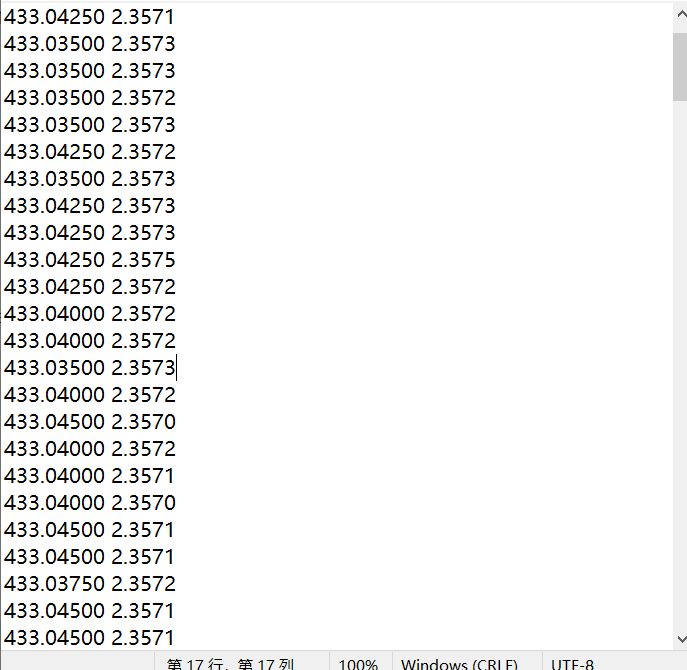
这里是每组识别了两个数据,我给出的代码只识别了一组,使用的时候可以看情况自己修改。
体会:这个小项目花了两个半天的时间,大部分时间耗费在了识别结果的处理上,因为 pytesseract 识别的准确度还是不太高,所以结果里面总是有一些奇怪的符号。最终使用了灰度处理的办法稍微改进了一下。尽管如此,合适的图片区间并不好找,主要还是视频清晰度和软件的识别精度的问题。本来想能不能直接录屏,但是测试设备不能联网,不方便下载软件录屏,目前就将就着用吧。
转载请注明出处:https://www.cnblogs.com/mysteriouspavilion/articles/15390276.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号