
http://blog.csdn.net/jkay_wong/article/details/6877446
http://blog.csdn.net/morewindows/article/details/6709644
https://labuladong.github.io/algo/2/21/62/
要说最大堆和最小堆,就得先知道最大树和最小树。【也叫二叉堆】
每个结点的值都大于(小于)或等于其子节点(如果有的话)值的树,就叫最大(最小)树。(区别于搜索二叉树:它是左子树都比右子树小)
最大堆(最小堆)是最大(最小)完全树。
所有的数据结构书中都有关于堆的详细介绍,向堆中插入、删除元素时间复杂度都是O(lgN),N为堆中元素的个数,而获取最小key值(小根堆)的复杂度为O(1)。
堆是一个完全二叉树,基本存储方式是一个数组。
由于堆是完全二叉树,所以可以用公式化描述,用一维数组来有效的描述堆结构。
利用二叉树的性质:
如果对一棵有n个结点的完全二叉树的结点按层序编号(从第1层到第[log2n]向下取整+1层,每层从左到右),则对任一结点i(1≤i≤n),有:
(1)如果i=1,则结点i无双亲,是二叉树的根;如果i>1,则其双亲是结点[i/2]向下取整。 【根节点的索引是从1开始的】
(2)如果2i>n,则结点i为叶子结点,无左孩子;否则如果2i <= n,其左孩子是结点2i。
(3)如果2i+1>n,则结点i无右孩子;否则,其右孩子是结点2i+1。
这样就就可以将堆中结点移到它的父节点或者其中一个子节点处。
下图展示一个最小堆:

// 父节点的索引 int parent(int root) { return root / 2; } // 左孩子的索引 int left(int root) { return root * 2; } // 右孩子的索引 int right(int root) { return root * 2 + 1; }
由于其它几种堆(二项式堆,斐波纳契堆等)用的较少,一般将二叉堆就简称为堆。
堆的存储

堆的操作——插入删除
下面先给出《数据结构C++语言描述》中最小堆的建立插入删除的图解,再给出本人的实现代码,最好是先看明白图后再去看代码。

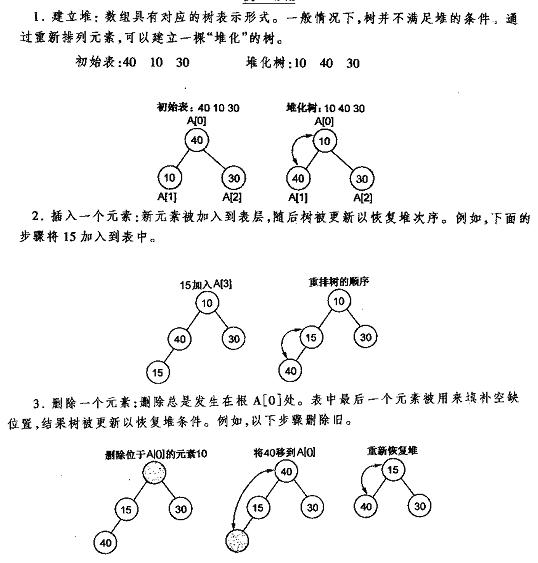
堆的插入
每次插入都是将新数据放在数组最后。
可以发现从这个新数据的父结点到根结点必然为一个有序的数列,现在的任务是将这个新数据插入到这个有序数据中——这就类似于直接插入排序中将一个数据并入到有序区间中,对照《白话经典算法系列之二 直接插入排序的三种实现》不难写出插入一个新数据时堆的调整代码:
- // 新加入i结点 其父结点为(i - 1) / 2
- void MinHeapFixup(int a[], int i)
- {
- int j, temp;
- temp = a[i];
- j = (i - 1) / 2; //父结点
- while (j >= 0 && i != 0)
- {
- if (a[j] <= temp)
- break;
- a[i] = a[j]; //把较大的子结点往下移动,替换它的子结点
- i = j;
- j = (i - 1) / 2;
- }
- a[i] = temp;
- }
更简短的表达为:
- void MinHeapFixup(int a[], int i)
- {
- for (int j = (i - 1) / 2; (j >= 0 && i != 0)&& a[i] > a[j]; i = j, j = (i - 1) / 2)
- Swap(a[i], a[j]);
- }
插入时:
- //在最小堆中加入新的数据nNum
- void MinHeapAddNumber(int a[], int n, int nNum)
- {
- a[n] = nNum;
- MinHeapFixup(a, n);
- }
堆的删除
按定义,堆中每次都只能删除第0个数据。
为了便于重建堆,实际的操作是将最后一个数据的值赋给根结点,然后再从根结点开始进行一次从上向下的调整。
调整时先在左右儿子结点中找最小的,如果父结点比这个最小的子结点还小说明不需要调整了,反之将父结点和它交换后再考虑后面的结点。相当于从根结点将一个数据的“下沉”过程。下面给出代码:
- // 从i节点开始调整,n为节点总数 从0开始计算 i节点的子节点为 2*i+1, 2*i+2
- void MinHeapFixdown(int a[], int i, int n)
- {
- int j, temp;
- temp = a[i];
- j = 2 * i + 1;
- while (j < n)
- {
- if (j + 1 < n && a[j + 1] < a[j]) //在左右孩子中找最小的
- j++;
- if (a[j] >= temp)
- break;
- a[i] = a[j]; //把较小的子结点往上移动,替换它的父结点
- i = j;
- j = 2 * i + 1;
- }
- a[i] = temp;
- }
- //在最小堆中删除数
- void MinHeapDeleteNumber(int a[], int n)
- {
- Swap(a[0], a[n - 1]);
- MinHeapFixdown(a, 0, n - 1);
- }
堆化数组
有了堆的插入和删除后,再考虑下如何对一个数据进行堆化操作。要一个一个的从数组中取出数据来建立堆吧,不用!先看一个数组,如下图:
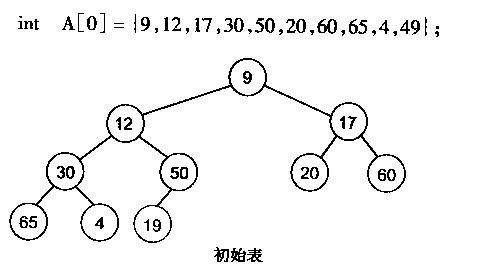

很明显,对叶子结点来说,可以认为它已经是一个合法的堆了即20,60, 65, 4, 49都分别是一个合法的堆。
只要从A[4]=50开始向下调整就可以了。然后再取A[3]=30,A[2] = 17,A[1] = 12,A[0] = 9分别作一次向下调整操作就可以了。
【从叶子节点向上进行堆化调整】
下图展示了这些步骤:

写出堆化数组的代码:
- //建立最小堆
- void MakeMinHeap(int a[], int n)
- {
- for (int i = n / 2 - 1; i >= 0; i--)
- MinHeapFixdown(a, i, n);
- }
至此,堆的操作就全部完成了(注1),再来看下如何用堆这种数据结构来进行排序。
堆排序
首先可以看到堆建好之后堆中第0个数据是堆中最小的数据。取出这个数据再执行下堆的删除操作。这样堆中第0个数据又是堆中最小的数据,重复上述步骤直至堆中只有一个数据时就直接取出这个数据。
由于堆也是用数组模拟的,故堆化数组后,第一次将A[0]与A[n - 1]交换,再对A[0…n-2]重新恢复堆。
第二次将A[0]与A[n – 2]交换,再对A[0…n - 3]重新恢复堆,重复这样的操作直到A[0]与A[1]交换。
由于每次都是将最小的数据并入到后面的有序区间,故操作完成后整个数组就有序了。有点类似于直接选择排序。
- void MinheapsortTodescendarray(int a[], int n)
- {
- for (int i = n - 1; i >= 1; i--)
- {
- Swap(a[i], a[0]);
- MinHeapFixdown(a, 0, i);
- }
- }
注意使用最小堆排序后是递减数组,要得到递增数组,可以使用最大堆。
由于每次重新恢复堆的时间复杂度为O(logN),共N - 1次重新恢复堆操作,再加上前面建立堆时N / 2次向下调整,每次调整时间复杂度也为O(logN)。二次操作时间相加还是O(N * logN)。故堆排序的时间复杂度为O(N * logN)。STL也实现了堆的相关函数,可以参阅《STL系列之四 heap 堆》。
注1 作为一个数据结构,最好用类将其数据和方法封装起来,这样即便于操作,也便于理解。此外,除了堆排序要使用堆,另外还有很多场合可以使用堆来方便和高效的处理数据,以后会一一介绍。
https://labuladong.github.io/algo/2/21/62/
/* 上浮第 x 个元素,以维护最大堆性质 */
private void swim(int x) {...}
/* 下沉第 x 个元素,以维护最大堆性质 */
private void sink(int x) {...}
对于最大堆,会破坏堆性质的有两种情况:
1、如果某个节点 A 比它的子节点(中的一个)小,那么 A 就不配做父节点,应该下去,下面那个更大的节点上来做父节点,这就是对 A 进行下沉。
2、如果某个节点 A 比它的父节点大,那么 A 不应该做子节点,应该把父节点换下来,自己去做父节点,这就是对 A 的上浮。
当然,错位的节点 A 可能要上浮(或下沉)很多次,才能到达正确的位置,恢复堆的性质。所以代码中肯定有一个 while 循环。
细心的读者也许会问,这两个操作不是互逆吗,所以上浮的操作一定能用下沉来完成,为什么我还要费劲写两个方法?
是的,操作是互逆等价的,但是最终我们的操作只会在堆底和堆顶进行(等会讲原因),显然堆底的「错位」元素需要上浮,堆顶的「错位」元素需要下沉。
private void swim(int x) { // 如果浮到堆顶,就不能再上浮了 while (node > 1 && less(parent(x), x)) { // 父节点比当前节点小 // 如果第 x 个元素比上层大 // 将 x 换上去 exchange(parent(x), x); x = parent(x); } }
下沉的代码实现:
下沉比上浮略微复杂一点,因为上浮某个节点 A,只需要 A 和其父节点比较大小即可;但是下沉某个节点 A,需要 A 和其两个子节点比较大小,如果 A 不是最大的就需要调整位置,要把较大的那个子节点和 A 交换。
private void sink(int x) { // 如果沉到堆底,就沉不下去了 while (left(x) <= size) { // 先假设左边节点较大 int older = left(x); // 如果右边节点存在,比一下大小 if (right(x) <= N && less(older, right(x))) older = right(x); // 结点 x 比俩孩子都大,就不必下沉了 if (less(older, x)) break; // 否则,不符合最大堆的结构,下沉 x 结点 exch(x, older); x = older; } }
insert 方法先把要插入的元素添加到堆底的最后,然后让其上浮到正确位置。
public void insert(Key e) { N++; // 先把新元素加到最后 pq[N] = e; // 然后让它上浮到正确的位置 swim(N); }
delMax 方法先把堆顶元素 A 和堆底最后的元素 B 对调,然后删除 A,最后让 B 下沉到正确位置。
public Key delMax() { // 最大堆的堆顶就是最大元素 Key max = pq[1]; // 把这个最大元素换到最后,删除之 exch(1, N); pq[N] = null; N--; // 让 pq[1] 下沉到正确位置 sink(1); return max; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号