第七章 事务(学习笔记)
1. 事务
事务可由一条非常简单的SQL语句组成,也可以由一组复杂的SQL语句组成。事务是访问并更新数据库中各种数据项的一个程序执行单元。在事务的操作中,要么都做修改,要么都不做。ACID特性:
- Aotomicity(原子性)
整个数据库事务是不可分割的工作单位。只有事务中所有的数据库操作都执行成功,才算整个事务成功。事务中任何一个SQL语句执行失败,已经执行成功的SQL语句也必须撤销,数据库状态应该退回到执行事务前的状态。
- Consistency(一致性)
一致性指事务将数据库从一种状态转变为下一种一致的状态。在事务开始之前和事务结束之后,数据库的完整性约束没有被破坏。
例如,表中有一个字段为姓名,为唯一约束,即在表中姓名不能重复。如果一个事务对姓名字段进行了修改,但是在事务提交或事务操作发生回滚后,表中的姓名变得非唯一了,这就破坏了事务的一致性操作,即事务从一种状态变为了一种不一致的状态。
- Isolation(隔离性)还有其他称呼,如并发控制(concurrency control),可串行化(serializability),锁(locking)等
事务的隔离性要求每个读写事务的对象对其他事务的操作对象能相互分离,即该事务提交前对其他事务都不可见,通常用锁来实现
- Durability(持久性)
事务一旦提交,其结果就是永久性的。即使发生宕机等故障,数据库也能将数据恢复。需要注意的是,只能从事务本身的角度来保证结果的永久性。但若不是数据库本身发生故障,而是一些外部的原因,如RAID卡损坏,自然灾害等原因导致数据库发生问题,那么提交的数据也有可能丢失。
1.1事务分类
- 扁平事务
在扁平事务中,所有操作处于同一层次中,由BEGIN WORK开始,由COMMIT WORK 或 ROLLBACK WORK 结束,其间的操作是原子的,要么都执行,要么都回滚。

- 带保存点的扁平事务
允许事务在执行过程中回滚到同一事务中较早的一个状态。这是因为某些事务可能在执行过程中出现的错误并不会导致所有的操作都无效,放弃整个事务不合乎要求,开销也大。保存点用来通知系统应该记住事务当前的状态,以便当之后发生错误时,事务能回到保存点当时的状态。
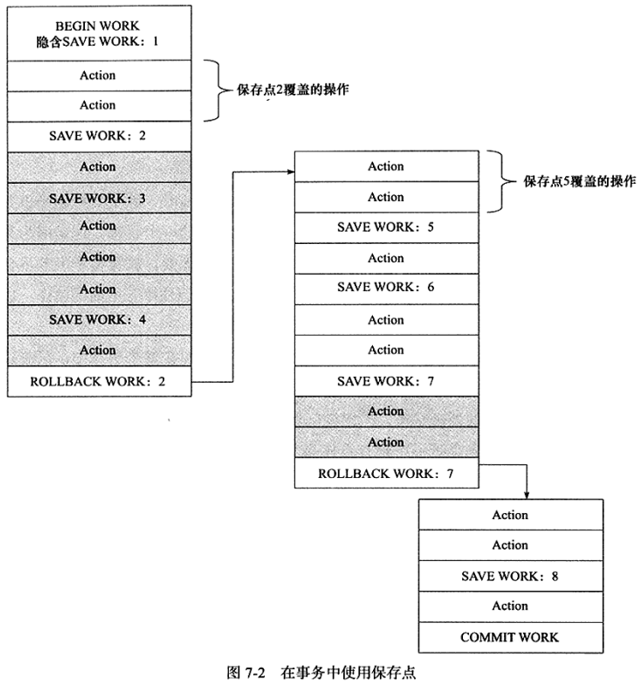
- 链事务
可视为保存点模式的一种变种。带有保存点的扁平事务,当发生系统崩溃时,所有保存点都会消失。进行恢复时,事务需要从头开始执行
链事务的思想是:在提交一个事务时,释放不需要的数据对象,将必要的处理上下文隐式的传给下一个要开始的事务。提交事务操作和开始下一个事务操作将合并为一个原子操作。
链事务只能恢复到最近一个保存点。带有保存点的扁平事务能回滚到任意正确的保存点。
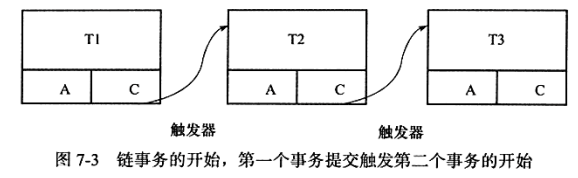
- 嵌套事务(InnoDB存储引擎并不支持)
- 分布式事务
在一个分布式环境下运行的扁平事务,因此需要根据数据所在位置访问网络中的不同节点。
假设用户在ATM进行银行的转账操作,例如持卡人从招商银行的储蓄卡转账10000元到工商银行的储蓄卡。将ATM机视为节点A,招商银行后台数据库视为节点B,工商银行后台数据库视为C,这个转账操作可分为以下步骤:
1) 节点A发出转账命令
2) 节点B执行储蓄卡中的余额值减去10000
3) 节点C执行储蓄卡中的余额增加10000
4) 节点A通知用户操作完成或操作失败
这里需要分布式事务,因为节点A不能通过调用一台数据库就完成任务。其需要访问网络中两个节点的数据库,而在每个节点的数据库执行的事务操作又都是扁平的。对于分布式事务,同样需要满足ACID特性,要么都发生,要么都失败。
2. 事务的实现
2.1 redo
redo log称为重做日志,用来保证事务的原子性和持久性。redo恢复提交事务修改的页操作。其由两部分组成:一是内存中的重做日志缓冲,是易失的;二是重做日志文件,是持久的。
在每次将重做日志缓冲写入重做日志文件后,InnoDB存储引擎都需要调用一次fsync操作。fsync的效率取决于磁盘的性能,因此磁盘的性能决定了事务提交的性能。
参数innodb_flush_log_at_trx_commit用来控制重做日志刷新到磁盘的策略。
0表示事务提交时,不进行写入重做日志操作,这个操作仅在master thread中完成(详细内容见第二章)
1表示事务提交时,必须调用一次fsync操作。
2表示提交时将重做日志写入重做日志文件,但仅写入文件系统的缓存中,不进行fsync操作。在该设置下,mysql数据库发生宕机而操作系统不发生宕机时,并不会导致事务的丢失。
2.1.1 LSN
LSN是log sequence number的缩写。代表日志序列号,其含义是:
- 重做日志写入的总量
- checkpoint的位置
- 页的版本
LSN表示事务写入重做日志的总量。加入当前重做日志的LSN为1000,有一个事务T1写入了100字节的重做日志,那么LSN就变为了1100,若又有事务T2写入了200字节的重做日志,那么LSN就变为了1300.
LSN不仅记录在重做日志中,还存在于每个页中。在每个页头部,有一个值FIL_PAGE_LSN,记录了该页的LSN。在页中,LSN表示该页最后刷新时LSN的大小。因为重做日志记录的是每个页的日志,因此页中的LSN用来判断页是否需要进行恢复操作。
2.2 undo
undo log用来保证事务的一致性。undo回滚行记录到某个特定版本。undo 存放在数据库内部的一个特殊段(segment)中,即undo段。
undo是逻辑日志,因此只是将数据库逻辑地恢复到原来的样子。所有修改都被逻辑地取消了,但是数据结构和页本身在回滚后可能大不相同。这是因为在多并发系统中,可能会有数十、数百甚至数千个并发事务。数据库的主要任务就是协调对数据记录的并发访问。比如,一个事务在修改当前一个页中某几条记录,同时还有别的事务在对同一个页中另几条记录进行修改。因此,不能将一个页回滚到事务开始地样子,因为这样会影响其他事务正在进行的工作。
例如,用户执行了INSERT 10W条记录的事务,这个事务会导致分配一个新的段,即表空间会增大。在用户执行ROLLBACK时,会将插入的事务进行回滚,但是表空间的大小不会因此而收缩。
对于每个INSERT,InnoDB存储引擎会完成一个DELETE;对于每个DELETE,InnoDB存储引擎会执行一个INSERT;对于每个UPDATE,InnoDB存储引擎会执行一个相反的UPDATE,将修改前的行放回去。
除了回滚操作,undo的另一个作用是MVCC,即在InnoDB存储引擎中MVCC的实现通过undo来完成。当用户读取一行记录时,若该纪录已被其他事务占用,当前事务可以通过undo读取之前的行版本信息。
另外,undo log也会产生redo log,只是因为undo log也需要持久性保护。
2.3 purge
delete 和 update操作不会直接删除原有的数据。而是将数据段中的delete flag标志设置为1. purge用于最终完成delete和update操作。这是为了支持MVCC,其他事务可能仍在引用该行,故InnoDB存储引擎需要保存之前的版本。如果该行记录不被其他事务引用,purge会进行真正的delete操作。
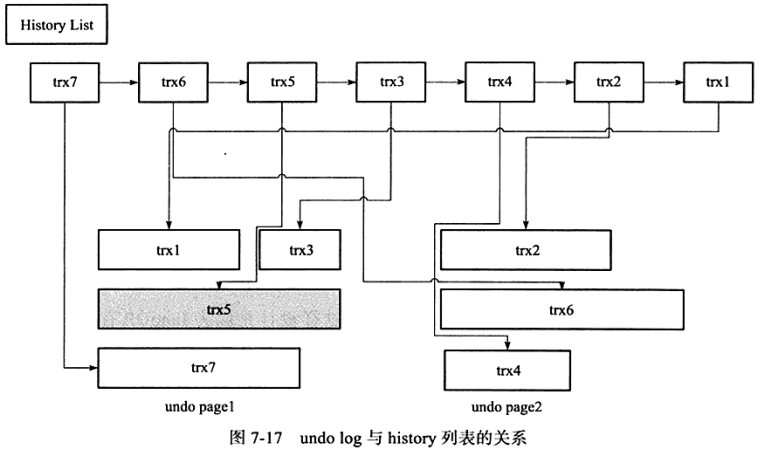
为了节省存储空间:一个页上允许多个事务的undo log存在。此外,InnoDB存储引擎还有一个history列表,它根据事务提交的顺序,将undo log进行链接。
下图trx5灰色表示还有其他事务引用。在执行purge过程中。InnoDB存储引擎首先从history list中找到第一个需要被清理的记录,为trx1。之后会在undo log也页中查找可以清理的undo log,即trx3。由于trx5被占用,所以清理trx2, trx6, trx4。由于undo page 2都被清理了,所以可以被重用。
3. 隐式提交的SQL语句
- DDL语句: ALTER DATABASE...UPGRADE DATA DIRECTORY NAME,ALTER EVENT, ALTER PROCEDURE, ALTER TABLE, ALTER VIEW,CREATE DATABASE, CREATE EVENT, CREATE INDEX, CREATE PROCEDURE, CREATE TABLE, CREATE TRIGGER, CREATE VIEW,DROP DATABASE, DROP EVENT, DROP INDEX, DROP PROCEDURE,DROP TABLE, DROP TRIGGER, DROP VIEW, RENAME TABLE,TRUNCATE TABLE
- 用来隐式地修改 MySQL架构的操作: CREATE USER、 DROP USER、 GRANT 、RENAME USER、 REVOKE、 SET PASSWORD
- 管理语句: ANALYZE TABLE、 CACHE INDEX、 CHECK TABLE、 LOAD INDEX INTO CACHE、 OPTIMIZE TABLE、 REPAIR TABLE
4. 对于事务操作的统计
计算每秒事务处理能力(Transaction Per Second, TPS)的方法是(com_commit+com_rollback)/time。使用该方法的前提是所有事务都是显式提交的。
MySQL还有另外两个参数handler-commit和handler_rollback用于事务的统计操作
5. 分布式事务
XA 是一个分布式事务协议。InnoDB存储引擎提供了对XA事务的支持,并通过XA事务来支持分布式事务的实。分布式事务允许多个独立的事务资源参与到一个全局事务中。全局事务要求其中的事务要么都提交,要么都回滚。在使用分布式事务时,InnoDB存储引擎的事务隔离级别必须设置为SERIALIZABLE。
XA事务由一个或多个资源管理器(Resource Managers)、一个事务管理器(Transaction Manager)以及一个应用程序(Application Program)组成。
- 资源管理器:提供事务资源的方法,通常一个数据库就是一个资源管理器
- 事务管理器:协调参与全局事务中的各个事务。需要和参与全局事务的所有资源管理器进行通信
- 应用程序:定义事务的边界,指定全局事务中的操作
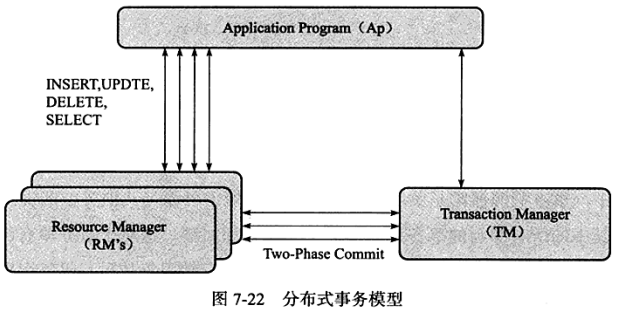
分布式事务使用两段式提交(two-phase commit)的方式。第一阶段,所有参与全局事务的节点都开始准备(PREPARE),告诉事务管理器它们准备好提交了。第二个阶段,事务管理器告诉资源管理器执行ROLLBACK还是COMMIT。
5.1 内部XA事务
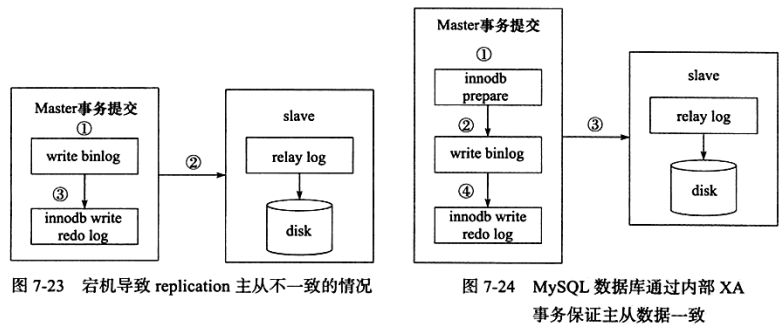
最常见的内部XA事务存在于binlog与InnoDB存储引擎之间。在事务提交时,先写二进制日志,再写InnoDB存储引擎的重做日志。对上述两个操作的要求也是原子的,即二进制日志和重做日志必须同时写入。若二进制日志写入了,而在写入InnoDB存储引擎发生了宕机,那么slave可能会收到master传来的二进制日志并执行,导致主从不一致,如图7-23所示。为了解决这个问题,MySQL数据库在 binlog与InnoDB存储引擎之间采用XA事务。当事务提交时, InnoDB存储引擎会先做一个PREPARE操作,将事务的xid写人,接着进行二进制日志的写入,如图7-24所示。如果在 InnoDB存储引擎提交前, MySQL数据库宕机了,那么 MySQL数据库在重启后会先检查准备的UXID事务是否已经提交,若没有,则在存储引擎层再进行一次提交操作。
6. 不好的事务习惯
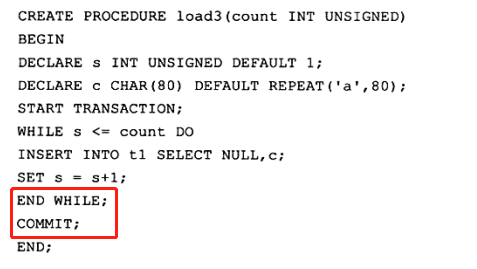
6.1 在循环中提交
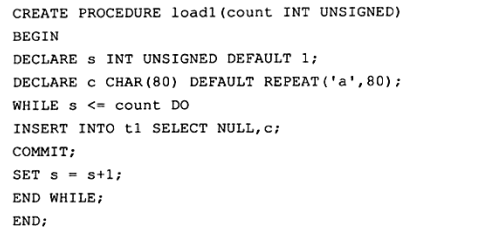
因为InnoDB存储引擎默认为自动提交,所以上述的存储过程可以去掉COMMIT。
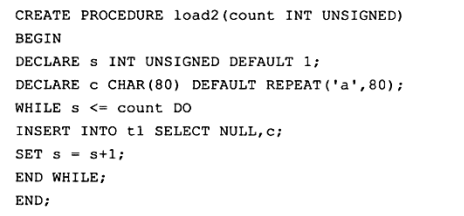
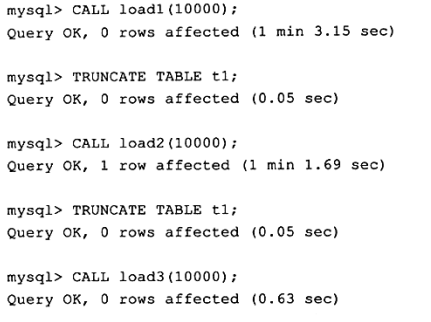
上面两个存储过程存在一个问题,当发生错误时,数据库会停留在一个未知的位置。另一个是性能问题,对于第一和第二种方法,每一次提交都要写一次重做日志,存储过程load1和load2实际写了10000次重做日志,而对于存储过程load3来说,只写了1次。
6.2 使用自动提交
MySQL数据库默认设置使用自动提交(autocommit),可以使用 set autocommit=0来关闭该功能。
也可以通过START TRANSACTION, BEGIN 来显式地开启一个事务,MySQL会自动执行 set autocommit=0,并在COMMIT或ROLLBACK结束一个事务后执行 set autocommit=1.
在开发应用程序时,最好把事务的控制权限交给开发人员,即在程序端进行事务地开始和结束。
6.3 使用自动回滚
对于开发人员,重要的不仅是知道发生了错误,而是发生了什么样的错误。对事务的COMMIT,BEGIN和ROLLBACK操作应该交给程序端来完成,存储过程需要完成的只是逻辑操作
7. 长事务
长事务就是执行时间较长的事务。如果将长事务封装在一个事务中完成。在执行过程中,当数据库或操作系统、硬件等发生问题时,重新开始事务的代价变得不可接受。因此对长事务的问题,有时可以转化为小批量的事务来进行处理。当事务发生错误时,只需要回滚一部分数据,然后接着上次已经完成的事务继续进行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号