破解起点小说网字体加密
参考博客
https://blog.csdn.net/u012082590/article/details/89024889
import requests import re from fontTools.ttLib import TTFont # <span class="MZYjnXxB">𘜂𘜂𘛾𘛺𘛽𘛾</span></em> url = 'https://book.qidian.com/info/1004608738' response = requests.get(url, headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}) # print(response.text) font_url = re.search(re.compile(r"@font-face.*?src.*?src: url\('(.*?)'\)", re.S), response.text).group(1) # print(font_url) data = re.search(re.compile(r'<div class="book-info ">.*?<p>.*?<em>.*?<span class=".*?">(.*?)</span>', re.S), response.text).group(1) print(data) num_list = [] numbers = data.split(';') for num in numbers: if num: # %x:十六进制的占位符 res = '%x' % int(num.replace('&#', '')) num_list.append(res) print(font_url, num_list) # 4. 请求字体文件的url,获取字体文件的内容。 font_response = requests.get(font_url, headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}).content with open('qd.woff', 'wb') as f: f.write(font_response) # 5. 将本地保存的qd.woff转化成qd.xml文件。 f = TTFont('qd.woff') f.saveXML('qd.xml') # 6. 根据十六进制的列表,从xml中根据code的值获取map标签。解析xml标签结构。 # [186f1, 186f2, 186f3, 186f4, 186f5] from xml.etree import ElementTree # 获取xml文件的根节点(文档树对象) obj(<Element object xxx>) = etree.HTML(page_source, parse=etree.HTMLParse(encoding="utf8")) root_obj = ElementTree.parse('qd.xml').getroot() # 在root_obj的基础上,开始查找<map>标签。 # find()类似于selenium中的find() # <Element 'cmap_format_12' at 0x0000000003B2F548> maps_element = root_obj.find('cmap').find('cmap_format_12').findall('map') # 遍历maps_element这个列表,里面保存的全部都是<Element 'map' at xxx>对象。 map_ele_dict = {} for map_ele in maps_element: # 取出map标签内的code和name属性的值。 # 以code为键,以name为值,保存到字典map_ele_dict map_ele_dict[map_ele.attrib['code'].replace('0x', '')] = map_ele.attrib['name'] # 7. xml解析完毕,会得到如下数据: # a. 网页源代码数据['1883d', '1883d', '18840', '1883e', '18838', '1883c'] # b. 字体文件xml中的数据: #{'18836': 'nine', '18838': 'six', '18839': 'two', '1883a': 'eight', '1883b': 'three', '1883c': 'five', '1883d': 'four', '1883e': 'period', '1883f': 'zero', '18840': 'one', '18841': 'seven'} convert_dict = { 'one': '1', 'two': '2', 'three': '3', 'four': '4', 'five': '5', 'six': '6', 'seven': '7', 'eight': '8', 'nine': '9', 'zero': '0', 'period': '.' } # 接下来,将源代码数据遍历 result = '' for number in num_list: # 从字典map_ele_dict中取出对应的one, two, three... english_number = map_ele_dict[number] # 再以one, two, three...为键,从字典convert_dict中取出阿拉伯数字 alb_number = convert_dict[english_number] result += alb_number print(result)
这个代码还是比较容易得
那个对应关系可以通过一个工具查看,官方提供免费版本下载但是要邮箱激活
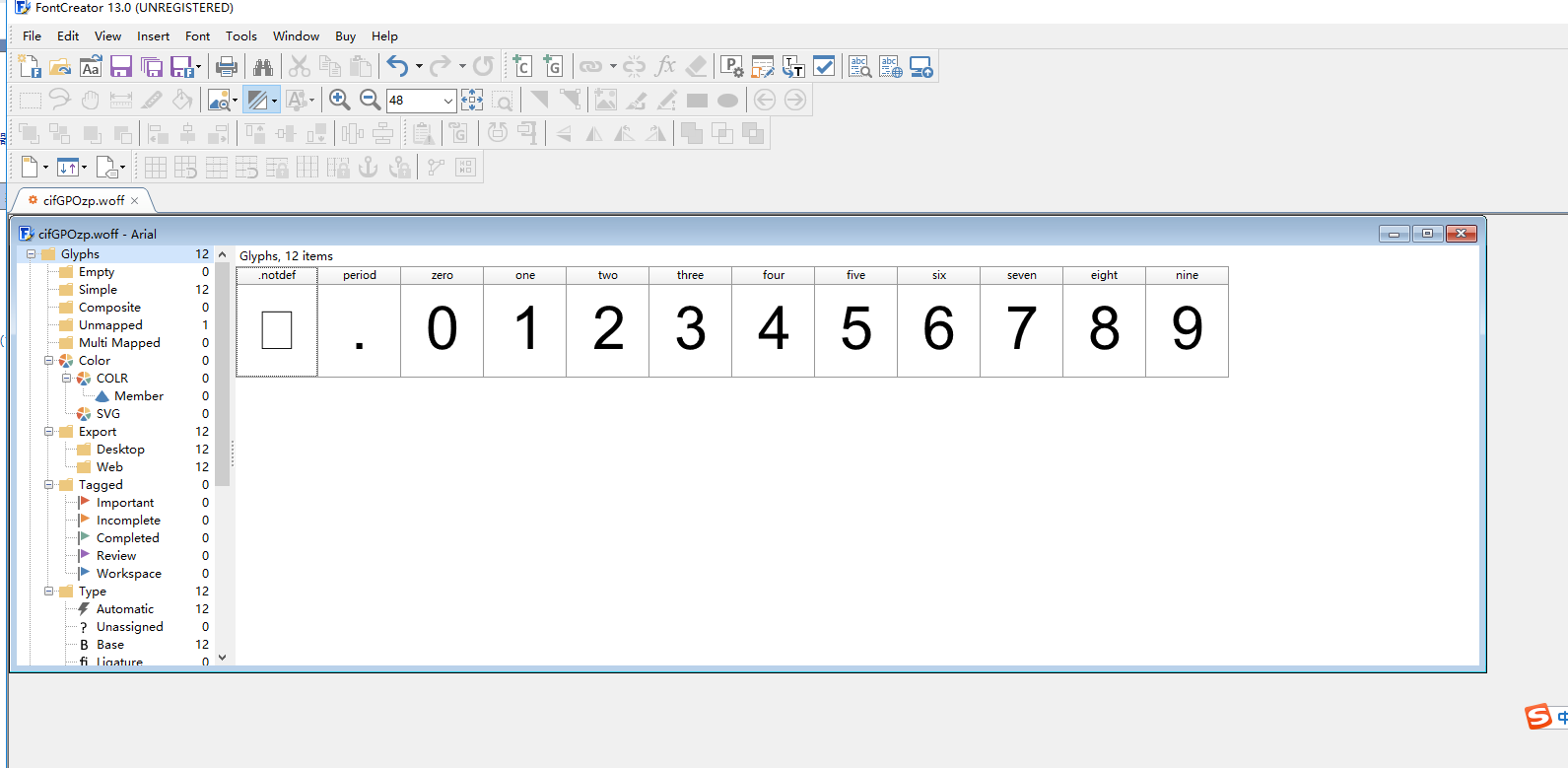
另一方面,就是有些包需要装都是pip安装的,少啥装啥就行了。
可以打开xml文件看看
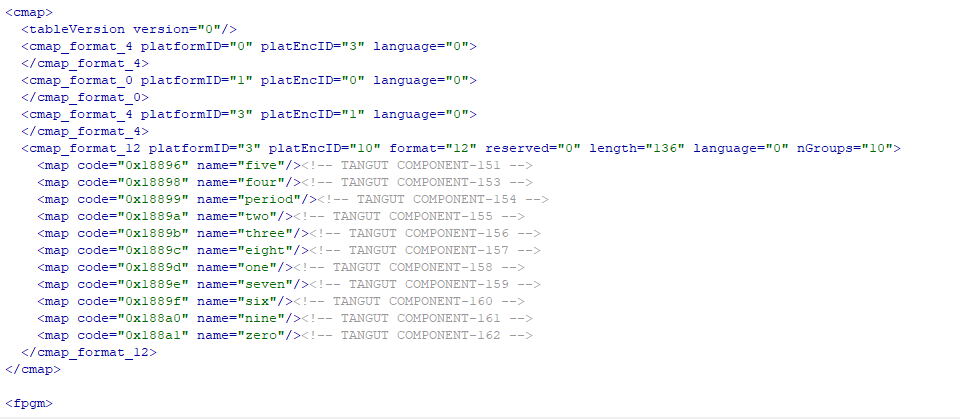
我们可以看到code那对应的是十六进制的数据,怎么知道的,因为
0-9 A-F 的范围是十六进制的,数据里出现了f的。。然后就是从根目录开始寻找节点,一直找到code和name,组成字典,再将处理过的页面里的数据作为键去取值,得到name,再根据那个表找对应的数据就行了。
这里最坑的就是正则匹配,
根据上面的原理去处理另一个页面的数据,整个人都不好了。。。
https://www.qidian.com/free/all?chanId=21&orderId=&vip=hidden&style=1&pageSize=20&siteid=1&pubflag=0&hiddenField=1&page=3
这个网页很神奇,用程序请求的代码少了关键部分代码,但是你看不见又可以用正则等东西从源码里把数据匹配出来,真的是没谁了,几年第一次遇到这种的。所以正则一定多注意,不是批不出来,是没写对。。
import requests import re from fontTools.ttLib import TTFont headers= { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36' } source = requests.get('https://www.qidian.com/free/all?chanId=21&orderId=&vip=hidden&style=1&pageSize=20&siteid=1&pubflag=0&hiddenField=1&page=3',headers=headers).text print(source) demo = re.compile('<\/style><span class=".*?">(&#.*?;)</span>万字',re.S) lists = demo.findall(source) print(lists) urls = re.compile('(https:\/\/qidian\.gtimg\.com\/qd_anti_spider\/\w+\.woff)',re.S) woff = urls.findall(source)[0] print(woff) font_response = requests.get(woff, headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}).content with open('qd.woff', 'wb') as f: f.write(font_response) f = TTFont('qd.woff') f.saveXML('qd.xml') from xml.etree import ElementTree root_obj = ElementTree.parse('qd.xml').getroot() maps_element = root_obj.find('cmap').find('cmap_format_12').findall('map') map_ele_dict = {} for map_ele in maps_element: # 取出map标签内的code和name属性的值。 # 以code为键,以name为值,保存到字典map_ele_dict map_ele_dict[map_ele.attrib['code'].replace('0x', '')] = map_ele.attrib['name'] convert_dict = { 'one': '1', 'two': '2', 'three': '3', 'four': '4', 'five': '5', 'six': '6', 'seven': '7', 'eight': '8', 'nine': '9', 'zero': '0', 'period': '.' } for i in lists: num_list = [] numbers = i.split(';') for num in numbers: if num: # %x:十六进制的占位符 res = '%x' % int(num.replace('&#', '')) num_list.append(res) print(num_list) result = '' for number in num_list: # 从字典map_ele_dict中取出对应的one, two, three... english_number = map_ele_dict[number] # 再以one, two, three...为键,从字典convert_dict中取出阿拉伯数字 alb_number = convert_dict[english_number] result += alb_number print(result)
最终搞定了,但是那部分源码为啥看不见却能匹配到真的现在也不知道,而且注意class后面的属性是会实时变化的,不能用来定位。这一点非常的坑。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号