ElasitcSearch - 倒序索引
转载自:https://blog.csdn.net/qq_31960623/article/details/118860928
简介
ElasticSearch引擎把文档数据写入到倒排索引(Inverted Index)的数据结构中,倒排索引建立的是分词(Term)和文档(Document)之间的映射关系,在倒排索引中,数据是面向词(Term)而不是面向文档的。
倒排索引(Inverted Index)也叫反向索引,有反向索引必有正向索引。通俗地来讲,正向索引是通过key找value,反向索引则是通过value找key。
原理
搜索的核心需求是全文检索,全文检索简单来说就是要在大量文档中找到包含某个单词出现的位置。
传统搜索
在传统关系型数据库中,数据检索只能通过 like 来实现。例如,如果需要查询名称中包含公寓的酒店的酒店数据,则需要使用如下sql来实现:
select * from hotel_table where hotel_name like '%公寓%';
这种实现方式实际会存在很多问题:
- 无法使用数据库索引,需要全表扫描,性能差
- 搜索效果差,只能首尾位模糊匹配,无法实现复杂的搜索需求
- 无法得到文档与搜索条件的相关性
倒排索引
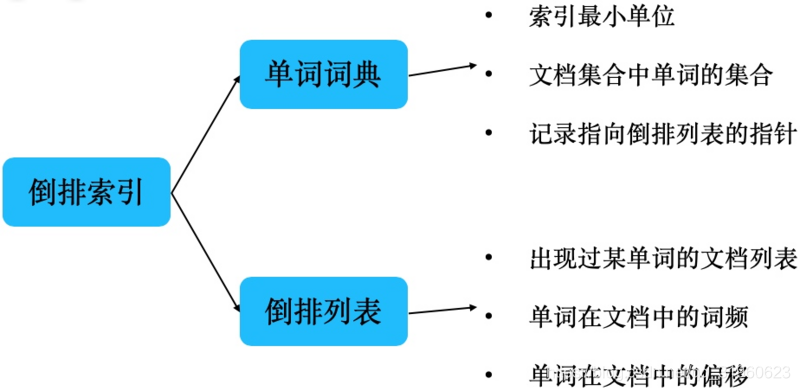
倒排索引(Inverted Index):每个文档都对应一个ID,倒排索引会按照指定语法对每一个文档进行分词,然后维护一张表,列举所有文档中出现的terms以及它们出现的文档ID和出现频率,它是实现"单词-文档矩阵"的一种具体存储形式。倒排索引主要由两部分组成:“单词词典"+"倒排文件”。
简单的来讲:正序索引是根据key找value,而倒序索引是根据value找key。
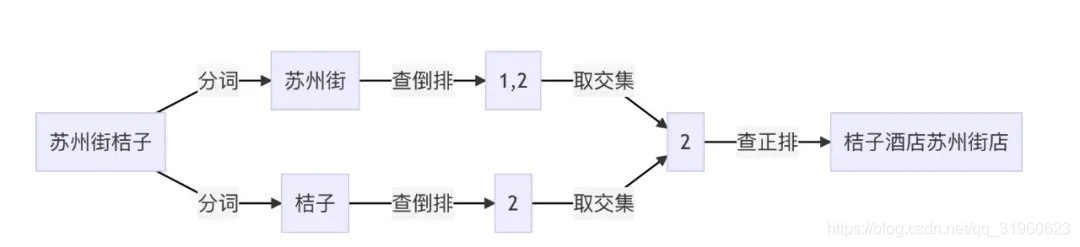
假设目前有以下两个文档内容:
* 苏州街维亚大厦
* 桔子酒店苏州街店
其处理步骤如下:
1、正排索引给每个文档进行编号,作为其唯一的标识。
| 文档id | content |
|---|---|
| 1 | 苏州街维亚大厦 |
| 2 | 桔子酒店苏州街店 |
2、生成倒排索引
首先要对字段的内容进行分词,分词就是将一段连续的文本按照语义拆分为多个单词,然后按照单词来作为索引,对应的文档 id 建立一个链表,就能构成上述的倒排索引结构。
| Word | 文档 id |
|---|---|
| 苏州街 | 1,2 |
| 维亚大厦 | 1 |
| 维亚 | 1 |
| 桔子 | 2 |
| 酒店 | 2 |
| 大赛 | 1 |
例如,如果需要在上述两个文档中查询 苏州街桔子 ,可以通过分词后 苏州街 查到 1、2,通过 桔子 查到 2,然后再进行取交取并等操作得到最终结果。
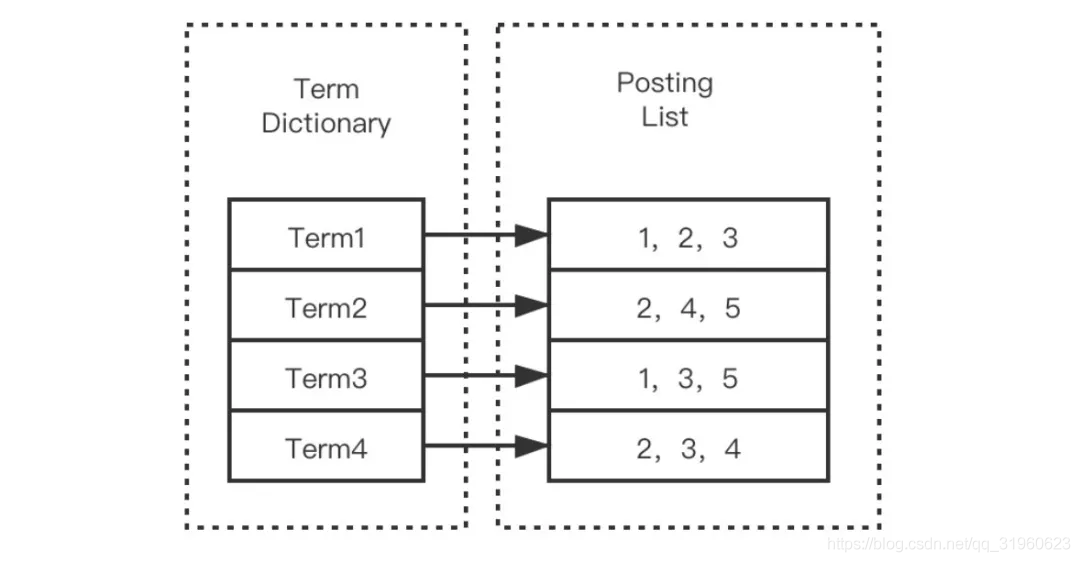
结构
-
单词 (Term): 连续文本通过分词器拆分多个单词
-
索引表(Term Dictionary,可简称为 Dictionary): 一系列的 Term 组成索引表
-
文档 id(DocId, Document Id):包含单词的所有文档唯一id,用于去正排索引中查询原始数据。
-
词频(TF,Term Frequency):记录 Term 在每篇文档中出现的次数,用于后续相关性算分。
-
位置(Position):记录 Term 在每篇文档中的分词位置(多个),用于做词语搜索(Phrase Query)。
-
偏移(Offset):记录 Term 在每篇文档的开始和结束位置,用于高亮显示等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号