

20234220 实验四《Python程序设计》实验报告
20234220 2024-2025-2 《Python程序设计》实验四报告
课程:《Python程序设计》
班级:2342
姓名:马燕秋
学号:20234220
实验教师:王志强
实验日期:2025年5月31日
必修/选修:专选课
一、实验内容及要求
(一)实验内容
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
例如:编写从社交网络爬取数据,实现可视化舆情监控或者情感分析。
例如:利用公开数据集,开展图像分类、恶意软件检测等
例如:利用Python库,基于OCR技术实现自动化提取图片中数据,并填入excel中。
例如:爬取天气数据,实现自动化微信提醒
例如:利用爬虫,实现自动化下载网站视频、文件等。
例如:编写小游戏:坦克大战、贪吃蛇、扫雷等等
注:在Windows/Linux系统上使用VIM、PDB、IDLE、Pycharm等工具编程实现。
(二)实验要求
①程序能运行,功能丰富。
②综合实践报告,要体现实验分析、设计、实现过程、结果等信息,格式规范,逻辑清晰,结构合理。
③在实践报告中,需要对全课进行总结,并写课程感想体会、意见和建议等。
二、实验过程及结果
综合老师讲过的内容及已经做过的实验,加之课堂上我对爬虫的学习不够深入,而爬虫确实可以便利学习和工作,所以本次实验我选择编写爬虫抓取祝福语信息,然后分别将信息以HTML和PDF的形式存储到文本中,减少我们检索信息需要的时间和精力。
(一)实验过程
爬虫基本步骤是 :确定需求、发送请求、获取数据、解析数据、保存数据。
1.准备代码需要用到的数据
①确定能否爬取
先访问robot.txt,判断该网站是否能够进行爬取。中国文库网并没有设置爬虫规则,因此我选择该网站进行实验。(老师课上讲过robots.txt 只是一个指示文件,类似于贴在健身房、社区中心、服务中心等区域的标识语。其自身没有权利执行规则,但是有素质的顾客会遵守规则,而没有素质的顾客可能会违反规则。)

②找到URL地址,请求方法是GET,请求参数字段可以是User-Agent

③找到HTML中的标题和正文所在所在位置,方便数据解析时可以找到我们需要的内容。

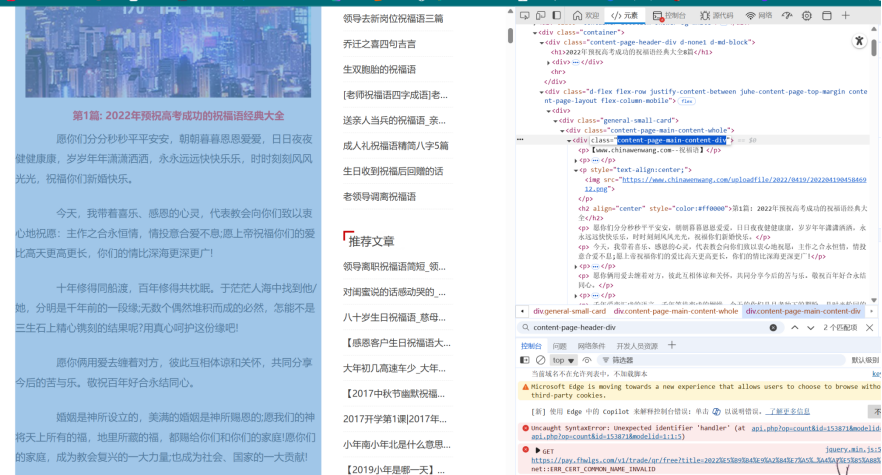
2.编写代码
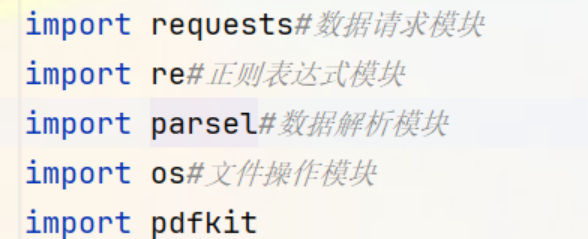
①导入必要的模块
由于要编写的是爬虫,还要解析网页内容,提取所需信息,处理提取的信息,并保存HTML和PDF文件,所以需要提前安装requests、parsel以及pdfkit模块(re和os属于内置模块,无需安装)。除此之外,需要单独在电脑上安装wkhtmltopdf引擎,方便后面把HTML文件转换成PDF。
②使用正则表达式将特殊字符替换为下划线,确保后面命名的文名符合Windous系统要求,保证后续文件能够正常保存。

③使用for循环遍历页码。对于每个页码,构造相应的URL,并设置请求头headers来模拟浏览器访问,避免被网站识别为爬虫而拒绝访问。然后使用requests.get()发送请求,获取网页的HTML内容,并打印出来进行调试。

④获取到文章列表页的HTML内容后,使用正则表达式提取每个文章的链接。再使用正则表达式匹配标签属性值。

⑤对于每个提取到的文章链接,再次发送请求获取文章详情页的HTML内容。使用parsel.Selector()将HTML内容转换为可解析的对象,然后使用CSS选择器提取文章的标题和内容并对标题进行清洗和处理。
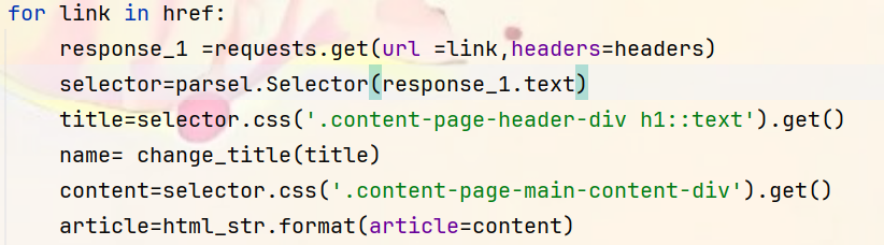
⑥为了将提取的内容保存为完整的HTML文件,需要再定义一个HTML模版,将article文章内容插入到这个位置。
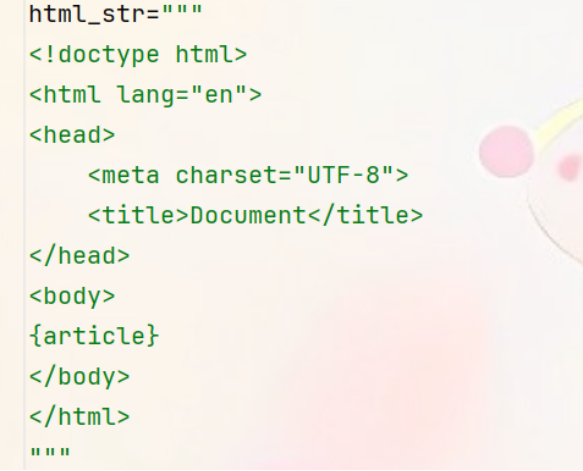
⑦对标题进行清洗处理后,将文章内容插入到上面的HTML模板中,生成完整的HTML文件。

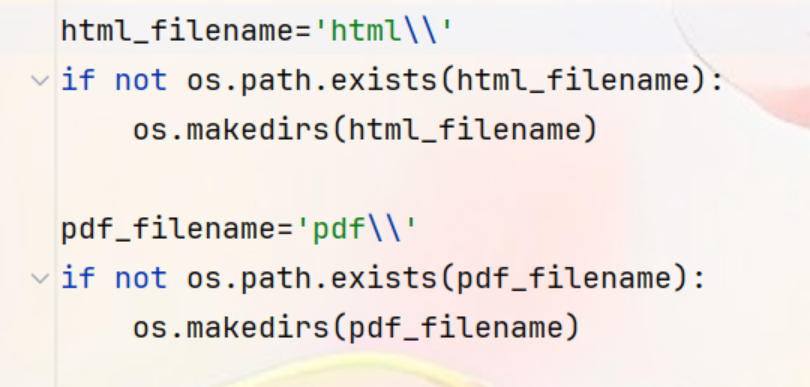
⑧创建html和pdf两个目录。在创建之前,使用os.path.exists()检查目录是否已经存在,如果不存在则使用os.makedirs()创建目录,方便保存信息。
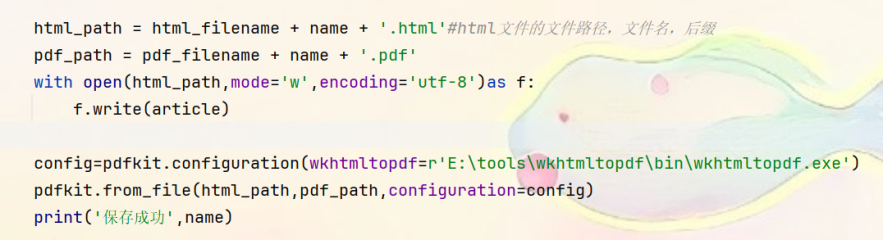
⑨将生成的完整的HTML文件保存到html目录下面,然后使用pdfkit将HTML文件转换为PDF文件,并保存到pdf目录下面,每次保存成功之后,打印提示信息。
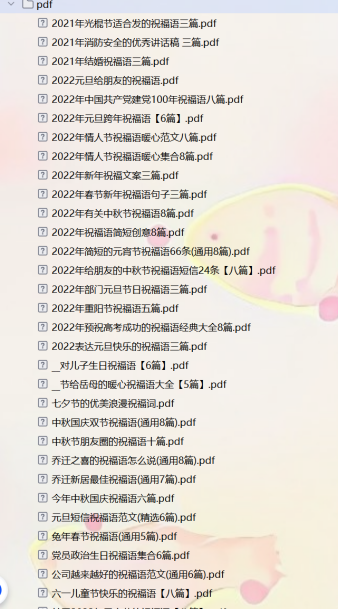
3.代码运行成果


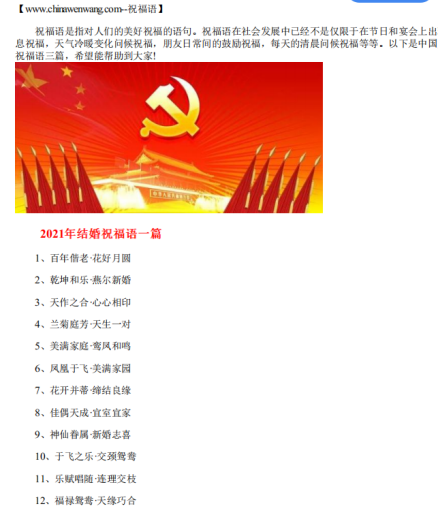
4.源代码如下
import requests#数据请求模块
import re#正则表达式模块
import parsel#数据解析模块
import os#文件操作模块
import pdfkit
html_str="""
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
{article}
</body>
</html>
"""
def change_title(name):
new_name=re.sub(r'[\\\/\:\*\?\"\<\>\|]','_',name)
return new_name
html_filename='html\\'
if not os.path.exists(html_filename):
os.makedirs(html_filename)
pdf_filename='pdf\\'
if not os.path.exists(pdf_filename):
os.makedirs(pdf_filename)
#文章列表的URL地址
for page in range(1,5):
url=f'https://www.chinawenwang.com/zlist-78-{page}.html'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0'
}
response = requests.get(url = url, headers=headers)
print(response.text)
href=re.findall(' <h2><a href="(.*?)"',response.text)
for link in href:
response_1 =requests.get(url =link,headers=headers)
selector=parsel.Selector(response_1.text)
title=selector.css('.content-page-header-div h1::text').get()
name= change_title(title)
content=selector.css('.content-page-main-content-div').get()
article=html_str.format(article=content)
html_path = html_filename + name + '.html'#html文件的文件路径,文件名,后缀
pdf_path = pdf_filename + name + '.pdf'
with open(html_path,mode='w',encoding='utf-8')as f:
f.write(article)
config=pdfkit.configuration(wkhtmltopdf=r'E:\tools\wkhtmltopdf\bin\wkhtmltopdf.exe')
pdfkit.from_file(html_path,pdf_path,configuration=config)
print('保存成功',name)
5.程序运行视频链接
https://www.bilibili.com/video/BV1uW7DzDE9k/?spm_id_from=333.1391.0.0
三、实验中遇到的问题和解决过程
问题1:不能理解解析数据过程中程序运行的逻辑。
解决方案:让AI使用比喻方式讲解,找python大佬再讲解一遍,就能懂了。
问题2:查找文章内容时不能快速定位到标题和内容所在位置。
解决方案:上网查看类似爬虫讲解视频,跟着步骤一点一点找。
四、实验总结
该程序需要运用到模块导入和使用、字符串处理、循环结构、文件操作、函数定义与调用、配置对象的使用等知识,对文科生的我来说很是复杂,但是编写下来之后,一定程度上是对以上学习内容的一种回顾。这个实验中最大的难题就是理解如何将爬到的信息进行处理,为了解决这个困难,我上网查找了很多资料,问了很多工科同学,功夫不负有心人,终于理解了,但是想要真正学以致用,未来还需要多加练习。此次实验充分让我感受到合理运用爬虫可以提高我们搜集信息的效率,还可以对搜集到的信息进行归纳处理,是科技便利人类的一个表现。
五、课程总结
没上这门课之前,我是不喜欢python课程的,对文科生的我来说,python在我心中留下来深奥难懂的刻板印象,但是真正上了这门课程,我发现python是有趣的,值得探索的一门好课程。
随着课程推进,我逐渐掌握了变量、函数、循环等基础语法,慢慢地我会主动探索了。完成实验内容时,我遇到过诸多难题,一次次的调试和修改代码,让我压力直线飙升,可当代码成功运行,看到预期的结果时,那种成就感又难以言表。老师给予的要求不高,给我们放宽了条件,所以我可以产生更多精力去探索,比如编写计算器时,我学会了使用tkinter,编写服务端和客户端时,我尽己所能完成了所有实验要求并弄懂了其中的加密代码。除此之外,我在业余生活中发现了方便我使用的工具,比如抢票、免费观看VIP视频(不经常用,仅供学习使用),我仿佛找到了高中时我问数学老师“这些复杂函数我学了之后生活中用在哪里呢?”的问题的答案。
编写代码过程中,我认识了代码整体性、美观性、可读性的重要性。我们写代码需要具有整体观念,要提前引入需要用到的工具,提前定义一些函数方便后面使用,考虑可能发生的错误情况,对错误情况进行规避。写完代码要看一看代码整体的美观性,合适的地方需要隔开,方便阅读。这段旅程让我明白,编程不仅是职业技能,更是一种用逻辑梳理混沌、用坚持化解困境的生活态度。我相信未来的生活中我仍然可以使用python便利自己的学习和生活,课程的结束不代表我与python说再见,而是开启了我自己主动探索的路程!
(经历了博客园随笔系统崩溃导致作业不见,但后来管理员帮我找回的事件后,我有了新的感受:机器处理的是信息和逻辑,它会因为一些原因导致出错,难以自己修复,而人处理的是意义、价值与关系,人的创造力无穷。技术是工具,而人赋予工具温度,并在工具失效时成为最后的防线。此外,我学会了备份作业~
六、意见和建议
①感谢老师温柔的脾气,宽松的实验要求,大大提升了我的兴趣和主动性,希望继续保持。
②但是老师上课编写代码的速度太快了,有点跟不上,老师能否慢一些,或者们提前发结构性的代码,让同学提前了解一下,如果没跟上的话也可以大致理解老师讲的内容。
③对于爬虫等难理解的代码,讲解时能否先注重运行的逻辑,后面再带上相关函数,这样大家更容易理解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号