20193131 2019-2020-2 《Python程序设计》实验四 报告
# 20193131 2019-2020-2 《Python程序设计》实验三报告
课程:《Python程序设计》
班级: 1931
姓名: 崔克政
学号:20193131
实验教师:王志强
实验日期:2021年6月18日
必修/选修: 公选课
## 1.实验内容
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等
## 2. 实验过程及结果
一、小说爬虫下载
涉及到的库及对应的作用:
- requests:用于获取get请求
- Beautiful Soup4:用于网页解析
- re:正则表达式
- os:系统相关操作
- time:获取的时间
这次我爬取的是新笔趣阁里面的小说,我们先进入小说网 ,对网站的网址和结构进行分析。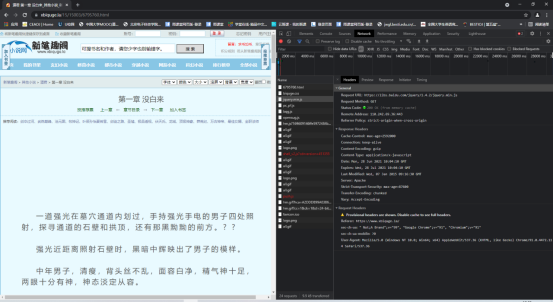


对网站结构进行分析,按F12检查网页源代码,我们仅需要的是Request Headers的内容,把里面的内容取出来放到字典中,其中关键的只有"User-Agent"
可以很清楚的看到,网页非常具有规律性,同一小说不同章节仅仅是最后一段数字在递增,可以通过正则表达式进行循环爬取,这次以5章为例
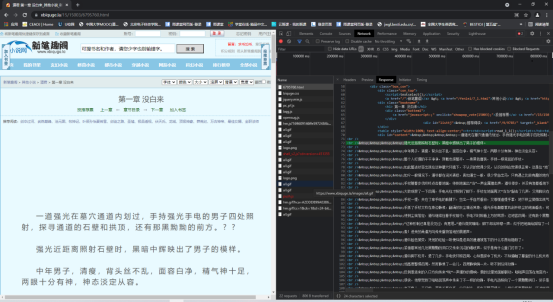

其中很简单的就找到了文字部分所在的连接位置,并且相当有规律,编写代码
title_re = re.compile(r'<h1>(.*?)</h1>') text_re = re.compile(r' ([\s\S]*?) ')
这两部分即为小说章节标题与正文部分的爬取。
代码如下
import requests import threading from bs4 import BeautifulSoup import re import os.path import time for i in range(6795760,6795765): header = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36'} req = requests.get('https://www.xbiquge.la/15/15003/%d.html' % i, headers=header) result = req.content result = result.decode('gbk','ignore') title_re = re.compile(r'<h1>(.*?)</h1>') text_re = re.compile(r' ([\s\S]*?) ') title = re.findall(title_re,result) text = re.findall(text_re,result) count = i - 6795759 file = open("C:\\Users\\86152\\Desktop\\小说\\第%d章.txt" % count,'a') for sentence in text: sentence = sentence.replace('<br', '') file.write(sentence) file.write('\n') path = os.walk("C:\\Users\\86152\\Desktop\\小说\\第%d章.txt" % count) file.close() file = file = open("C:\\Users\\86152\\Desktop\\小说\\第%d章.txt" % count,'r') print("第%d章下载完毕" % count)
试运行
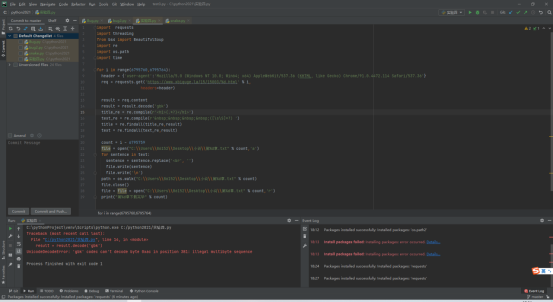
果然出错了哈哈哈,仔细查看是库文件安装错了位置,重新安装后可以成功运行
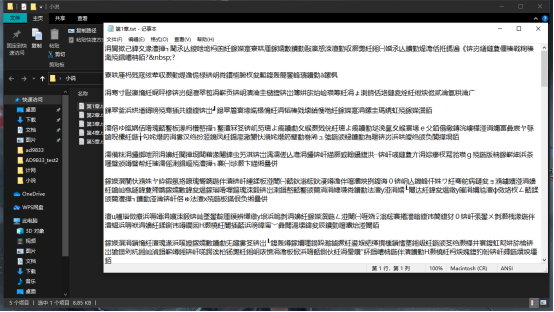
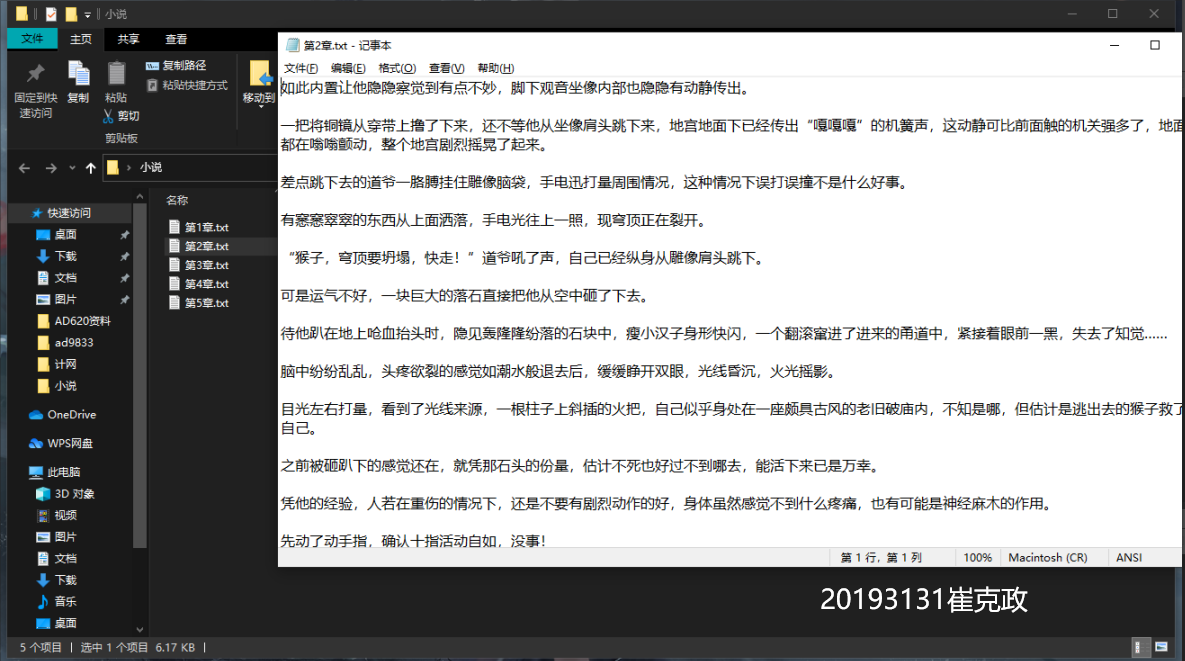
成功爬下了小说,但出现了乱码,经查询发现是编码问题,
参考了
https://www.cnblogs.com/yanduanduan/p/7250518.html
与
https://blog.csdn.net/zangbianer/article/details/84526011
后发现这个小说网站使用的是UTF-8进行编码,而我使用的是gbk写入.txt,所以是乱码
更正代码
result = result.decode('utf8','ignore')
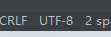
成功解决
二、贪吃蛇小游戏
早就听闻在强大库文件支持下,Python编写游戏相较C有巨大优势,这次我也进行了尝试
首先呢,需要有贪吃蛇、有食物;需要能控制贪吃蛇来上下移动获取食物;贪吃蛇在吃取食物后,自身长度增加,同时食物消失并随机生成新的食物;如果贪吃蛇触碰到四周墙壁或是触碰到自己身体时,则游戏结束。
那么就先来设定食物和背景的颜色
# 目标方块颜色 redColor = pygame.Color(255, 0, 0) # 背景颜色 blackColor = pygame.Color(0, 0, 0) # 蛇颜色 whiteColor = pygame.Color(255, 255, 255)
然后是蛇的长度、初始位置、蛇的初始位置
# 初始化目标方块的位置 targetPosition = [500, 100] # 目标方块标记 判断贪吃蛇是否吃掉目标方块 1为没吃掉 0为吃掉 targetFlag = 1 # 初始化贪吃蛇的位置 # 初始化贪吃蛇长度 snake_head = [400, 100] snake_body = [[80, 100], [60, 100]]
按键输入
elif event.type == KEYDOWN: if event.key == K_RIGHT: changedirection = 'right' if event.key == K_LEFT: changedirection = 'left' if event.key == K_UP: changedirection = 'up' if event.key == K_DOWN: changedirection = 'down' if event.key == K_ESCAPE: pygame.event.post(pygame.event.Event(QUIT))
吃下食物
# 增加蛇的长度 snake_body.insert(0, list(snake_head)) # 如果贪吃蛇位置和目标方块位置重合 if snake_head[0] == targetPosition[0] and snake_head[1] == targetPosition[1]: targetFlag = 0
加入变速模块,随着吃下的方块越多,蛇的爬行速度也会增加
# 如果贪吃蛇位置和目标方块位置重合 if snake_head[0] == targetPosition[0] and snake_head[1] == targetPosition[1]: targetFlag = 0 global speed speed=speed+1
一开始仅仅使用了局部变量来进行,一直在报错,经查证后发现全局变量需要global xxx的形式进行定义,并且在第一次使用时还需要再次进行global xxx的声明,表示确实在使用全局变量。
实际效果
代码链接:https://gitee.com/mybysq121/python2021/commit/06fc80ba92f7176a518659def446578e7fef9abe
##参考
全局变量:http://www.360doc.com/content/19/0306/08/58190678_819538495.shtml
小说爬虫下载:https://blog.csdn.net/weixin_43126271/article/details/84984767?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-3.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-3.control
## 实验过程中遇到的问题和解决过程
- 问题1:运行时涉及到很多环境,总是会出现缺少安装的现象,运用pip安装发现失败
- 问题1解决方案:参考资料,将pip加入了系统的环境变量,最终使pip install能够顺利运行
- 问题2:对正则表达式的具体内容不清楚
- 问题2解决方案:翻阅了课程的相关资料
##其他(感悟、思考等)
Python 作为一个近年备受好评的语言,它的一些优点让人无法忽视。Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。它的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有比其他语言更有特色语法结构。Python 是一种解释型语言: 这意味着开发过程中没有了编译这个环节。类似于PHP和Perl语言。Python 还是交互式语言: 这意味着,可以在一个Python提示符,直接互动执行写程序。
这次是python的最后一次实验,也是给我带来极大震撼的实验,从一开始对爬虫的一窍不通到经过了不断学习之后,能自己敲出爬虫代码,找到headers,获取小说内容的时候,我感到了一种极大的成就感,也让我看到了自己爬虫技术提高的可能性。平时通过观看云班课中的视频自学和观摩老师进行实操,我可以此每次顺利完成作业,并且学到了非常多的知识,不断认识到Python的强大之处。回顾整学期,循环、列表、类、元组、函数等等我都熟悉了知识点,而且每次作业虽然会遇到困难,但是通过自己查资料解决也使我有了自主学习的能力和解决问题的能力。通过课程的学习,我学习到了python如何使用,python语言的发展历史。学习到了流程控制语句:if-elif-else语句(elif else 可选)、for/while循环。学习到了序列如何应用、字符串与正则表达式如何实际去应用以及相关之间的关系;学习到了函数如何编写;学习了面向对象编程,万物皆为对象;学习了异常处理,是为了防止错误中断程序使程序更加的健壮;学习了数据库,python如何操作数据库,还学习到了一些简单的控制数据库语句;最后学习了爬虫。
我还是很喜欢老师这样的教学方式的,因为我现在越来越体会到自学的重要性,老师不是一直存在的,通过自己的资源和能力获取知识才是最可靠的。我没有更多的建议可以告诉老师,希望老师可以继续这样教学下去,通过独特的教学方式也让之后报这门选修的同学们领悟到自学的重要。
总的来说,这次实验,这门课程,收获颇丰。人生苦短,我用python。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号