数据采集与融合-第六次作业
作业①:
1)爬取豆瓣电影Top250数据
要求:
用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据。
每部电影的图片,采用多线程的方法爬取,图片名字为电影名
了解正则的使用方法
代码
import os
import re
import threading
import prettytable
import requests
import urllib.parse
from bs4 import BeautifulSoup
from prettytable import PrettyTable
def searchPy(url):
try:
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36 Edg/85.0.564.51"}
resp=requests.get(url,headers = headers)
resp.encoding = resp.apparent_encoding
return resp.text
except:
print("爬取页面失败!")
def getInfo(url,page,save_path):
for i in range(0,page):
html = searchPy(url +"?start=" +str(i*25))
soup=BeautifulSoup(html,"html.parser")
items=soup.select("div[class='article'] div[class='item']")
imgSrc=[]
imgName=[]
for item in items:
try:
rank=item.select("div[class='pic'] em")[0].text # 排名
title=item.select("span[class='title']")[0].text # 电影名
# 去除字符串里的换行符和空格等
bd=item.select("div[class='bd'] p")[0].text.replace("\n","").replace("\xa0","").strip()
# 分割获得导演和主演
bdss=bd.split(":")
director=bdss[1].strip().split(" ")[0]
actor=bdss[2].strip().split(" ")[0]
# 分割再使用re匹配到年份
bds = bdss[-1].split("/")
m=re.search(r"\d+",bd)
year=bd[m.start():m.end()]
country=bds[-2] # 国家
type= bds[-1] # 电影类型
score=item.select("div[class='star'] span")[1].text # 评分
# 使用re匹配数字即评分人数
num = item.select("div[class='star'] span")[3].text
m = re.search(r"\d+", num)
num=num[m.start():m.end()]
quote=item.select("p[class='quote'] span")[0].text #音乐
imgSrc.append(item.select("div[class='pic'] img")[0]['src']) #图片url
fileName=title+".jpg" #文件名
imgName.append(fileName)
tab.add_row([rank,title,director,actor,year,country,type,score,num,quote,fileName])
except :
pass
downloadImgbyMultThreads(save_path,imgSrc,imgName)
# 多线程爬取
def downloadImgbyMultThreads(save_path, imageSrc, imageName):
# 下载图片
try:
for i in range(len(imageSrc)):
# 下载指定url内容到本地
T = threading.Thread(target=urllib.request.urlretrieve, args=(imageSrc[i], imageName[i]))
# 设置子线程为前台线程
T.setDaemon(False)
T.start()
threads.append(T)
except Exception as err:
print(err)
url="https://movie.douban.com/top250"
save_path = r"images/"
# 在当前文件夹下创建一个文件夹存放图片
if not os.path.exists(save_path):
os.makedirs(save_path)
# 将当前路径切换到存储路径下
os.chdir(save_path)
threads=[]
tab = PrettyTable() # 设置表头
# tab.set_style(prettytable.PLAIN_COLUMNS)
tab.field_names = ["排名","电影名称","导演","主演","上映时间","国家","电影类型","评分","评价人数","引用","文件路径"]
# 爬取10个页面的信息
getInfo(url,10,save_path)
# 让主线程等待其他线程
for t in threads:
t.join()
print(tab) # 打印表格
结果
控制台输出:

下载图片文件夹:
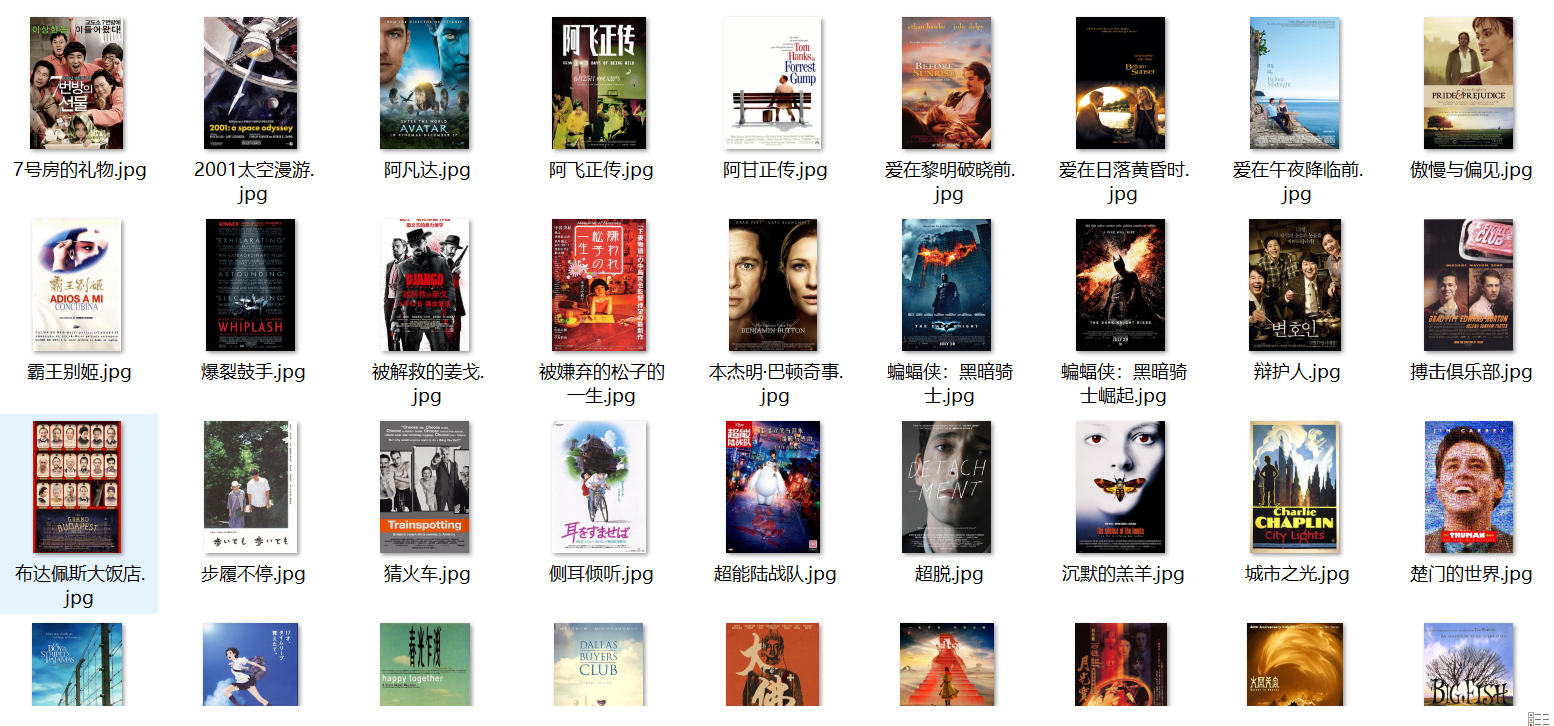
2)、心得体会
重新复习了一下css语法查找元素的方法和bs,request的使用,除了分割导演和主演这两个字段比较困难,其他的再看一下以前的写过的代码,没有太大的难度。
作业②:
1)爬取科软排名信息
要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取科软排名信息
爬取科软学校排名,并获取学校的详细链接,进入下载学校Logo存储、获取官网Url、院校信息等内容。
代码:
items.py设计数据项目类:
class UniversityrankItem(scrapy.Item):
sNo = scrapy.Field()
schoolName = scrapy.Field()
city = scrapy.Field()
officalUrl = scrapy.Field()
info = scrapy.Field()
mFile=scrapy.Field()
mSrc=scrapy.Field()
数据项目设计好后编写爬虫程序MySpider.py:
import time
import requests
import scrapy
from universityRank.items import UniversityrankItem
from bs4 import UnicodeDammit
class MySpider(scrapy.Spider):
name = "mySpider"
start_urls = []
urls=[]
sNo=0
names=[]
citys=[]
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36 Edg/85.0.564.51"}
# 获取所有大学详细链接
def __init__(self):
resp = requests.get('https://www.shanghairanking.cn/rankings/bcur/2020', headers=self.headers)
resp.encoding = resp.apparent_encoding
data = resp.text
selector = scrapy.Selector(text=data)
trs = selector.xpath("//*[@id='content-box']/div[2]/table/tbody/tr")
for tr in trs:
url = 'https://www.shanghairanking.cn' + tr.xpath("./td[2]/a/@href").extract_first().strip()
self.names.append(tr.xpath("./td[2]/a/text()").extract_first().strip())
self.citys.append(tr.xpath("./td[3]/text()").extract_first().strip())
self.start_urls.append(url)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
schoolName = self.names[self.sNo]
city = self.citys[self.sNo]
officalUrl=selector.xpath("//div[@class='univ-website']/a/text()").extract_first()
info=selector.xpath("//div[@class='univ-introduce']/p/text()").extract_first()
time.sleep(1)
mSrc=selector.xpath("//td[@class='univ-logo']/img/@src").extract_first()
self.sNo+=1
item= UniversityrankItem()
item["sNo"] = self.sNo
item["schoolName"] = schoolName.strip() if schoolName else ""
item["city"] = city.strip() if city else ""
item["officalUrl"] = officalUrl.strip() if officalUrl else ""
item["info"] = info.strip() if info else ""
item["mFile"]=str(self.sNo)+".jpg"
item["mSrc"]=mSrc.strip() if mSrc else ""
yield item
except Exception as err:
print(err)
在pipelines.py编写数据管道处理类:
import os
import urllib
import pymysql
class UniversityrankPipeline:
def __init__(self):
self.count = 0
self.opened = True
def open_spider(self, spider):
print("连接数据库")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="1234", db="mydb",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
try:
# 如果有表就删除
self.cursor.execute("DROP TABLE IF EXISTS universityRank")
except:
pass
try:
# 建立新的表
self.cursor.execute("CREATE TABLE universityRank(sNo int,"
"schoolName VARCHAR (32),"
"city VARCHAR(32),"
"officalUrl VARCHAR(32),"
"info VARCHAR(512),"
"mFile VARCHAR(8),"
"PRIMARY KEY (sNo))")
except Exception as err:
print(err)
print("表格创建失败")
except Exception as err:
print("数据库连接失败")
self.opened = False
save_path = "universityImgs"
# 在当前文件夹下创建一个文件夹存放图片
if not os.path.exists(save_path):
os.makedirs(save_path)
# 将当前路径切换到存储路径下
os.chdir(save_path)
# 提交数据并关闭数据库,使用count变量统计爬取的信息数
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.showDB()
self.con.close()
self.opened = False
print("关闭数据库")
print("总共爬取", self.count, "条信息")
def showDB(self):
try:
# 格式化输出
fm = "{0:^4}\t{1:^12}\t{2:^8}\t{3:^18}\t{4:^5}\t{5:^50}"
cn_blank = 2 * chr(12288) # 两个中文空格作为填充
titles = ["排名","学校名","城市","官网Url","图片文件","院校信息"]
print("{0:^4}\t{1:^14}\t{2:^8}\t{3:^14}\t{4:^6}\t{5:^50}".format(titles[0], titles[1], titles[2], titles[3], titles[4], titles[5], cn_blank))
self.cursor.execute("SELECT * FROM universityRank")
rows = self.cursor.fetchall()
for row in rows:
print(fm.format(row['sNo'], row["schoolName"], row["city"], row["officalUrl"], row['mFile'],row["info"],cn_blank))
except Exception as err:
print(err)
# 输出数据内容,并使用insert的SQL语句把数据插入到数据库中
def process_item(self, item, spider):
try:
# 下载图片
urllib.request.urlretrieve(item["mSrc"], filename=item["mFile"])
except Exception as err:
print("图片下载失败", err)
try:
if self.opened:
self.count +=1
# 插入数据到表中
self.cursor.execute(
"insert into universityRank( sNo,schoolName ,city,officalUrl,mFile,info) values(%s,%s,%s,%s,%s,%s)",
(item['sNo'], item["schoolName"], item["city"], item["officalUrl"],item['mFile'], item["info"]))
except Exception as err:
print("数据插入失败",err)
return item
设置scrapy的配置文件setting.py
ITEM_PIPELINES = {
'img_scrapy.pipelines.ImgScrapyPipeline': 300,
}
运行run.py就可以执行gupiao的爬虫程序
from scrapy import cmdline
cmdline.execute("scrapy crawl mySpider -s LOG_ENABLED=false".split())
结果:
控制台输出结果:
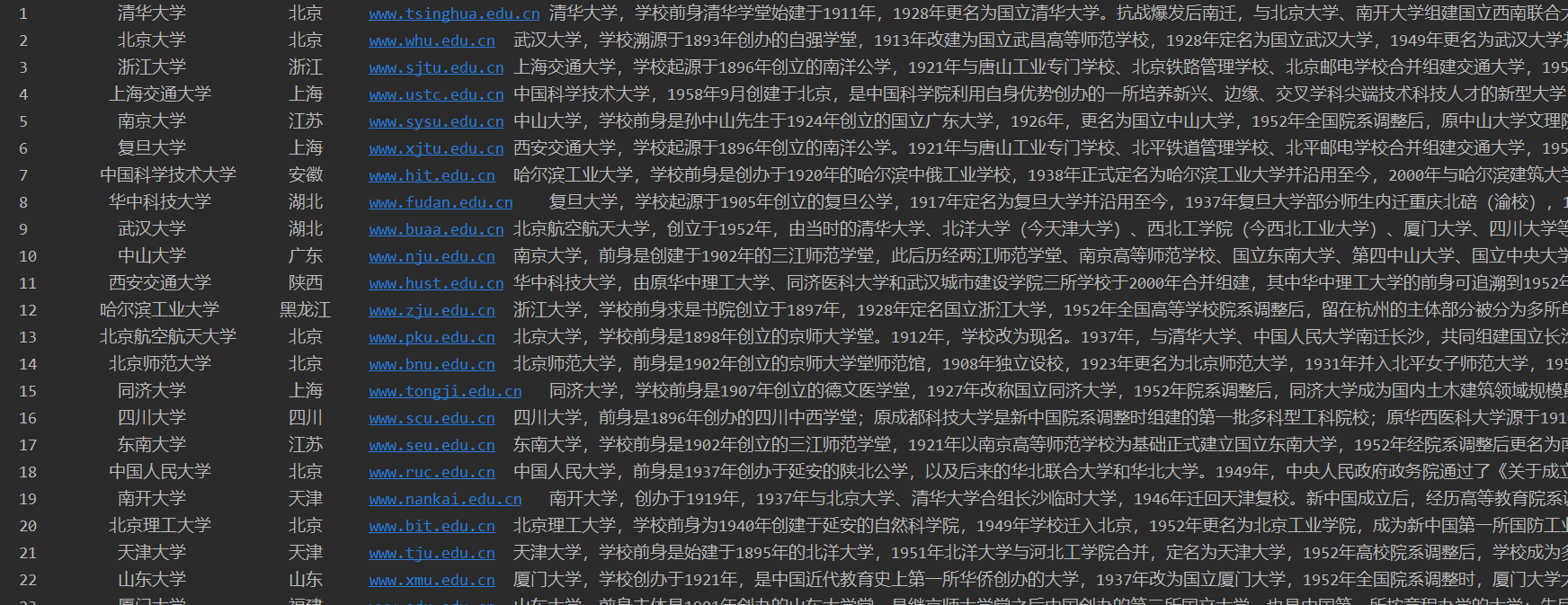
数据库部分结果截图:

下载图片文件夹:

2)、心得体会
这道题是要使用scrapy来抓取网站上的多个页面,不知道用scrapy怎么在主页面里面一个个点进所有大学的详情页面,就先在init的方法里用requests方法先获取所有学校的详情页面链接存到start_urls里,变量start_urls用于定义要爬取网页的url ,爬虫运行时,顺序运行每一个url生成请求并被parse()方法调用解析。其他的以前也做过,再复习一下就行了。
作业③
1)、爬取中国mooc网课程资源信息
要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素加载、网页跳转等内容。
使用Selenium框架+ MySQL数据库存储技术模拟登录慕课网,并获取学生自己账户中已学课程的信息并保存在MYSQL中。
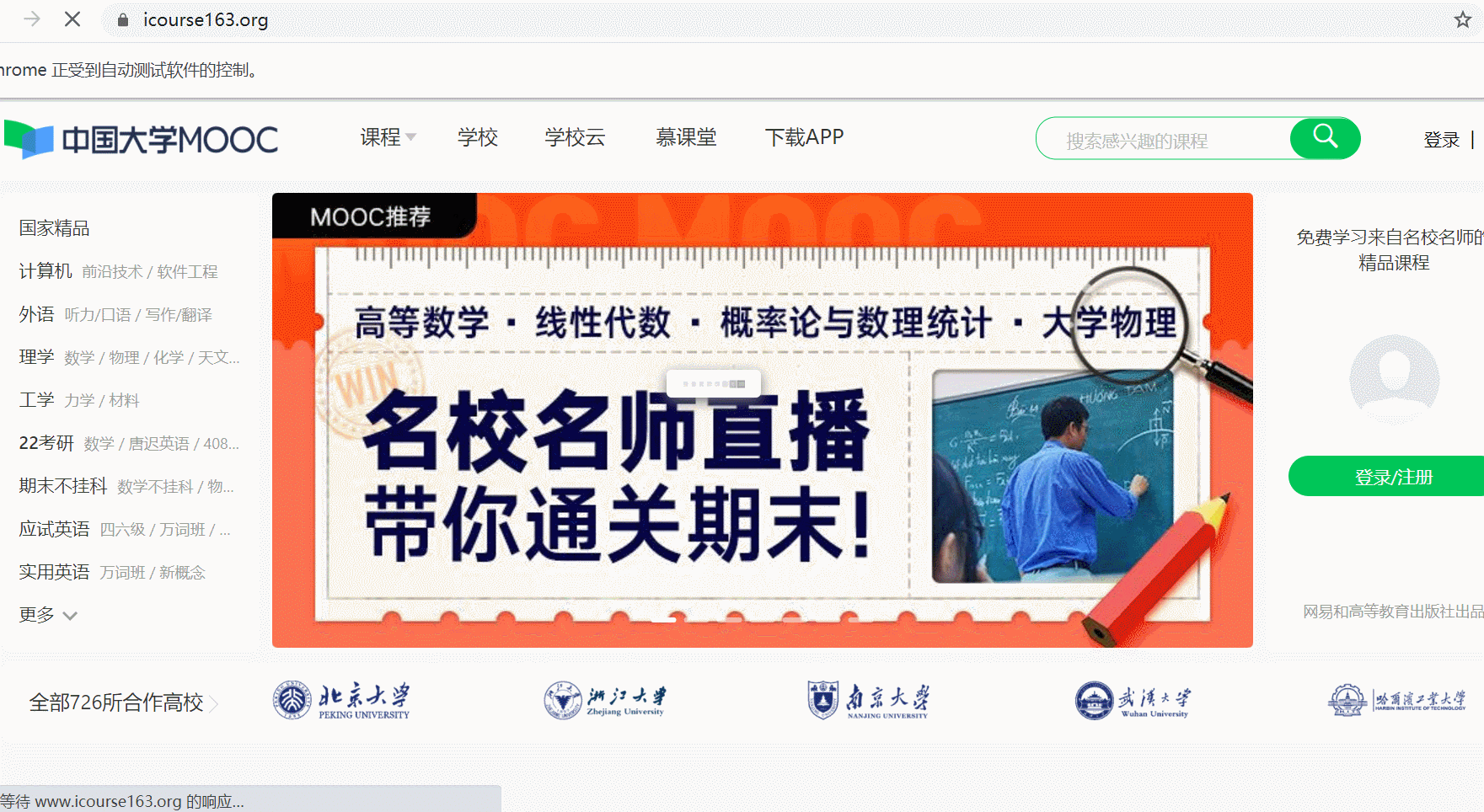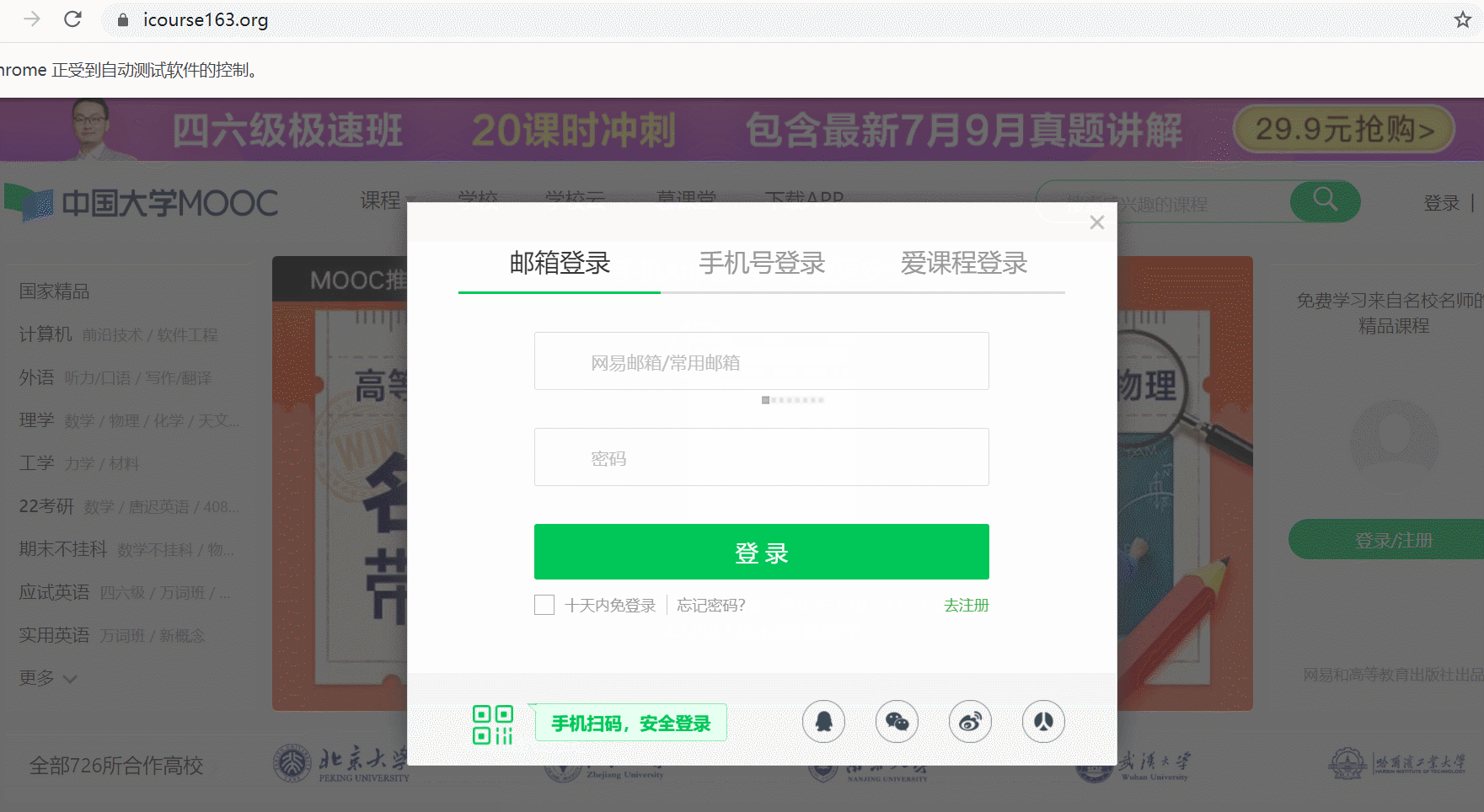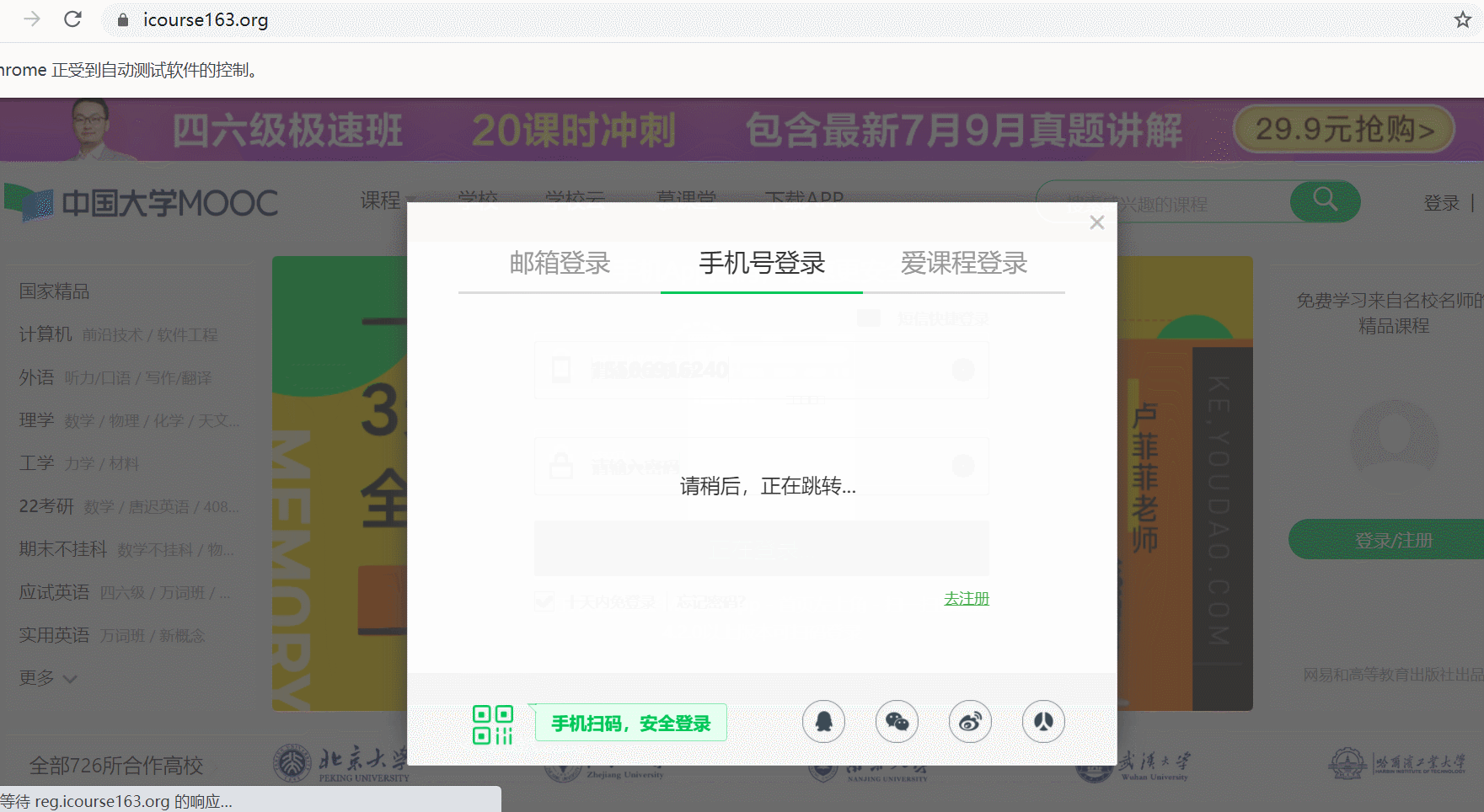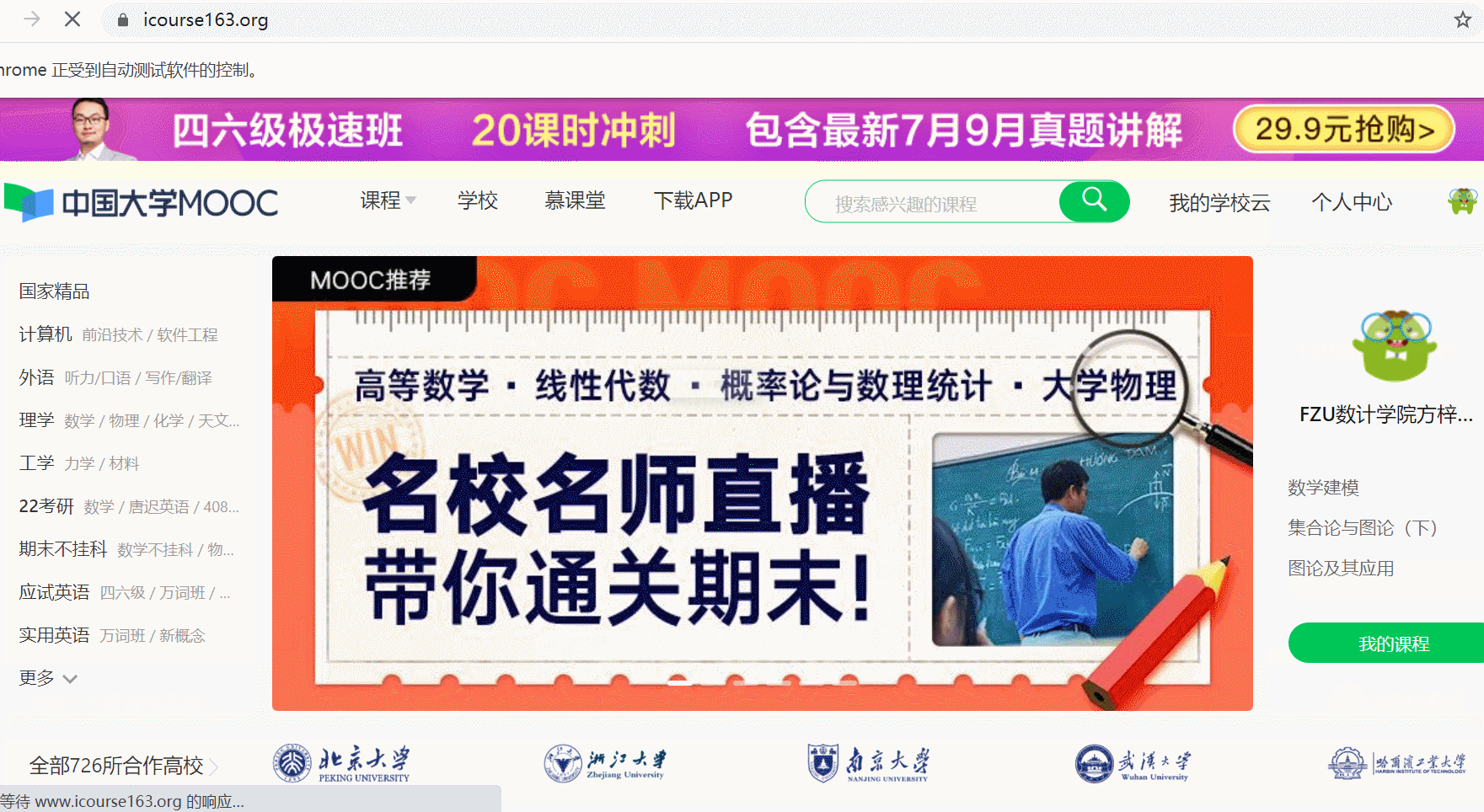
其中模拟登录账号环节需要录制gif图。
代码:
import re
import prettytable
import pymysql
from prettytable import PrettyTable
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import datetime
from selenium.webdriver.common.by import By
import time
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
class MySpider:
headers = {
"User-Agent":
"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
def startUp(self, url):
# 实例化浏览器对象
chrome_options = Options()
# 不显示打开浏览器的界面,指定谷歌浏览器路径
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--no-sandbox')
self.driver = webdriver.Chrome(chrome_options=chrome_options)
self.driver.get(url)
self.count = 0 # 爬取信息数量
locator = (By.XPATH, "//div[@class='unlogin']")
# 等待网页数据加载
WebDriverWait(self.driver, 10, 0.5).until(expected_conditions.presence_of_element_located(locator))
def con_sql(self):
# 连接 MySQL数据库,并创建操作游标self.cursor
try:
print("连接数据库")
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="1234", db="mydb",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
try:
# 如果有表就删除
self.cursor.execute("DROP TABLE IF EXISTS myCourse")
except:
pass
try:
# 建立新的表
self.cursor.execute("CREATE TABLE myCourse(Id int,"
"cCourse VARCHAR (32),"
"cCollege VARCHAR(32),"
"cTeacher VARCHAR(32),"
"cTeam VARCHAR(32),"
"cCount VARCHAR(32),"
"cProcess VARCHAR(32),"
"cBrief VARCHAR(128),"
"PRIMARY KEY (id))")
except Exception as err:
print(err)
print("表格创建失败")
except Exception as err:
print("数据库连接失败",err)
exit()
except Exception as err:
print(err)
def showDB(self):
try:
tab = PrettyTable() # 设置表头
tab.set_style(prettytable.PLAIN_COLUMNS)
tab.field_names = ["课程号", "课程名称","学校名称","主讲教师","团队成员","参加人数", "课程进度", "课程简介"]
self.cursor.execute("SELECT * FROM myCourse")
rows = self.cursor.fetchall()
for row in rows:
tab.add_row([row['Id'],row['cCourse'], row['cCollege'], row['cTeacher'],
row['cTeam'], row['cCount'],row['cProcess'],row['cBrief']])
print(tab)
self.con.close()
print("关闭数据库连接")
except Exception as err:
print(err)
def closeUp(self):
try:
self.con.commit()
self.driver.close()
print("总共爬取", self.count, "条信息")
except Exception as err:
print(err)
def login(self):
# 登录入口
WebDriverWait(self.driver, 10).until(
expected_conditions.element_to_be_clickable((By.XPATH, "//div[@class='unlogin']/a"))).click()
# 其他方式登录
WebDriverWait(self.driver, 10).until(
expected_conditions.element_to_be_clickable((By.XPATH,
"//div[@class='ux-login-set-scan-code f-pr']//span[@class='ux-login-set-scan-code_ft_back']"))).click()
# 选择手机号登录
WebDriverWait(self.driver, 10).until(
expected_conditions.element_to_be_clickable(
(By.XPATH, "//ul[@class='ux-tabs-underline_hd']/li[2]"))).click()
time.sleep(1)
temp_iframe_id = self.driver.find_elements_by_tag_name('iframe')[1].get_attribute('id')
self.driver.switch_to_frame(temp_iframe_id)
time.sleep(1)
# 输入手机号和密码
self.driver.find_element_by_xpath("//input[@id='phoneipt']").send_keys(PHONE)
self.driver.find_element_by_xpath("//input[@class='j-inputtext dlemail']").send_keys(PASSWORD)
# 点击登录按钮
self.driver.find_elements_by_xpath("//div[@class='f-cb loginbox']")[0].click()
time.sleep(1)
def processSpider(self):
try:
# 点击跳转查看我的课程
WebDriverWait(self.driver, 10, 0.5).until(expected_conditions.presence_of_element_located(
(By.XPATH, "//div[@class='_2yDxF WTuVf']//div[@class='_3uWA6']"))).click()
# 等待网页数据加载
time.sleep(3)
divs = self.driver.find_elements_by_xpath("//div[@class='course-card-wrapper']")
for div in divs:
try:
course = div.find_element_by_xpath(".//div[@class='body']//span[@class='text']").text
college = div.find_element_by_xpath(".//div[@class='school']/a").text
# 点击课程课程详情介绍
self.driver.execute_script("arguments[0].click();",div.find_element_by_xpath(".//div[@class='menu']/div/a"))
# 跳转到新打开的页面
self.driver.switch_to.window(self.driver.window_handles[-1])
team = self.driver.find_elements_by_xpath(
"//div[@class='um-list-slider_con']/div//h3[@class='f-fc3']")
teacher=team[0].text
Team = ""
for t in team:
Team += " " + t.text
count = re.sub("\D", "",self.driver.find_element_by_xpath(
"//span[@class='course-enroll-info_course-enroll_price-enroll_enroll-count']").text)
process = self.driver.find_element_by_xpath(
"//div[@class='course-enroll-info_course-info_term-info_term-time']//span[position()=2]").text
brief = self.driver.find_element_by_xpath("//div[@id='j-rectxt2']").text
# 关闭新页面,返回原来的页面
self.driver.close()
self.driver.switch_to.window(self.driver.window_handles[0])
self.count += 1
id = self.count
self.insertDB(id, course, college, teacher, Team, count, process, brief)
except Exception as err:
print(err)
pass
except Exception as err:
print(err)
def insertDB(self, id, course, college, teacher, cTeam, count, process, brief):
try:
self.cursor.execute(
"insert into myCourse(Id,cCourse,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief) values(%s,%s,%s,%s,%s,%s,%s,%s)",
(id, course, college, teacher, cTeam, count, process, brief))
except Exception as err:
print(err)
print("数据插入失败")
def executeSpider(self, url):
starttime = datetime.datetime.now()
print("爬虫开始......")
self.startUp(url)
self.con_sql()
self.login()
print("爬虫处理......")
self.processSpider()
print("爬虫结束......")
self.closeUp()
self.showDB()
endtime = datetime.datetime.now()
time = (endtime - starttime).seconds
print("一共花了", time, "秒")
spider = MySpider()
spider.executeSpider("https://www.icourse163.org")
结果:
模拟登录gif图:
控制台输出:

数据库部分数据截图:

2)、心得体会
这道题就是登录那里花了很多时间,刚开始不知道普通的方式无法直接定位到iframe内部的标签元素,需要用到selenium单独提供的switch_to模块去切换,登录完成以后跳转页面又偶尔会出现其他弹窗,导致页面元素无法点击,一天登录太多次要被验证滑块登录,做了两天才做好,登录以后剩下的基本就和上次作业一样了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号