第二次作业:卷积神经网络 part 2
【第一部分】 问题总结
【第二部分】 代码练习
《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》
· MobileNets是谷歌公司在2017年发布的一种可以在手机等移动终端运作的神经网络结构。
· MobileNet和传统的CNN在结构上的差别主要是,传统CNN中在batch normalization和ReLU(线性整流函数)前边,是一个3×3卷积层,而MobileNet将卷积过程分为一个3×3深度方向的卷积和一个1×1点对点的卷积。
Mobilenet v1核心是把卷积拆分为Depthwise+Pointwise两部分。Depthwise 处理一个三通道的图像,使用3×3的卷积核,完全在二维平面上进行,卷积核的数量与输入的通道数相同,所以经过运算会生成3个feature map。卷积的参数为: 3 × 3 × 3 = 27,如下所示:
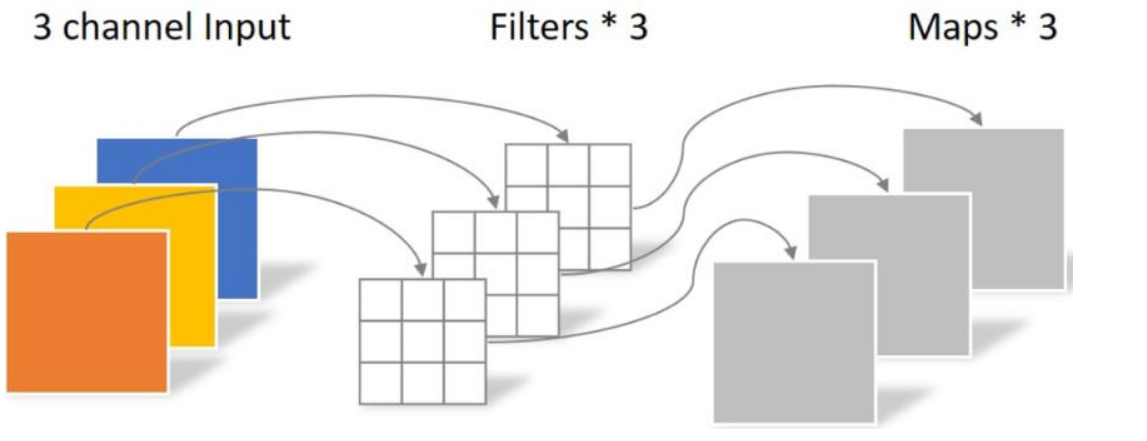
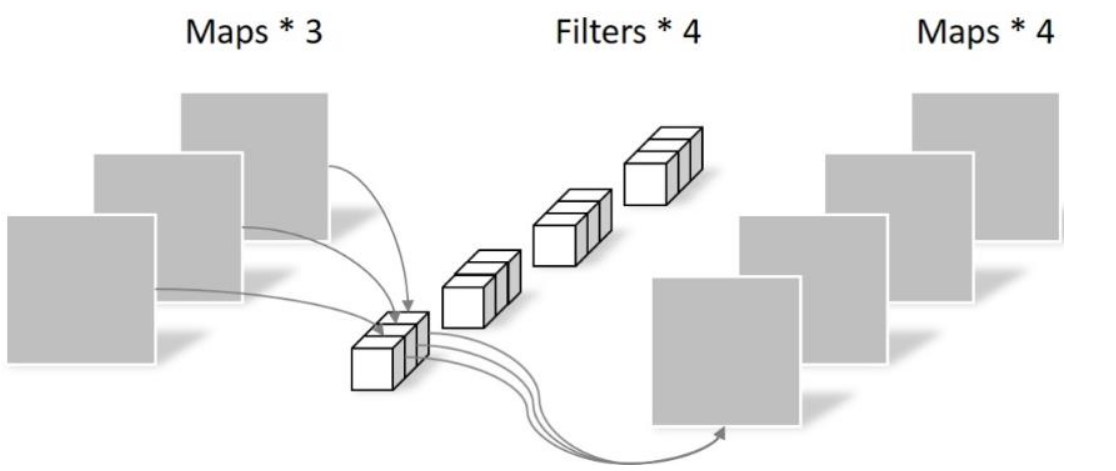
Pointwise 不同之处在于卷积核的尺寸为1×1×k,k为输入通道的数量。所以,这里的卷积运算会将上一层的feature map加权融合,有几个filter就有几个feature map,参数数量为:1 × 1 × 3 × 4 = 12
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
class Block(nn.Module):
'''Depthwise conv + Pointwise conv'''
def __init__(self, in_planes, out_planes, stride=1):
super(Block, self).__init__()
# Depthwise 卷积,3*3 的卷积核,分为 in_planes,即各层单独进行卷积
self.conv1 = nn.Conv2d(in_planes, in_planes, kernel_size=3, stride=stride, padding=1, groups=in_planes, bias=False)
self.bn1 = nn.BatchNorm2d(in_planes)
# Pointwise 卷积,1*1 的卷积核
self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(out_planes)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
return out
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=False, num_workers=2)
#创建 MobileNetV1 网络
class MobileNetV1(nn.Module):
# (128,2) means conv planes=128, stride=2
cfg = [(64,1), (128,2), (128,1), (256,2), (256,1), (512,2), (512,1),
(1024,2), (1024,1)]
def __init__(self, num_classes=10):
super(MobileNetV1, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.layers = self._make_layers(in_planes=32)
self.linear = nn.Linear(1024, num_classes)
def _make_layers(self, in_planes):
layers = []
for x in self.cfg:
out_planes = x[0]
stride = x[1]
layers.append(Block(in_planes, out_planes, stride))
in_planes = out_planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layers(out)
out = F.avg_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
# 网络放到GPU上
net = MobileNetV1().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
#模型训练
for epoch in range(10): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')
#模型测试
correct = 0
total = 0
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %.2f %%' % (
100 * correct / total))
模型训练结果
Epoch: 1 Minibatch: 1 loss: 2.370
Epoch: 1 Minibatch: 101 loss: 1.700
Epoch: 1 Minibatch: 201 loss: 1.618
Epoch: 1 Minibatch: 301 loss: 1.508
Epoch: 2 Minibatch: 1 loss: 1.268
Epoch: 2 Minibatch: 101 loss: 1.376
Epoch: 2 Minibatch: 201 loss: 1.397
Epoch: 2 Minibatch: 301 loss: 1.317
Epoch: 3 Minibatch: 1 loss: 1.205
Epoch: 3 Minibatch: 101 loss: 1.227
Epoch: 3 Minibatch: 201 loss: 1.075
Epoch: 3 Minibatch: 301 loss: 1.157
Epoch: 4 Minibatch: 1 loss: 1.022
Epoch: 4 Minibatch: 101 loss: 1.187
Epoch: 4 Minibatch: 201 loss: 1.156
Epoch: 4 Minibatch: 301 loss: 0.968
Epoch: 5 Minibatch: 1 loss: 0.935
Epoch: 5 Minibatch: 101 loss: 0.714
Epoch: 5 Minibatch: 201 loss: 0.968
Epoch: 5 Minibatch: 301 loss: 0.759
Epoch: 6 Minibatch: 1 loss: 0.838
Epoch: 6 Minibatch: 101 loss: 0.806
Epoch: 6 Minibatch: 201 loss: 0.712
Epoch: 6 Minibatch: 301 loss: 0.851
Epoch: 7 Minibatch: 1 loss: 0.595
Epoch: 7 Minibatch: 101 loss: 0.854
Epoch: 7 Minibatch: 201 loss: 0.752
Epoch: 7 Minibatch: 301 loss: 0.775
Epoch: 8 Minibatch: 1 loss: 0.483
Epoch: 8 Minibatch: 101 loss: 0.773
Epoch: 8 Minibatch: 201 loss: 0.610
Epoch: 8 Minibatch: 301 loss: 0.760
Epoch: 9 Minibatch: 1 loss: 0.494
Epoch: 9 Minibatch: 101 loss: 0.409
Epoch: 9 Minibatch: 201 loss: 0.551
Epoch: 9 Minibatch: 301 loss: 0.774
Epoch: 10 Minibatch: 1 loss: 0.538
Epoch: 10 Minibatch: 101 loss: 0.537
Epoch: 10 Minibatch: 201 loss: 0.604
Epoch: 10 Minibatch: 301 loss: 0.523
Finished Training
模型测试结果

跟其他的那些大型、消耗巨大资源的神经网络相比,MobileNet的准确性不如前者高,但是MobileNet的优势是能够在功耗和性能之间寻求良好的平衡点。
《MobileNetV2: Inverted Residuals and Linear Bottlenecks》
MobileNet V1 的主要问题: 结构非常简单,但是没有使用RestNet里的residual learning;另一方面,Depthwise Conv确实是大大降低了计算量,但实际中,发现不少训练出来的kernel是空的。
MobileNet V2 的主要改动一:设计了Inverted residual block
ResNet中的bottleneck,先用1x1卷积把通道数由256降到64,然后进行3x3卷积,不然中间3x3卷积计算量太大。所以bottleneck是两边宽中间窄(也是名字的由来)。
现在我们中间的3x3卷积可以变成Depthwise,计算量很少了,所以通道可以多一些。所以MobileNet V2 先用1x1卷积提升通道数,然后用Depthwise 3x3的卷积,再使用1x1的卷积降维。作者称之为Inverted residual block,中间宽两边窄。
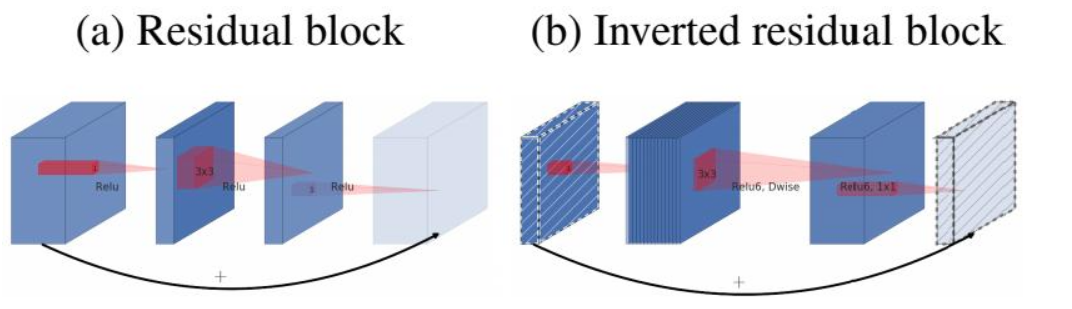
MobileNet V2 的主要改动二:去掉输出部分的ReLU6
在 MobileNet V1 里面使用 ReLU6,ReLU6 就是普通的ReLU但是限制最大输出值为 6,这是为了在移动端设备 float16/int8 的低精度的时候,也能有很好的数值分辨率。Depthwise输出比较浅,应用ReLU会带来信息损失,所以在最后把ReLU去掉了(注意下图中标红的部分没有ReLU)。

import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
class Block(nn.Module):
'''expand + depthwise + pointwise'''
def __init__(self, in_planes, out_planes, expansion, stride):
super(Block, self).__init__()
self.stride = stride
# 通过 expansion 增大 feature map 的数量
planes = expansion * in_planes
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, groups=planes, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn3 = nn.BatchNorm2d(out_planes)
# 步长为 1 时,如果 in 和 out 的 feature map 通道不同,用一个卷积改变通道数
if stride == 1 and in_planes != out_planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_planes))
# 步长为 1 时,如果 in 和 out 的 feature map 通道相同,直接返回输入
if stride == 1 and in_planes == out_planes:
self.shortcut = nn.Sequential()
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
# 步长为1,加 shortcut 操作
if self.stride == 1:
return out + self.shortcut(x)
# 步长为2,直接输出
else:
return out
#创建 MobileNetV2 网络
class MobileNetV2(nn.Module):
# (expansion, out_planes, num_blocks, stride)
cfg = [(1, 16, 1, 1),
(6, 24, 2, 1),
(6, 32, 3, 2),
(6, 64, 4, 2),
(6, 96, 3, 1),
(6, 160, 3, 2),
(6, 320, 1, 1)]
def __init__(self, num_classes=10):
super(MobileNetV2, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.layers = self._make_layers(in_planes=32)
self.conv2 = nn.Conv2d(320, 1280, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(1280)
self.linear = nn.Linear(1280, num_classes)
def _make_layers(self, in_planes):
layers = []
for expansion, out_planes, num_blocks, stride in self.cfg:
strides = [stride] + [1]*(num_blocks-1)
for stride in strides:
layers.append(Block(in_planes, out_planes, expansion, stride))
in_planes = out_planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layers(out)
out = F.relu(self.bn2(self.conv2(out)))
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=False, num_workers=2)
# 网络放到GPU上
net = MobileNetV2().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
#模型训练
for epoch in range(10): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')
#模型检测
correct = 0
total = 0
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %.2f %%' % (
100 * correct / total))
模型训练结果
Epoch: 1 Minibatch: 1 loss: 2.310
Epoch: 1 Minibatch: 101 loss: 1.906
Epoch: 1 Minibatch: 201 loss: 1.432
Epoch: 1 Minibatch: 301 loss: 1.364
Epoch: 2 Minibatch: 1 loss: 1.318
Epoch: 2 Minibatch: 101 loss: 1.135
Epoch: 2 Minibatch: 201 loss: 1.253
Epoch: 2 Minibatch: 301 loss: 1.112
Epoch: 3 Minibatch: 1 loss: 1.045
Epoch: 3 Minibatch: 101 loss: 1.020
Epoch: 3 Minibatch: 201 loss: 0.930
Epoch: 3 Minibatch: 301 loss: 0.987
Epoch: 4 Minibatch: 1 loss: 0.876
Epoch: 4 Minibatch: 101 loss: 0.684
Epoch: 4 Minibatch: 201 loss: 0.899
Epoch: 4 Minibatch: 301 loss: 0.747
Epoch: 5 Minibatch: 1 loss: 0.610
Epoch: 5 Minibatch: 101 loss: 0.893
Epoch: 5 Minibatch: 201 loss: 0.708
Epoch: 5 Minibatch: 301 loss: 0.663
Epoch: 6 Minibatch: 1 loss: 0.609
Epoch: 6 Minibatch: 101 loss: 0.594
Epoch: 6 Minibatch: 201 loss: 0.632
Epoch: 6 Minibatch: 301 loss: 0.635
Epoch: 7 Minibatch: 1 loss: 0.637
Epoch: 7 Minibatch: 101 loss: 0.538
Epoch: 7 Minibatch: 201 loss: 0.527
Epoch: 7 Minibatch: 301 loss: 0.471
Epoch: 8 Minibatch: 1 loss: 0.510
Epoch: 8 Minibatch: 101 loss: 0.675
Epoch: 8 Minibatch: 201 loss: 0.699
Epoch: 8 Minibatch: 301 loss: 0.578
Epoch: 9 Minibatch: 1 loss: 0.457
Epoch: 9 Minibatch: 101 loss: 0.469
Epoch: 9 Minibatch: 201 loss: 0.348
Epoch: 9 Minibatch: 301 loss: 0.453
Epoch: 10 Minibatch: 1 loss: 0.371
Epoch: 10 Minibatch: 101 loss: 0.444
Epoch: 10 Minibatch: 201 loss: 0.452
Epoch: 10 Minibatch: 301 loss: 0.325
Finished Training
模型检测结果
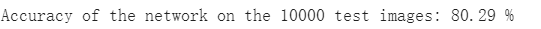
准确率变高了。
《HybridSN: Exploring 3-D–2-D CNN Feature Hierarchy for Hyperspectral Image Classification》
【第三部分】 论文阅读心得
《Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising》
· 提出CNN+残差学习进行图像降噪
· DnCNN模型能够处理具有未知噪声水平的高斯去噪
《Squeeze-and-Excitation Networks》
SENet主要通过学习的方式获取每个特征通道的重要程度,然后产生对应的特征权重进行学习。
· motivation
Explicitly model channel-interdependencies within modules
Feature recalibration:选择性地增强有用的特性并抑制不太有用的特性
· 压缩+激发
压缩:将全局空间信息压缩成一个通道描述符,利用全局平均池化得到一个通道维度(特征维度)上的统计数据。
激发:自适应重标定。根据输入特征的描述符,给每个通道赋予权重。
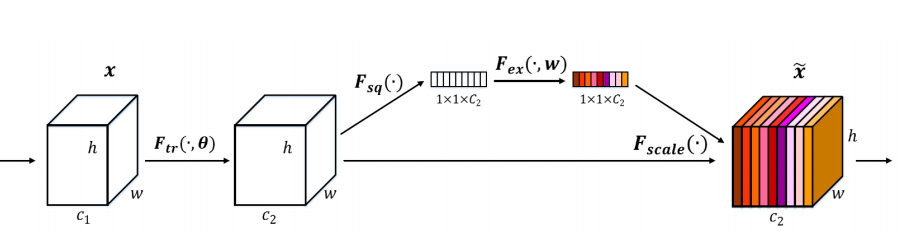
1.对U先做一个Global Average Pooling(图中的Fsq(.),作者称为Squeeze过程)
2.输出的1x1xC数据再经过两级全连接(图中的Fex(.),作者称为Excitation过程)
3.最后用sigmoid(论文中的self-gating mechanism)限制到[0,1]的范围,把这个值作为scale乘到U的C个通道上, 作为下一级的输入数据。这种结构的原理是想通过控制scale(权重)的大小,把重要的特征增强,不重要的特征减弱,从而让提取的特征指向性更强。我们不仅可以通过按c(通道)进行压缩,还可以按照h或者w进行压缩。
参考
《Deep Supervised Cross-modal Retrieval》
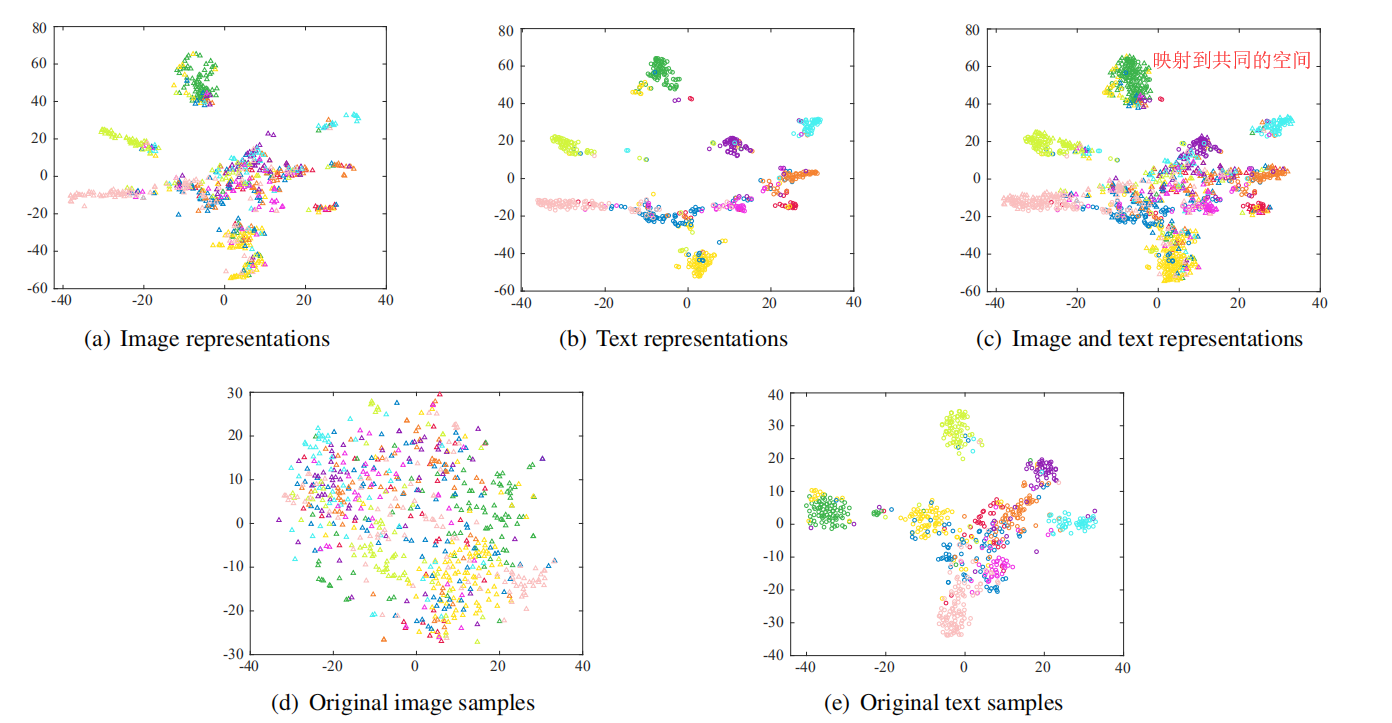
跨模式检索的目的是使灵活的检索跨不同的模式。跨模式检索的核心是如何度量不同类型数据之间的内容相似性。比如一张图片和一个文本,内容都是描述的同一种鸟。
· 通过构建恰当的目标函数使得不同类型数据提取出来的特征能够映射到共同的表示空间中。
Q:怎么完成映射到共同空间中?
A:两个子网络共享其最后一层神经网络的权值,使相同类别的图像和文本样本生成尽可能相似的表示。
参考
· 两个不同的识别器最后全连接层共享权重
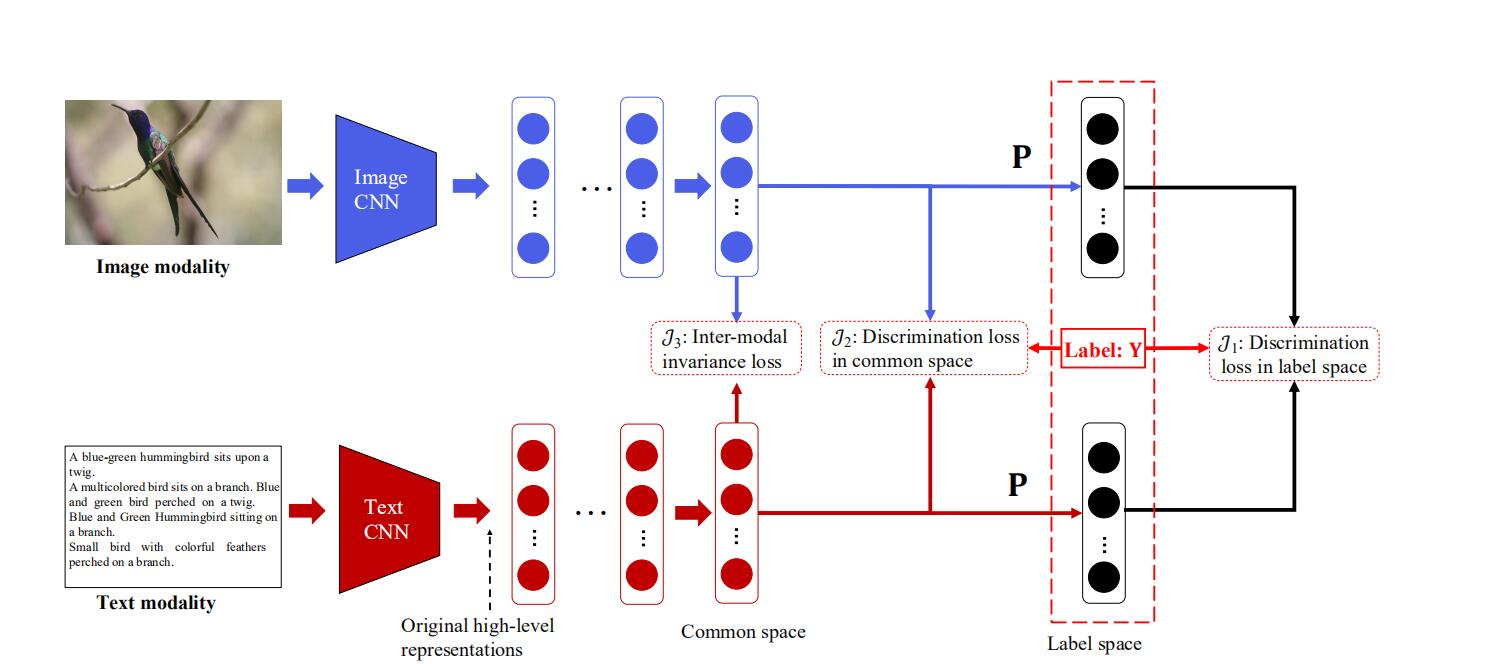
· 模型准去率的度量标准:mAP,综合查准率和查全率
由图像查询对应文本;由文本查询对应图片。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号