《Rotate to Attend: Convolutional Triplet Attention Module》&《GINet: Graph Interaction Network for Scene Parsing》阅读
《Rotate to Attend: Convolutional Triplet Attention Module》
一、摘要
- 研究了轻量且有效的注意力机制
- 提出Triplet Attention:使用Triplet Branch结构捕获跨维度交互(?)来计算注意力权重的新方法。可以解决Cross-dimension的缺点。
二、相关方法
学习注意力权重背后是让网络有能力学习关注哪里,并进一步关注目标对象。些Attention机制通过建立Channel之间的依赖关系或加权空间注意Mask有能力改善由标准CNN生成的特征表示。
- Channel Attention
- Spatial Attention
- 两者结合
例子:
![]()

以上大多数方法都有明显的缺点(Cross-dimension),Triplet Attention解决了这些缺点。
Triplet Attention模块旨在捕捉Cross-dimension交互,从而能够在一个合理的计算开销内(与上述方法相比可以忽略不计)提供显著的性能收益。
三、Triplet Attention方法
目标:如何在不涉及任何维数降低的情况下,建立廉价但有效的通道注意力模型?
本文:riplet Attention实现了几乎无参数的注意机制来建模通道注意和空间注意
3.1 Triplet Attention结构
由3个平行的Branch组成
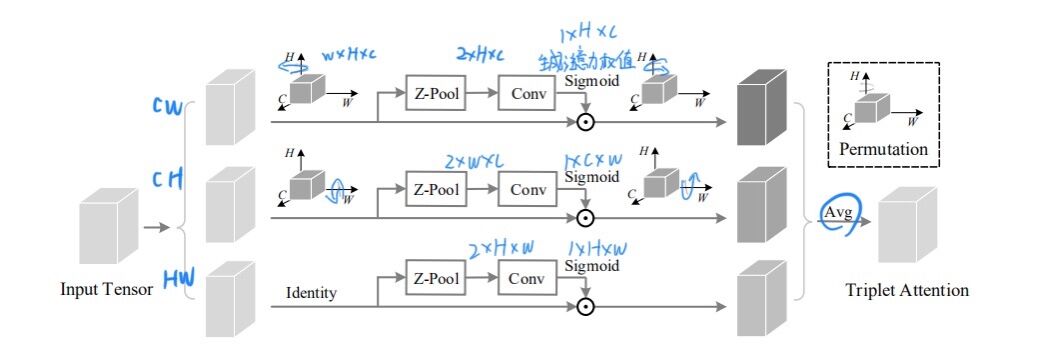
最终输出的张量: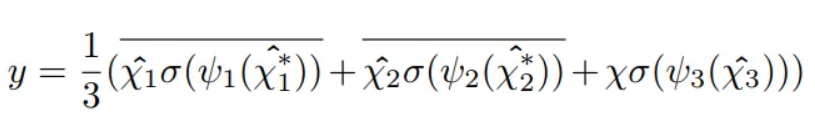
3.2 Complexity Analysis
与其他方法的比较,C为该层的输入通道数,r为MLP在计算通道注意力时瓶颈处使用的缩减比,用于2D卷积的核大小用k表示,k<<<C。
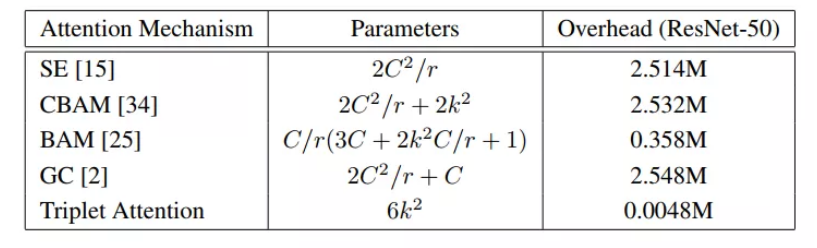
从图表对比来看,Triplet Attention方法确实很轻量。
3.3 实验结果
-
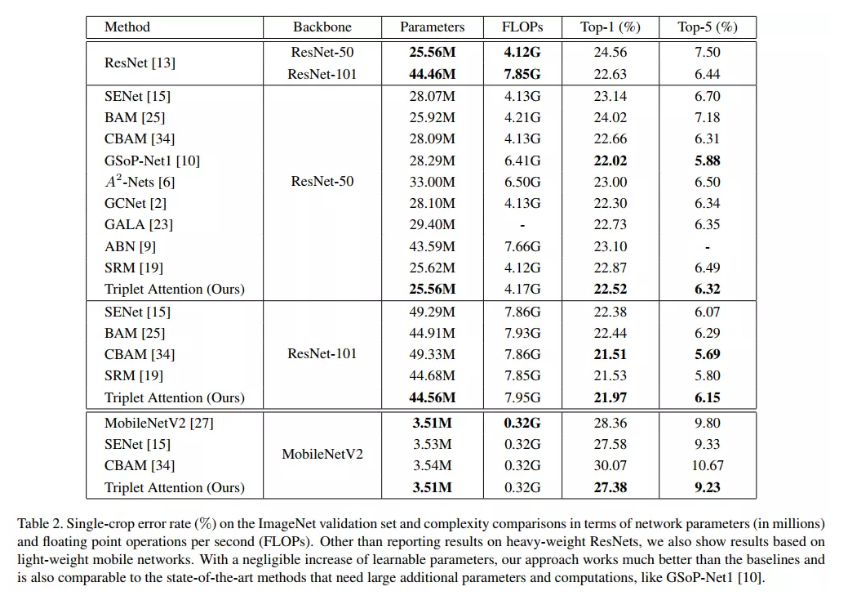
图像分类
![]()
-
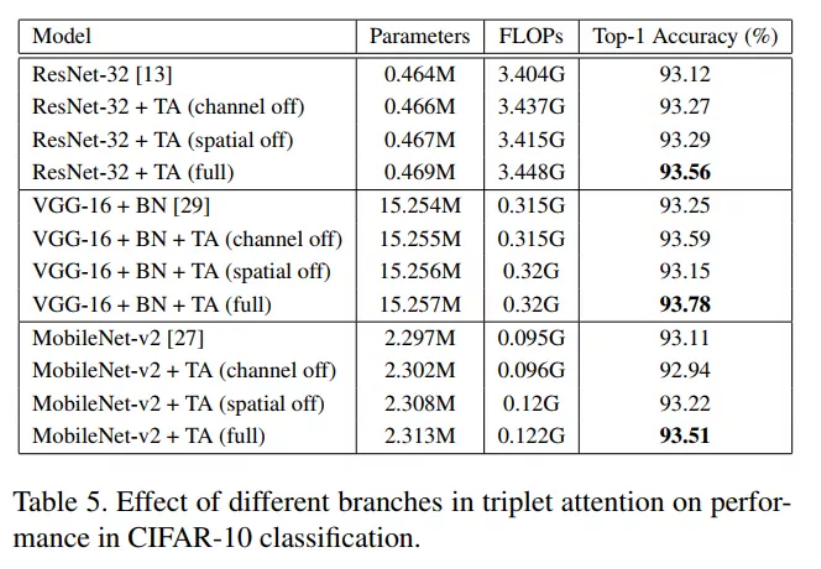
目标检测实验
![]()
![]()
-
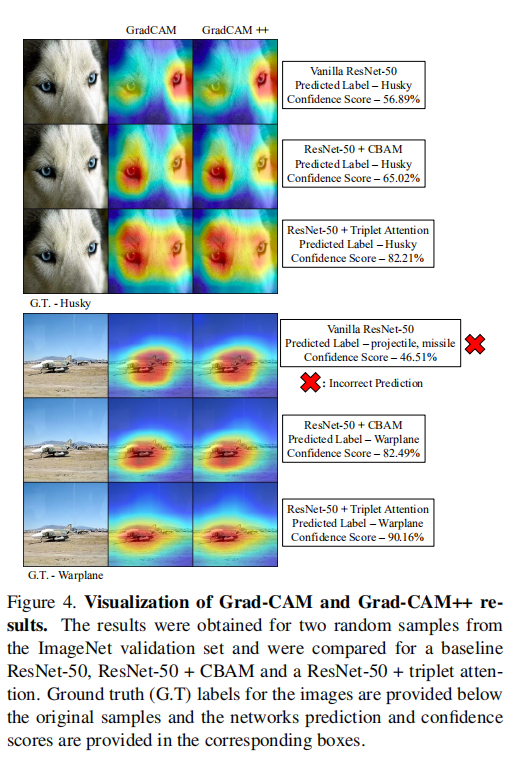
消融实验
![]()
-
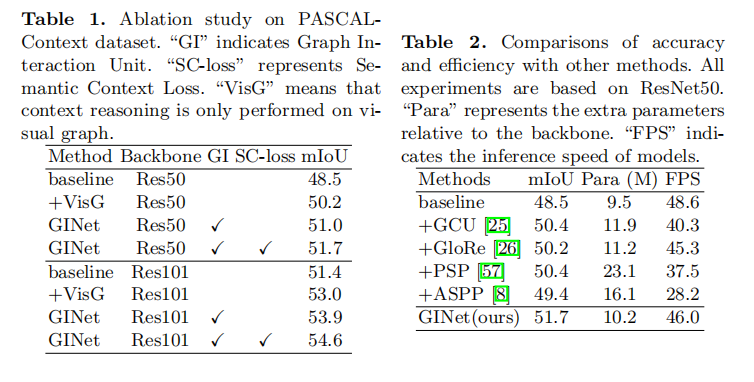
HeatMap输出对比
![]()

四、总结
本文提出Triplet Attention,它抓住了张量中各个维度特征的重要性。Triplet Attention使用了一种有效的注意计算方法,不存在任何信息瓶颈(?)。
实验证明,Triplet Attention提高了ResNet和MobileNet等标准神经网络架构在ImageNet上的图像分类和MS COCO上的目标检测等任务上的Baseline性能,而只引入了最小的计算开销。是一个非常不错的即插即用的注意力模块。
《GINet: Graph Interaction Network for Scene Parsing》
一、摘要
主要意义尝试在语义分割框架中引入额外的语义上下文信息
大部分语义分割的方法都是基于输入图像,也就是视觉特征进行分类(FCN/PSP/DeepLab),但这样就缺少了不同类别间的上下文相关性。 non-local可以通过计算不同像素之间的相关性来建立上下文关系,但计算量较大。于是有人试图将图卷积神经网络(GCN)加入到语义分割中,将特征空间中的一些区域映射到图空间中,每个节点代表不同的区域。对图空间做图卷积的话,就相当于捕捉不同区域之间的关系。之后再将图空间映射回特征空间。
二、相关方法
GCN with segmentation
首先把特征从特征空间投射到图空间,再在图空间进行卷积,捕捉区域之间的关系,最后把特征从图空间返投射到特征空间。
- GloRe
- GCU
- SGR
- LatentGNN
三、本文方法
3.1 推理视觉区域之间的关系 + 语义概念

框架

- 作者使用预训练好的ResNet作为backbone提取视觉特征。随后,作者将图像中的类别以文本的形式提取出来经过word embedding(如GloVe),将单词映射到方便处理的多维向量。
- 将视觉特征和文本特征经过graph projection投射到图空间,分别构建两个图VisG和SemG。此时VisG中的节点表示某一区域的视觉特征,边表示不同区域之间的关系。SemG中的节点和边表示经过word embedding后的文本特征和文本间的关系。
- 在GI Unit中进行图交互graph interaction,利用文本图的语义信息指导视觉图的形成。
- 将经过GI Unit处理后的图重新投影到特征空间,并通过1*1的卷积和上采样的到最终结果。
3.2 实验
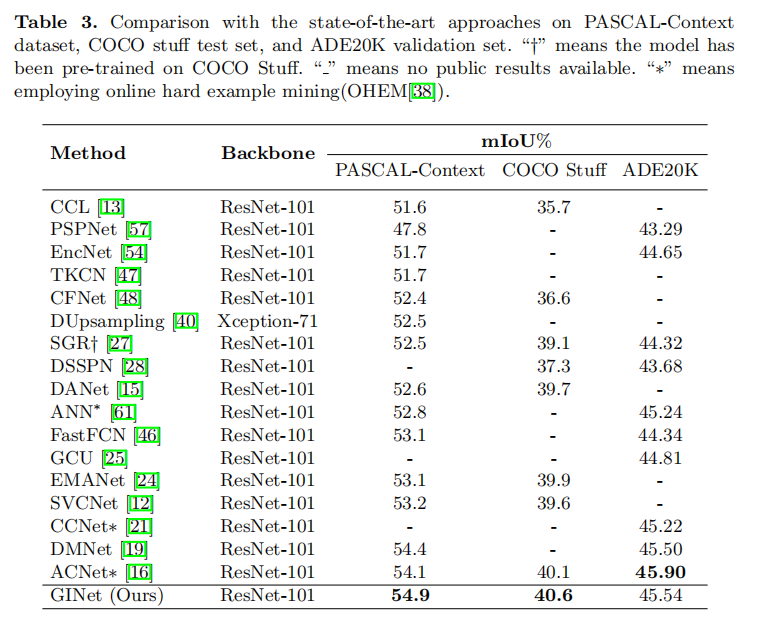
结果可视化
不同节点对应不同范围

四、总结
- 提出了一种新的图交互单元GI unit用于上下文建模
- 提出了Semantic Context Loss (SC-loss) 用来强调出现在场景中的类别,抑制没有出现的类别
- 提出了一种图交互网络GINet

 浙公网安备 33010602011771号
浙公网安备 33010602011771号