
Pytorch+Vgg
Pytorch:
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 6 output channels, 5x5 square convolution
# kernel
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square you can only specify a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
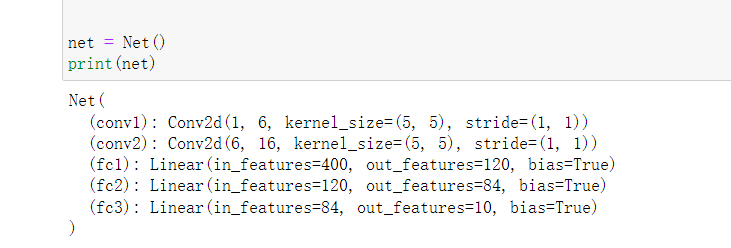
net = Net()
print(net)
params = list(net.parameters())
print(len(params))
print(params[0].size()) # conv1's .weight

input = torch.randn(1, 1, 32, 32)
out = net(input)
print(out)

Vgg:
import torch
from torchvision import transforms,datasets
from torch import nn
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.tensorboard import SummaryWriter
from torchvision import models
#搭建VGG-16网络
# 数据预处理
"""
Fashion-Mnist数据集大小为24*24,VGG网络输入为224,
所以进行resize,但是这样效果不咋好,实际应用时不建议这样做
"""
train_transforms = transforms.Compose([transforms.ToTensor(),
transforms.Resize((224,224)),
transforms.Normalize((0.5,),(0.5,))])
test_transforms = transforms.Compose([transforms.ToTensor(),
transforms.Resize((224,224)),
transforms.Normalize((0.5,),(0.5,))])
# 加载数据集
train_data = datasets.FashionMNIST(root="./data",
train=True,
download=True,
transform=train_transforms)
test_data = datasets.FashionMNIST(root="./data",
train=False,
download=True,
transform=test_transforms)
# 将数据集放入迭代器
batch_size = 2
train_loader = torch.utils.data.DataLoader(train_data,batch_size,shuffle=True)
test_loader = torch.utils.data.DataLoader(test_data,batch_size,shuffle=True)
# 查看迭代器中的图片和标签
# image,label = next(iter(train_loader))
# print("image.shape:{}\n,label.shape:{}".format(image.shape,label.shape))
# 搭建VGG-16网络
cfg = {
'VGG11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'VGG13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'VGG16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'VGG19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
class VGG(nn.Module):
# 网络初始化
def __init__(self,vgg_name):
super(VGG,self).__init__()
# 在容器中构建卷积网络
# net = models.vgg16(pretrained=False)
self.features = self.make_layers(cfg[vgg_name])
# self.features = net
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(512*7*7,4096),nn.ReLU(),nn.Dropout(),
nn.Linear(4096,4096),nn.ReLU(),nn.Dropout(),
nn.Linear(4096,10),nn.ReLU(),
)
# 不明白
def forward(self,x):
feature = self.features(x)
out = feature.view(feature.size(0), -1) # 将向量展成
# out = self.classifier(feature.view(x.shape[0],-1))
out = self.classifier(out)
return out
def make_layers(self,cfg):
layers = []
in_channel = 1
for x in cfg:
if x == "M":
layers += [nn.MaxPool2d(kernel_size=2,stride=2)]
else:
layers += [nn.Conv2d(in_channel,x,kernel_size=3,padding=1),
nn.BatchNorm2d(x),nn.ReLU()]
in_channel = x
return nn.Sequential(*layers) # 参数元组化
# 使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("device:",device)
# 网络实例化
net = VGG(vgg_name = 'VGG16').to(device)
# 设置损失函数
criterion = torch.nn.CrossEntropyLoss()
# 设置优化方式
optim = torch.optim.SGD(net.parameters(),lr=0.001,momentum=0.01)
epochs = 20
# 保存数据
write = torch.utils.tensorboard.SummaryWriter("run/example")
# 训练
train_loss = []
test_loss = []
for epoch in range(epochs):
losses = 0.0
for image,label in train_loader:
image,label = image.to(device),label.to(device)
optim.zero_grad() # 梯度置零
y_hat = net(image)
loss = criterion(y_hat,label)
loss.backward() # 后向传播
optim.step() # 更新参数
losses += loss.item()
else:
test_losses = 0
pr = 0
with torch.no_grad():
net.eval() # 关闭训练模式
for image,label in test_loader:
image,label = image.to(device),label.to(device)
y_hat = net(image)
loss = criterion(y_hat,label)
losses += loss.item()
# 返回矩阵的每一行的最大值和下标
ps = torch.exp(y_hat)
top_pos,top_class = ps.topk(1,dim=1)
equals = top_class == label.view(*top_class)
pr = torch.mean(equals.type(torch.FloatTensor))
net.train()
# 将训练误差和测试误差放到列表中
train_loss.append(losses/len(train_loader))
test_loss.append(test_loss/len(test_loader))
print("训练集训练次数:{}/{}:".format((epoch+1),epochs),
"训练误差:{:.3f}".format(losses/len(train_loader)),
"测试误差:{:.3f}".format(test_loss/len(test_loader)),
"模型分类准确率:{:.3f}".format(pr/len(test_loader)))
# # 可视化误差
# 将训练误差和测试误差数据从GPU转回CPU 并且将tensor->numpy (因为numpy 是cup only 的数据类型)
train_loss = np.array(torch.tensor(train_loss),device = "cpu")
test_loss = np.array(torch.tensor(test_loss),device = "cpu")
# 可视化
plt.plot(train_loss,labels="train_loss")
plt.plot(test_loss,label="test_loss")
plt.legend()
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号