lucene3.5--学习笔记 孔浩--昭通学院 20150401
****************************************************************************************
01_lucenc简介和创建索引初步 02_lucene简介和搜索初步
public class HelloLucence {
public void index() {
//2.创建IndexWriter
IndexWriterConfig iwc = new IndexWriterConfig(Version.LUCENE_35 , new StandardAnalyzer(Version.LUCENE_35 ));
IndexWriter writer = null ;
try {
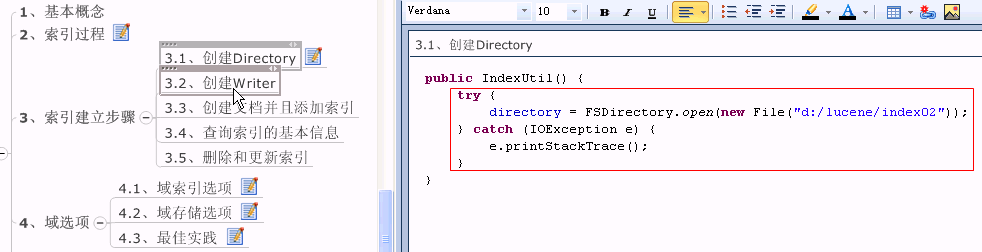
//1.创建Directory
//Directory directory = new RAMDirectory();
Directory directory = FSDirectory.open( new File("d:/lucene" ));
writer = new IndexWriter(directory, iwc);
//3.创建Document对象
Document doc = null ;
//4.为Document添加Field
File f = new File("D:/lucene2" );
for(File file :f .listFiles()){
doc = new Document();
doc.add(new Field("content", new FileReader(file)));
doc.add(new Field("filename" ,file .getName(),Field.Store.YES,Field.Index. NOT_ANALYZED));
doc.add(new Field("path",file .getAbsolutePath(),Field.Store.YES,Field.Index. NOT_ANALYZED));
//5.通过IndexWriter添加文档到索引中
writer.addDocument(doc );
}
} catch (CorruptIndexException e ) {
e.printStackTrace();
} catch (LockObtainFailedException e ) {
e.printStackTrace();
} catch (IOException e ) {
e.printStackTrace();
} finally{
if(writer !=null){
try {
writer.close();
} catch (IOException e ) {
e.printStackTrace();
}
}
}
}
public void searcher(){
try {
//1.创建Directory
//Directory directory = new RAMDirectory();
Directory directory = FSDirectory.open( new File("d:/lucene" ));
//2.创建IndexReader
IndexReader reader = IndexReader.open( directory);
//3.根据IndexReader创建IndexSearcher
IndexSearcher searcher = new IndexSearcher(reader);
//4.创建搜索的Query
//创建parser来确定要搜索文件的内容,第二个参数表示搜索的域
QueryParser parser = new QueryParser(Version.LUCENE_35 , "content" , new StandardAnalyzer(Version.LUCENE_35 ));
//创建query,表示搜索域为content中包含java的文档
Query query = parser .parse("phonegap");
//5.根据searcher搜索并且返回TopDocs
TopDocs tds = searcher .search(query, 10);
//6.根据topDocs获取ScoreDoc对象
ScoreDoc[] sds = tds .scoreDocs ;
for(ScoreDoc sd :sds ){
//7.根据seacher和ScordDoc对象获取具体的Document对象
Document d = searcher.doc(sd .doc );
//8.根据Document对象获取需要的值
System. out.println(d .get("filename")+ "["+d .get("path")+ "]");
}
reader.close();
} catch (IOException e ) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ParseException e ) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
**************************************************************************************************************************
03--索引 分词 加权


**************************************************************************************************************************
**************************************************************************************************************************

**************************************************************************************************************************
**************************************************************************************************************************
package org.itat.test;
import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.NumericField;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.StaleReaderException;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.LockObtainFailedException;
import org.apache.lucene.store.RAMDirectory;
import org.apache.lucene.util.Version;
public class IndexUtil {
private String[] ids = {"1", "2","3" ,"4" ,"5" ,"6" };
private String[] emails = {"aa@itat.org" ,"bb@itat.org" ,"cc@cc.org" ,"dd@sina.org" ,"ee@zttc.edu" ,"ff@itat.org" };
private String[] contents = {
"welcome to visited the space,I like book" ,
"hello boy, I like pingpeng ball" ,
"my name is cc I like game" ,
"I like football",
"I like football and I like basketball too" ,
"I like movie and swim"
};
private Date[] dates = null;
private int [] attachs = {2,3,1,4,5,5};
private String[] names = {"zhangsan","lisi" ,"john" ,"jetty" ,"mike" ,"jake" };
private Directory directory = null;
private Map<String,Float> scores = new HashMap<String,Float>();
private static IndexReader reader = null;
public IndexUtil() {
try {
setDates();
scores.put("itat.org" ,2.0f);
scores.put("zttc.edu" , 1.5f);
//directory = FSDirectory.open(new File("d:/lucene/index02"));
directory = new RAMDirectory();
index();
reader = IndexReader.open( directory,false );
} catch (IOException e ) {
e.printStackTrace();
}
}
public IndexSearcher getSearcher() {
try {
if(reader ==null) {
reader = IndexReader.open( directory,false );
} else {
IndexReader tr = IndexReader.openIfChanged(reader);
if(tr !=null) {
reader.close();
reader = tr ;
}
}
return new IndexSearcher(reader);
} catch (CorruptIndexException e ) {
e.printStackTrace();
} catch (IOException e ) {
e.printStackTrace();
}
return null ;
}
private void setDates() {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
try {
dates = new Date[ids.length];
dates[0] = sdf .parse("2010-02-19");
dates[1] = sdf .parse("2012-01-11");
dates[2] = sdf .parse("2011-09-19");
dates[3] = sdf .parse("2010-12-22");
dates[4] = sdf .parse("2012-01-01");
dates[5] = sdf .parse("2011-05-19");
} catch (ParseException e ) {
e.printStackTrace();
}
}
public void undelete() {
//使用IndexReader进行恢复
try {
IndexReader reader = IndexReader.open(directory, false);
//恢复时,必须把IndexReader的只读(readOnly)设置为false
reader.undeleteAll();
reader.close();
} catch (CorruptIndexException e ) {
e.printStackTrace();
} catch (StaleReaderException e ) {
e.printStackTrace();
} catch (LockObtainFailedException e ) {
e.printStackTrace();
} catch (IOException e ) {
e.printStackTrace();
}
}
public void merge() {
IndexWriter writer = null ;
try {
writer = new IndexWriter(directory,
new IndexWriterConfig(Version.LUCENE_35 ,new StandardAnalyzer(Version.LUCENE_35 )));
//会将索引合并为2段,这两段中的被删除的数据会被清空
//特别注意:此处 Lucene在3.5之后不建议使用,因为会消耗大量的开销,
//Lucene 会根据情况自动处理的
writer.forceMerge(2);
} catch (CorruptIndexException e ) {
e.printStackTrace();
} catch (LockObtainFailedException e ) {
e.printStackTrace();
} catch (IOException e ) {
e.printStackTrace();
} finally {
try {
if(writer !=null) writer.close();
} catch (CorruptIndexException e ) {
e.printStackTrace();
} catch (IOException e ) {
e.printStackTrace();
}
}
}
public void forceDelete() {
IndexWriter writer = null ;
try {
writer = new IndexWriter(directory,
new IndexWriterConfig(Version.LUCENE_35 ,new StandardAnalyzer(Version.LUCENE_35 )));
writer.forceMergeDeletes();
} catch (CorruptIndexException e ) {
e.printStackTrace();
} catch (LockObtainFailedException e ) {
e.printStackTrace();
} catch (IOException e ) {
e.printStackTrace();
} finally {
try {
if(writer !=null) writer.close();
} catch (CorruptIndexException e ) {
e.printStackTrace();
} catch (IOException e ) {
e.printStackTrace();
}
}
}
public void delete() {
IndexWriter writer = null ;
try {
writer = new IndexWriter(directory,
new IndexWriterConfig(Version.LUCENE_35 ,new StandardAnalyzer(Version.LUCENE_35 )));
//参数是一个选项,可以是一个Query,也可以是一个term,term是一个精确查找的值
//此时删除的文档并不会被完全删除,而是存储在一个回收站中的,可以恢复
writer.deleteDocuments(new Term("id", "1"));
writer.commit();
} catch (CorruptIndexException e ) {
e.printStackTrace();
} catch (LockObtainFailedException e ) {
e.printStackTrace();
} catch (IOException e ) {
e.printStackTrace();
} finally {
try {
if(writer !=null) writer.close();
} catch (CorruptIndexException e ) {
e.printStackTrace();
} catch (IOException e ) {
e.printStackTrace();
}
}
}
public void delete02() {
try {
reader.deleteDocuments(new Term("id", "1"));
} catch (CorruptIndexException e ) {
e.printStackTrace();
} catch (LockObtainFailedException e ) {
e.printStackTrace();
} catch (IOException e ) {
e.printStackTrace();
}
}
public void update() {
IndexWriter writer = null ;
try {
writer = new IndexWriter(directory,
new IndexWriterConfig(Version.LUCENE_35 ,new StandardAnalyzer(Version.LUCENE_35 )));
/*
* Lucene并没有提供更新,这里的更新操作其实是如下两个操作的合集
* 先删除之后再添加
*/
Document doc = new Document();
doc.add(new Field("id","11" ,Field.Store.YES,Field.Index. NOT_ANALYZED_NO_NORMS));
doc.add(new Field("email" ,emails [0],Field.Store.YES,Field.Index. NOT_ANALYZED));
doc.add(new Field("content" ,contents [0],Field.Store.NO,Field.Index. ANALYZED));
doc.add(new Field("name",names [0],Field.Store.YES,Field.Index. NOT_ANALYZED_NO_NORMS));
writer.updateDocument(new Term("id", "1"), doc );
} catch (CorruptIndexException e ) {
e.printStackTrace();
} catch (LockObtainFailedException e ) {
e.printStackTrace();
} catch (IOException e ) {
e.printStackTrace();
} finally {
try {
if(writer !=null) writer.close();
} catch (CorruptIndexException e ) {
e.printStackTrace();
} catch (IOException e ) {
e.printStackTrace();
}
}
}
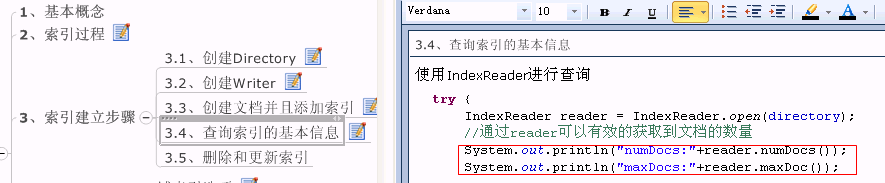
public void query() {
try {
IndexReader reader = IndexReader.open( directory);
//通过reader可以有效的获取到文档的数量
System. out.println("numDocs:" +reader .numDocs());
System. out.println("maxDocs:" +reader .maxDoc());
System. out.println("deleteDocs:" +reader .numDeletedDocs());
reader.close();
} catch (CorruptIndexException e ) {
e.printStackTrace();
} catch (IOException e ) {
e.printStackTrace();
}
}
public void index() {
IndexWriter writer = null ;
try {
writer = new IndexWriter(directory, new IndexWriterConfig(Version.LUCENE_35 , new StandardAnalyzer(Version.LUCENE_35 )));
writer.deleteAll();
Document doc = null ;
for(int i =0;i<ids.length;i++) {
doc = new Document();
doc.add(new Field("id",ids [i ],Field.Store.YES,Field.Index. NOT_ANALYZED_NO_NORMS));
doc.add(new Field("email" ,emails [i ],Field.Store.YES,Field.Index. NOT_ANALYZED));
doc.add(new Field("email" ,"test" +i +"@test.com" ,Field.Store.YES,Field.Index. NOT_ANALYZED));
doc.add(new Field("content" ,contents [i ],Field.Store.NO,Field.Index. ANALYZED));
doc.add(new Field("name",names [i ],Field.Store.YES,Field.Index. NOT_ANALYZED_NO_NORMS));
//存储数字
doc.add(new NumericField("attach" ,Field.Store.YES, true).setIntValue(attachs [i ]));
//存储日期
doc.add(new NumericField("date" ,Field.Store.YES, true).setLongValue(dates [i ].getTime()));
String et = emails[i ].substring(emails[i].lastIndexOf( "@")+1);
System. out.println(et );
if(scores .containsKey(et)) {
doc.setBoost(scores .get(et));
} else {
doc.setBoost(0.5f);
}
writer.addDocument(doc );
}
} catch (CorruptIndexException e ) {
e.printStackTrace();
} catch (LockObtainFailedException e ) {
e.printStackTrace();
} catch (IOException e ) {
e.printStackTrace();
} finally {
try {
if(writer !=null)writer.close();
} catch (CorruptIndexException e ) {
e.printStackTrace();
} catch (IOException e ) {
e.printStackTrace();
}
}
}
public void search01() {
try {
IndexReader reader = IndexReader.open( directory);
IndexSearcher searcher = new IndexSearcher(reader);
TermQuery query = new TermQuery(new Term("email","test0@test.com" ));
TopDocs tds = searcher .search(query, 10);
for(ScoreDoc sd :tds .scoreDocs ) {
Document doc = searcher .doc(sd.doc);
System. out.println("(" +sd .doc +"-" +doc .getBoost()+"-"+ sd. score+")" +
doc.get("name" )+"[" +doc .get("email")+ "]-->"+doc .get("id")+ ","+
doc.get("attach" )+"," +doc .get("date")+ ","+doc .getValues("email")[1]);
}
reader.close();
} catch (CorruptIndexException e ) {
e.printStackTrace();
} catch (IOException e ) {
e.printStackTrace();
}
}
public void search02() {
try {
IndexSearcher searcher = getSearcher();
TermQuery query = new TermQuery(new Term("content" ,"like" ));
TopDocs tds = searcher .search(query, 10);
for(ScoreDoc sd :tds .scoreDocs ) {
Document doc = searcher .doc(sd.doc);
System. out.println(doc .get("id")+ "---->"+
doc.get("name" )+"[" +doc .get("email")+ "]-->"+doc .get("id")+ ","+
doc.get("attach" )+"," +doc .get("date")+ ","+doc .getValues("email")[1]);
}
searcher.close();
} catch (CorruptIndexException e ) {
e.printStackTrace();
} catch (IOException e ) {
e.printStackTrace();
}
}
}
**************************************************************************************************************************
04_lucene索引_的删除和更新


**************************************************************************************************************************
05_lucene索引_加权操作和Luke的简单演示
private Map<String, Float>scores = new HashMap<String, Float>();
public IndexUtil(){
setDates();
scores.put( "itat.org", 2.0f);
scores.put( "zttc.edu", 1.5f);
//directory = FSDirectory.open(new File("D:/ lucene/index02"));
directory = new RAMDirectory();
index();
}
public void index(){
IndexWriter writer = null;
try {
writer = new IndexWriter(directory ,new IndexWriterConfig(Version.LUCENE_35 , new StandardAnalyzer(Version.LUCENE_35 )));
writer.deleteAll();
Document doc = null;
for(int i =0;i <ids .length ;i ++){
doc = new Document();
doc.add( new Field("id" ,ids [i ],Field.Store.YES,Field.Index. NOT_ANALYZED_NO_NORMS ));
doc.add( new Field("email" ,emails [i ],Field.Store.YES,Field.Index. NOT_ANALYZED ));
doc.add( new Field("email" ,"test" +i +"@test.com" ,Field.Store.YES ,Field.Index. NOT_ANALYZED));
doc.add( new Field("content" ,contents [i],Field.Store.NO,Field.Index. ANALYZED));
doc.add( new Field("name" ,names [i ],Field.Store.YES,Field.Index. NOT_ANALYZED_NO_NORMS ));
doc.add( new NumericField("attach" ,Field.Store.YES, true).setIntValue(attachs [i ]));
doc.add( new NumericField("date" ,Field.Store.YES, true).setLongValue(dates [i ].getTime()));
String et = emails[ i].substring( emails[ i].lastIndexOf( "@")+1);
if(scores .containsKey(et)){
doc.setBoost( scores.get( et));
} else{
doc.setBoost(0.5f);
}
writer.addDocument( doc);
}
} catch (IOException e ) {
e.printStackTrace();
} finally {
if(writer !=null)
try {
writer.close();
} catch (IOException e ) {
e.printStackTrace();
}
}
}
**************************************************************************************************************************
06_对日期和数字进行索引
public void index(){
IndexWriter writer = null;
try {
writer = new IndexWriter(directory ,new IndexWriterConfig(Version.LUCENE_35 , new StandardAnalyzer(Version.LUCENE_35 )));
writer.deleteAll();
Document doc = null;
for(int i =0;i <ids .length ;i ++){
doc = new Document();
doc.add( new Field("id" ,ids [i ],Field.Store.YES,Field.Index. NOT_ANALYZED_NO_NORMS ));
doc.add( new Field("email" ,emails [i ],Field.Store.YES,Field.Index. NOT_ANALYZED ));
doc.add( new Field("email" ,"test" +i +"@test.com" ,Field.Store.YES ,Field.Index. NOT_ANALYZED));
doc.add( new Field("content" ,contents [i],Field.Store.NO,Field.Index. ANALYZED));
doc.add( new Field("name" ,names [i ],Field.Store.YES,Field.Index. NOT_ANALYZED_NO_NORMS ));
doc.add( new NumericField("attach",Field.Store. YES,true ).setIntValue(attachs[i]));
doc.add( new NumericField("date",Field.Store. YES,true ).setLongValue(dates[i].getTime()));
String et = emails[ i].substring( emails[ i].lastIndexOf( "@")+1);
if(scores .containsKey(et)){
doc.setBoost( scores.get( et));
} else{
doc.setBoost(0.5f);
}
writer.addDocument( doc);
}
} catch (IOException e ) {
e.printStackTrace();
} finally {
if(writer !=null)
try {
writer.close();
} catch (IOException e ) {
e.printStackTrace();
}
}
}
**************************************************************************************************************************
09_lucene的搜索_TermRange等基本搜索--精确匹配
public IndexSearcher getSearcher(){
try {
if(reader ==null){
reader = IndexReader. open(directory);
} else{
IndexReader tr = IndexReader. openIfChanged(reader);
if(tr !=null){
reader.close();
reader = tr;
}
}
return new IndexSearcher(reader);
} catch (CorruptIndexException e ) {
e.printStackTrace();
} catch (IOException e ) {
e.printStackTrace();
}
return null ;
}
public void searchByTerm (String field ,String name ,int num){
IndexSearcher searcher = getSearcher();
Query query = new TermQuery(new Term(field,name));
try {
TopDocs tds = searcher.search( query, num);
System. out.println("一共查询了:" +tds .totalHits );
for(ScoreDoc sd :tds .scoreDocs ){
Document doc = searcher.doc( sd. doc);
System. out.println(doc .get("id" )+"----->" +
doc.get( "name")+"[" +doc .get("email" )+"]--->" +doc .get("id" )+"," +
doc.get( "attach")+"," +doc .get("date" ));
}
searcher.close();
} catch (IOException e ) {
e.printStackTrace();
}
}
**************************************************************************************************************************
10_lucene的搜索_其他常用Query搜索
前缀搜索
**************************************************************************************************************************
短语查询
public void searchByPhrase (int num ){
IndexSearcher searcher = getSearcher();
PhraseQuery query = new PhraseQuery();
query.setSlop(1);
query.add( new Term("content" ,"i" ));
query.add( new Term("content" ,"football" ));
try {
TopDocs tds = searcher.search( query, num);
System. out.println("一共查询了:" +tds .totalHits );
for(ScoreDoc sd :tds .scoreDocs ){
Document doc = searcher.doc( sd. doc);
System. out.println(doc .get("id" )+"----->" +
doc.get( "name")+"[" +doc .get("email" )+"]--->" +doc .get("id" )+"," +
doc.get( "attach")+"," +doc .get("date" ));
}
searcher.close();
} catch (IOException e ) {
e.printStackTrace();
}
}
**************************************************************************************************************************
模糊查询
public void searchByFuzzy (int num ){
IndexSearcher searcher = getSearcher();
Query query = new FuzzyQuery(new Term("name", "mlke"),0.5f,2);
try {
TopDocs tds = searcher.search( query, num);
System. out.println("一共查询了:" +tds .totalHits );
for(ScoreDoc sd :tds .scoreDocs ){
Document doc = searcher.doc( sd. doc);
System. out.println(doc .get("id" )+"----->" +
doc.get( "name")+"[" +doc .get("email" )+"]--->" +doc .get("id" )+"," +
doc.get( "attach")+"," +doc .get("date" ));
}
searcher.close();
} catch (IOException e ) {
e.printStackTrace();
}
}

**************************************************************************************************************************



@Test
public void searchByQueryParse (){
QueryParser parser = new QueryParser(Version.LUCENE_35 ,"content" ,new StandardAnalyzer(Version.LUCENE_35 ));
parser.setDefaultOperator(Operator. AND);
parser.setAllowLeadingWildcard( true);
Query query;
try {
query = parser.parse( "like");
query = parser.parse( "football");
query = parser.parse( "name:mike");
query = parser.parse( "email:*@itat.org");
query = parser.parse( "- name:mike + football ");
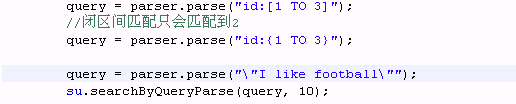
query = parser.parse( "id:[1 TO 3]");
query = parser.parse( "id:{1 TO 3}");
query = parser.parse( "\"I like football\"" );
query = parser.parse( "name:make~");
su.searchByQueryParse( query, 10);
} catch (ParseException e ) {
e.printStackTrace();
}
}
**************************************************************************************************************************
12_lucene的搜索_复习和再查询分页搜索
public void searchPage (String query ,int pageIndex,int pageSize) {
try {
Directory dir = FileIndexUtils. getDirectory();
IndexSearcher searcher = getSearcher( dir);
QueryParser parser = new QueryParser(
Version. LUCENE_35,"content" ,new StandardAnalyzer(Version.LUCENE_35 ));
Query q = parser.parse( query);
TopDocs tds = searcher.search( q, 500);
ScoreDoc[] sds = tds. scoreDocs;
int start = (pageIndex -1)*pageSize ;
int end = pageIndex * pageSize ;
for(int i = start ;i <end ;i ++){
Document doc = searcher.doc( sds[ i]. doc);
System. out.println(sds [i ].doc +":" +doc .get("path" )+"-->" +doc .get("filename" ));
}
} catch (org.apache.lucene.queryParser.ParseException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e ) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public void searchNoPage (String query ) {
try {
Directory dir = FileIndexUtils. getDirectory();
IndexSearcher searcher = getSearcher( dir);
QueryParser parser = new QueryParser(
Version. LUCENE_35,"content" ,new StandardAnalyzer(Version.LUCENE_35 ));
Query q = parser.parse( query);
TopDocs tds = searcher.search( q, 500);
ScoreDoc[] sds = tds. scoreDocs;
for(int i = 0;i <sds .length ;i ++){
Document doc = searcher.doc( sds[ i]. doc);
System. out.println(sds [i ].doc +":" +doc .get("path" )+"-->" +doc .get("filename" ));
}
} catch (org.apache.lucene.queryParser.ParseException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e ) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
**************************************************************************************************************************
13_lucene的搜索_基于searchAfter的实现--分页
public void searchPageByAfter (String query ,int pageIndex,int pageSize) {
try {
Directory dir = FileIndexUtils. getDirectory();
IndexSearcher searcher = getSearcher( dir);
QueryParser parser = new QueryParser(
Version. LUCENE_35,"content" ,new StandardAnalyzer(Version.LUCENE_35 ));
Query q = parser.parse( query);
ScoreDoc lastSd = getLastScoreDoc( pageIndex, pageSize , q , searcher);
TopDocs tds = searcher.searchAfter( lastSd, q, pageSize);
//TopDocs tds = searcher.search(q, 500);
//int last = (pageIndex-1)*pageSize -1 ;
//ScoreDoc[] sds = tds.scoreDocs;
//tds = searcher.searchAfter(sds[last], q, 20);
for(ScoreDoc sd :tds .scoreDocs ){
Document doc = searcher.doc( sd. doc);
System. out.println(sd .doc +":" +doc .get("path" )+"-->" +doc .get("filename" ));
}
} catch (org.apache.lucene.queryParser.ParseException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e ) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
**************************************************************************************************************************
15_lucene的分词_通过TokenStream显示分词
public class AnalyzerUtils {
public static void displayToken(String str,Analyzer a){
try {
TokenStream stream = a.tokenStream( "content", new StringReader(str));
//创建一个属性,这个属性会添加到流中,随着这个TokenStream增加
CharTermAttribute cta = stream.addAttribute(CharTermAttribute.class);
while(stream .incrementToken()){
System. out.print("[" +cta +"]" );
}
System. out.println();
} catch (IOException e ) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
public class TestAnalyzer {
@Test
public void test01() {
Analyzer a1 = new StandardAnalyzer(Version.LUCENE_35);
Analyzer a2 = new StopAnalyzer(Version.LUCENE_35);
Analyzer a3 = new SimpleAnalyzer(Version.LUCENE_35);
Analyzer a4 = new WhitespaceAnalyzer(Version.LUCENE_35);
String txt = "this is my house,I am come from yunan zhaotong,my email is yunann@gmail.com,my qq is 34654645";
AnalyzerUtils. displayToken(txt, a1);
AnalyzerUtils. displayToken(txt, a2);
AnalyzerUtils. displayToken(txt, a3);
AnalyzerUtils. displayToken(txt, a4);
}
@Test
public void test02() {
Analyzer a1 = new StandardAnalyzer(Version.LUCENE_35);
Analyzer a2 = new StopAnalyzer(Version.LUCENE_35);
Analyzer a3 = new SimpleAnalyzer(Version.LUCENE_35);
Analyzer a4 = new WhitespaceAnalyzer(Version.LUCENE_35);
String txt = "你好,我来自登录的第十" ;
AnalyzerUtils. displayToken(txt, a1);
AnalyzerUtils. displayToken(txt, a2);
AnalyzerUtils. displayToken(txt, a3);
AnalyzerUtils. displayToken(txt, a4);
}
}
**************************************************************************************************************************
16_lucene分词_通过TokenStream显示分词的详细信息
public static void displayAllTokenInfo(String str,Analyzer a){
try {
TokenStream stream = a.tokenStream( "content", new StringReader(str));
PositionIncrementAttribute pia = stream.addAttribute(PositionIncrementAttribute.class);
OffsetAttribute oa = stream.addAttribute(OffsetAttribute. class);
CharTermAttribute cta = stream.addAttribute(CharTermAttribute.class);
TypeAttribute ta = stream.addAttribute(TypeAttribute. class);
for(;stream .incrementToken();){
System. out.print(pia .getPositionIncrement()+":");
System. out.println(cta +"[" +oa .startOffset()+"-"+ oa.endOffset()+ "]-->"+ta .type());
}
System. out.println();
} catch (IOException e ) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
@Test
public void test03() {
Analyzer a1 = new StandardAnalyzer(Version.LUCENE_35);
Analyzer a2 = new StopAnalyzer(Version.LUCENE_35);
Analyzer a3 = new SimpleAnalyzer(Version.LUCENE_35);
Analyzer a4 = new WhitespaceAnalyzer(Version.LUCENE_35);
String txt = "how are you thank you";
AnalyzerUtils. displayAllTokenInfo(txt, a1);
AnalyzerUtils. displayAllTokenInfo(txt, a2);
AnalyzerUtils. displayAllTokenInfo(txt, a3);
AnalyzerUtils. displayAllTokenInfo(txt, a4);
}
**************************************************************************************************************************
17_lucene的分词_中文分词介绍




**************************************************************************************************************************

**************************************************************************************************************************
自定义stop分词器
public class MyStopAnalyzer extends Analyzer{
@SuppressWarnings("rawtypes" )
private Set stops ;
@SuppressWarnings("unchecked" )
public MyStopAnalyzer (String[] sws ) {
//会自动将字符串数组转换为set
stops = StopFilter. makeStopSet(Version.LUCENE_35, sws, true);
//将原有的停用词加入到现在的停用词
stops.addAll(StopAnalyzer. ENGLISH_STOP_WORDS_SET);
}
public MyStopAnalyzer () {
//获取原有的停用词
stops = StopAnalyzer. ENGLISH_STOP_WORDS_SET;
}
@Override
public TokenStream tokenStream(String fieldName , Reader reader) {
//为这个分词器设定过滤链和 Tokenizer
return new StopFilter(Version.LUCENE_35,
new LowerCaseFilter(Version.LUCENE_35,
new LetterTokenizer(Version.LUCENE_35 ,reader )), stops );
}
}
@Test
public void test04 (){
Analyzer a1 = new MyStopAnalyzer(new String[]{"I", "you"});
Analyzer a2 = new MyStopAnalyzer();
String txt = "how are you thank you";
AnalyzerUtils. displayToken(txt, a1);
AnalyzerUtils. displayToken(txt, a2);
}
**************************************************************************************************************************

**************************************************************************************************************************

 浙公网安备 33010602011771号
浙公网安备 33010602011771号