RNN+Attention(HAN) 文本分类 阅读笔记
转自:https://zhuanlan.zhihu.com/p/42121435
Part I:论文模型
Part II:代码理解
Part III:后记
本文主要记录一下对 Hierarchical Attention Network for Document Classification (HAN)及其相应复现代码(tensorflow)的理解。
Part I:论文模型
一、直觉上的理解
要对一篇文章进行文本分类,人工的做法通常是抓住中心句或者中心词汇,并将其归类。那么,一篇文章中每个句子的重要程度、一个句子中每个词汇的重要程度,都是不一样的。不同的词汇和句子对文章的表达有不同的影响,词汇和句子的重要性是严重依赖于上下文的,即使是相同的词汇和句子,在不同的上下文中重要性也不一样。
当我们人对文章进行分类时,通常会将文章分成多个句子,再对每个句子进行分析,这个可以类比于我们平时做英语的阅读理解。于是论文的作者这样的分层思路,便提出了论文中的模型。
二、论文模型
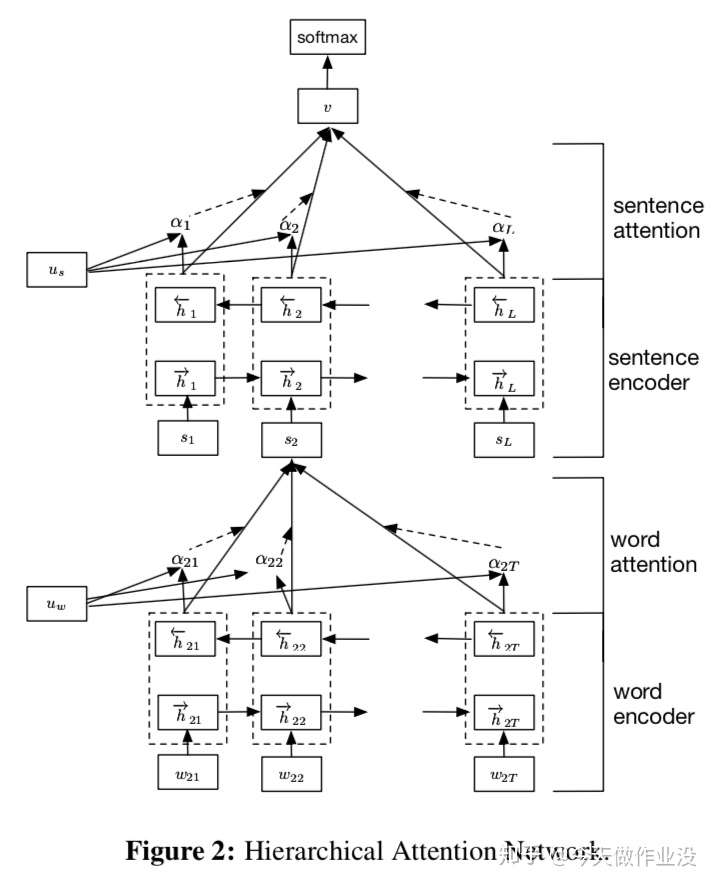 HAN 论文模型
HAN 论文模型
其实模型是相对简单且好理解的。从下往上看,其实只是一些层的叠加。
- word encoder:对词汇进行编码,建立词向量。接着用双向 GRU 从单词的两个方向汇总信息来获取单词的注释,因此将上下文信息合并到句子向量中。
- word attention:接着对句子向量使用 Attention 机制。
- sentence encoder:与上面一样,根据句子向量,使用双向 GRU 构建文档向量。
- sentence attention:对文档向量使用 Attention 机制。
- softmax:常规的输出分类结果。
三、两向 GRU 的好处
单向的 RNN(LSTM、GRU),是根据前面的信息推出后面的,但有时候只看前面的词是不够的,
例如,
我今天不舒服,我打算__一天。
只根据‘不舒服‘,可能推出我打算‘去医院‘,‘睡觉‘,‘请假‘等等,
但如果加上后面的‘一天‘,能选择的范围就变小了,‘去医院‘这种就不能选了,
而‘请假‘‘休息‘之类的被选择概率就会更大。
四、Attention 机制的个人理解
举个翻译的例子,比如将“我爱机器学习”逐词翻译成“I love machine learning”。
在翻译“机器学习”的时候,前面的“我爱”对“机器学习”的影响并不是特别大,所以我们可以将大部分“注意力”集中在“机器学习”,极小的“注意力”放在“我爱”上;而不用留意整个句子(无注意力机制)。
文中作者使用的 attention 其实只是 mlp + softmax:
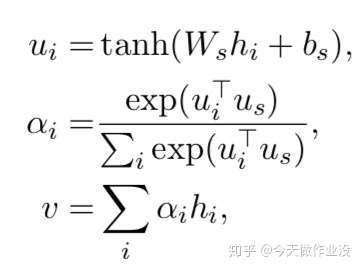
关于注意力机制原理的图,感觉并不太好理解。相关论文:FEED-FORWARD NETWORKS WITH ATTENTION CAN SOLVE SOME LONG -TERM MEMORY PROBLEMS
Part II:代码理解
这里主要讲一下对 论文复现代码(很详细) 的理解吧。反正我自己是不会写= =。
代码链接:https://github.com/lc222/HAN-text-classification-tf
博主的代码其实是有一些问题的,我做了一点小修改,但是还有 bug。不知道咋解决了。
直接贴修改的代码吧
DataUtils.py
#将所有的评论文件都转化为30*30的索引矩阵,也就是每篇都有30个句子,每个句子有30个单词
# 不够的补零,多余的删除,并保存到最终的数据集文件之中
with open('yelp_academic_dataset_review.json', 'rb') as f:
for line in f:
doc = []
review = json.loads(line)
sents = sent_tokenizer.tokenize(review['text'])
for i, sent in enumerate(sents):
if i < max_sent_in_doc:
word_to_index = []
for j, word in enumerate(word_tokenizer.tokenize(sent)):
if j < max_word_in_sent:
word_to_index.append(np.array(vocab.get(word, UNKNOWN)))
#add padding
npad = (0,30-len(word_to_index))
word_to_index = np.pad(word_to_index, pad_width=npad, mode='constant', constant_values=0)#padding
doc.append(np.array(word_to_index))
label = int(review['stars'])
labels = [0] * num_classes
labels[label-1] = 1
data_y.append(labels)
# print(np.array(doc).shape)
# print(np.array(doc).ndim)
#add padding
if np.array(doc).ndim == 1:
continue
npad2 = ((0,30-len(doc)), (0,0))