1.lr.predict_proba(under_text_x) 获得的是正负的概率值
在sklearn逻辑回归的计算过程中,使用的是大于0.5的是正值,小于0.5的是负值,我们使用使用不同的概率结果判定来研究概率阈值对结果的影响
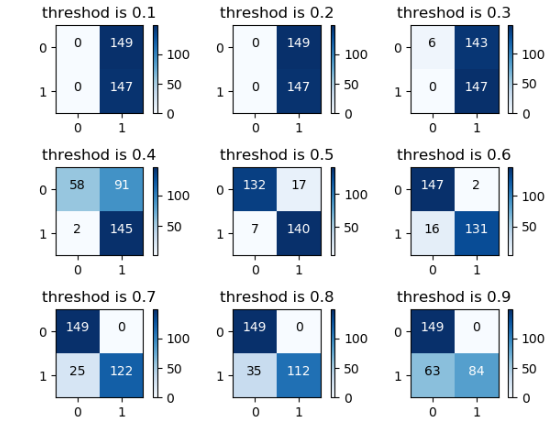
从图中我们可以看出,阈值越小,被判为正的越多,即大于阈值的就是为正,但是存在一个很明显的问题就是很多负的也被判为正值。
当阈值很小时,数据的召回率很大,但是整体数据的准确率很小
因此我们需要根据召回率和准确率的综合考虑选择一个合适的阈值
lr = LogisticRegression(C=best_c, penalty='l1') lr.fit(under_train_x, under_train_y) pred_array = np.array(lr.predict_proba(under_text_x)) thresholds = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9] j = 1 for threshold in thresholds: pred_y_new = np.zeros([len(under_text_x), 1]) pred_y_new[pred_array[:, 1] > threshold] = 1 # 获得矩阵 plt.subplot(3, 3, j) conf = confusion_matrix(under_test_y, pred_y_new) # 画图 plot_matrix(conf, classes=[0, 1], title='threshod is {}'.format(threshold)) accurracy = (conf[0, 0] + conf[1, 1]) / (conf[0, 0] + conf[0, 1] + conf[1, 0] + conf[1, 1]) # 召回率 recall = conf[1, 1] / (conf[1, 0] + conf[1, 1]) j = j + 1 plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号