ElasticSearch - 常用 API
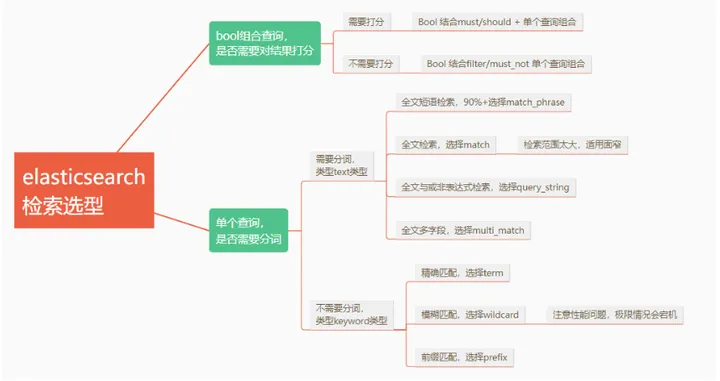
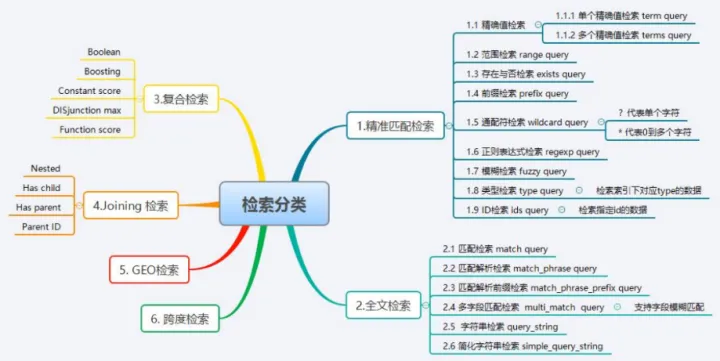
前言
本文示例以 ElasticSearch 8.6.2 版本演示,更详细的 API 参数及用法请参考官方文档。测试命令我用的是 Kibana,在输入时会有命令和语法错误提示,可直接复制 CURL 格式、格式化、查看文档,点击导航栏上面的 help,也提供了一些快捷方式,方便学习。
- 索引(index):等同于mysql的表(table)
- 文档(Document):等同于mysql的行(row)
- 字段(field):等同于mysql的字段(column)
一、索引
1.索引是否存在
语法:
HEAD <index>
实例:
HEAD test7
//存在返回:
200 - OK//不存在返回:
{ "statusCode": 404, "error": "Not Found", "message": "404 - Not Found" }
2.创建索引
创建文档时如果索引不存在也会自动创建索引。
语法:
PUT <index> { "aliases": {}, # 别名 "mappings": {}, # 映射 "settings": {}, # 配置 }路径参数:
<index>(必需,字符串)要创建的索引的名称。请求体:
<aliases>(可选,对象的对象)索引的别名。
<mappings>(可选,映射对象)索引中字段的映射。如果指定时,此映射可以包括:
字段名称
字段数据类型
映射参数
索引名称必须满足以下条件:
- 仅小写
- 不能包含 \, /,*,?, ",<,>,|, (空格),,,#
- 7.0 之前的索引可能包含 : ,但该冒号已弃用,在 7.0+ 中不受支持
- 不能以 _ ,-,+ 开头
- 不能是 . 或 ..
- 不能超过 255 字节(请注意它是字节,因此多字节字符将更快地计入 255 限制)
- 以 . 开头的名称已被弃用,隐藏索引和插件管理的内部索引除外.
测试:
//请求:
PUT /test7
{
//映射
"mappings": {
"properties": {
//字段名
"name":{
//字段类型
"type": "text"
},
"age":{
"type": "byte"
},
"addr":{
"type": "text",
//分词器(插入数据时使用细分词)
"analyzer": "ik_max_word",
//查询分词器(查询时使用粗分词)
"search_analyzer": "ik_smart"
}
}
}
}
//返回:
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "test"
}
//请求:
GET test
//返回:
{
"test": {
"aliases": {},
"mappings": {},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "1",
"provided_name": "test",
"creation_date": "1677306509277",
"number_of_replicas": "1",
"uuid": "tXKSzCSUQNWxnDhqeBrLeA",
"version": {
"created": "8060299"
}
}
}
}
}
2.1 alias别名
ES 的 aliases(别名) 就类似数据库的视图,我们为索引 test 创建一个别名 test_alias,这样我们对 test_alias 的操作就像对 test 的操作一样。
//请求:
第一种方式:
POST _aliases
{
"actions": [
{
"add": {
"index": "test",
"alias": "测试"
}
}
]
}
第二种方式:
PUT /test/_alias/测试2
//返回:
{
"acknowledged": true
}
//查看别名索引
`GET _cat/aliases`
//返回
.kibana-event-log-8.4.1 .kibana-event-log-8.4.1-000011 - - - false
.kibana .kibana_8.4.1_001 - - - -
.kibana_8.4.1 .kibana_8.4.1_001 - - - -
测试 test - - - -
.kibana_task_manager .kibana_task_manager_8.4.1_001 - - - -
.kibana_task_manager_8.4.1 .kibana_task_manager_8.4.1_001 - - - -
.kibana_security_session .kibana_security_session_1 - - - true
.kibana-event-log-8.4.1 .kibana-event-log-8.4.1-000012 - - - false
.kibana-event-log-8.4.1 .kibana-event-log-8.4.1-000013 - - - false
.kibana-event-log-8.4.1 .kibana-event-log-8.4.1-000014 - - - true
.security .security-7 - - - -
.security-profile .security-profile-8 - - - -
- 别名不仅仅可以关联一个索引,它能聚合多个索引,也可对于同一个index,给不同人看到不同的数据,假设 test 有个字段是 team,team 字段记录了该数据是哪个人添加的,设置别名可以使不同人之间的 team 数据是不可见的。
- 多个索引可设置同个别名(即使索引的映射不同),搜索时多个索引的文档将合并
- 一个索引可设置多个别名
可参考:Elasticsearch基础11——索引之别名使用
2.2 mappings映射
ES 的 mappings(映射) 相当于数据库中的表结构,对表的字段类型长度索引做设置,而在 ES 中 映射是定义一个文档和它所包含的字段如何被存储和索引的过程,分为 自动映射(Dynamic mapping) 和 显式映射(Explicit mapping)。
动态映射:
- 动态映射允许您试验 并在刚开始时探索数据。Elasticsearch 添加了新字段 自动,只需为文档编制索引即可。您可以将字段添加到顶级 映射,以及内部对象和嵌套字段。
- 使用动态模板定义自定义映射,这些映射是 应用于基于匹配条件动态添加的字段。
显式映射:
显式映射允许您精确选择如何 定义映射定义,例如:
- 哪些字符串字段应被视为全文字段。
- 哪些字段包含数字、日期或地理位置。
- 日期值的格式。
- 用于控制动态添加字段映射的自定义规则。
使用运行时字段进行架构更改,而无需 重新索引。可以将运行时字段与索引字段结合使用,以 平衡资源使用情况和性能。您的索引会更小,但 搜索性能较慢。
注:在ElasticSearch中一旦创建了映射是不被允许进行修改的,因为对于数据存储、分析、检索,都是按照mapping 中的配置进行的,如果前期 根据 mapping存储好了之后,又对 mapping 进行更改,那么就会导致前面存储的数据和后面的检索策略后面的存储 数据不一致的情况,导致检索行为不准确。 只能在创建index 的时候手动配置 mapping,或者新增 fieId mapping。
映射字段类型:
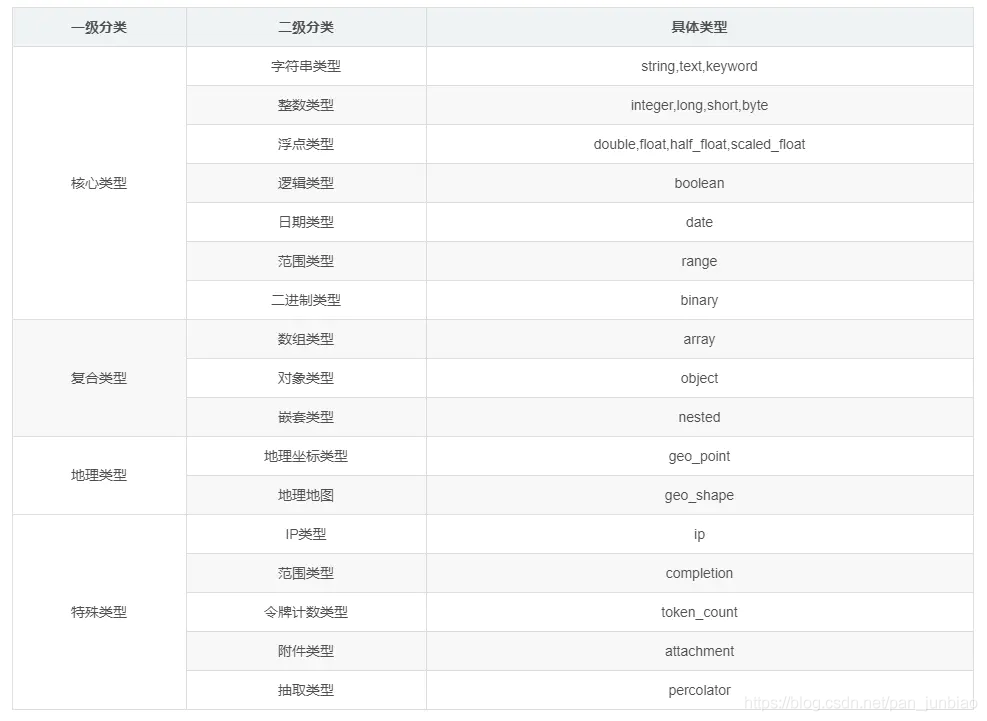
//请求:
POST test/_doc/_mapping
{
"properties":{
"id":{
"type":"long"
},
"name":{
"type":"keyword"
}
}
}
//返回:
{
"_index": "test",
"_id": "_mapping",
"_version": 1,
"result": "created", # 创建成功
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
//请求:
GET test/_mapping
//返回:
{
"test": {
"mappings": {
"properties": {
"id": {
"type": "long"
},
"name": {
"type": "keyword"
}
}
}
}
}
2.3 settings配置
索引的配置项可以分为静态配置与动态配置,所谓的静态配置即索引创建后不能修改。
index.number_of_shards:索引分片的数量。在ES层面可以通过es.index.max_number_of_shards属性设置索引最大的分片数,默认为1024,index.number_of_shards的默认值为Math.min(es.index.max_number_of_shards,5),故通常默认值为5。index.shard.check_on_startup:分片在打开之前是否应该检查该分片是否损坏。当检测到损坏时,它将阻止分片被打开。可选值:false:不检测;checksum:只检查物理结构;true:检查物理和逻辑损坏,相对比较耗CPU;fix:类同与false,7.0版本后将废弃。默认值:false。index.codec:数据存储的压缩算法,默认值为LZ4,可选择值best_compression ,比LZ4可以获得更好的压缩比(即占据较小的磁盘空间,但存储性能比LZ4低)。index.routing_partition_size:路由分区数,如果设置了该参数,其路由算法为:(hash(_routing) + hash(_id) % - index.routing_parttion_size ) % number_of_shards。如果该值不设置,则路由算法为 hash(_routing) % number_of_shardings,_routing默认值为_id。
更多参数可参考配置
//查询配置
GET /test/_settings
3、查看索引
语法:
GET /<index> # 查看指定索引信息
GET _cat/indices?v # 查看所有索引 ?V即返回结果带标题
4、删除索引
语法:
DELETE <index>
四、文档(Document) API
1、查询文档是否存在
HEAD <index>/_doc/<_id>
HEAD <index>/_source/<_id>
2、索引文档
索引文档就是创建文档,这里的索引表示创建文档这个动作。
语法:
PUT /<target>/_doc/<_id>
POST /<target>/_doc/<_id>
PUT /<target>/_create/<_id>
POST /<target>/_create/<_id>
路径参数:
<target>(必需,字符串)目标数据流或索引的名称。
<_id>可选,字符串)文档的唯一标识符。省略此参数会自动生成文档 ID。
示例:
//请求:
POST test/_doc/1
{
"id":"1",
"name":"张三",
"age":20
}
//返回:
{
"_index": "test", # 文档所在索引
"_id": "1", # 文档ID,这是ES 的文档ID 和 源数据中的id关联需要业务维护
"_version": 1, # 版本
"result": "created", # 执行结果 - 成功
"_shards": { # 分片
"total": 2, # 分片总数 - 一主一副
"successful": 1, # 正常运行的分片数量,因为是单机,主副分片在一起,只会使用主分片
"failed": 0 # 失败数量,副分片没用到并不是运行失败,主副分片本就是为了数据冗余而存在的,单机的话副分片就用不到了,宕机一起死
},
"_seq_no": 1, # _seq_no是严格递增的顺序号,每个文档一个,Shard级别严格递增,保证后写入的Doc的_seq_no大于先写入的Doc的_seq_no。任何类型的写操作,包括index、create、update和Delete,都会生成一个_seq_no。
"_primary_term": 1 # _primary_term主要是用来恢复数据时处理当多个文档的_seq_no一样时的冲突,比如当一个shard宕机了,raplica需要用到最新的数据,就会根据_primary_term和_seq_no这两个值来拿到最新的document
}
//测试:
POST test/_doc
{
"id":"2",
"name":"李四",
"age":22
}
//返回:
{
"_index": "test",
"_id": "Ra20kIYBD3T716opayt9", # 自动生成的文档ID
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1
}
注:
- 如果创建文档时索引不存在,那么在第一次创建文档的时候会自动创建对应索引。
- 如果指定id的文档已存在,则执行更新文档操作
3、获取文档
语法:
# 获取索引下所有文档
GET /<index>/_search
# 获取指定文档
GET <index>/_doc/<_id>
GET <index>/_source/<_id>
路径参数:
<index>(必需,字符串)包含文档的索引的名称。
<_id>(必需,字符串)文档的唯一标识符。
GET <index>/_source/<_id>/?_source_includes=*.id&_source_excludes=entities
查询参数详细用法参考官网(https://www.elastic.co/guide/en/elasticsearch/reference/8.6/docs-get.html#docs-get-api-prereqs)
3.1、元数据
这里关于获取文档返回信息中的参数叫做元数据:
- _index:文档所属索引的名称。
- _id:文档的唯一标识符。
- _version:文档版本。每次更新文档时递增。
- _seq_no:分配给文档以编制索引的序列号 操作。序列号用于确保文档的较旧版本 不会覆盖较新的版本。请参阅 乐观并发控制。
- _primary_term:为索引操作分配给文档的主要术语。 请参阅 乐观并发控制。
found:指示文档是否存在:true 或 false。 - _source:如果 found 是 true,则包含以 JSON 格式设置的文档数据。如果 _source 参数设置为 false 或 stored_fields 参数设置为 true,则排除。
注意:元数据和源数据不要搞混了,源数据是元数据 _source 下的内容,就是我们存到 ES 中的信息。
测试:
//请求:
GET /test2/_doc/byrYSosBGsVgU79kxURn
//返回:
{
"_index": "test2",//索引
"_id": "byrYSosBGsVgU79kxURn",//文档ID
"_version": 1,//版本号
"_seq_no": 1,//顺序号 _seq_no和_primary_term 共同用于版本控制
"_primary_term": 1,//编号
"found": true,//是否找到
"_source": {//源数据,存到ES中的数据
"id": "2",
"name": "李四",
"age": 22
}
}
查询索引下全部文档
//请求:
GET /test/_search
//返回
{
"took": 2,//花费了2毫秒的时间
"timed_out": false,//未超时
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "test",
"_id": "1",
"_score": 1,
"_source": {
"name": "黎明",
"age": "20",
"addr": "香港"
}
}
]
}
}
返回的结果中存在一些参数:
- took:代表ES执行搜索花费的时间(毫秒),"took" :2就代表上述的搜索;
- timed_out:表示搜索是否超时;
- _shards:其中total表示总共搜索了多少碎片,successful/failed表示成功/失败搜索的碎片数量;
- hits:搜索结果;
- hits.total:表示符合搜索条件的documnet的总数量;
- hits.sort:对结果进行排序(如果按分数排序则丢失);
- hits.max_score:最大得分,代表文档最大匹配度
- hits.hits:实际搜索结果的返回值数组(默认只有前10个document的结果);
- hits.hits._score: 得分,代表文档匹配度
4、修改文档
官方提供 Update API 实际上是局部更新,能够编写文档更新脚本。要完全替换现有文档,则使用 索引文档API。
4.1、局部更新
更新API支持传递合并到现有文档中的部分文档。
更新API 还能够编写文档更新脚本,脚本可以更新、删除或跳过修改文档。
语法:
POST /<index>/_update/<_id>
路径参数:
<index>(必需,字符串)包含文档的索引的名称。
<_id>(必需,字符串)文档的唯一标识符。
请求体:
doc:修改信息。
script:脚本内容。
测试:
修改源数据:
//请求:
POST /test/_update/1
{
"doc": {
"name":"老二",
"age":22
}
}
执行脚本测试(年龄加10):
//请求:
POST test/_update/1
{
"script" : {
//通过脚本更新制定字段,其中ctx是脚本语言中的一个执行对象,先获取_source,再修改age字段
"source": "ctx._source.age+= params.add",
"lang": "painless",//指定编写脚本的语言,默认为painless,6.0 开始,ES 只支持 Painless。
"params" : {
"add" : 10
}
}
}
//请求:
GET test2/_source/1
//返回:
{
"id": "1",
"name": "老二",
"age": 32
}
4.2、全量更新
和新增文档一样,如果请求体变化,会将原有的数据内容覆盖。
//请求:
POST test2/_doc/1
{
"name":"张三"
}
5、删除文档
DELETE /<index>/_doc/<_id>
//请求:
DELETE test2/_doc/1
//返回:
{
"_index": "test",
"_id": "1",
"_version": 10,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 11,
"_primary_term": 1
}
//请求:
GET test2/_doc/1
//返回:
{
"_index": "test",
"_id": "1",
"found": false
}
五、搜索(Search) API
Search API 执行搜索查询并返回与查询匹配的搜索命中。可以使用 查询字符串参数 或 请求体 提供搜索查询。
GET /<target>/_search
GET /_search
POST /<target>/_search
POST /_search
路径参数:
<target>
(可选,字符串)以逗号分隔的数据流、索引和别名列表 搜索。支持通配符 ()。省略则搜索所有数据流和索引。
部分查询参数(更多参考)
- q:(可选,字符串)使用Lucene查询字符串语法进行查询。您可以使用q参数来运行查询参数搜索。查询参数搜索不支持完整的Elasticsearch查询DSL,但便于测试。
- from:(可选,整数)起始文档偏移量。需要为非负,默认值为0。默认情况下,使用from和size参数,页面浏览次数不能超过10000次。要浏览更多点击,请使用search_after参数。
- size:(可选,整数)定义要返回的命中数。默认值为 10。默认情况下,使用from和size参数,页面浏览次数不能超过10000次。要浏览更多点击,请使用search_after参数。
- sort:(可选,字符串)以逗号分隔的<field>:<direction>对列表。
- _source:(可选) (可选)指示为匹配的文档返回哪些源字段。这些字段在命中时返回_搜索响应的源属性。默认为true。请参见源过滤。
- true:(布尔值)返回整个文档源。
- false:(布尔值)不返回文档源。
- <string>:(string)要返回的源字段的逗号分隔列表。支持通配符(*)模式。
- timeout:(可选,时间单位)指定等待每个碎片响应的时间段。如果在超时到期之前没有收到响应,则请求失败并返回错误。默认为无超时。
- version:(可选,布尔值)如果为true,则返回文档版本作为命中的一部分。默认为false。
1.Query参数查询 与 请求体查询
//请求:
GET /test/_search?q=name:黎明
//请求:
GET /test/_search?q=name:黎明&from=0&size=2&_source=name
{
"_index": "test",
"_id": "1",
"_score": 1.5098253,
"_source": {
"name": "黎明" //_source 限制返回字段
}
}
match_all:等同于上面的空查询,没有任何条件,最简单的查询,它匹配所有文档就相当于空搜索
//请求:
GET test/_search
{
"query":{
"match_all":{}
}
}
2、单条件筛选
首先我们需要知道 ES 中默认使用分词器为标准分词器(StandardAnalyzer),标准分词器对于英文单词分词 ,对于中文单字分词。
在 ES 的 映射类型(Mapping Type)中keyword,date,integer,long,double,boolean or ip 这些类型不分词,只有 text类型分词。
2.1、匹配关键字
2.1.1、短语模糊匹配
match:先对搜索词进行分词,分词完毕后再逐个对分词结果进行匹配,因此相比于 term 的精确搜索,match 是分词匹配搜索,相当于模糊匹配,只包含其中一部分关键词就行 。
注意:这里的
match和 下面的match_pharse查询都是属于全文查询,全文查询会给当前的句子进行分词
GET /dede-admin-log/_search
{
"query":{
"match":{
"content":{
"query":"重启",
"operator": "and"
}
}
}
}
2.1.2、短语精确匹配
match_phrase :短语匹配查询,要求必须全部精确匹配,且顺序必须与指定的短语相同。首先解析查询字符串来产生一个词条列表,然后会搜索所有的词条,但只保留包含了所有搜索词条的文档。match_phrase 还支持词条列表各词项间隔距离多少的设置。
GET /dede-admin-log/_search
{
"query": {
"match_phrase": {
"content": {
"query": "设备韩国",
"slop": 10//Slop参数定义了短语中允许的词项之间的最大距离。默认为0,表示必须照指定的顺序连续出现。
}
}
}
}
2.1.3、关键词精确匹配
term:单词或单字精确匹配,只是查分词,不会对查询语句进行分词,所以会区分大小写。同Mysql的"="
terms:多个 term 的并集。同Mysql的where in
GET dede-admin-log/_search
{
"query":{
"term": {
"content.keyword": "登录"
}
}
}
GET dede-admin-log/_search
{
"query":{
"terms": {
"content.keyword": ["登录","登出"]
}
}
}
2.1.4、多字段查询
multi_match 查询提供了一个简便的方法用来对多个字段执行相同的查询。
同mysql的多字段搜索 name|address => '韩'
GET /test/_search
{
"query": {
"multi_match": {
"query": "韩",
"fields": ["name","address"]
}
}
}
2.1.5通配符查询
wildcard:ES中可以实现通配符搜索,通配符匹配也是扫描完整索引,通配符可以在 索引中使用,也可以在 keyword中使用。
ElsticSearch支持的通配符有2个,分别是:
*:0个或多个任意字符
?:任意单个字符
注意: 为了防止极慢的通配符匹配,查询字符串不要以通配符开头,只在查询字符串中间或末尾使用通配符。
GET dede-admin-log/_search
{
"query": {
"wildcard": {
"content.keyword": {
"value": "添加设备池*"
}
}
}
}
2.2、范围查询
2.2.1、数字范围
range 查询可同时提供包含(inclusive)和不包含(exclusive)这两种范围表达式,可供组合的选项如下:
- gt: > 大于(greater than)
- lt: < 小于(less than)
- gte: >= 大于或等于(greater than or equal to)
- lte: <= 小于或等于(less than or equal to)
GET dede-admin-log/_search
{
"query":{
"range": {
"id": {
"gte": 10000,
"lte": 11000
}
}
}
}
2.2.2、日期范围
range 查询同样可以应用在日期字段上:
GET dede-admin-log/_search
{
"query":{
"range": {
"create_time": {
"gte": "2022-11-09",
"lte": "2022-11-09"
}
}
}
}
2.3、多id查询
根据 ID 返回文档。此查询使用存储在 _id 字段中的文档 ID。
GET dede-admin-log/_search
{
"query":{
"ids":{
"values": ["1Sv9pIwBGsVgU79kyMUO","1Cv9pIwBGsVgU79kyMUO"]
}
}
}
3、多条件筛选(高级查询)
3.1 布尔查询
bool 查询:可以实现你的需求。这种查询将多查询组合在一起,成为用户自己想要的布尔查询。它接收以下参数:
must:文档必须匹配这些条件才能被包含进来。must_not:文档必须不匹配这些条件才能被包含进来。should:如果满足这些语句中的任意语句,将增加 _score ,否则,无任何影响。它们主要用于修正每个文档的相关性得分。filter:必须 匹配,但它以不评分、过滤模式来进行。这些语句对评分没有贡献,只是根据过滤标准来排除或包含文档。
GET /dede-admin-log/_search
{
"query": {
"bool": {
"must": [
{ "match": { "content": "添加" }} //内容必须包含 添加
],
"must_not": [
{ "match": { "content": "设备池" }}//内容不能包含 设备池
],
"should": [
{ "term": { "content": "代理" }} //内容包含 代理 的score增加,排序靠前
],
"filter": [
{ "range": { "id": { "gte": "10000" }}}//过滤筛选出id大于10000的数据
]
}
}
}
4.指定字段
_source :指定返回的源数据字段。 等同tp的field
GET dede-admin-log/_search
{
"_source": ["index","content"]
}
5、高亮查询
如果返回的结果集中很多符合条件的结果,那怎么能一眼就能看到我们想要的那个结果呢?比如像百度所示的那样,将搜索词高亮显示:
5.1、默认高亮显示
highlight:ES 会从查询到的数据中,找到匹配的短语或关键字词,并以 标签包裹起来。
GET dede-admin-log/_search
{
"query": {
"match_phrase": {
"content": "设备池"
}
},
"highlight": {
"fields": {
"content": {}
}
}
}
5.2、自定义高亮html标签
ES 可以在 highlight 中使用 pre_tags 和 post_tags 来自定义匹配内容前后高亮的html标签。
GET dede-admin-log/_search
{
"query": {
"match_phrase": {
"content": "设备池"
}
},
"highlight": {
"pre_tags": "<b style='color:red'>",
"post_tags": "</b>",
"fields": {
"content": {}
}
}
}
6、排序
sort:指定字段排序方式。
GET dede-admin-log/_search
{
"sort": {
"id": {
"order": "desc"
}
}
}
7、分页
from:起始数据位置。
size:返回数据数量。
ES 分页查询限制总数能不超过10000,如果查询超过1W的数据,可以将from赋值为大于1W的值,不过from越大,效率越低,效果同MySql的limit
{
"from": 0, # 0 开始
"size": 2 # 获取两条数据
}
六、批量操作(Mget、Bulk) API
_mget:可以同时执行不同的 get 操作,多个API操作之间的结果互不影响。
6.1 批量查询
6.1.1 相同索引
//请求:
GET dede-admin-log/_mget
{
"docs":[
{
"_id": "LCz9pIwBGsVgU79k2gRo"
},
{
"_id": "Kyz9pIwBGsVgU79k2gRo"
}
]
}
//如果是查詢id,也可以使用一下方法
GET dede-admin-log/_mget
{
"ids": ["LCz9pIwBGsVgU79k2gRo","Kyz9pIwBGsVgU79k2gRo"]
}
6.1.2 不同索引
GET /_mget
{
"docs":[
{
"_index":"dede-admin-log",
"_id": 1
},
{
"_index":"dede-client-log",
"_id": 1
}
]
}
6.2 批量修改
_bulk:可以同时执行不同的CUD操作,多个API操作之间的结果互不影响
bulk request会加载到内存中,如果太大的话,性能反而下降,因此需要反复尝试一个最大的 bulk size。一般从1000~5000条数据开始,尝试逐渐增加。另外,如果看大小的话,最好在5M。
POST /_bulk
{"create":{"_index":"dede-admin-log","_id":"1"}}
{"doc":{"id":999999,"content":"添加测试"}}
{"update":{"_index":"dede-admin-log","_id":"LCz9pIwBGsVgU79k2gRo"}}
{"doc":{"content":"更新测试"}}
{"delete":{"_index":"dede-admin-log","_id":"Kyz9pIwBGsVgU79k2gRo"}}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号