kafka-clients介绍
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients --> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.4.0</version> </dependency>
这里是基于2.4.0进行说明的。
一、kafka生产者
org.apache.kafka.clients.producer.KafkaProducer -- 生产者
org.apache.kafka.clients.producer.ProducerConfig -- 生产者配置
org.apache.kafka.clients.producer.ProducerRecord -- 消息
不同的应用场景对消息有不同的需求,即是否允许消息丢失、重复、延迟以及吞吐量的要求。不同场景对Kafka生产者的API使用和配置会有直接的影响。
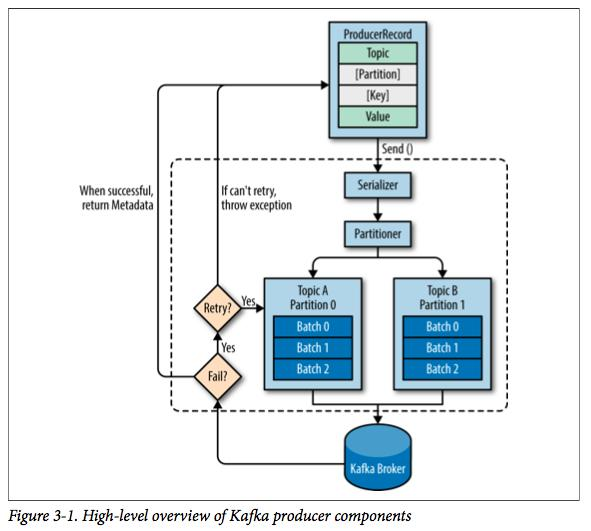
kakfa发送消息的主要步骤:
每个消息是一个ProducerRecord对象,必须指定消息所属的Topic和消息值Value,此外还可以指定消息所属的Partition以及消息的Key。
① 序列化ProducerRecord有多个构造器
② 如果ProducerRecord中指定了Partition,则Partitioner不做任何事情;否则,Partitioner根据消息的key得到一个Partition。这是生产者就知道向哪个Topic下的哪个Partition发送这条消息。
③ 消息被添加到相应的batch中,独立的线程将这些batch发送到Broker上。
④ broker收到消息会返回一个响应。如果消息成功写入Kafka,则返回RecordMetaData对象,该对象包含了Topic信息、Patition信息、消息在Partition中的Offset信息;若失败,返回一个错误。
Kafka的顺序保证。Kafka保证同一个partition中的消息是有序的,即如果生产者按照一定的顺序发送消息,broker就会按照这个顺序把他们写入partition,消费者也会按照相同的顺序读取他们。
1. 生产者配置
bootstrap.servers
list。
用于建立与kafka集群的连接,这个list仅仅影响用于初始化的hosts,来发现全部的servers。
格式:host1:port1,host2:port2,…,数量尽量不止一个,以防其中一个down了。
acks
字符串, 默认值是1。
Server完成 producer request 前需要确认的数量。
acks=0时,producer不会等待确认,直接添加到socket等待发送;
acks=1时,等待leader写到local log就行;
acks=all或acks=-1时,等待isr中所有副本确认
(注意:确认都是 broker 接收到消息放入内存就直接返回确认,不是需要等待数据写入磁盘后才返回确认,这也是kafka快的原因)
buffer.memory
long, 默认值33554432。
Producer可以用来缓存数据的内存大小。该值实际为RecordAccumulator类中的BufferPool,即Producer所管理的最大内存。
如果数据产生速度大于向broker发送的速度,producer会阻塞max.block.ms,超时则抛出异常。
compression.type
字符串,默认值none。
Producer用于压缩数据的压缩类型,取值:none, gzip, snappy, or lz4。
batch.size
int,默认值16384。
Producer可以将发往同一个Partition的数据做成一个Produce Request发送请求,即Batch批处理,以减少请求次数,该值即为每次批处理的大小。
另外每个Request请求包含多个Batch,每个Batch对应一个Partition,且一个Request发送的目的Broker均为这些partition的leader副本。
若将该值设为0,则不会进行批处理。
linger.ms
long, 默认值0。
Producer默认会把两次发送时间间隔内收集到的所有Requests进行一次聚合然后再发送,以此提高吞吐量,而linger.ms则更进一步,这个参数为每次发送增加一些delay,以此来聚合更多的Message。
官网解释翻译:producer会将request传输之间到达的所有records聚合到一个批请求。通常这个值发生在欠负载情况下,record到达速度快于发送。但是在某些场景下,
client即使在正常负载下也期望减少请求数量。这个设置就是如此,通过人工添加少量时延,而不是立马发送一个record,producer会等待所给的时延,以让其他records发送出去,
这样就会被聚合在一起。这个类似于TCP的Nagle算法。该设置给了batch的时延上限:当我们获得一个partition的batch.size大小的records,就会立即发送出去,而不管该设置;
但是如果对于这个partition没有累积到足够的record,会linger指定的时间等待更多的records出现。该设置的默认值为0(无时延)。例如,设置linger.ms=5,会减少request发送的数量,
但是在无负载下会增加5ms的发送时延。
max.request.size
int, 默认值1048576。
请求的最大字节数。这也是对最大消息大小的有效限制。注意:server具有自己对消息大小的限制,这些大小和这个设置不同。此项设置将会限制producer每次批量发送请求的数目,以防发出巨量的请求。
receive.buffer.bytes
int, 默认值32768。
TCP的接收缓存 SO_RCVBUF 空间大小,用于读取数据。
request.timeout.ms
int,默认值30000。
client等待请求响应的最大时间,如果在这个时间内没有收到响应,客户端将重发请求,超过重试次数发送失败。
send.buffer.bytes
int,默认值131072。
TCP的发送缓存 SO_SNDBUF 空间大小,用于发送数据。
timeout.ms
int,默认值30000。
指定server等待来自followers的确认的最大时间,根据acks的设置,超时则返回error。
max.in.flight.requests.per.connection
int,默认值5。
在block前一个connection上允许最大未确认的requests数量。当设为1时,即是消息保证有序模式,
注意:这里的消息保证有序是指对于单个Partition的消息有顺序,因此若要保证全局消息有序,可以只使用一个Partition,当然也会降低性能
metadata.fetch.timeout.ms
long,默认值60000。
在第一次将数据发送到某topic时,需先fetch该topic的metadata,得知哪些服务器持有该topic的partition,该值为最长获取metadata时间。
reconnect.backoff.ms
long,默认值50.
连接失败时,当我们重新连接时的等待时间。
retry.backoff.ms
long, 默认值100。
在重试发送失败的request前的等待时间,防止若目的Broker完全挂掉的情况下Producer一直陷入死循环发送,折中的方法。
metrics.sample.window.ms
long, 默认值3000
metrics系统维护可配置的样本数量,在一个可修正的window size
metrics.num.samples
int, 默认值2
用于维护metrics的样本数
metric.reporters
数组[]
类的列表,用于衡量指标。实现MetricReporter接口
metrics.log.level
metrics日志记录级别,默认info
metadata.max.age.ms
long, 默认值300000
强制刷新metadata的周期,即使leader没有变化
security.protocol
默认值PLAINTEXT
与broker会话协议,取值:LAINTEXT, SSL, SASL_PLAINTEXT, SASL_SSL
partitioner.class
默认值class org.apache.kafka.clients.producer.internals.DefaultPartitioner
分区类,实现Partitioner接口
max.block.ms
long,默认值60000
控制block的时长,当buffer空间不够或者metadata丢失时产生block
connections.max.idle.ms
long,默认值540000
设置多久之后关闭空闲连接
client.id
字符串,默认值""
当向server发出请求时,这个字符串会发送给server,目的是能够追踪请求源
retries
int,默认值0
发生错误时,重传次数。当开启重传时,需要将`max.in.flight.requests.per.connection`设置为1,否则可能导致失序
key.serializer
key 序列化方式,类型为class,需实现Serializer interface, 如:org.apache.kafka.common.serialization.StringSerializer
value.serializer
value 序列化方式,类型为class,需实现Serializer interface,如org.apache.kafka.common.serialization.StringSerializer
enable.idempotence
true为开启幂等性
transaction.timeout.ms
事务超时时间,默认60000,单位ms
transactional.id
设置事务id,必须唯一
2. 创建Kafka生产者
import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; /** * kafka生产者 */ public class KafkaProducer { public static void main(String[] args) { Properties properties = new Properties(); properties.put("bootstrap.servers", "localhost:9092"); properties.put("acks", "all"); properties.put("retries", 0); properties.put("batch.size", 16384); 1 properties.put("linger.ms", 1); properties.put("buffer.memory", 33554432); properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); org.apache.kafka.clients.producer.KafkaProducer<String, String> kafkaProducer = new org.apache.kafka.clients.producer.KafkaProducer<String, String>(properties); for (int i = 1; i <= 600; i++) { //参数1:topic名, 参数2:消息文本; ProducerRecord多个重载的构造方法 kafkaProducer.send(new ProducerRecord<String, String>("test20200519", "message"+i)); System.out.println("message"+i); } kafkaProducer.close(); } }
Kafka的生产者有如下三个必选的属性:
① bootstrap.servers,指定broker的地址清单
② key.serializer必须是一个实现org.apache.kafka.common.serialization.Serializer接口的类,将key序列化成字节数组。注意:key.serializer必须被设置,即使消息中没有指定key。
③ value.serializer,将value序列化成字节数组。
3. 发送消息到kafka
(1) 同步发送消息
Properties properties = new Properties(); properties.put("bootstrap.servers", "localhost:9092"); properties.put("acks", "all"); properties.put("retries", 0); properties.put("batch.size", 16384); properties.put("linger.ms", 1); properties.put("buffer.memory", 33554432); properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); //KafkaProducer类发送数据,kafka Producer是线程安全的,可以在多个线程之间共享生产者实例 org.apache.kafka.clients.producer.KafkaProducer<String, String> kafkaProducer = new org.apache.kafka.clients.producer.KafkaProducer<String, String>(properties); // -- 同步发送消息 for (int i = 1; i <= 600; i++) { //参数1:topic名, 参数2:消息文本; ProducerRecord多个重载的构造方法 kafkaProducer.send(new ProducerRecord<String, String>("test20200519", "message"+i)); System.out.println("message"+i); } //或者 ProducerRecord<String, String> syncRecord = new ProducerRecord<>("test20200519", "Kafka_Products", "测试"); //Topic Key Value try{ Future future = kafkaProducer.send(syncRecord); future.get();//不关心是否发送成功,则不需要这行。 } catch(Exception e) { e.printStackTrace();//连接错误、No Leader错误都可以通过重试解决;消息太大这类错误kafkaProducer不会进行任何重试,直接抛出异常 } kafkaProducer.close();
(2) 异步发送消息
Properties properties = new Properties(); properties.put("bootstrap.servers", "localhost:9092"); properties.put("acks", "all"); properties.put("retries", 0); properties.put("batch.size", 16384); properties.put("linger.ms", 1); properties.put("buffer.memory", 33554432); properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); //KafkaProducer类发送数据,kafka Producer是线程安全的,可以在多个线程之间共享生产者实例 org.apache.kafka.clients.producer.KafkaProducer<String, String> kafkaProducer = new org.apache.kafka.clients.producer.KafkaProducer<String, String>(properties); // -- 异步发送消息 ProducerRecord<String, String> asyncRecord = new ProducerRecord<String, String>("test20200519", "Kafka_Products","测试--1");//Topic Key Value kafkaProducer.send(asyncRecord, new DemoProducerCallback());//发送消息时,传递一个回调对象,该回调对象必须实现org.apache.kafka.clients.producer.Callback接口 kafkaProducer.close(); class DemoProducerCallback implements Callback{ @Override public void onCompletion(RecordMetadata recordMetadata, Exception e) { if (e != null) {//如果Kafka返回一个错误,onCompletion方法抛出一个non null异常。 e.printStackTrace();//对异常进行一些处理,这里只是简单打印出来 } } }
4. 序列化器
建议使用JSON、Apache Avro、Thrift或者Protobuf这些成熟的序列化/反序列化方案。
5. 分区
我们创建消息的时候,必须要提供主题和消息的内容,而消息的key是可选的,当不指定key时默认为null。消息的key有两个重要的作用:1)提供描述消息的额外信息;2)用来决定消息写入到哪个分区,所有具有相同key的消息会分配到同一个分区中。
如果key为null,那么生产者会使用默认的分配器,该分配器使用轮询(round-robin)算法来将消息均衡到所有分区。
如果key不为null而且使用的是默认的分配器,那么生产者会对key进行哈希并根据结果将消息分配到特定的分区。注意的是,在计算消息与分区的映射关系时,使用的是全部的分区数而不仅仅是可用的分区数。这也意味着,如果某个分区不可用(虽然使用复制方案的话这极少发生),而消息刚好被分配到该分区,那么将会写入失败。另外,如果需要增加额外的分区,那么消息与分区的映射关系将会发生改变,因此尽量避免这种情况。
6. 自定义分配器
下面将key为Banana的消息单独放在一个分区,与其他的消息进行分区隔离:
import org.apache.kafka.clients.producer.Partitioner; import org.apache.kafka.common.Cluster; import org.apache.kafka.common.InvalidRecordException; import org.apache.kafka.common.PartitionInfo; import org.apache.kafka.common.utils.Utils; import java.util.List; import java.util.Map; public class BananaPartitioner implements Partitioner { public void configure(Map<String, ?> configs) { } public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); int numPartitions = partitions.size(); if ((keyBytes == null) || (!(key instanceof String))) throw new InvalidRecordException("We expect all messages to have customer name as key"); if (((String) key).equals("Banana")) return numPartitions; // Banana will always go to last partition // Other records will get hashed to the rest of the partitions return (Math.abs(Utils.murmur2(keyBytes)) % (numPartitions - 1)); } public void close() { } }
二、kafka消费者
1. 消费者配置
group.id
字符串
消费者所属消费组的唯一标识
max.poll.records
int,默认值500
一次拉取请求的最大消息数
max.poll.interval.ms
int, 默认值300000
指定拉取消息线程最长空闲时间
session.timeout.ms
int, 默认值10000
检测消费者是否失效的超时时间
heartbeat.interval.ms
int, 默认值10000
消费者心跳时间,默认3000ms
bootstrap.servers
连接集群broker地址
enable.auto.commit
boolean, 默认值true
是否开启自动提交消费位移的功能
auto.commit.interval.ms
int,默认值5000
自动提交消费位移的时间间隔
partition.assignment.strategy
range 或 roundrobin,默认的值是range。
消费者的分区配置策略。
auto.offset.reset
字符串,默认值"latest"
如果分区没有初始偏移量,或者当前偏移量服务器上不存在时,将使用的偏移量设置,earliest从头开始消费,latest从最近的开始消费,none抛出异常
fetch.min.bytes
int,默认值1
消费者客户端一次请求从Kafka拉取消息的最小数据量,如果Kafka返回的数据量小于该值,会一直等待,直到满足这个配置大小,默认1b
fetch.max.bytes
int,默认值50*1024*1024,即50MB
消费者客户端一次请求从Kafka拉取消息的最大数据量
fetch.max.wait.ms
int,默认500。
从Kafka拉取消息时,在不满足fetch.min.bytes条件时,等待的最大时间
metadata.max.age.ms
强制刷新元数据时间,毫秒,默认300000,5分钟
max.partition.fetch.bytes
int,默认1*1024*1024,即1MB
设置从每个分区里返回给消费者的最大数据量,区别于fetch.max.bytes。
send.buffer.bytes
int,默认128*1024
Socket发送缓冲区大小,默认128kb,-1将使用操作系统的设置
receive.buffer.bytes
Socket发送缓冲区大小,默认64kb,-1将使用操作系统的设置
client.id
消费者客户端的id
reconnect.backoff.ms
连接失败后,尝试连接Kafka的时间间隔,默认50ms
reconnect.backoff.max.ms
尝试连接到Kafka,生产者客户端等待的最大时间,默认1000ms
retry.backoff.ms
消息发送失败重试时间间隔,默认100ms
metrics.sample.window.ms
样本计算时间窗口,默认30000ms
metrics.num.samples
用于维护metrics的样本数量,默认2
metrics.log.level
metrics日志记录级别,默认info
metric.reporters
类的列表,用于衡量指标,默认空list
check.crcs
boolean,默认true
自动检查CRC32记录的消耗
key.deserializer
key反序列化方式
value.deserializer
value反序列化方式
connections.max.idle.ms
设置多久之后关闭空闲连接,默认540000ms
request.timeout.ms
客户端将等待请求的响应的最大时间,如果在这个时间内没有收到响应,客户端将重发请求,超过重试次数将抛异常,默认30000ms
default.api.timeout.ms
设置消费者api超时时间,默认60000ms
interceptor.classes
自定义拦截器
exclude.internal.topics
内部的主题:一consumer_offsets 和一transaction_state。该参数用来指定 Kafka 中的内部主题是否可以向消费者公开,默认值为 true。如果设置为 true,那么只能使用 subscribe(Collection)的方式而不能使用 subscribe(Pattern)的方式来订阅内部主题,设置为 false 则没有这个限制。
isolation.level
用来配置消费者的事务隔离级别。如果设置为“read committed”,那么消费者就会忽略事务未提交的消息,即只能消 费到 LSO (LastStableOffset)的位置,默认情况下为 “read_uncommitted”,即可以消 费到 HW (High Watermark)处的位置
2. 创建kafka消费者
import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import java.time.Duration; import java.util.Arrays; import java.util.Properties; /** * kafka消费者 */ public class KafkaConsumer { public static void main(String[] args) { Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", "test"); props.put("enable.auto.commit", "true"); props.put("auto.commit.interval.ms", "1000"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("auto.offset.reset","earliest"); //KafkaConsumer类不是线程安全的 org.apache.kafka.clients.consumer.KafkaConsumer<String, String> consumer = new org.apache.kafka.clients.consumer.KafkaConsumer<>(props); consumer.subscribe(Arrays.asList("test20200519")); try{ while (true) { //拉取消息 ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000)); for (ConsumerRecord<String, String> record : records) { System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value()); } } }finally{ consumer.close(); } } }
3. kafka多线程消费
kafka的KafkaConsumer不是线程安全的,必须保证只能被一个线程操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号