【系统设计】基于位置的服务
在本文中,我们将设计一个邻近服务,用来发现用户附近的地方,比如餐馆,酒店,商场等。
设计要求
从一个小明去面试的故事开始。

面试官:你好,我想考察一下你的设计能力,如果让你设计一个邻近服务,用来搜索用户附近的商家,你会怎么做?
小明:好的,用户可以指定搜索半径吗?如果搜索范围内没有足够的商家,系统是否支持扩大搜索范围?
面试官:对,用户可以根据需要修改,大概有以下几个选项,0.5km,1km,2km,5km,10km,20km。
小明:嗯,还有其他的系统要求吗?
面试官:另外还需要考虑的是,系统的低延迟,高可用,和可扩展性,以及数据隐私。
小明:好的,了解了。
总结一下,需要做一个邻近服务,可以根据用户的位置(经度和纬度)以及搜索半径返回附近的商家,半径可以修改。因为用户的位置信息是敏感数据,我们可能需要遵守数据隐私保护法。
高层次设计
高层次设计图如下所示,系统包括两部分:基于位置的服务 (location-based service)LBS 和业务(bussiness)相关的服务。
让我们来看看系统的每个组件。
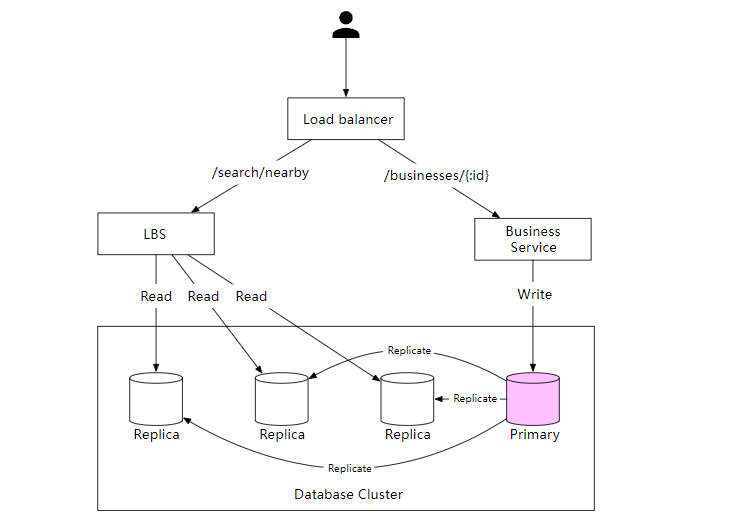
负载均衡器
负载均衡器可以根据路由把流量分配给多个后端服务。
基于位置的服务 (LBS)
LBS 服务是系统的核心部分,通过位置和半径寻找附近的商家。LBS 具有以下特点:
- 没有写请求,但是有大量的查询
- QPS 很高,尤其是在密集地区的高峰时段。
- 服务是无状态的,支持水平扩展。
Business 服务
商户创建,更新,删除商家信息,以及用户查看商家信息。
数据库集群
数据库集群可以使用主从配置,提升可用性和性能。数据首先保存到主数据库,然后复制到从库,主数据库处理所有的写入操作,多个从数据库用于读取操作。
接下来,我们具体讨论位置服务 LBS 的实现。
1. 二维搜索
这种方法简单,有效,根据用户的位置和搜索半径画一个圆,然后找到圆圈内的所有商家,如下所示。
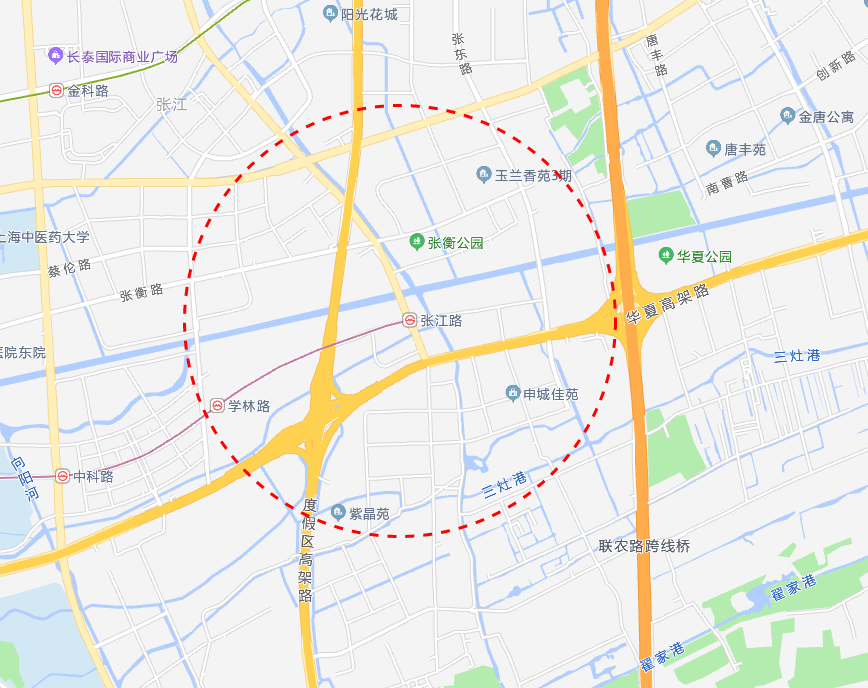
商家的纬度用 latitude 表示,经度用 longitude 表示。同样的用户的纬度和经度可以用 user_latitude 和 user_longitude 表示,半径用 radius 表示。
上面的搜索过程可以翻译成下面的伪 SQL 。
SELECT business_id, latitude, longitude,
FROM business
WHERE
latitude >= (@user_latitude - radius) AND latitude < (@user_latitude + radius)
AND
longitude >= (@user_longitude - radius) AND longitude < (@user_longitude + radius)
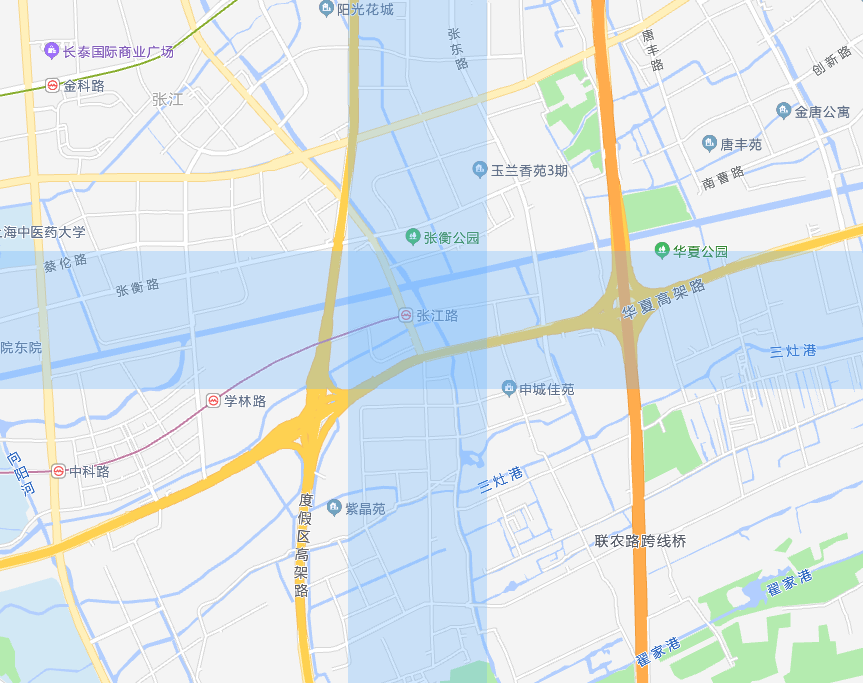
这种方式可以实现我们的需求,但是实际上效率不高,因为我们需要扫描整个表。虽然我们可以对经纬度创建索引,效率有提升,但是并不够,我们还需要对索引的结果计算取并集。
2. Geohash
我们上面说了,二维的经度和纬度做索引的效果并不明显。而 Geohash 可以把二维的经度和纬度转换为一维的字符串,通过算法,每增加一位就递归地把世界划分为越来越小的网格,让我们来看看它是如何实现的。
首先,把地球通过本初子午线和赤道分成四个象限,如下
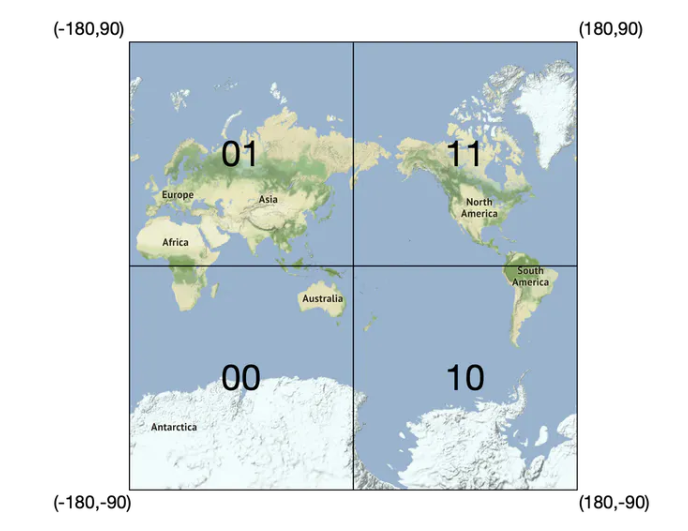
- 纬度范围 [-90, 0] 用 0 表示
- 纬度范围 [0, 90] 用 1 表示
- 经度范围 [-180, 0] 用 0 表示
- 经度范围 [0, 180] 用 1 表示
然后,再把每个网格分成四个小网格。
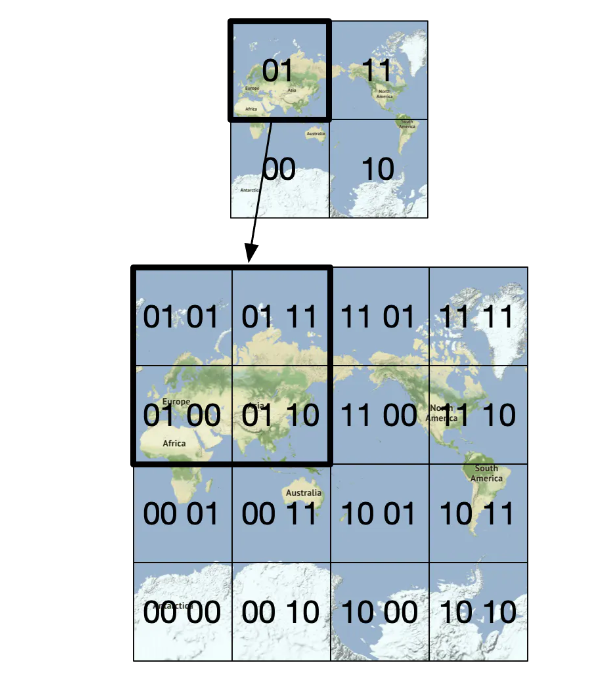
重复这个过程,直到网格的大小符合我们的需求,Geohash 通常使用 base32 表示。让我们看两个例子。
-
Google 总部的 Geohash(长度为 6):
1001 10110 01001 10000 11011 11010 (base32 convert) → 9q9hvu (base32) -
Facebook 总部的 Geohash(长度 为 6):
1001 10110 01001 10001 10000 10111 (base32 convert) → 9q9jhr (base32)
Geohash 有 12 个精度(也称为级别), 它可以控制每个网格的大小,字符串越长,拆分的网格就越小,如下

实际中,按照具体的场景选择合适的 Geohash 精度。
通过这种方式,最终把地图分成了下面一个个小的网格,一个 Geohash 字符串就表示了一个网格,这样查询每个网格内的商家信息,搜索是非常高效的。
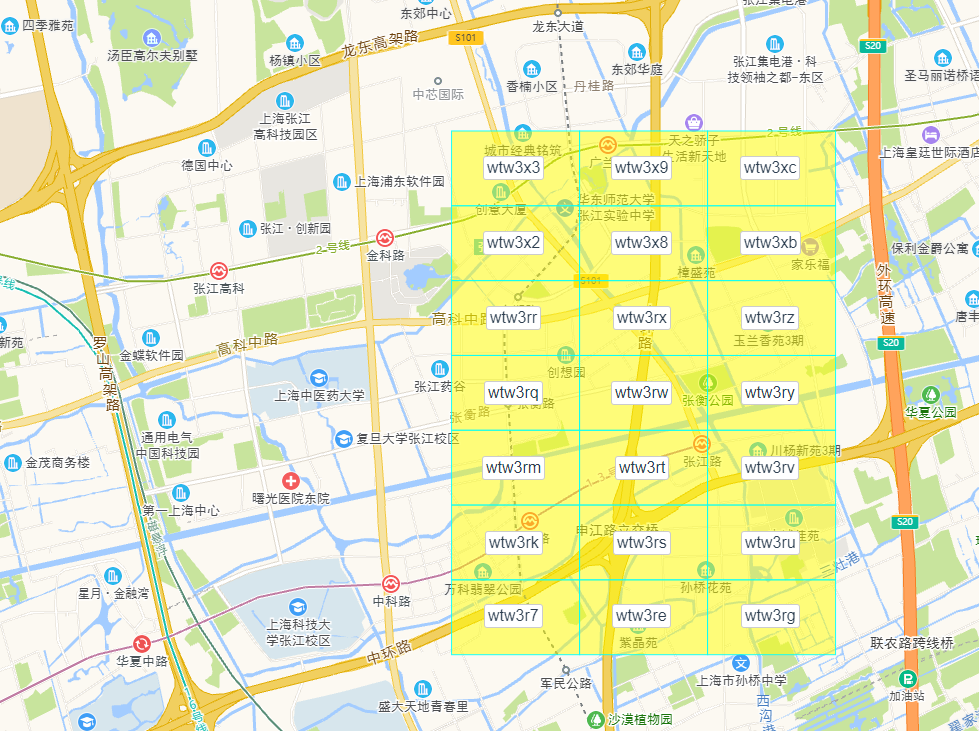
可能你已经发现了一些规律,上图的每个网格中,它们都相同的前缀 wtw3。是的,Geohash 的特点是,两个网格的相同前缀部分越长,就表示它们的位置是邻近的。
反过来说,两个相邻的网格,它们的 Geohash 字符串一定是相似的吗?
不一定,因为存在 边界问题。当两个网格都在边缘时,虽然它们是相邻的,但是 Geohash 的值从第一位就不一样,如下图,两个紫色的点相邻。
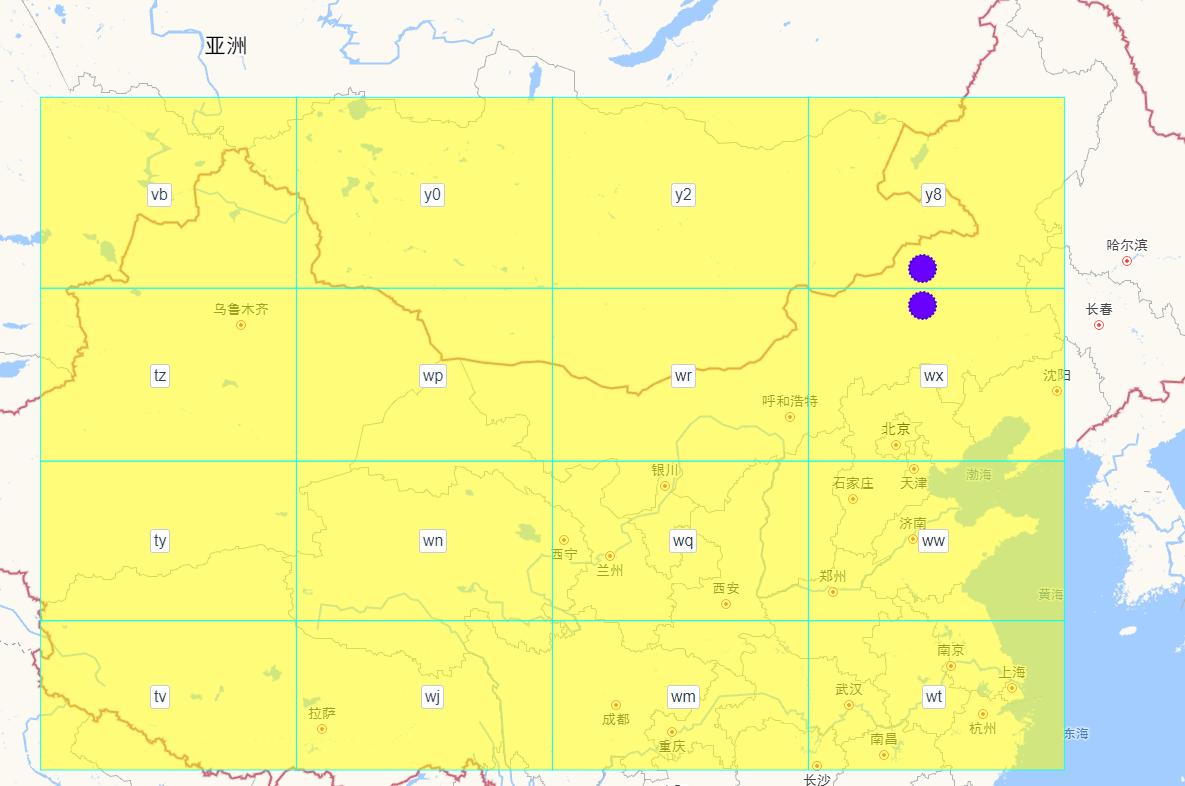
下面是一个精度比较高的网格,有些相邻网格的 Geohash 的值是完全不一样的。
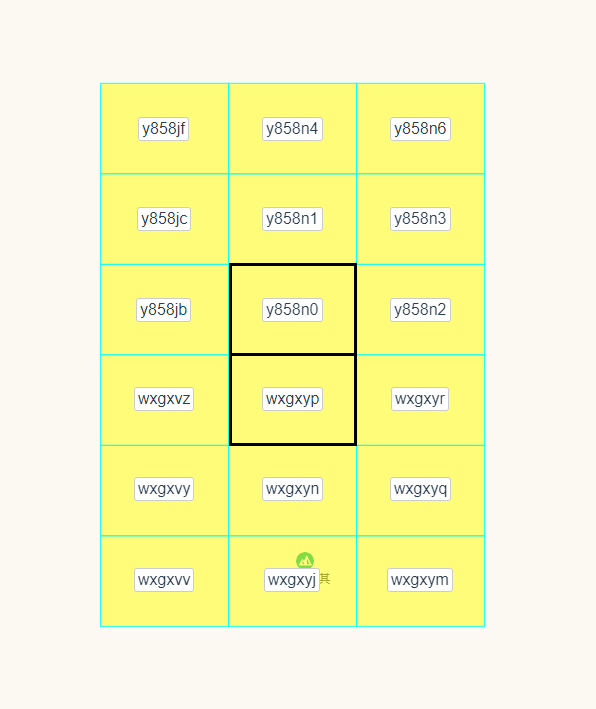
还有一个边界问题是,对于用户(橙色)来说,隔壁网格的商家(紫色)可能比自己网格的商家(紫色)的距离还要近,如下图
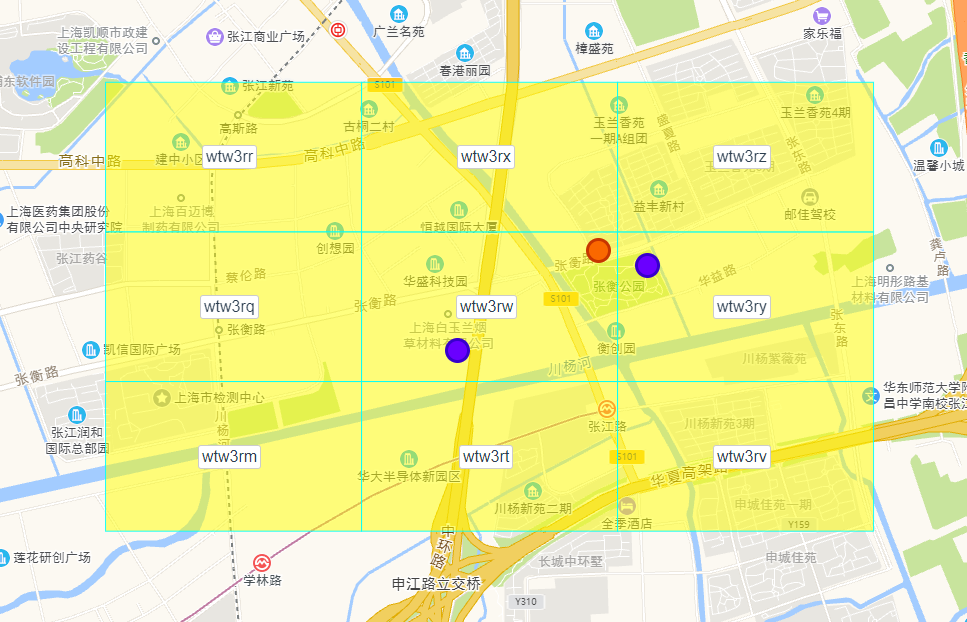
所以,在查询附近的商家时,不能只局限于用户所在的网格,要扩大到用户相邻的4个或者9个网格,然后再计算距离,进行筛选,最终找到距离合适的商家。
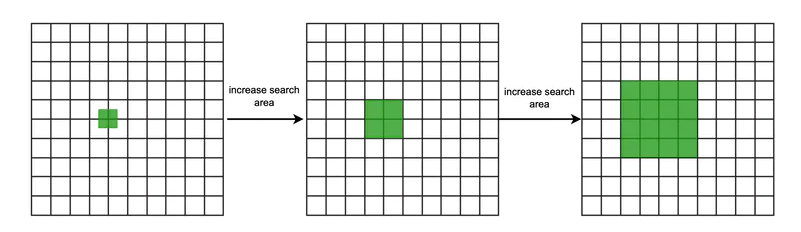
另外,当在用户在偏远的郊区时,我们可以按照下面的方式,扩大搜索范围,返回足够数量的商家。
Geohash 的使用非常广泛的,另外 Redis 和 MongoDB 都提供了相应的功能,可以直接使用。
3 . 四叉树
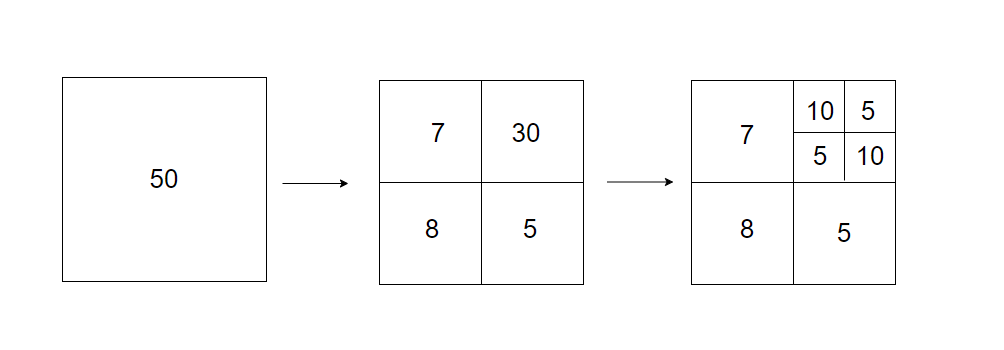
还有一种比较流行的解决方案是四叉树,这种方法可以递归地把二维空间划分为四个象限,直到每个网格的商家数量都符合要求。
如下图,比如确保每个网格的数量不超过10,如果超过,就拆分为四个小的网格。
请注意,四叉树是一种内存数据结构,它不是数据库解决方案。它运行在每个LBS 服务上,数据结构是在服务启动时构建的。
接下来,看一下节点都存储了哪些信息?
内部节点
网格的左上角和右下角的坐标,以及指向 4个 子节点的指针。
叶子节点
网格的左上角和右下角的坐标,以及网格内的商家的 ID 数组。
现实世界的四叉树示例
Yext 提供了一张图片 ,显示了其中一个城市构建的四叉树。我们需要更小、更细粒度的网格用在密集区域,而更大的网格用在偏远的郊区。
谷歌 S2 和 希尔伯特曲线
Google S2 库是这个领域的另一个重要参与者,和四叉树类似,它是一种内存解决方案。它基于希尔伯特曲线把球体映射到一维索引。
而 希尔伯特曲线 是一种能填充满一个平面正方形的分形曲线(空间填充曲线),由大卫·希尔伯特在1891年提出,如下

希尔伯特曲线是怎么生成的?
最简单的一阶希尔伯特曲线,先把正方形平均分成四个网格,然后从其中一个网格的正中心开始,按照方向,连接每一个网格。

二阶的希尔伯特曲线, 每个网格都先生成一阶希尔伯特曲线 , 然后把它们首尾相连。

三阶的希尔伯特曲线

n阶的希尔伯特曲线, 实现一条线连接整个平面。
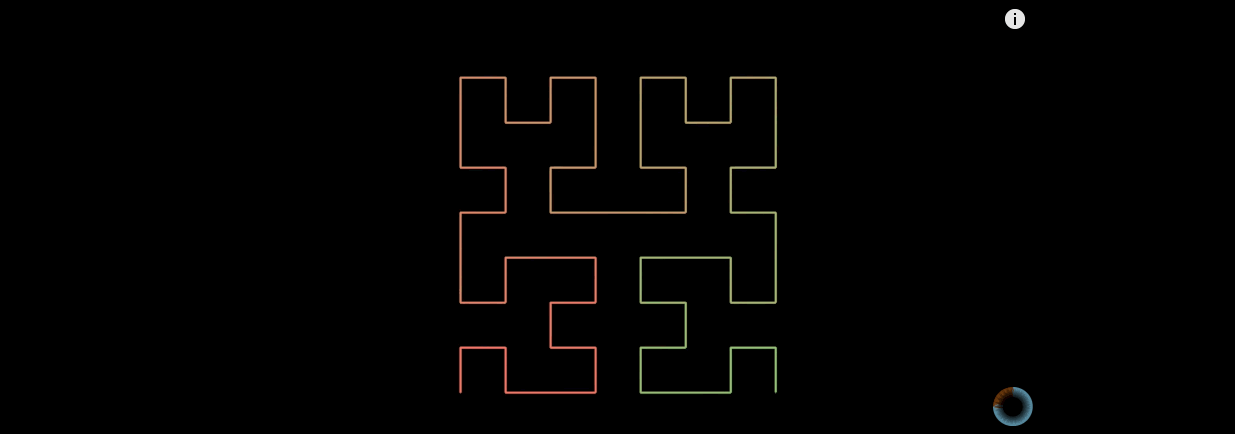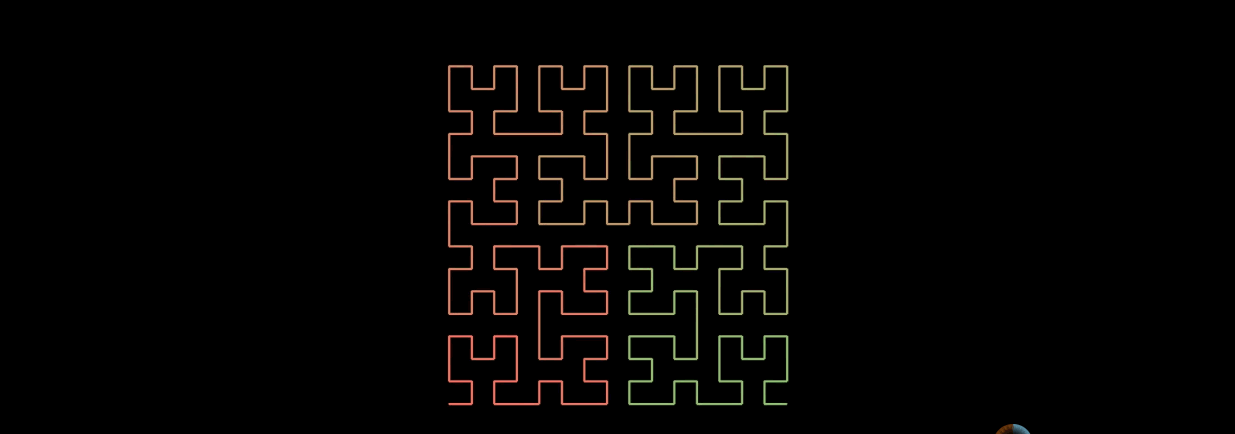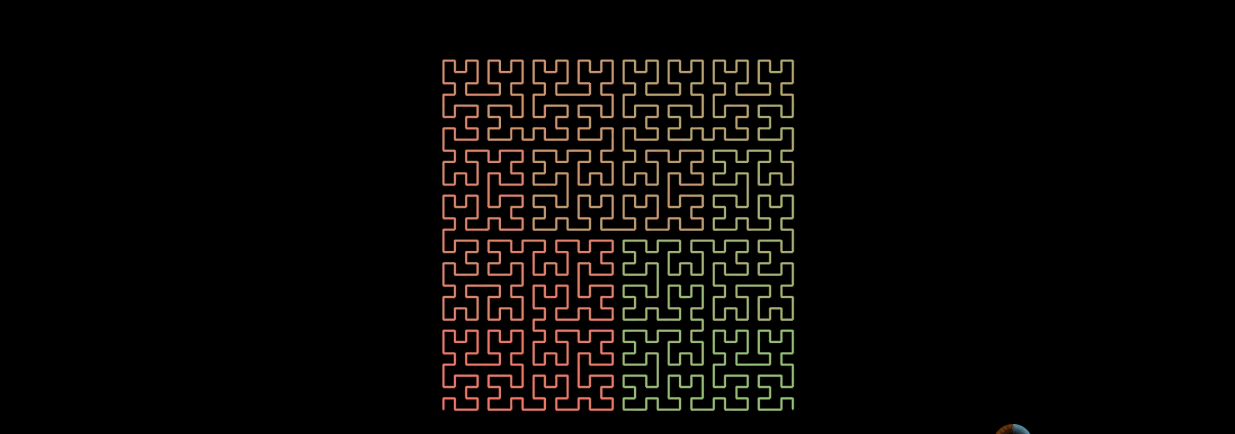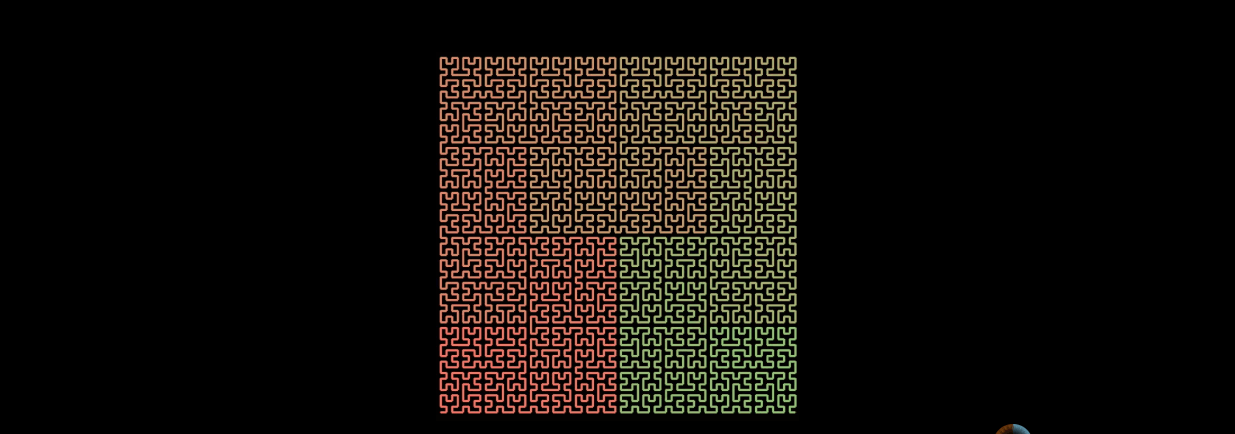
同样,希尔伯特曲线也可以填充整个三维空间。

希尔伯特曲线的一个重要特点是 降维,可以把多维空间转换成一维数组,可以通过动画看看它是如何实现的。

在一维空间上的搜索比在二维空间上的搜索效率高得多了。
多数据中心和高可用
我们可以把 LBS 服务部署到多个区域,不同地区的用户连接到最近的数据中心,这样做可以提升访问速度以及系统的高可用,并根据实际的场景,进行扩展。
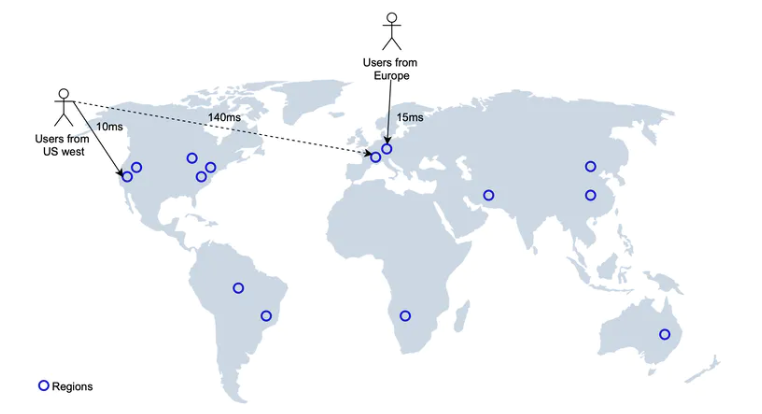
最终设计图
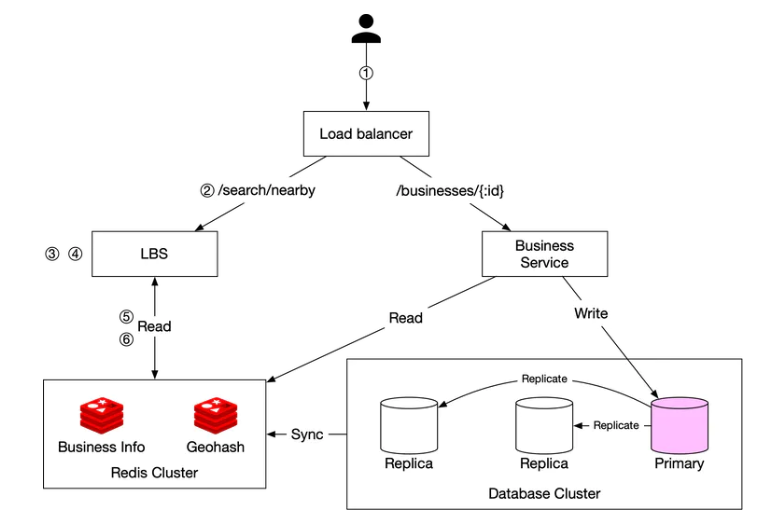
- 用户需要寻找附近 500 米的餐馆。客户端把用户位置(经度和纬度),半径(500m)发送给后端。
- 负载均衡器把请求转发给 LBS。
- 基于用户位置和半径信息,LBS 找到与搜索匹配的 geohash 长度。
- LBS 计算相邻的 Geohash 并将它们添加到列表中。
- 调用 Redis 服务获取对应的商家 ID。
- LBS 根据返回的商家列表,计算用户和商家之间的距离,并进行排名,然后返回给客户端。
总结
在本文中,我们设计了一个邻近服务,介绍了4种常见了实现方式,分别是二维搜索,Geohash, 四叉树和 Google S2。它们有各自的优缺点,您可以根据实际的业务场景,选择合适的实现。
Reference
https://halfrost.com/go_spatial_search/#toc-25
https://www.amazon.com/System-Design-Interview-Insiders-Guide/dp/1736049119

 浙公网安备 33010602011771号
浙公网安备 33010602011771号