3 手写线程池(C++11)
写在文章的前面
这篇介绍线程池的博客磕磕绊绊写了五六天,由于博主学识尚浅,最终还是没有提供一个能正确运行的线程池,但文章提供了如何构造线程池的思路,大家可以参考。后续待博主参考更多线程池写法后再来完善本篇博客。
以下为原文
引言: 线程池的学习相对于“手写智能指针”是比较花精力的,网上大部分线程池的博客或文章都是介绍Java中的线程池,C++的很少见,故写这篇文章记录搜集到的资料跟自身的理解。
前置知识
构建线程池之前,我们需要回答两个问题:
什么是线程池?为什么要有线程池?
线程池定义: 预先创建并维护一定数量的线程,这些线程可以被重复利用来执行任务,而不是为每个任务都创建和销毁线程,这就是线程池。
线程池的优势: 线程池的主要作用就是为了避免创建销毁线程时所带来的开销,任务到来的时候,可以立即放置在任务队列中,供空闲线程执行
线程池的组成
线程池的组成可以分为四个部分,具体可见下图:
1)线程池本身;
2)工作队列(存放线程池);
3)任务队列;
4)回调函数;
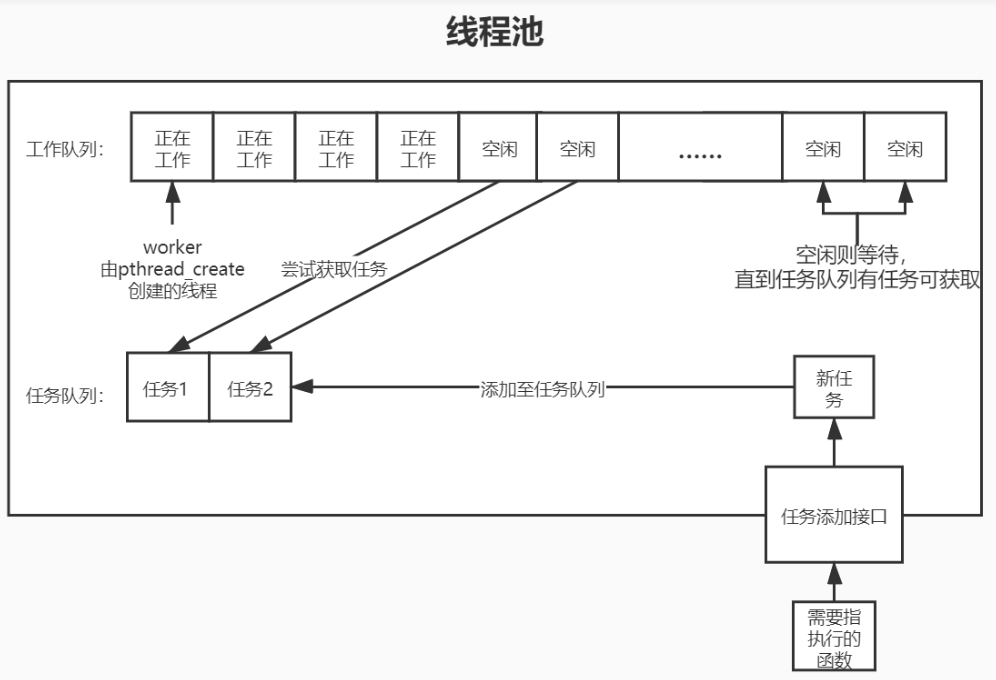
下面我们就分别从这四个部分构建。
1 线程池本池
很显然,我们应该将其封装成一个类,我们将其取名为ThreadPool。按照以往的惯例,一个类我们要定义它的无参构造,有参构造以及析构函数,这是最基本的。这里我们不写无参构造,无参构造与有参构造的逻辑基本一致,且无参构造基本不会发生。
那么按照我们上面所说的,线程池应该包含工作队列、任务队列以及回调函数:
2 工作队列
即存放线程的地方,这里我们用一个vector来存储,将其中每一个元素称之为worker,这个worker不应只单单指工作线程本身,也包含一些与线程绑定的状态,这里我们使用两个bool值来标记线程状态,一个用来表示是否处于工作态,is_working;一个用来表示是否需要终止,terminate。
因为我们的工作队列中的线程应该是被创建之后脱离主线程,处于一个while循环之中要么在执行任务,要么则是在阻塞等待任务,当线程需要被回收时,我们需要一个标记来告诉它,可以退出循环,荣归故里了!
还需要什么了?有时候我们需要在工作线程中访问线程池的一些成员变量,因此我们需要告诉子线程,你是被谁创造出来的。
OK,暂时就这些,接下来就可以进行封装了,对于这种简单无复杂逻辑的封装,我们传统上使用struct:
struct Worker{ // 工作线程封装
std::thread thread;
std::bool is_working;
std::bool terminate;
ThreadPool* pool;
};
所以,工作队列应该是:
std::vector<Worker> m_workers;
3 任务队列
存放任务函数(回调函数)的地方。任务函数使用C++11中的function类来接收(相当于函数指针),在C语言的pthread_create中,允许传递一个任务函数需要使用到的参数,我们这里也仿照这样设计。这个参数的类型选择也有讲究,为void*类型,该类型可以接收任何类型的指针,在回调函数中,可以再将其强制转换成想要的类型,我们也仿照其设计,即function<void(void*)>。任务函数的应该与类Worker类似:
struct Job { // 任务封装
std::function<void(void*)> func;
void* func_arg;
Job(std::function<void(void*) f, void* a>) : func(f), user_arg(a) {}
};
这里我们加了一个有参构造函数,方便提交任务的时候,直接对Job进行赋值。其实Job的设计也可以从用户提交任务的角度来考虑,对于用户来讲,只会交给线程池一个任务函数与任务函数执行所需的参数,别的一概不管,谁让他是甲方了😅。
因此存放任务函数的地方也初见雏形,一般我们会使用队列,双端队列或者是链表来存放任务函数,这些容器的特性能够便于我们执行先进先服务的任务处理操作(还有其他任务处理逻辑,例如设立任务优先级,按优先级服务)。
OK,接下来有个需要注意的地方(敲黑板):
线程池中的任务是如何流动的了?首先用户会向线程池提交任务到任务队列中,这时主线程(线程池)中的任务队列持有该任务,接着我们需要将任务交付到子线程(工作线程)中,这样,在某一时刻,该任务会同时被主线程与子线程持有,如果在子线程处理任务时,主线程将任务意外删除,可能会造成异常发生。总的来讲:
在多线程环境中,任务对象可能被多个地方同时访问:
1)主线程将任务添加到任务队列;
2)子线程(工作线程)从队列中获取并执行任务;
使用共享指针可以确保任务对象在所有引用都被释放后才销毁,避免悬空指针和内存访问错误。当然,指针的使用也可以避免深拷贝开销。
所以,任务队列应该是:
std::list<std::shared_ptr<Job>> m_jobs_list;
那有了任务队列,我们有一个很朴素的想法,紧接着就是为用户(甲方)提供提交任务的函数了,这里提交任务函数我们要以用户的角度去思考,作为用户,我只会给线程池两样东西,一是我希望执行的任务函数,二是提供给任务函数的参数。但根据我们之前的设计,任务函数的参数是作为一个指针传递过来的,如果我们只是接收这个指针,显然会得到一个指针副本,指向用户想要传递的参数值,也就是说该参数值依旧在用户手上,这显然是不安全的,我们需要对其进行深拷贝一份过来保存,在自己手上才是最安全的嘛😋。所以我们需要用户额外在填入一个参数,为传递给任务函数参数值的大小。
这个任务函数的处理逻辑应该是什么了:
1)收到这三个参数,将其封装为Job;
2)将其添加进任务队列;
3)通知线程对其进行处理;
别小看这三点,这三点仍然有需要注意的地方。对于1),我们需要进行深拷贝操作;对于2),任务队列是隶属于线程池的一部分,而不是某个线程所有,访问它需要进行加锁,所以我们需要一把线程池级别的锁m_mtx,添加任务的时候,我们需要判断任务队列是否还装的下,毕竟你的线程池不是无限大,所以我们需要一个成员变量m_max_jobs来表示任务队列最大容量;对于3),这里其实就是一个生产者-消费者模式,意味着我们还需要一个条件变量外加一个锁来完成线程间的同步操作。
这里有个小知识点:
为什么生产之-消费者模型往往都会有锁 + 条件变量了?
1)任务队列是共享变量,由多个线程共享,所以每次访问时需要加锁;
2)由于生产者向任务队列中放入任务的时间是不确定的,所以工作线程只能不断循环访问或者间隔访问任务队列,看是否有任务到来,毫无疑问,这样对CPU造成的负担是巨大的,所以我们需要一种通知机制(条件变量),来告诉线程们,什么时候可以来任务队列中取任务了;
这里我们可以再做的完善些,将提交任务分为面向用户的与面下线程池的,这样未来升级该线程池的时候逻辑会更加清晰。
那么,两个任务提交函数如下:
// 面向用户的任务添加函数
int PushJob(function<void<void*>> func, void* arg, int len) {
if (!func || len <= 0 || arg == nullptr) {
std::cerr << "Input Error!" << endl;
return -1;
}
// 开始深拷贝
void* arg_copy = nullptr;
arg_copy = malloc(len);
if (!arg_copy) {
std::cerr << "malloc Error!" << endl;
return -2;
}
// 创建任务
auto job = std::make_shared<Job>(func, arg_copy);
if (!AddJob(job)) {
std::cerr << "AddJob Error!" << endl;
free(arg_copy);
return -3;
}
return 0;
}
// 线程池内部的添加任务
bool AddJob(std::shared_ptr<Job> job) {
// 加锁访问任务队列
std::unique_lock<std::mutex> lock(m_mtx);
if (m_jobs_list.size() >= m_max_jobs) {
std::cerr << "overflow" << endl;
return false;
}
m_jobs_list.push_back(job);
m_cv.notify_one(); // 唤醒一个线程
return true;
}
4 回调函数
OK,走到了最后一个组件了,那看过任务队列的介绍后,大家对回调函数也应该不陌生了,任务队列中存储的任务就是回调函数,有时我们也将其称为任务函数。但这是我们现在要讲的回调函数吗?并不完全是!
我们再次回顾整个流程,封装我们要的线程与任务,构造线程队列与任务队列,其中任务队列存放的是用户想要执行的任务函数,接下来,我们应该创建线程将任务队列里的函数取出来执行,问题就在创建线程这一步,按照C++11中thread的使用方式,我们需要在创建线程的时候传入一个回调函数,作为这个新建线程所要执行的事情。
那么,对于这个新建线程的回调函数的处理逻辑应该是什么了?
当然是不断地从任务队列中取出任务函数去执行!所以任务队列中的任务函数才是我们真正要去执行地回调函数!
下面我们来梳理线程执行函数的处理逻辑:
1)线程处理函数的任务是处理任务队列里的任务函数,而且是只要没收到停止的命令,就应该一直在处理任务与等待任务的路上(真是牛马了😢)。所以该函数的主题应该是一个死循环,除非都到停止指令,否则一直处于这个循环中;
2)考虑如何让线程停止,在我们的设计里,新建线程是会与主线程detach的,好在我们之前留了一个变量,terminate用来标记线程是否结束,还定义了一个变量,is_working来指明线程是否在工作,所以线程的传参应该是一个Worker类;
总的处理逻辑为:上锁 -> 有条件阻塞等待 -> 获取任务,更新任务队列 -> 判断任务是否有效,开始执行任务 -> 任务结束
所以,线程执行函数如下:
void ThreadLoop(Worker& worker) {
while (true) {
std::shared_ptr<Job> job;
{
// 上锁,释放锁,阻塞等待;防止虚假唤醒给wait加了条件
std::unique_lock<std::mutex> lock(m_mtx);
m_cv.wait(lock, [this, &worker]() {return !m_jobs_list.empty() && !worker.terminate;});
// 获取任务
if (worker.terminate)
break;
job = m_jobs_list.front();
m_jobs_list.pop_front();
}
// 开始执行任务
worker.is_working = true;
if (job && job->func) {
job->func(job->func_arg);
}
// 任务结束
worker.is_working = false;
}
}
好了,四大组件都介绍完了,终于要开始搭线程池框架了!(太不容易了😭)
综上,我们有了工作线程队列、任务队列以及存放在任务队列中的任务函数,除了线程池本身的构造函数与析构函数外,其余工作基本都已实现,下一步就是搭框架了。这里我们依旧遵循分离式编译的原则,类中只定义,不写具体实现,类外写具体实现。
#include <iostream>
#include <list>
#include <vector>
#include <thread>
#include <functional>
#include <memory>
#include <mutex>
#include <condition_variable>
class ThreadPool {
public:
ThreadPool(int woker_nums, int max_jobs = 10);
~ThreadPool();
int PushJob(std::function<void(void*)>, void* arg, int len);
private:
struct Worker {
std::thread thread;
bool is_working;
bool terminate;
ThreadPool* pool;
};
struct Job {
std::function<void(void*)> func;
void* func_arg;
Job(std::function<void(void*)> f, void* a) : func(f), func_arg(a) {}
};
bool AddJob(std::list<std::shared_ptr<Job>> job);
static void ThreadLoop(Worker& worker);
private:
int m_max_jobs;
int m_sum_threads;
std::vector<Worker> m_worker;
std::list<std::shared_ptr<Job>> m_jobs_list;
std::mutex m_mtx;
std::condition_variable m_cv;
};
构造函数与析构函数的处理逻辑如下:
ThreadPool::ThreadPool(int worker_nums, int max_jobs)
: m_sum_threads(worker_nums), m_max_jobs(max_jobs) {
// 参数有效性判断
if (worker_nums <= 0 || max_jobs <= 0) {
std::cerr << "ThreadPool args Error!" << std::endl;
exit(1);
}
// 线程结构体初始化
m_workers.resize(worker_nums);
for (int i = 0; i < worker_nums; ++i) {
m_workers[i].is_working = false;
m_workers[i].terminate = false;
m_workers[i].pool = this->shared_from_this();
// 创建线程并进行线程分离
m_workers[i].thread = std::thread(&ThreadPool::ThreadLoop, std::ref(m_workers[i]), this);
m_workers[i].thread.detach();
}
}
ThreadPool::~ThreadPool() {
// 设置所有线程终止标志
for (int i = 0; i < m_sum_threads; ++i) {
m_workers[i].terminate = true;
}
// 唤醒所有等待的线程
{
std::unique_lock<std::mutex> lock(m_mtx);
m_cv.notify_all(); // 相当于pthread_cond_broadcast
}
// 注意:不需要delete m_workerss,因为使用vector自动管理
}
以下是完整代码
点击查看代码
#include <iostream>
#include <list>
#include <vector>
#include <thread>
#include <functional>
#include <memory>
#include <mutex>
#include <condition_variable>
class ThreadPool : public std::enable_shared_from_this<ThreadPool> {
public:
ThreadPool(int woker_nums, int max_jobs = 10);
~ThreadPool();
int PushJob(std::function<void(void*)>, void* arg, int len);
private:
struct Worker {
std::thread thread;
bool is_working;
bool terminate;
std::shared_ptr<ThreadPool> pool;
};
struct Job {
std::function<void(void*)> func;
void* func_arg;
Job(std::function<void(void*)> f, void* a) : func(f), func_arg(a) {}
};
bool AddJob(std::shared_ptr<Job> job);
static void ThreadLoop(Worker& worker, ThreadPool* pool);
private:
int m_max_jobs;
int m_sum_threads;
std::vector<Worker> m_workers;
std::list<std::shared_ptr<Job>> m_jobs_list;
std::mutex m_mtx;
std::condition_variable m_cv;
};
ThreadPool::ThreadPool(int worker_nums, int max_jobs)
: m_sum_threads(worker_nums), m_max_jobs(max_jobs) {
// 参数有效性判断
if (worker_nums <= 0 || max_jobs <= 0) {
std::cerr << "ThreadPool args Error!" << std::endl;
exit(1);
}
// 线程结构体初始化
m_workers.resize(worker_nums);
for (int i = 0; i < worker_nums; ++i) {
m_workers[i].is_working = false;
m_workers[i].terminate = false;
m_workers[i].pool = this->shared_from_this();
// 创建线程并进行线程分离
m_workers[i].thread = std::thread(&ThreadPool::ThreadLoop, std::ref(m_workers[i]), this);
m_workers[i].thread.detach();
}
}
ThreadPool::~ThreadPool() {
// 设置所有线程终止标志
for (int i = 0; i < m_sum_threads; ++i) {
m_workers[i].terminate = true;
}
// 唤醒所有等待的线程
{
std::unique_lock<std::mutex> lock(m_mtx);
m_cv.notify_all(); // 相当于pthread_cond_broadcast
}
// 注意:不需要delete m_workerss,因为使用vector自动管理
}
int ThreadPool::PushJob(std::function<void(void*)> func, void* arg, int len) {
if (!func || len <= 0 || arg == nullptr) {
std::cerr << "Input Error!" << std::endl;
return -1;
}
// 开始深拷贝
void* arg_copy = nullptr;
arg_copy = malloc(len);
if (!arg_copy) {
std::cerr << "malloc Error!" << std::endl;
return -2;
}
// 创建任务
auto job = std::make_shared<Job>(func, arg_copy);
if (!AddJob(job)) {
std::cerr << "AddJob Error!" << std::endl;
free(arg_copy);
return -3;
}
return 0;
}
// 线程池内部的添加任务
bool ThreadPool::AddJob(std::shared_ptr<Job> job) {
// 加锁访问任务队列
std::unique_lock<std::mutex> lock(m_mtx);
if (m_jobs_list.size() >= m_max_jobs) {
std::cerr << "overflow" << std::endl;
return false;
}
m_jobs_list.push_back(job);
m_cv.notify_one(); // 唤醒一个线程
return true;
}
void ThreadPool::ThreadLoop(Worker& worker, ThreadPool* pool) {
while (true) {
std::shared_ptr<Job> job;
{
// 上锁,释放锁,阻塞等待;防止虚假唤醒给wait加了条件
std::unique_lock<std::mutex> lock(pool->m_mtx);
pool->m_cv.wait(lock, [&pool, &worker]() {return !pool->m_jobs_list.empty()
&& !worker.terminate;});
// 获取任务
if (worker.terminate)
break;
job = pool->m_jobs_list.front();
pool->m_jobs_list.pop_front();
}
// 开始执行任务
worker.is_working = true;
if (job && job->func) {
job->func(job->func_arg);
}
// 任务结束
worker.is_working = false;
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号