Spring-依赖注入
Spring依赖注入
本文将尝试深入Spring源码,来理解Spring实现依赖注入的原理。
首先要明白一个关键点:创建Bean和依赖注入是两个不同的操作。Spring是先创建一个Bean,后注入这个Bean的依赖(有特例,后面讲)。
Spring 创建 Bean 通常情况下是使用构造函数(构造器)创建的(也有使用工厂方法创建的,这个不唯一,我们重点关注构造函数创建 Bean)。若类中没有显式定义构造器,则默认使用无参构造函数创建Bean。
构造函数注入依赖
在此之前我们大都听说过 循环依赖,在Spring框架下是使用 三级缓存 来解决循环依赖的。
但是如果这个循环依赖是有构造函数注入依赖而引发的,那么Spring就会报错。
下面举个通过构造函数引入依赖的例子:
@Component
public class PeopleOne {
private PeopleTwo peopleTwo;
@Autowired
public PeopleOne(PeopleTwo peopleTwo){
this.peopleTwo = peopleTwo;
System.out.println("PeopleOne");
}
}
@Component
public class PeopleTwo {
private PeopleOne peopleOne;
@Autowired
public PeopleTwo(PeopleOne peopleOne){
this.peopleOne = peopleOne;
System.out.println("PeopleTwo");
}
}
在上面的例子中我们可以看到,PeopleOne的实例化需要依赖PeopleTwo的创建,而PeopleTwo的实例化也依赖于PeopleOne的创建。但是在实际运行时会报出如下错误:

为什么?
构造函数注入导致的循环依赖无法解决,是因为在实例化过程中双方都需要对方的完全初始化实例,而Spring无法在构造阶段处理这种相互依赖。而其他注入方式允许在对象创建后设置依赖,因此可以解决循环依赖的问题。
这样解释不够清晰,我们深入源码来看看构造函数注入依赖时,Spring是如何实例化Bean的。
走源码
我们的测试示例不使用循环依赖的例子,而是完整地测试一下正确的构造函数注入依赖过程:
@Component
public class PeopleOne {
private PeopleTwo peopleTwo;
@Autowired
public PeopleOne(PeopleTwo peopleTwo){
this.peopleTwo = peopleTwo;
System.out.println("PeopleOne");
}
}
@Component
public class PeopleTwo {
public PeopleTwo(){
System.out.println("PeopleTwo");
}
}
Main.class中的代码如下:
@Configuration
@ComponentScan("com.lck")
public class Main {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(Main.class);
System.out.println("Hello world!");
}
}
首先从main方法开始,点击进入AnnotationConfigApplicationContext类,主要关注refresh方法,实例化Bean和注入依赖的操作都是在该方法中实现:
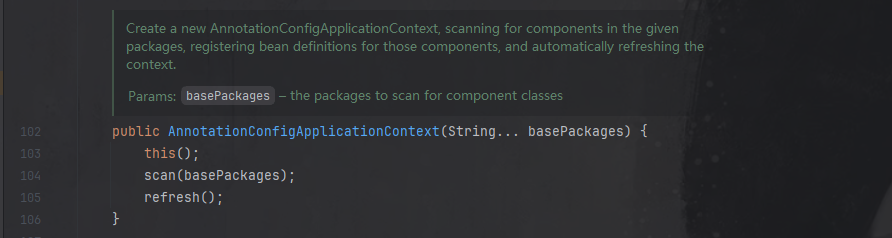
在refresh中重点关注finishBeanFactoryInitialization(beanFactory);方法。
- 核心任务:实例化所有 非延迟加载的单例 Bean。
- 关键步骤:
- 初始化 ConversionService:处理类型转换。
- 冻结配置:禁止修改 Bean 定义。
- 预实例化单例:调用
getBean()触发 Bean 的创建、依赖注入和初始化。
这里解释一下什么是延迟加载和非延迟加载的单例Bean。
- 非延迟加载的单例 Bean 是容器在启动阶段立即初始化的单例对象。这种 Bean 的创建和依赖注入在应用上下文初始化时完成。
- 延迟加载(Lazy Loading) 指的是在 首次访问时才创建对象,而不是在应用启动时立即初始化。在 Spring 中,可以通过
@Lazy注解实现延迟加载的单例 Bean。
比如我用 @Lazy 注解标注一个类,实际上在启动时不会创建这个类的Bean;
@Lazy
@Component
public class PeopleThree {
public PeopleThree() {
System.out.println("PeopleThree");
}
}
启动后的结果如下,并没有打印创建 PeopleThree 的 Bean 时必然打印的内容 “PeopleThree”:
在经过我们一系列的跳过之后,进入关键方法doGetBean:
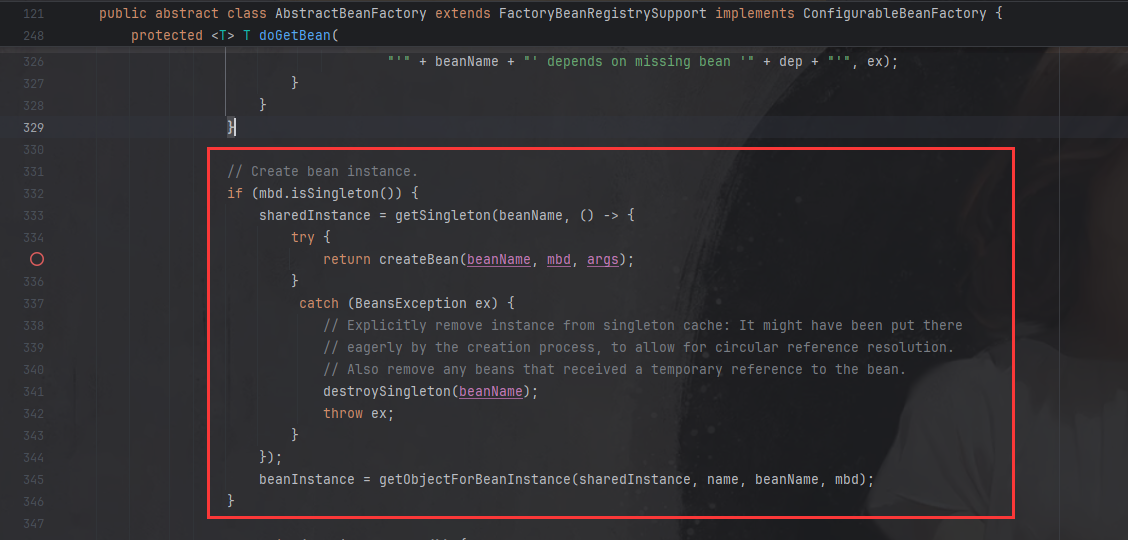
这段代码是Spring框架中创建Bean实例的部分。代码开头有一个条件判断,mbd.isSingleton(),这是在检查当前Bean的作用域是否是单例。如果是单例的话,就会执行后面的逻辑。
接下来,sharedInstance = getSingleton(...),这里调用了getSingleton方法,并且传入了一个Lambda表达式作为参数。getSingleton方法的作用是从单例缓存中获取已经存在的Bean实例(显而易见我们还没创建Bean,所以是肯定获取不到的),如果不存在的话,就通过createBean方法来创建新的实例。这里用到了双检锁或者缓存机制来保证单例的唯一性,避免重复创建。
在createBean方法中调试后,我们发现实际创建 Bean 会在doCreateBean方法中实现:
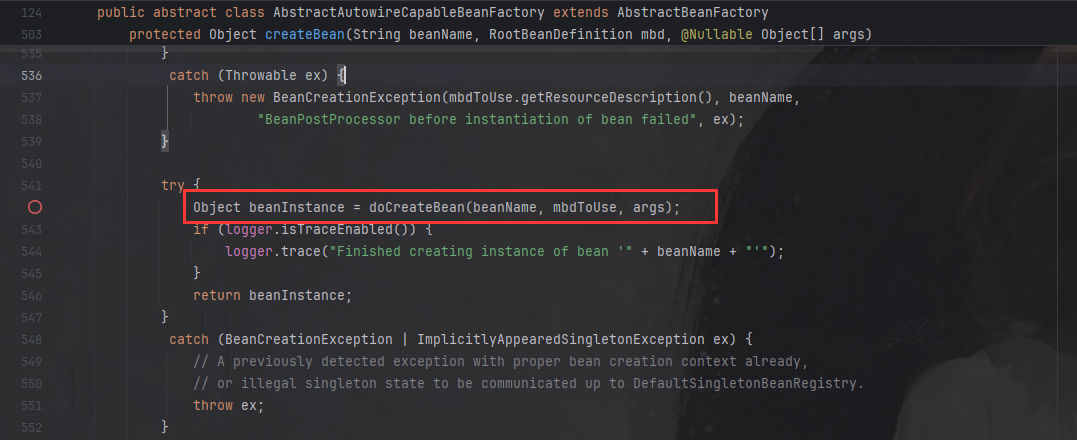
在doCreateBean方法中有一个关键的createBeanInstance方法,这个方法太重要了,所有实例化的操作都在这个方法中实现:
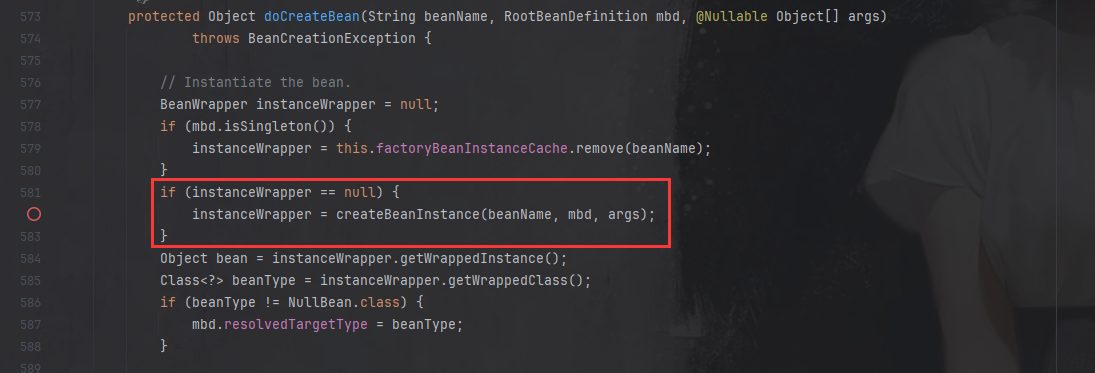
而 createBeanInstance 中的具体实现我们先不关心,我们先搞明白在执行完 createBeanInstance 方法后,控制台的输出情况。
我们上面给出的两个类中,PeopleOne 通过构造函数注入依赖,在调试执行完 createBeanInstance 方法后,控制台的执行结果如下:
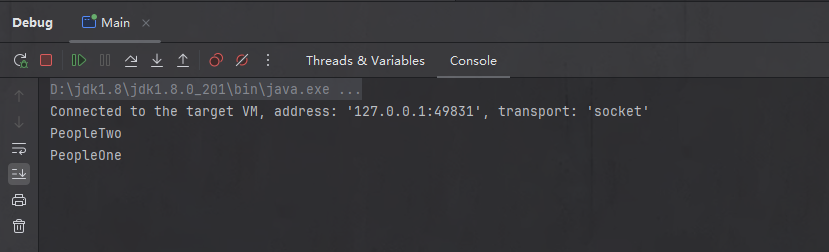
这说明什么?这里我们正在调试 PeopleOne 类的 Bean 创建过程,而在此之前PeopleTwo的Bean还没创建,为什么实际上却是先输出 PeopleTwo 的 Bean 的结果,然后再输出 PeopleOne 的实例化结果?
结果显而易见,就是在createBeanInstance方法中,要创建 PeopleOne 的 Bean 时,发现构造函数中有 PeopleTwo 对象作为参数,因此需要先创建 PeopleTwo 的 Bean,在创建完 PeopleTwo 的 Bean 后,再返回来继续创建 PeopleOne 的 Bean。
因此我们说构造函数注入依赖是在实例化时完成的,通过 createBeanInstance 一个方法就将实例化和注入依赖全都实现。
setter方法注入依赖
下面我们再调试一下使用setter方法注入依赖,比较一下和构造函数注入依赖的不同之处。将PeopleOne类中注入依赖的方式改一下,PeopleOne 的实例化用无参构造函数实现,但是依赖注入用setter方法实现。
@Component
public class PeopleOne {
private PeopleTwo peopleTwo;
public PeopleOne() {
System.out.println("PeopleOne: Instantiation PeopleOne But Not DI");
}
@Autowired
public void setPeopleTwo(PeopleTwo peopleTwo) {
this.peopleTwo = peopleTwo;
System.out.println("PeopleOne: After DI");
}
}
经过一系列调试之后,代码仍然走到 createBeanInstance 方法处:
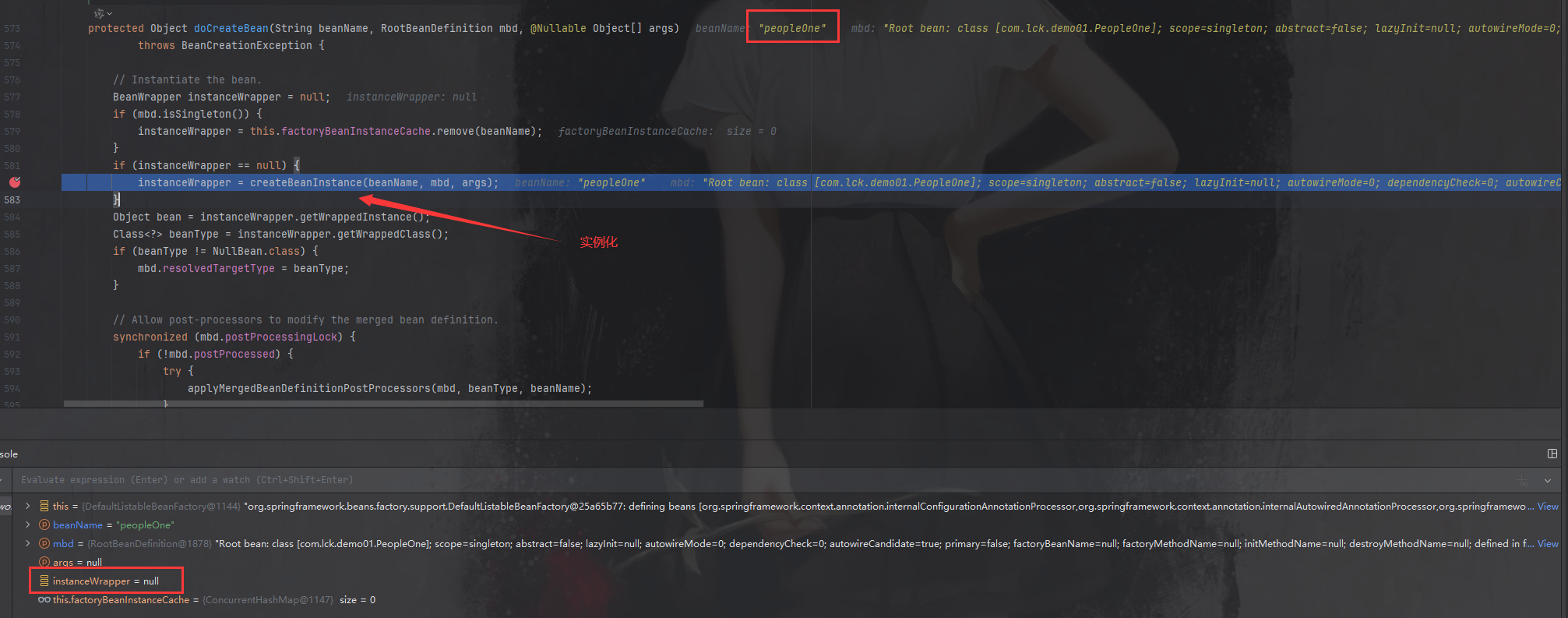
此时的控制台如下,空空如也,这说明PeopleOne仍然还没有实例化,也没有注入依赖。
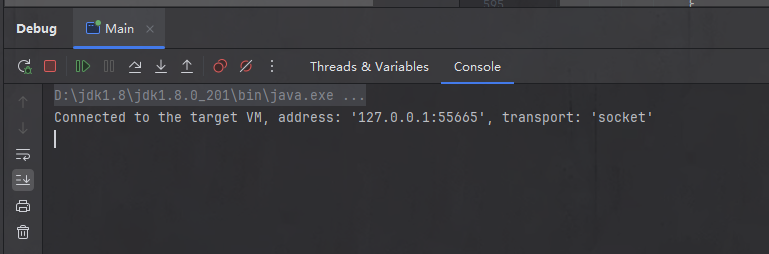
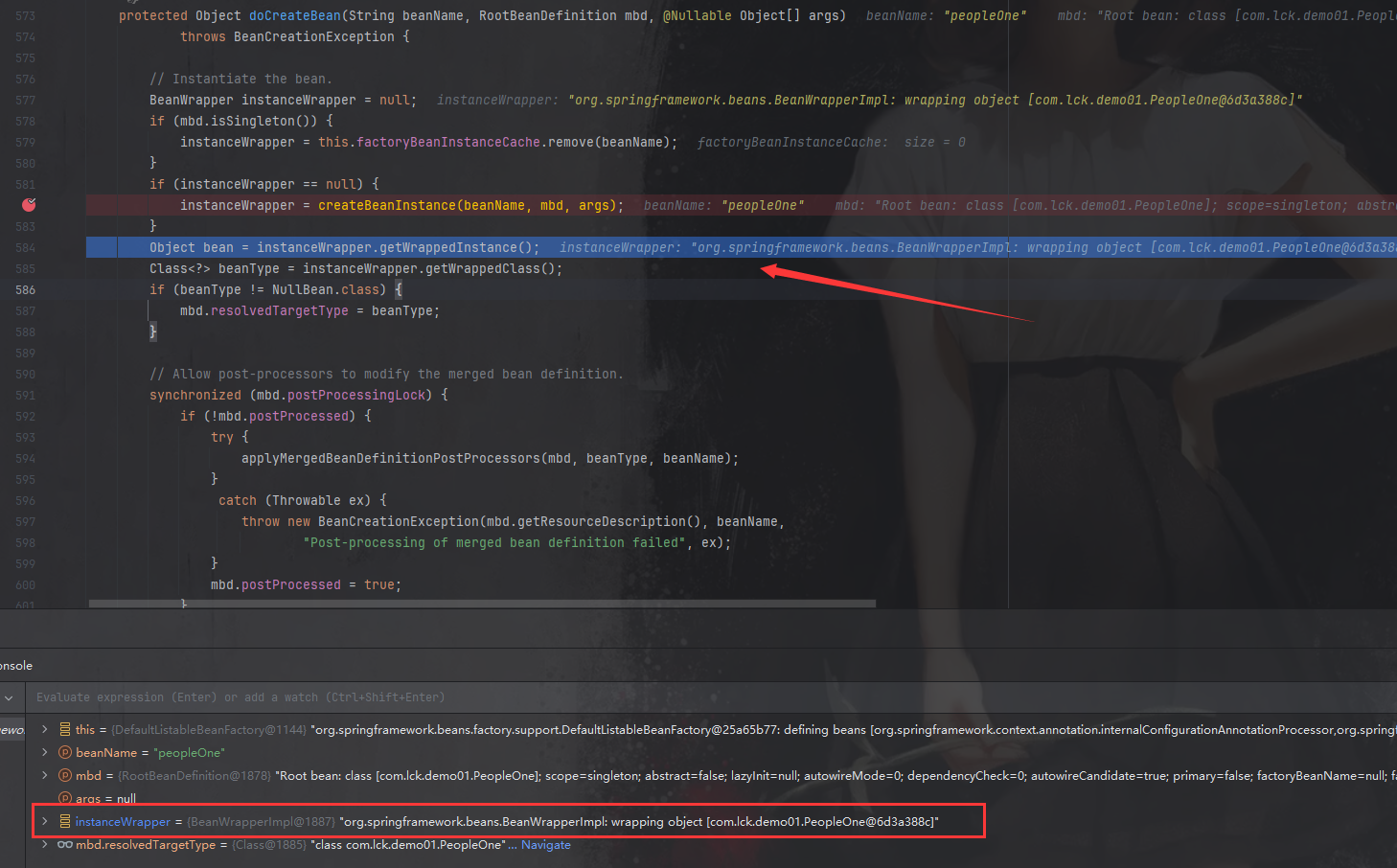
但是,当我们执行完createBeanInstance后,一切都变了,instanceWrapper 不再是一个null值,而是有了具体的对象,这个对象就是实例化后的 PeopleOne 的Bean,说明此时 PeopleOne 的 Bean 已经创建完成。
控制台也输出了创建 Bean 时会输出的内容,即 PeopleOne 的无参构造方法中打印的内容。
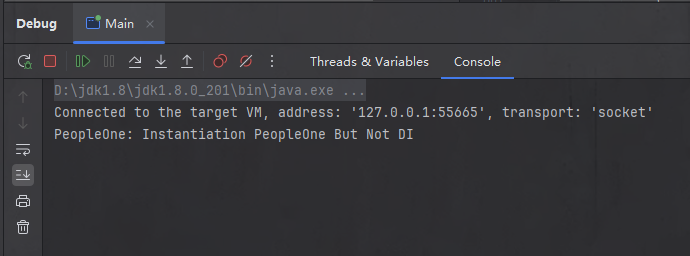
但是此时却没有打印注入依赖时会打印的内容:"PeopleOne: After DI"
这说明什么?这说明使用setter注入依赖的方式,是在Bean实例化之后才会执行注入依赖的操作。
还记得上面提到的构造函数注入依赖吗?使用构造函数注入依赖时,当执行完createBeanInstance方法后,不仅Bean创建完成了,对应的依赖也注入完成了。这里就能体现出两种依赖注入方式的不同。
这个暂且不管,我们继续往下debug。代码走到如下所示位置的时候,也显而易见了,源码的注释就已经解释地很清楚,这一步是给Bean注入属性并且初始化的。
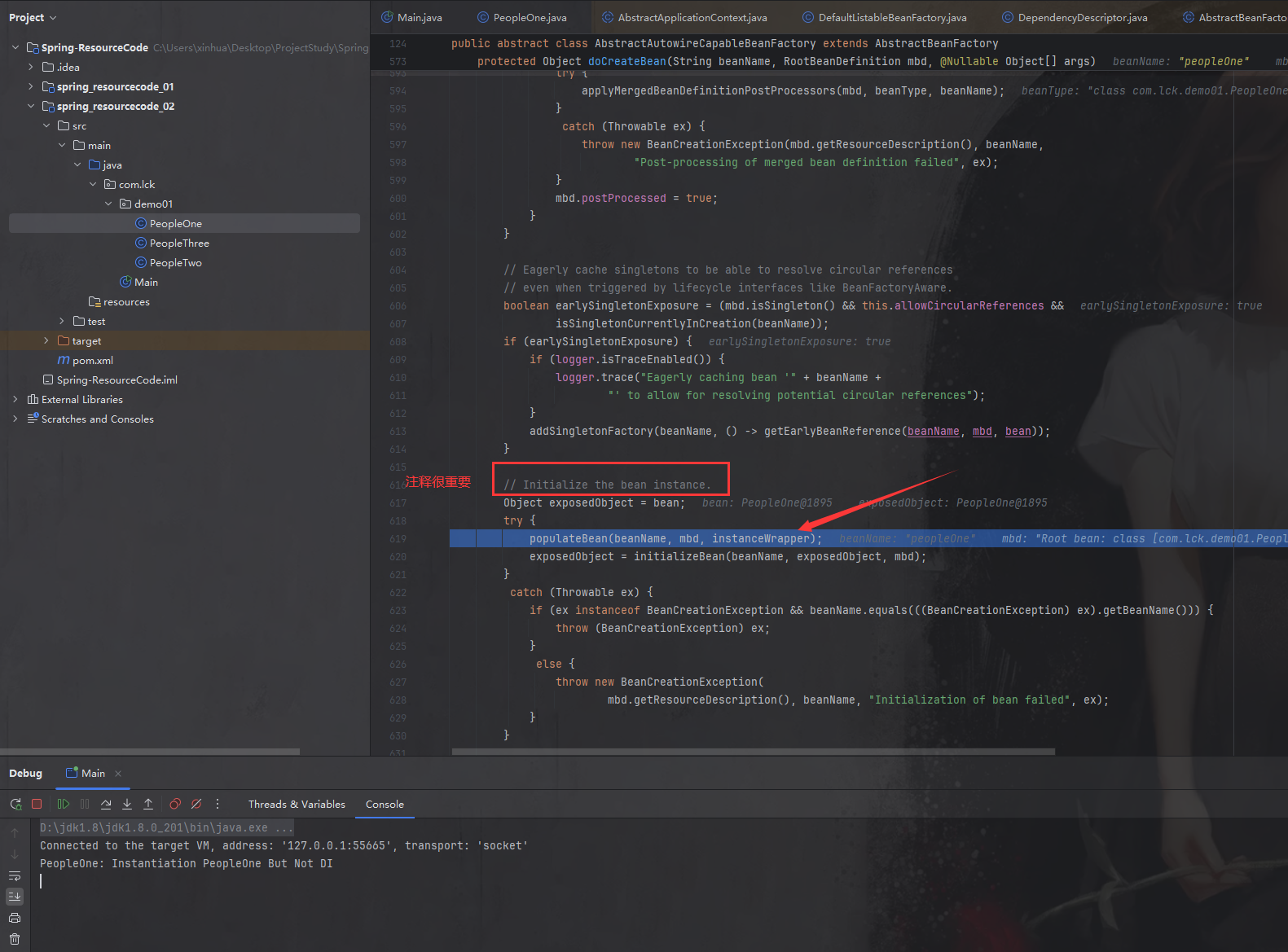
这里的populateBean方法就很重要了。
- 目标:将 Bean 的依赖(其他 Bean、配置值等)注入到其属性中。
- 完成事项:
- 通过
@Autowired、@Resource、@Value等注解注入字段或方法参数。 - 通过 XML 配置的
<property>标签设置属性值。 - 处理自动装配(
byName或byType)。
- 通过
- 此时 Bean 的状态:
Bean 的 属性已被赋值,但可能尚未准备好使用(例如:依赖的资源未初始化)。
我们看到在注入依赖之后,还会有初始化的操作,而初始化阶段在依赖注入之后执行,目标是 让 Bean 进入可用状态,主要完成以下操作:
| 初始化操作 | 说明 |
|---|---|
执行 @PostConstruct 方法 |
在依赖注入完成后执行自定义初始化逻辑(例如:启动后台线程、预加载缓存)。 |
实现 InitializingBean 接口 |
调用 afterPropertiesSet() 方法(Spring 原生接口,类似 @PostConstruct)。 |
XML 中配置的 init-method |
通过 XML 的 init-method 属性指定初始化方法。 |
| AOP 代理的生成 | 某些代理对象(如 @Transactional)在此阶段生成,确保代理覆盖所有初始化后的 Bean。 |
初始化的过程我们先不管,主要还是关注依赖注入,当我们执行完populateBean之后,控制台打印展示如下:
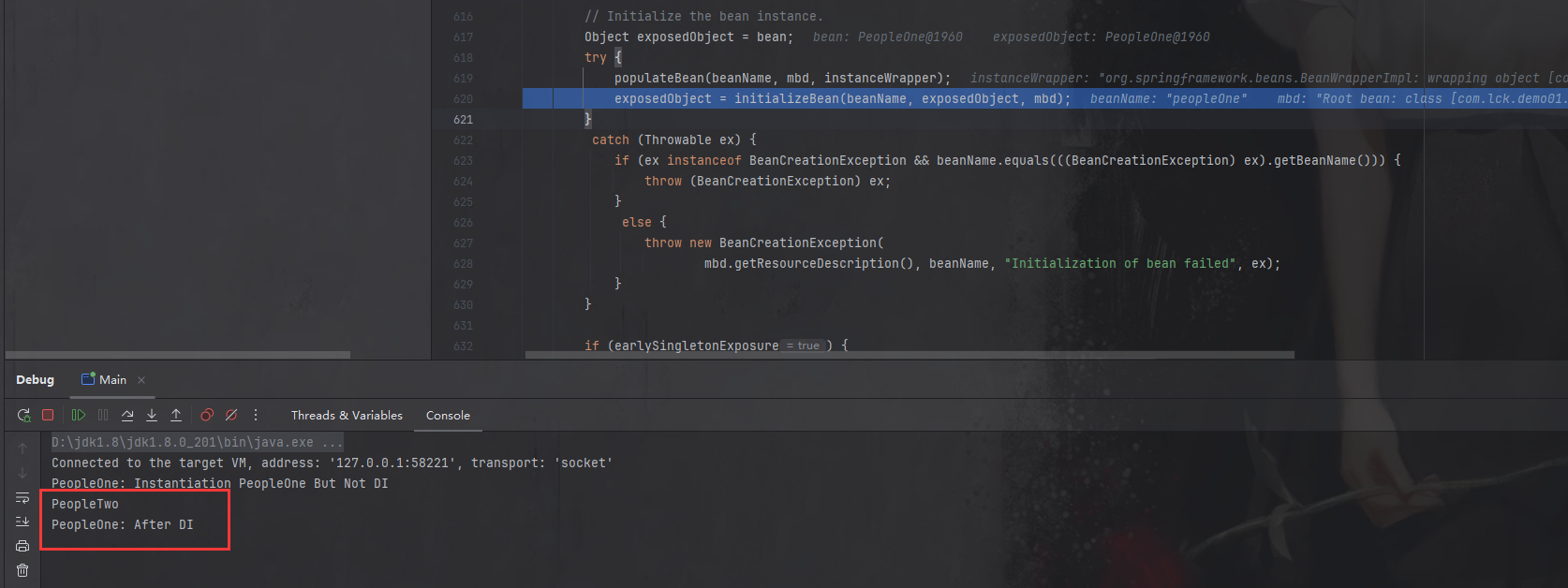
这说明在populateBean方法中就完成了依赖的注入。
这里就很明显了:构造函数注入依赖的方式中,Bean的实例化和依赖注入都是在 createBeanInstance 方法中实现,两者不能独立实现。但是使用 setter 方法注入依赖时,createBeanInstance 就实现了创建 Bean,具体的依赖注入是放在 populateBean 方法中实现的,两个步骤分开实现,就解决了循环依赖的问题。当 创建完 A 的 Bean (此时 A 的 Bean 只是半成品)后,注入依赖时,发现需要 B 的 Bean,可以立马去创建 B 的 Bean,在创建 B 的 Bean 时,发现 B 需要 A 的 Bean,此时 A 已经有对应的 Bean 了,因此 B 可以直接完成创建并注入依赖。B 创建完成后,可以再返回来继续给 A 注入依赖。循环依赖就解决了。
**整个spring源码内容太多太复杂了,各种封装继承、设计模式等等。因此本人只能在debug中浅显了解一下spring创建Bean并且注入依赖的过程。精力有限,后面有空再继续更新其他注入依赖的方式吧**
本文来自博客园,作者:maoxianjia,转载请注明原文链接:https://www.cnblogs.com/mxj-lck/p/18844275

 浙公网安备 33010602011771号
浙公网安备 33010602011771号