
python使用爬虫技术抓取网页中的title标签
使用爬虫技术抓取网页中的title标签
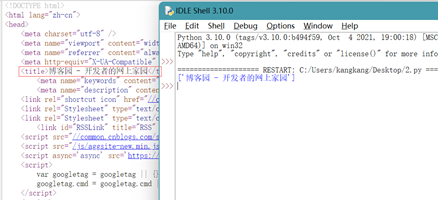
import urllib.request import re page = urllib.request.urlopen('https://www.cnblogs.com') html = page.read().decode('utf-8') title=re.findall('<title>(.+)</title>',html) print (title)
import urllib.request import re page = urllib.request.urlopen('https://www.cnblogs.com') html = page.read().decode('utf-8') title=re.findall('<title>(.+)</title>',html) print (title)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号