面试问题
数据库:
-
数据库建表原则
-
分库分表:
分库:按业务分库 uc、lock、cdb
垂直:1、通过分表把核心数据和非核心数据分开,让表的结构更清晰,职责更单一,更便于维护。
2、把调用频次高的放在一张表,调用频次低的放在另一张表。
水平:1、数据量大,不好维护
2、按地区分表 按type分表
分表中间件:sharding JDBC
解决问题:
分库:是为了解决数据库连接资源不足问题,和磁盘IO的性能瓶颈问题。分表:是为了解决单表数据量太大,sql语句查询数据时,即使走了索引也非常耗时问题。此外还可以解决消耗cpu资源问题。分库分表:可以解决 数据库连接资源不足、磁盘IO的性能瓶颈、检索数据耗时 和 消耗cpu资源等问题。
-
建索引的原则
决定在哪些字段上建立索引取决于你的数据库设计和查询需求。索引是用于加速数据库查询的工具,但不是所有字段都需要被索引。以下是一些关于在哪些字段上建立索引的常见考虑因素:
- 主键字段:通常,每个表都有一个主键字段,用于唯一标识每个记录。主键字段通常会自动被索引,因为它们用于确保表中的唯一性。
- 外键字段:外键字段用于关联不同表之间的数据。在外键字段上建立索引可以加速连接操作和查询。
- 经常用于过滤和筛选的字段:如果某个字段经常用于查询的
WHERE条件,那么在这个字段上建立索引可以提高查询性能。这通常包括经常用于等值查询、范围查询或排序的字段。 - 经常用于连接的字段:如果你经常进行连接操作(如
JOIN)以关联多个表,那么在连接字段上建立索引可以加速连接操作。 - 经常用于排序的字段:如果某个字段经常用于
ORDER BY子句进行排序,那么在这个字段上建立索引可以提高排序操作的性能。 - 大表中的关键字段:在大型表中,通常需要更多的索引来加速查询。在这种情况下,需要权衡磁盘空间和维护成本。
- 频繁更新的字段:需要注意,对于频繁更新的字段,索引可能会导致性能下降,因为每次更新都需要更新索引。因此,在这些字段上建立索引需要谨慎。
- 覆盖索引:有时,你可以创建覆盖索引,这是一个包含查询所需字段的索引,从而避免了回表查询,提高了性能。
普通索引:即一个索引只包含单个列,一个表可以有多个单列索引;
唯一索引:索引列的值必须唯一,但允许有空值;
复合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并;
聚簇索引(聚集索引):并不是一种单独的索引类型,而是一种数据存储方式。具体细节取决于不同的实现,InnoDB的聚簇索引其实就是在同一个结构中保存了B+Tree索引和数据行,也就是InnoDB的主键索引;
非聚簇索引:除聚簇索引之外的就是非聚簇索引,也就是非主键索引也称二级索引或辅助索引;需要注意的是,InnoDB存储引擎中的主键索引是聚簇索引,而非主键索引则是非聚簇索引。另外,如果一个表没有主键或唯一键,InnoDB会选择一个唯一非空索引作为聚簇索引。如果表中没有合适的索引可以作为聚簇索引,InnoDB会创建一个隐藏的聚簇索引来存储数据。
-
索引的底层数据类型
-
三大范式
第一范式(1NF):字段不可分;
第二范式(2NF):有主键,非主键字段依赖主键;
第三范式(3NF):非主键字段不能相互依赖。 -
索引失效的情况
使用合适的数据类型:为了减少索引的大小,应该尽可能使用短的数据类型。例如,如果只需要存储年份,可以使用 SMALLINT 数据类型,而不是 INT 或 BIGINT 数据类型。
精简索引数量:索引越多,查询速度越慢,因为查询需要扫描更多的索引。因此,应该仅在必要时使用索引,避免创建过多的索引。
选择合适的索引类型:不同类型的索引适用于不同的查询场景。因此,应该根据查询的特点选择合适的索引类型,例如 B+ 树索引或哈希索引。
避免过长的索引:索引长度越长,索引越大,查询速度就越慢。因此,应该避免创建过长的索引,例如超过 100 个字符。
考虑索引列的顺序:按照查询条件的顺序创建索引,可以最大限度地利用索引的优势。这是因为索引在执行查询时只能使用索引的最左前缀。
避免在索引列上进行函数操作:在索引列上进行函数操作会使索引失效,无法利用索引进行查询。因此,应该避免在索引列上进行函数操作,例如在索引列上使用函数 LOWER() 或 UPPER()。
使用覆盖索引:如果查询只需要返回索引列,可以使用覆盖索引。覆盖索引只需要扫描索引,而不需要扫描数据行,可以加快查询速度。
避免使用 NOT IN 和 OR 条件:使用 NOT IN 和 OR 条件会导致 MySQL 无法使用索引进行查询,应该尽可能避免使用这些条件。
定期维护索引:定期维护索引可以提高查询性能。例如,可以删除不必要的索引,重新生成索引统计信息等.
-
索引的type:
NULL > system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
system > const > eq_ref > ref > range > index > ALL
eq_ref 跟 const 的区别是:两者都利用唯一索引,但前者是关联查询,后者只是普通查询?eq_ref 跟 ref 的区别:后者是非唯一索引
-
innodb 和 MyIsam对比
1). 数据的存储结构不同
2). 存储空间的消耗不同
3). 对事务的支持不同
4). 对锁的支持不同
5). 对外键的支持不同
-
什么是回表
回表(Covering Index)是指查询数据时,如果需要从辅助索引中查询列数据,而不是直接从主键索引或者聚簇索引中获取,就需要回到原始的表中再查找对应的数据,这个过程就被称为回表。
在MySQL中,辅助索引只存储了索引列的值和指向对应主键索引的指针,因此如果查询的列不在辅助索引中,就需要通过回表从原始的表中获取对应数据。这会增加I/O的操作,降低查询效率。
为了避免回表的操作,我们可以使用覆盖索引(Covering Index),即在辅助索引上包含所有需要查询的列,这样在查询时就可以直接从索引中获取所需要的数据,而不需要回到原始的表中进行查找。这样可以大大提高查询效率。
-
数据库事务隔离级别
-
读未提交:可以读取到事务未提交的数据,隔离性差,会出现脏读(当前内存读),不可重复读,幻读问题;
-
读已提交:
-
可重复读
-
串行化
-
什么是脏读 什么是幻读
-
什么是MVCC
消息队列:
1、如果发生异常情况,如何重新消费?
2、如何避免重复消费
1.IO和NIO的区别
NIO就是New IO在JDK1.4中引入。
IO和NIO有相同的作用和目的,但实现方式不同,NIO主要用到的是块,所以NIO的效率要比IO快不少。
在Java API中提供了两套NIO,一套针对标准输入输出NIO,另一套就是网络编程IO。
| IO | NIO |
|---|---|
| 面向流 | 面向缓冲 |
| 阻塞IO | 非阻塞IO |
| 无 | 选择器 |
###① 面向流和面向缓冲区
-
Java IO 是面向流的而Java NIO是面向缓冲区的,就如同一个的重点在于过程,另一重点在于一个有一个阶段。
在Java IO中读取数据和写入数据是面向流(Stream)的,就如同河流一样。所有的数据不停地向前的流淌,我们只能触碰到当前的流水。
如果需要获取某个数据的前一项或后一项数据那就必须自己缓存数据(将水从河流中打出来),而不能直接从流中获取(因为面向流就意味着我们只有一个数据流的切面)
-
Java NIO中数据的读写是面向缓冲区(Buffer)的,读取时可以将整块的数据读取到缓冲区中,在写入时则可以将整个缓冲区中的数据一起写入。
这就好像是在河流上建立水坝,面向流的数据读写只提供了一个数据流切面,而面向缓冲区的IO则使我们能够看到所有的水(数据的上下文),也就是说在缓冲区中获取某项数据的前一项数据或者是后一项数据十分方便。这种便利是有代价的,因为我们必须管理好缓冲区,这包括不能让新的数据覆盖了缓冲区中还没有被处理的有用数据;将缓冲区中的数据正确的分块,分清哪些被处理过哪些还没有等等。
##② 阻塞和非阻塞
-
Java IO是阻塞的,如果在一次读写数据调用时数据还没有准备好,或者目前不可写,那么读写操作就会被阻塞直到数据准备好或目标可写为止。
-
Java NIO则是非阻塞的,每一次数据读写调用都会立即返回,并将目前可读(或可写)的内容写入缓冲区或者从缓冲区中输出,即使当前没有可用数据,调用仍然会立即返回并且不对缓冲区做任何操作。
举个例子:
IO和NIO去超市买东西,如果超市中没有需要的商品或者数量还不够, IO会一直等到超市中需要的商品数量足够了就将所有需要的商品带回来。Java NIO则不同,不论超市中有多少需要的商品,它都将有需要的商品,立即全部买下并返回,甚至是没有需要的商品也会立即返回。
IO 要求一次完成任务,NIO允许多次完成任务
2.IO和NIO的适用场景
NIO是为弥补传统IO的不足而诞生的,但是NIO也有缺陷,应为NIO是面向缓冲区的操作,每一次的数据处理都是对缓冲区进行的,那就必须注意:在数据处理之前必须要判断缓冲区的数据是否完整或者已经读取完毕。如果没有,假设数据只读取了一部分,那么对不完整的数据处理没有任何意义。所以每次数据处理之前都要检测缓冲区。
注意:每次要进行数据处理必须保证数据已经准备完毕,但数据处理可以有多次。
IO和NIO各自使用场景:
IO:少量的连接,这些连接每次都要发送大量的数据。
NIO:需要管理同时打开的成千上万个连接,而这些链接每次只发送少量的数据,例如聊天服务器
##IO和NIO的工作流程
Java IO 工作流程
由于Java IO是阻塞的,所以当面对多个流的读写时需要多个线程处理。例如在网络IO中,Server端使用一个线程监听一个端口,一旦某个连接被accept,创建新的线程来处理新建立的连接。
其中 read/write 是阻塞的。
Java NIO 工作流程
Java NIO 提供 Selector 实现单个线程管理多个channel的功能。
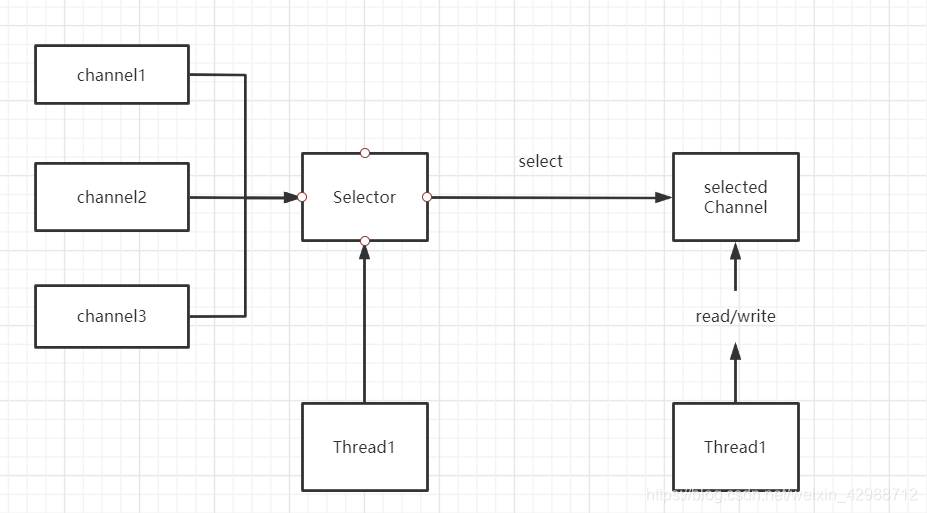
其中select 调用可能是阻塞的,也可以是非阻塞的。但是read/write是非阻塞的!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号