第一次个人编程作业
https://github.com/muyu9/031902338
一、PSP表格
- 在开始实现程序之前,在附录提供PSP表格记录下你估计将在程序的各个模块的开发上耗费的时间。
- 在你实现完程序之后,在附录提供的PSP表格记录下你在程序的各个模块的开发上实际花费的时间。
| Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| 计划 | 8 | 10 |
| · 估计这个任务需要多少时间 | 8 | 10 |
| 开发 | 1960 | 2357 |
| · 需求分析 (包括学习新技术) | 600 | 660 |
| · 生成设计文档 | 30 | 20 |
| · 设计复审 | 10 | 7 |
| · 代码规范 (为目前的开发制定合适的规范) | 40 | 30 |
| · 具体设计 | 60 | 60 |
| · 具体编码 | 1100 | 1500 |
| · 代码复审 | 60 | 50 |
| · 测试(自我测试,修改代码,提交修改) | 60 | 30 |
| 报告 | 48 | 37 |
| · 测试报告 | 15 | 10 |
| · 计算工作量 | 3 | 2 |
| · 事后总结, 并提出过程改进计划 | 30 | 25 |
| · 合计 | 2016 | 2384 |
二、计算模块接口
- 计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。(18')
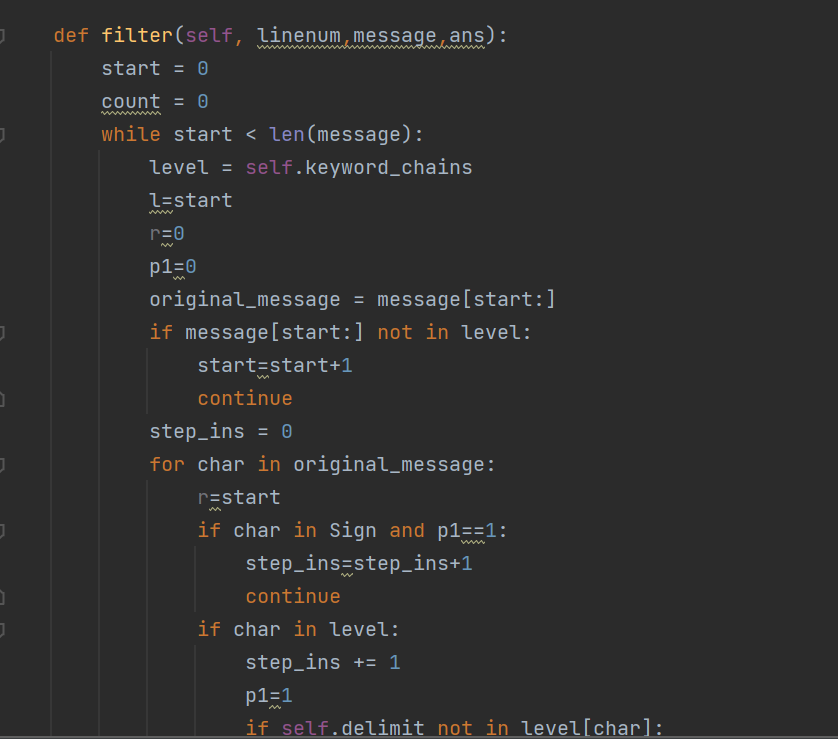
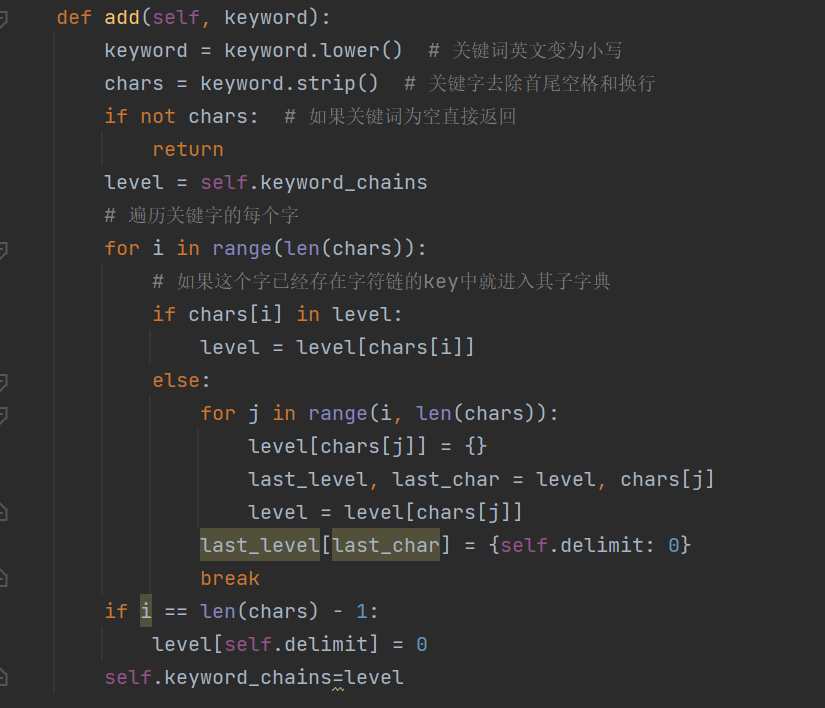
一个类DFAFilter(object),初始化函数、读取敏感字函数parse(self, path)、建立敏感字的字典树add(self, keyword)、DFA查找filter(self, linenum,message,ans)、汉字和拼音的排列组合。filter中在敏感字查找的同时实现答案列表的填写。关键算法是DFA算法。采用类管理,初始化一个空字典链表,特定结束符以及生成敏感词链表的函数。接下来是parse()读取敏感词库表,通过add()将敏感词以嵌套字典的方式形成链表,即为level,访问level即可匹配敏感词。最后,将传入的词组进行敏感词过滤,遍历新词组,只有当前字在敏感词链表中才能加入敏感词。
没有什么独到之处,参考的是大佬写好的DFA算法,在这个的基础上修改的。

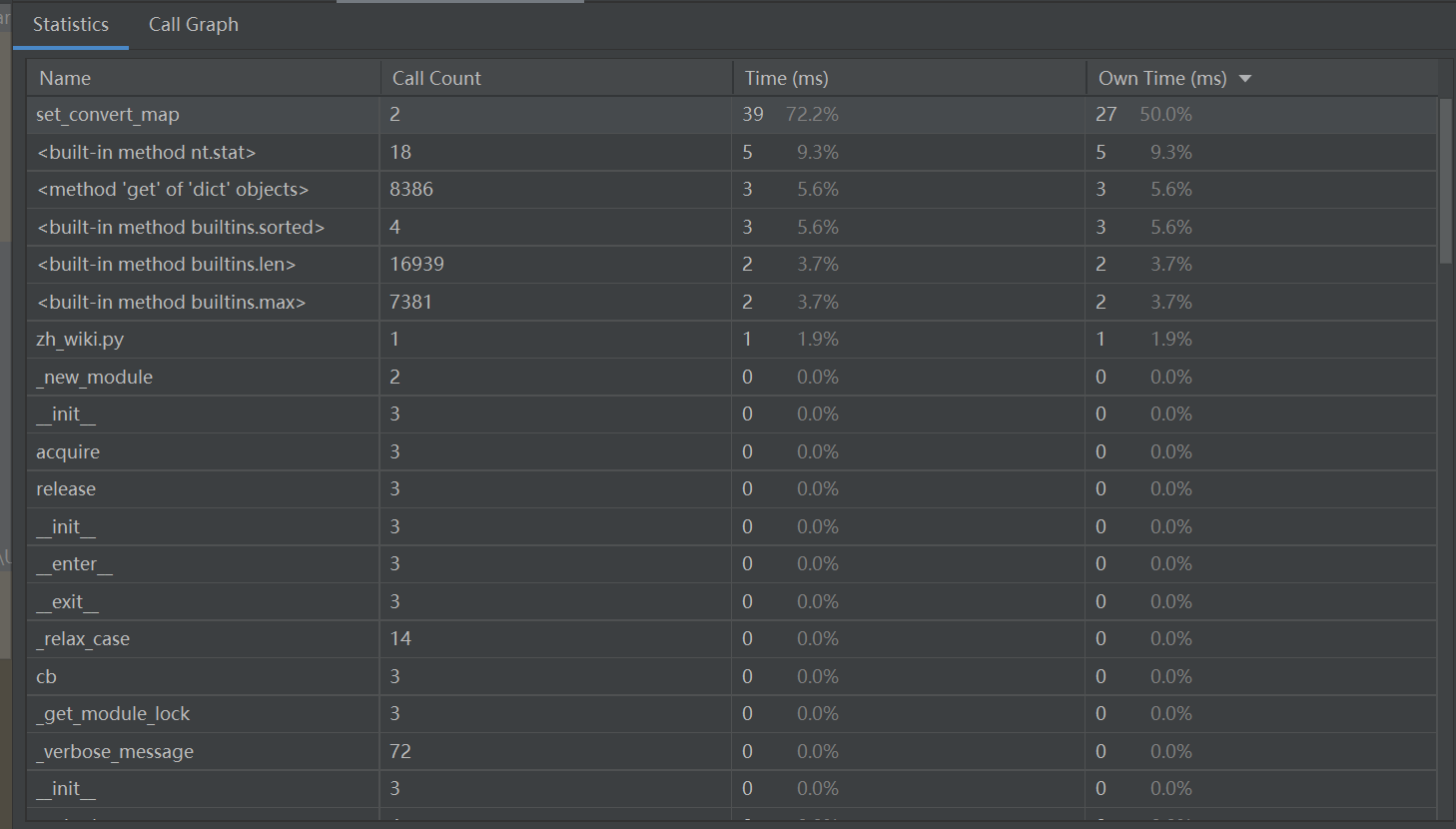
- 计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2019、JProfiler或者Jetbrains系列IDE自带的Profiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。
性能分析图
![]()
- 在计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。(12')
代码如下
测试覆盖图
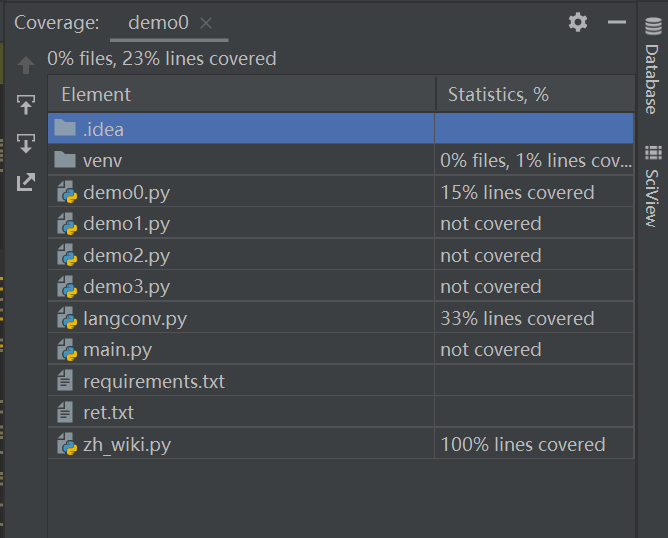
不知道为啥一直是这样。。。。。。(真的写了挺久,实在是不行)

- 计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。(6')
只在文件读入读出时进行了异常处理。输入输出异常:输入文件不存在时、无法写到指定文件时,引发错误“Unable to open ans file”
三、心得
- 在完成本次作业过程的心得体会(3')
心得体会就是我真的是菜鸡。一开始看到题目就有点烦躁,要求好多,不懂的好多,看起来好难。题目看了好几遍才完全理解要的是什么。至少半年没写过代码,有点陌生,对完成这次作业没有什么信心。C++语言掌握得也不咋地,而且这次作业可参考的代码很多是用python的。所以就在B站找了python的网课,大概了解一些语法。这就已经用了不少时间。然后结果当然是边写边BUG,把出现的BUG再去百度找问题然后解决。对这个语言的掌握不够,工具都用不好,还能写出什么东西来。最终。。。没有写出完整、可行的代码。结果一直只有total=0的输出,啥也没有。虽然没有写出来,但是在debug的过程中还是加深了对python语法的理解,还需要继续学习和观看关于python的网课视频。这次学习语言花了比较多的时间,希望下次的编程作业可以完成。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号