![]()
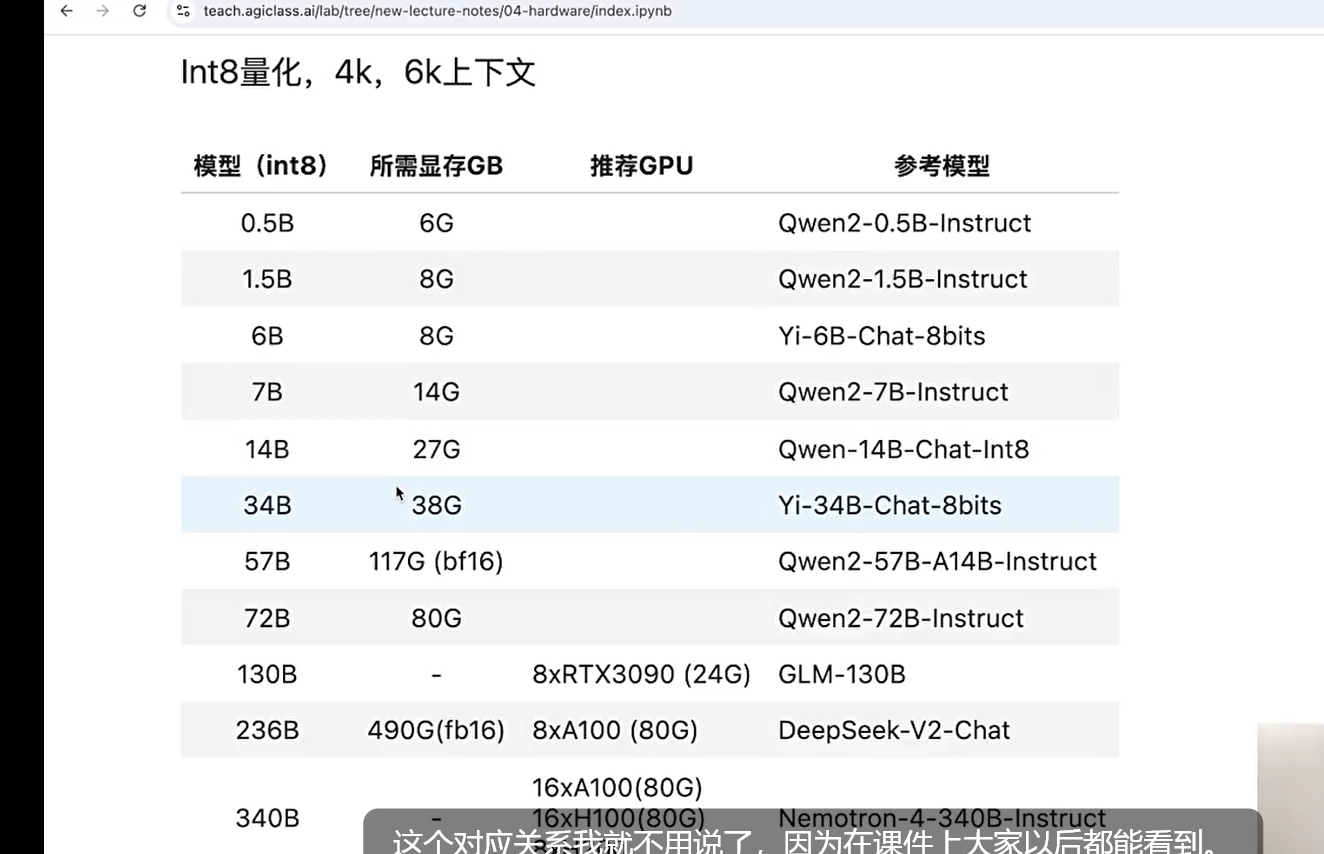
张图是关于 大语言模型(LLM)在 Int8 量化 下,不同参数规模模型所需显存、推荐 GPU 及参考模型的对应关系,帮你快速判断硬件能不能跑对应模型,大白话拆解如下:
每行对应一类模型,关键看 4 列:
- 模型(int8) :模型参数数量(比如 0.5B、1.5B ,B 是十亿,数字越大模型越复杂 ),且都用了 Int8 量化(把模型参数精度降低,减少显存占用,让大模型能在小硬件跑起来 )。
- 所需显存 GB :跑这个模型至少得有多少显存的 GPU ,显存不够就会报错、跑不起来 。
- 推荐 GPU :官方 / 经验里,用啥 GPU 能比较稳地跑这个模型(没有写的,要么是通用常见 GPU ,要么得靠多卡组合 )。
- 参考模型 :具体的模型名字,方便你对号入座找例子 。
-
0.5B 模型
- 参数规模小(0.5B ,五亿参数 ),Int8 量化后 只需 6G 显存 。
- 参考模型是
Qwen2-0.5B-Instruct (通义千问的小参数版本 ),普通游戏本(比如 6G 显存以上的显卡)都能跑跑试试 。
-
1.5B 模型
- 所需显存 8G ,参考模型
Qwen2-1.5B-Instruct 。
- 像你机械革命 G16(4070 8G 显存),刚好能跑这类模型!用来学习、做小任务(比如文本分类、简单对话)很合适 。
-
6B 模型
- 所需显存也是 8G ,参考模型
Yi-6B-Chat-8bits (Yi 系列 60 亿参数模型,Int8 量化版 )。
- 虽然参数比 1.5B 大很多,但因为 Int8 量化压缩了显存占用,8G 也能跑。不过实际跑的时候,除了显存,还要看 CPU、内存给不给力,别让它们拖后腿 。
-
7B 模型
- 所需显存涨到 14G ,参考模型
Qwen2-7B-Instruct 。
- 这时候你 8G 显存的 4070 就不够了,得换 14G 及以上显存的 GPU(比如台式机的 3060 12G 勉强够,或者更高端的 4080 16G 这类 )。
-
14B 模型
- 所需显存 27G ,参考模型
Qwen-14B-Chat-Int8 。
- 得用大显存 GPU ,普通消费级显卡扛不住,一般得靠专业卡(比如 A100 这类)或者多卡组合(好几张显卡一起分摊显存 )。
-
34B 模型
- 所需显存 38G ,参考模型
Yi-34B-Chat-8bits 。
- 更吃显存,得更高端的硬件,普通笔记本、台式机基本别想,属于企业级 GPU 才敢碰的规模 。
-
57B 模型
- 标注了
bf16(另一种精度格式,比 Int8 精度高些,显存占用也会多一丢丢 ),所需显存 117G ,参考模型 Qwen2-57B-A14B-Instruct 。
- 这种规模基本是大厂玩的,得超级多的高端 GPU 堆起来才能跑 。
-
72B 模型
- 所需显存 80G ,参考模型
Qwen2-72B-Instruct 。
- 同样得靠大显存专业 GPU ,普通人接触不到,属于科研、大厂训练用的 。
-
130B 模型
- 没写具体显存,直接推荐
8xRTX3090 (24G) (8 张 24G 显存的 RTX3090 显卡一起跑 ),参考模型 GLM-130B 。
- 多卡组合分摊显存和计算压力,普通人根本玩不起,硬件成本超高 。
-
236B 模型
- 标注
490G(fb16) ,推荐 8xA100 (80G) (8 张 80G 显存的 A100 专业卡 ),参考模型 DeepSeek-V2-Chat 。
- 妥妥的超大规模模型,只有大公司、科研机构能搞,硬件成本天价 。
-
340B 模型
- 推荐
16xA100(80G) 或 16xH100(80G) (16 张顶级专业卡 ),参考模型 Nemotron-4-340B-Instruct 。
- 目前最前沿的超大规模模型级别,硬件门槛极高,普通人和小团队想都别想 。
- 选模型:根据自己显卡显存,直接对应找能跑的模型。比如你 8G 显存,就玩 1.5B、6B 这类模型,别碰 7B 及以上的,省得折腾半天报错 。
- 配硬件:想跑大模型,看这张表就知道得花多少钱升级 GPU 。比如想跑 7B 模型,就得换 14G 以上显存的显卡;想玩 14B 及更大的,准备好上专业卡、多卡组合 。
- 理解差距:直观感受大模型参数规模和硬件需求的爆炸式增长。几百亿参数的模型,得几十、上百 G 显存的专业卡堆起来才能跑,普通人玩玩小模型(几 B、十几 B )就够了 。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号