

rag 召回怎么做的
在 RAG(Retrieval-Augmented Generation,检索增强生成)中,召回(Retrieval)是核心环节之一,其目标是从海量知识库(如文档、数据库、网页等)中快速、准确地找到与用户查询(Query)最相关的候选内容(如文档片段、句子、段落),为后续的生成模型(LLM)提供 “参考资料”。召回的质量直接影响 RAG 的最终效果 —— 召回不足会导致生成内容缺乏依据,召回冗余则会增加模型处理负担并引入噪声。
RAG 召回的核心流程
召回的本质是 “从知识库中筛选与查询相关的候选内容”,核心流程可拆解为以下步骤:
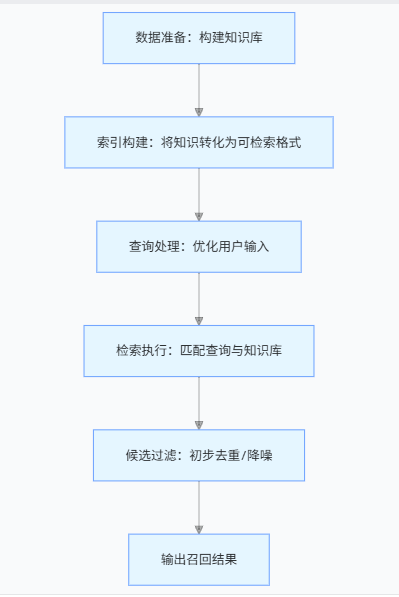
一、数据准备:构建结构化知识库
召回的前提是有高质量的知识库,需先对原始数据(如 PDF、Word、网页文本等)进行预处理,使其适合检索:
-
文档分块(Chunking)
原始文档通常篇幅较长(如一篇论文、一本手册),直接作为检索单元会导致精度低(部分内容相关但整体不相关)。需将文档拆分为更小的 “语义单元”(Chunk),常见策略包括:- 固定长度分块:按字符数 / 词数拆分(如每 200 字一个 Chunk),简单但可能割裂语义。
- 语义分块:基于段落、章节、标点(如句号、换行)或 NLP 技术(如语义连贯性检测)拆分,确保每个 Chunk 内部语义完整(例:按 “段落边界”“主题切换” 拆分)。
- 层次分块:先拆大 Chunk(如章节),再拆小 Chunk(如段落),支持多粒度检索。
-
文本清洗与增强
去除无关信息(如格式符号、广告、重复内容),补充元数据(如文档来源、发布时间、作者、标签),或提取关键信息(如实体、摘要、关键词),提升后续检索的精准度。
例:对法律文档分块后,为每个 Chunk 标注 “法条编号”“适用场景” 等元数据,方便按场景检索。 -
知识库存储
将分块后的文本及元数据存储到可高效检索的介质中(如向量数据库、关系型数据库、搜索引擎),支持后续快速查询。
二、索引构建:将知识转化为 “可检索格式”
索引是召回的 “加速器”,通过将文本转化为机器可快速比对的格式(如向量、关键词索引),避免对全量知识库进行逐字扫描。常见索引类型包括:
1. 向量索引(主流选择)
基于Embedding(嵌入)技术,将文本(Chunk 或 Query)转化为高维向量(如 768 维、1024 维),向量的距离(如余弦相似度、欧氏距离)代表文本语义的相关性。
- 核心步骤:
- 用预训练 Embedding 模型(如 BERT、Sentence-BERT、MiniLM、LLaMA 等)将每个 Chunk 转化为向量(“Chunk 向量”),存储到向量数据库(如 Milvus、Pinecone、Weaviate、Qdrant)中。
- 向量数据库会构建特殊索引(如 IVF、HNSW、FAISS 等)加速向量相似度搜索,避免暴力计算。
- 优势:擅长捕捉语义相关性,能处理 “同义词替换”“句式变换” 等查询(例:Query “如何理赔医疗险” 可召回 Chunk “医疗险赔付流程说明”)。
- 不足:对长文本的 Embedding 可能丢失细节,且向量计算成本较高。
2. 倒排索引(传统文本检索核心)
基于关键词匹配,记录 “关键词→包含该词的 Chunk 列表” 的映射关系,是搜索引擎(如 Elasticsearch)的核心技术。
- 核心步骤:
- 对每个 Chunk 进行分词(如中文用 Jieba、英文用 NLTK),提取关键词(过滤停用词 “的、是、在” 等),记录关键词在 Chunk 中的出现频率(TF)、文档频率(IDF)等。
- 构建 “关键词→ChunkID→位置 / 权重” 的倒排表,检索时直接通过关键词匹配定位相关 Chunk。
- 优势:速度快、成本低,适合精确关键词查询(例:Query “2023 年医保新政” 可快速匹配含 “医保新政 2023” 的 Chunk)。
- 不足:依赖字面匹配,难以处理语义相关但关键词不同的查询(例:Query “感冒报销流程” 无法召回含 “上呼吸道感染赔付步骤” 的 Chunk)。
3. 混合索引(兼顾语义与关键词)
结合向量索引和倒排索引的优势,常见策略:
- 先关键词过滤,再向量精排:用倒排索引快速过滤含核心关键词的 Chunk,再用向量索引计算语义相似度排序。
- 向量 + 关键词融合检索:同时计算向量相似度和关键词匹配分数,加权后排序(例:Elasticsearch 的 “dense_vector + text” 混合检索)。
三、查询处理:优化用户输入
用户的原始查询(Query)可能存在模糊、口语化、冗余等问题(如 “我想知道买了重疾险之后生病怎么报销”),需先预处理以提升检索精度:
- 分词与清洗
对 Query 分词(如中文 “重疾险 生病 报销”),去除停用词、修正错别字(如 “报消”→“报销”)。 - 查询扩展(Query Expansion)
补充与 Query 语义相关的词汇,扩大召回范围:- 同义词扩展:用词典或 Embedding 模型找到同义词(如 “报销”→“赔付、理赔”)。
- 实体链接:识别 Query 中的实体(如 “重疾险”→链接到 “重大疾病保险” 术语),补充实体属性(如 “保障范围、理赔条件”)。
- 历史上下文扩展:结合对话历史(如多轮对话中前序问题)优化当前 Query(例:用户前问 “重疾险种类”,当前问 “怎么报”→扩展为 “重疾险怎么报销”)。
- 查询压缩
去除冗余信息,保留核心语义(如 “我最近买了一份重疾险,想问问如果之后生病住院了怎么报销流程”→压缩为 “重疾险 生病住院 报销流程”)。
四、检索执行:匹配查询与知识库
根据索引类型选择对应的检索算法,从知识库中找出候选 Chunk:
1. 基于向量索引的检索
- 将预处理后的 Query 通过 Embedding 模型转化为向量(“Query 向量”)。
- 在向量数据库中通过近似最近邻搜索(ANN) 算法(如 HNSW、IVF-Flat)快速找到与 Query 向量距离最近的 Top N 个 Chunk 向量(如 Top 20)。
- 优势:能捕捉语义相关性,适合模糊查询、跨表述查询。
2. 基于倒排索引的检索
- 用 Query 的关键词在倒排表中匹配含相同关键词的 Chunk,通过TF-IDF、BM25等算法计算关键词权重(如关键词在 Chunk 中出现频率越高、在全库中越稀有,权重越高)。
- 按权重排序,返回 Top N 个 Chunk。
- 优势:速度快,适合精确关键词查询。
3. 混合检索策略
结合两种索引的优势,常见模式:
- “宽召回 + 精排序”:先用倒排索引召回大量候选(确保覆盖),再用向量索引计算语义相似度精排(提升精度)。
- “向量召回 + 关键词过滤”:先用向量索引召回语义相关 Chunk,再用关键词过滤掉无关内容(如 Query 含 “重疾险”,过滤不含该词的 Chunk)。
五、候选过滤与重排序(可选)
初步召回的候选 Chunk 可能存在重复、低质量或边缘相关内容,需进一步优化:
- 去重:去除重复或高度相似的 Chunk(如同一文档的相邻 Chunk 内容重复)。
- 阈值过滤:设定相似度阈值(如向量余弦相似度 > 0.7),过滤低于阈值的 Chunk。
- 元数据过滤:结合 Chunk 的元数据(如文档发布时间、权威性)筛选(如优先选择 “2023 年保险行业报告” 而非 “个人博客”)。
- 重排序(Reranking):用更精细的模型(如 Cross-Encoder)重新计算 Query 与候选 Chunk 的相关性,调整排序(例:向量召回的 Top 20 中,用 Cross-Encoder 选出真正最相关的 Top 5)。
六、召回效果的关键指标
评估召回效果的核心指标:
- 召回率(Recall):检索到的相关 Chunk 占知识库中所有相关 Chunk 的比例(越高越好,避免漏检)。
- 精确率(Precision):检索到的 Chunk 中真正相关的比例(越高越好,避免噪声)。
- 速度(Latency):从 Query 输入到返回结果的时间(越短越好,影响用户体验)。
不同场景下的召回策略选择
| 场景 | 核心需求 | 推荐召回策略 | 示例工具 |
|---|---|---|---|
| 专业文档检索(如法律、医疗) | 高精度,语义匹配 | 向量索引(领域微调 Embedding)+ 元数据过滤 | Milvus + 领域模型 |
| 开放域问答(如百科、客服) | 高召回,兼顾速度 | 混合索引(倒排 + 向量)+ 查询扩展 | Elasticsearch + Sentence-BERT |
| 实时对话系统 | 低延迟,短文本匹配 | 倒排索引(BM25)+ 轻量向量检索 | Pinecone + 轻量 Embedding |
总结
RAG 召回的核心逻辑是:通过数据预处理构建结构化知识库→用索引技术将知识转化为可检索格式→优化用户查询→通过向量 / 关键词 / 混合检索找到相关候选→过滤重排序输出结果。其目标是在 “全面性”(不漏掉相关内容)和 “精确性”(减少无关内容)之间找到平衡,为后续 LLM 生成提供高质量的 “参考素材”。实际应用中,需根据知识库规模、领域特性、用户需求调整检索策略(如选择合适的分块方式、索引类型、重排序模型)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号