Cache
为什么需要cache
- CPU执行速度与DRAM存储器速度之间的差距越来越大,DRAM速度严重拉底了CPU的执行效率
AMAT
- AMAT:Average Memory Access Time;存储器平均访问时间
AMAT = Hit time + Miss rate*Miss Penalt
但是AMAT的计算是一个比较复杂的事情。
Hit time
先说Hit Time,即命中时的访存延迟。大家会有一个误区,命中时必须要访问L1 cache,其实不然。现代处理器大多使用Store-Load Forwarding技术。存储器读操作首先要查询的并不是L1-cache,而是在更前面执行的,还没有来得及提交的Store结果。这些结果保存在一段数据缓冲区中,这个数据缓冲区也是一种cache,不过比L1-cache更快,离CPU更近。
对于指令cache,现代处理器中,指令cache前面还有一个LFB:Line-Fill Buffer。
总之,处理器系统储存层次中, L1 cache并不是最快的,也不是第一级。
因此Hit time的计算并不容易。
即便不考虑这些内核内部的细节,只从L1 cache开始,Hit Time的计算也是比较复杂的事情。
- 在单核环境中,L1 miss后逐级查找下级cache,直至dram、disk。
- 但是在多核系统中,内核A自己的cache未命中时,所需的数据可能在内核B的cache中,此时NoC需要执行SNP操作,可能执行stash操作,内核B将数据直接转发给内核A,也可能由HN节点发送给内核A,情况比较多,计算准确时间几乎不可能。
如果考虑到SMP系统间cache的一致性,情况会更加复杂。
Miss rate
Miss penalty
miss penalty其实在Hit time已经讲过,多核、SMP对miss的影响,不确定性较多。
为什么可以cache
- 时间相关性(temporal locality):如果一个数据被访问了,那么在以后很有可能还会被访问
- 空间相关性(spatial locality):如果一个数据被访问了,那么它周围的数据在以后有可能会被访问
cache层级
L1 cache
- 分为I-Cache、D-Cache
- 一般由SRAM实现,主要是追求快
- 属于CPU流水线的一部分
- L1 cache为内核私有cache
- 超标量处理器中,L1 cache均为多端口
L2 cache
- 指令和数据共享L2 cache
- L2 cache容量比L1要大,速度会慢,主要是追求全
- 一般为单端口
L3 cache
- 一般多核共享,容量更大
- 指令数据共享
cache结构
- cache一般由3部分组成
-- 数据部分:一般为地址连续的多个数据,比如64bytes
-- tag:存储连续数据对应地址的公共部分
-- cache line状态位
如下图所示: - 地址被分为若干部分
-- word & byte用来索引一个cache line中的某个byte(位宽与cache line中byte数量有关)
-- index用来索引具体cache line(位宽与每一个set中cache line的count有关)
-- tag为剩下的地址,直接存放在tag域中,
-- 下图中,cache为4路组相连,通过index直接索引到所有4个set中相同index的4个cache line,将目标addr的tag同时和4个cache中的tag进行比较,判断是否hit及hit时的way number,同时通过word & byte得到对应的byte数据。

cache组成方式
- 直接映射:某个地址对应数据,只能存放在cache中一个地方
- 全相连:某个地址对应数据,可以存放在cache中所有的地方
- 组相连:某个地址对应数据,可以存放在cache中多个地方
- 普通cache一般采用组相连

组相连
- 组相连是最常见的方式
- 如果一个地址的数据,可以放在n个cache line中,则称为n-way组相连
- 组相连的tag和data分别存放在两个SRAM中
-- Tag SRAM & Data SRAM
-- 两个SRAM可以并行访问:速度快,功耗高;也可以串行访问:速度慢,功耗低
下图为2路组相连实例:

Cache写入
- I-Cache只会读,不会执行写;即使有自修改(self-modifying),也要借助D-Cache,将要改写的指令作为数据,通过D-Cache完成
write hit时
- write through(写通)
-- CPU执行写操作时,直接将数据同时写入cache和SRAM(cache中数据为clean状态)
-- 缺点:速度慢 - write back(写回)
-- 执行store指令时,数据只写入cache,不写入SRAM
-- 速度快,但是cache和SRAM中数据不一致,此时cache中数据状态为Dirty
write miss时
-
Non-write allocate
-- 直接将数据写入到SRAM中,不写入cache -
write allocate
-- 需要将数据写入到cache中,此时需要先执行读操作,将数据读到cache中,再执行写cache;此时可以采用write through或者write back一般write through和Non-write allocate搭配;write back和write allocate搭配


cache替换策略
- 如果 cache miss,且对应index的n-way cache line均已经被使用,此时需要替换一个cache line出去
- 纯FIFO替换
-- 玄铁C910的I-Cache采用FIFO替换, 每一次替换更新完某一路的 Cache line 后就会将 fifo_din 位取反,代表下一次替换另一路,从而实现 FIFO 的替换逻辑 - LRU(Least Recently used)
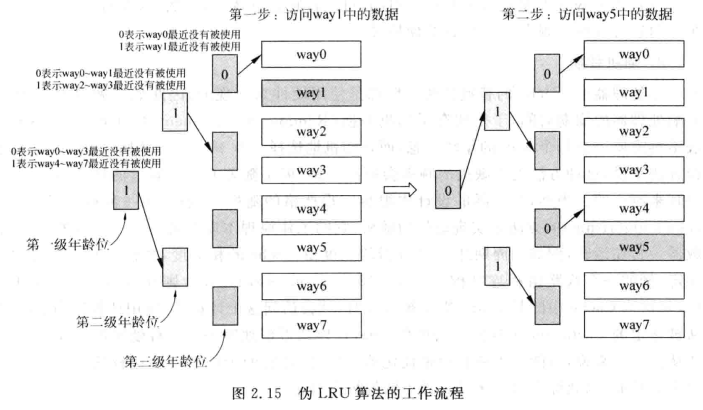
-- 将最近最少使用的cache line替换出去;一般需要对每个cache line增加一个计数器,每被访问一次,数值加1,或者其他数值减1;但是way数量增加时,LRU实现代价太大,因此基本使用伪LRU - 伪LRU
-- 用 树型位向量 或 状态机 近似 “谁最久没被访问”,面积减半,命中率接近真 LRU。
| 名称 | 商用核 | 机制 | 硬件 |
|---|---|---|---|
| Tree-PLRU | ARM A76 | 二叉树 | W-1 bit |
| Bit-PLRU | Intel Sunny Cove | 环形移位 | W bit 循环指针 |
| DRRIP | 玄铁 C930 | 2 bit 概率更新 | 2 bit / line |
| NRU | Apple M2 | Not Recently Used | 1 bit / line,周期清 0 |
| 核 | 年份 | 缓存 | 替换算法 | 硬件开销 | 是否伪 LRU |
|---|---|---|---|---|---|
| C910 | 2019 | ICache | FIFO (1 bit) | 1 bit / set | ❌ |
| C930 | 2025 | L1/L2/L3 | DRRIP (2 bit) | 2 bit / line | ✅(概率型) |
cache性能提升手段
写缓存
- 如果被替换的cache line是dirty,此时需要先将dirty数据写回SRAM,再串行读SRAM,效率低;
- 写缓存:将被替换的dirty cache line,先存放在一个buff中
- 提高效率,但设计会复杂(miss时,需要检查写buff中是否命中,增加比较电路)
流水线
- 比如写命中时,需要先访问tag SRAM,命中之后,才能写data SRAM
- 可以使用两级流水线实现,

多级cache

victim cache
- cache中被替换的数据有可能会马上被访问。比如2way 组相连中,如果程序频繁使用3个数据,且这3个数据在同一个set中,就会导致数据频繁被替换出去,导致始终无法命中
- victim cache用来存放被替换出去的cache,全相连;VC可以提升cache命中率
- 一般cache和victim cache不会存放相同的数据
- victim cache在cache之后(还有一种Filter cache,是在cache之前,数据被访问时,先放在filter cache,而不是cache,只有再次被访问时,才会真正放入cache中)

prefetch预取
- 执行第一条指令时,cache为空,此时会miss,为了减少这种miss,在未使用时,可以硬件/软件提前cache数据
多端口cache
- 现代处理器,单周期可以执行多条load/store指令,因此需要多端口cache
- 考虑到cache容量较大,多端口设计难度大,现代处理器一般采用multi-bank机制
- multi-bank
-- 将cache分为多个bank,每个bank有独立的端口
-- 如果同时访问不同的bank,可以通过各自端口直接访问
-- multi-bank要尽量避免出现back冲突

 浙公网安备 33010602011771号
浙公网安备 33010602011771号