陈明灿-第二次作业
| 这个作业属于哪个课程 | 至诚软工实践F班 |
|---|---|
| 这个作业要求在哪里 | 第二次作业 |
| 这个作业的目标 | 使用fiddler抓包工具抓去数据,并进行解析 |
| Github 地址 | Github地址 |
第二次作业:个人编程
一、实时监控朴朴上某产品的详细价格信息
【必做】基础:使用 fiddler 抓包工具+代码,实时监控朴朴上某产品的详细价格信息
解题思路
在获得题目时,首先明确自己所需要使用的工具
- 1、fiddler-- 抓包工具,可以将网络传输发送与接收的数据包进行截获、重发、编辑等操作。
- 2、浏览器--开发者工具,NetWork:从发起网页页面请求Request后分析HTTP请求后得到的各个请求资源信息
- 3、安卓模拟器--使用夜神模拟器
实现过程
首先安装好fiddler 后我们需要进行一些系统的配置,由于校园网限制代理服务器,所以采用移动热点继续进行,首先我们获取本地的ipv4地址,进入命令控制符使用指令获取
WIN+R->cmd->ipconfig
- [ ]

fiddler 的配置,打开连接及安装证书
位置:Tools->Options->Connections

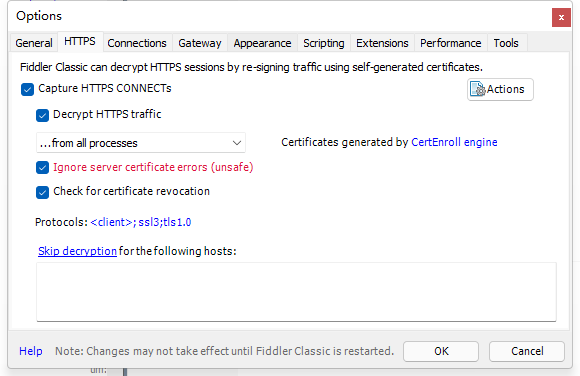
配置完成后我们使用夜神模拟器,添加网络代理,在我们添加代理后,可以尝试打开APP操作来进行抓包,此时可能会有APP限制抓包【禁用网络】,原因及解决方法在下面

在使用抓包工具进行抓包时,我们可能会遇到APP没有网络等原因,很大可能是因为所配置的证书不被信任,所以我们可以禁止SSL证书验证来破解APP的抓包限制,要解决这个问题要使用的工具是:Xposed+JustTrustMe
XposedInstaller(xposed框架)是一款可以在不修改APK的情况下影响程序运行(修改系统)的框架服务,基于它可以制作出许多功能强大的模块,且在功能不冲突的情况下同时运作。而JustTrustMe是Github上的一个开源工程,他是一个Xposed模块,用来禁止SSL证书验证。【夜神模拟器有提供安装包进行下载配置】
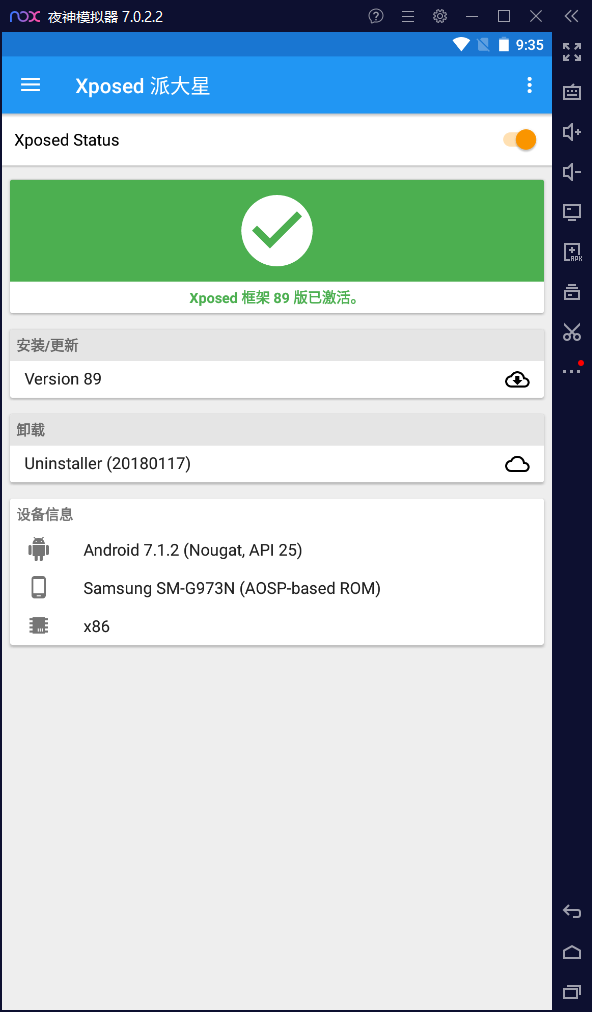

现在准备工作就已经完成,我们可以开始正式的进行APP抓包,我们打开朴朴选择一个产品,在fiddler中可以看到接口信息及返回信息
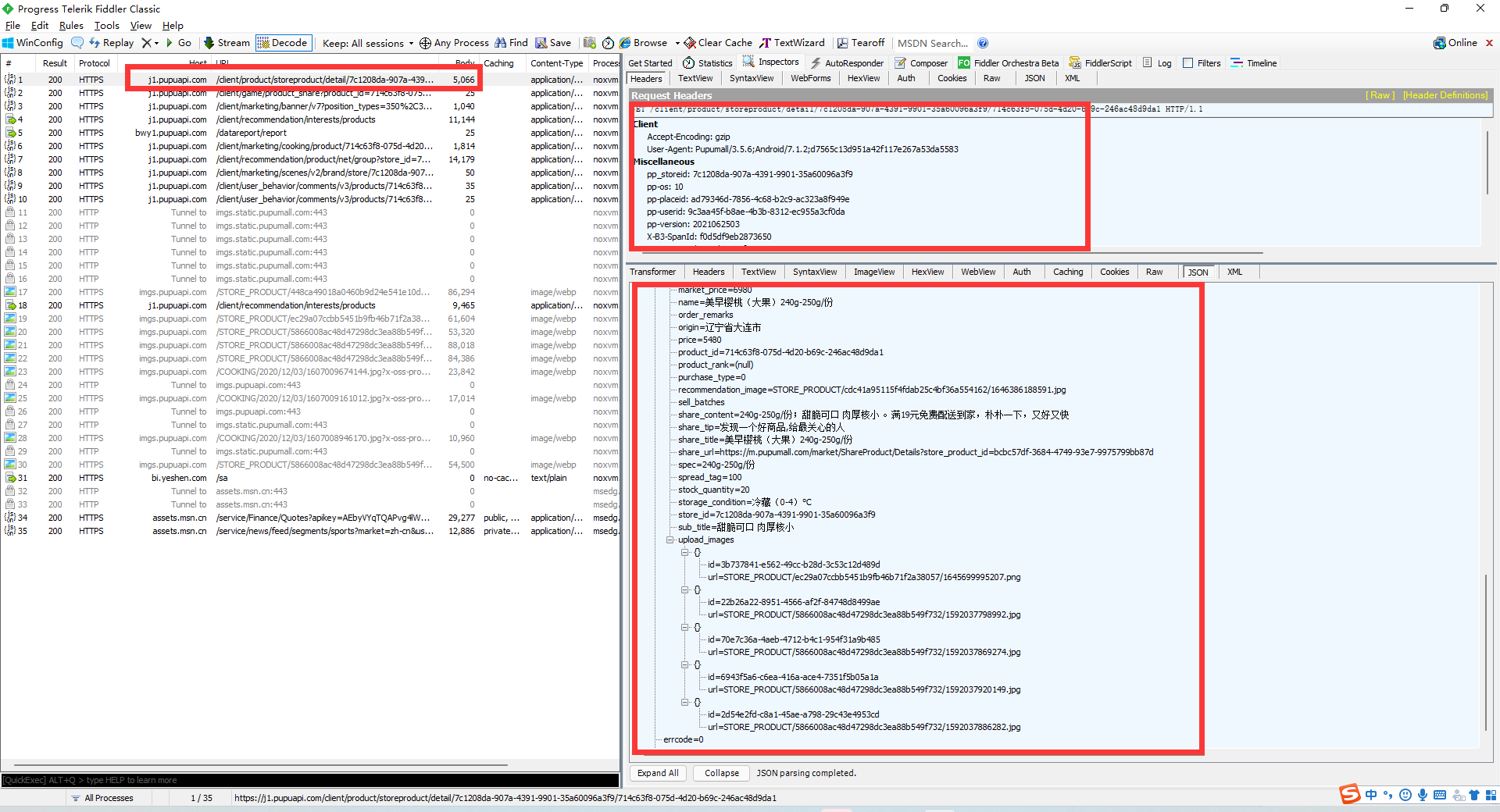
此刻,我们已经获取到朴朴商品的接口信息,接口信息如下:
接口地址:
https://j1.pupuapi.com/client/product/storeproduct/detail/7c1208da-907a-4391-9901-35a60096a3f9/714c63f8-075d-4d20-b69c-246ac48d9da1
请求头:
pp-version: 2021062503
pp_storeid: 7c1208da-907a-4391-9901-35a60096a3f9
pp-placeid: ad79346d-7856-4c68-b2c9-ac323a8f949e
User-Agent: Pupumall/3.5.6;Android/7.1.2;d7565c13d951a42f117e267a53da5583
pp-userid: 9c3aa45f-b8ae-4b3b-8312-ec955a3cf0da
pp-os: 10
Authorization: Bearer eyJhbGciOiJIUzI1NiJ9.eyJzdWIiOiIiLCJhdWQiOiJodHRwczovL3VjLnB1cHVhcGkuY29tIiwiaXNfbm90X25vdmljZSI6IjAiLCJpc3MiOiJodHRwczovL3VjLnB1cHVhcGkuY29tIiwiZ2l2ZW5fbmFtZSI6IjEzMzU4NTkzMTA5IiwiZXhwIjoxNjQ3MzU4MDE4LCJ2ZXJzaW9uIjoiMi4wIiwianRpIjoiOWMzYWE0NWYtYjhhZS00YjNiLTgzMTItZWM5NTVhM2NmMGRhIn0.PKwOKHLWe7N6tKUe28HhXeqmJNbiNWtoa79Jxfepr-w
X-B3-TraceId: 52cd9c18efe60e40
X-B3-SpanId: f0d5df9eb2873650
Host: j1.pupuapi.com
Connection: Keep-Alive
Accept-Encoding: gzip
我们可以使用任意编程语言进行解析,该题采用python,如下
"""
监控朴朴上某产品的详细价格信息
"""
import requests
import time
# 获得商品详情json
def getProduct():
url = "https://j1.pupuapi.com/client/product/storeproduct/detail/7c1208da-907a-4391-9901-35a60096a3f9/97721095-5c55-4746-bd9e-8c98ef2946a3"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'
}
result = requests.get(url=url, headers=headers)
data = result.json()['data']
return data
# 获得商品名
def getName(result):
return result['name']
# 获得产品规格
def getSpec(result):
return result['spec']
# 获得现价
def getPrice(result):
return float(result['price']) / 100
# 获得原价
def getMarketPrice(result):
return float(result['market_price']) / 100
# 获得详细内容
def getShareContent(result):
return result['share_content']
# 获得实时价格
def nowPrice():
return float(getProduct()['price']) / 100
if __name__ == '__main__':
# 调用接口,获得商品数据
proData = getProduct()
# 获得商品名称
proName = getName(proData)
# 获得产品规格
proSpec = getSpec(proData)
# 获得产品现价
proPrice = getPrice(proData)
# 获取产品原价
proMarketPrice = getMarketPrice(proData)
# 获取产品详细内容
proContent = getShareContent(proData)
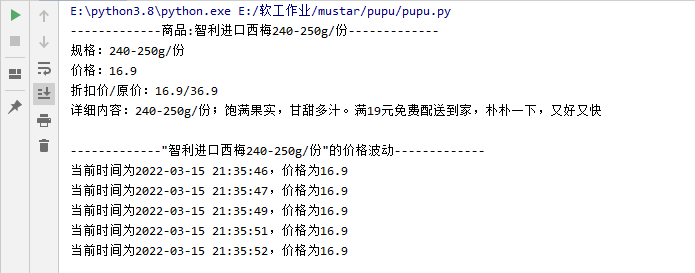
print('-------------商品:%s-------------' % proName)
print('规格:%s' % proSpec)
print('价格:%.1f' % proPrice)
print('折扣价/原价:%.1f/%.1f' % (proPrice, proMarketPrice))
print('详细内容:%s\n' % proContent)
print('-------------"%s"的价格波动-------------' % proName)
# 循环获取目前价格
while True:
# 获得当前时间
dateTime = time.strftime("%Y-%m-%d %H:%M:%S" , time.localtime())
print('当前时间为%s,价格为%.1f' % (dateTime, nowPrice()))
time.sleep(1)
当运行该文件时,控制台输出结果如下:
在项目进行调试,我们能够发现以下问题:
- 当接口在同ip下短时间内多次调用,我们会遇到ip被封禁的情况,我们可以采用以下方法进行规避:
- 更换User-Agent
- 使用多个代理IP进行抓包
二、爬取自己的知乎收藏夹,以每个收藏夹的名称为大类,其下展示各个具体收藏文章的名称及其链接。
面对这题,没有使用fiddler进行抓包,我们可以通过浏览器开发者工具中的network进行监控数据的传输,打开开发者工具【F12】后我们可以找到network。
在我们进入页面时,network可以监听数据的传输,此时我们进入个人页面可以找到收藏夹的接口
接口地址:https://www.zhihu.com/api/v4/people/mu-shang-zhu-42/collections
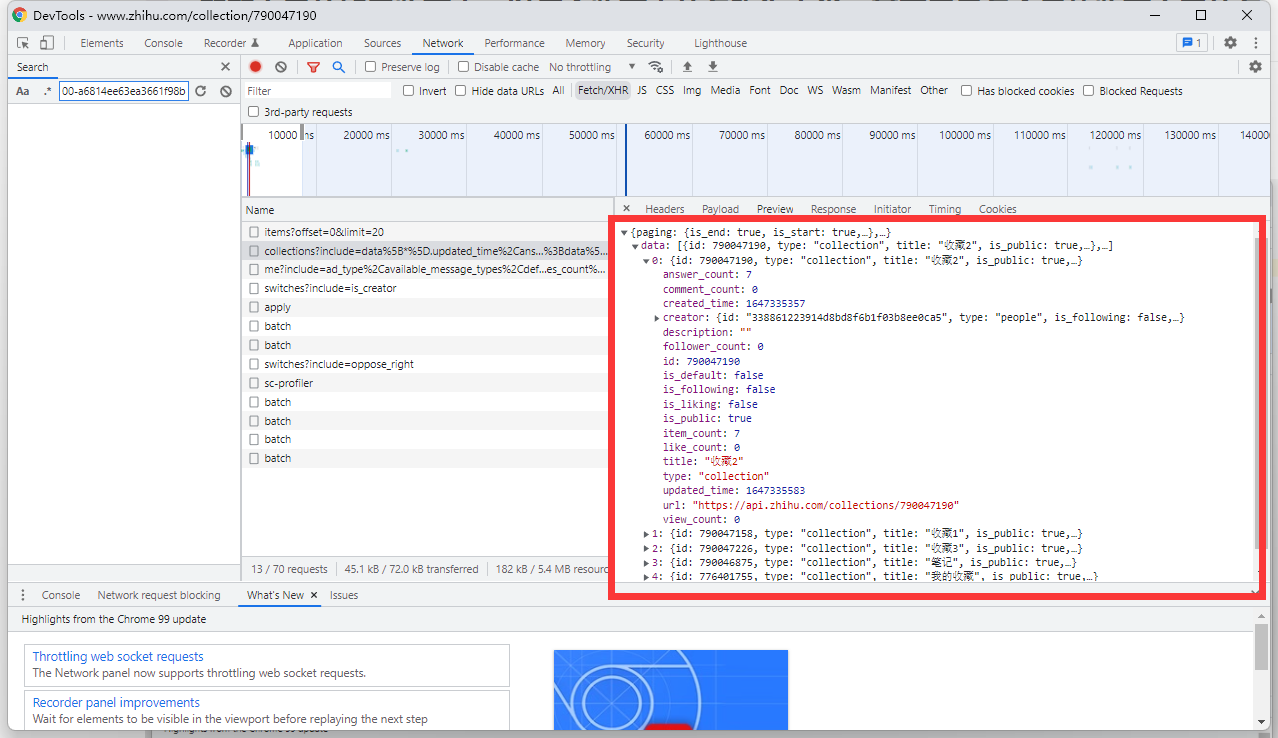
我们可以得知该接口通过GET进行调用,可将接口地址复制到浏览器中进行查看,此时浏览器页面中会加载调用接口返回的json数据,如下:
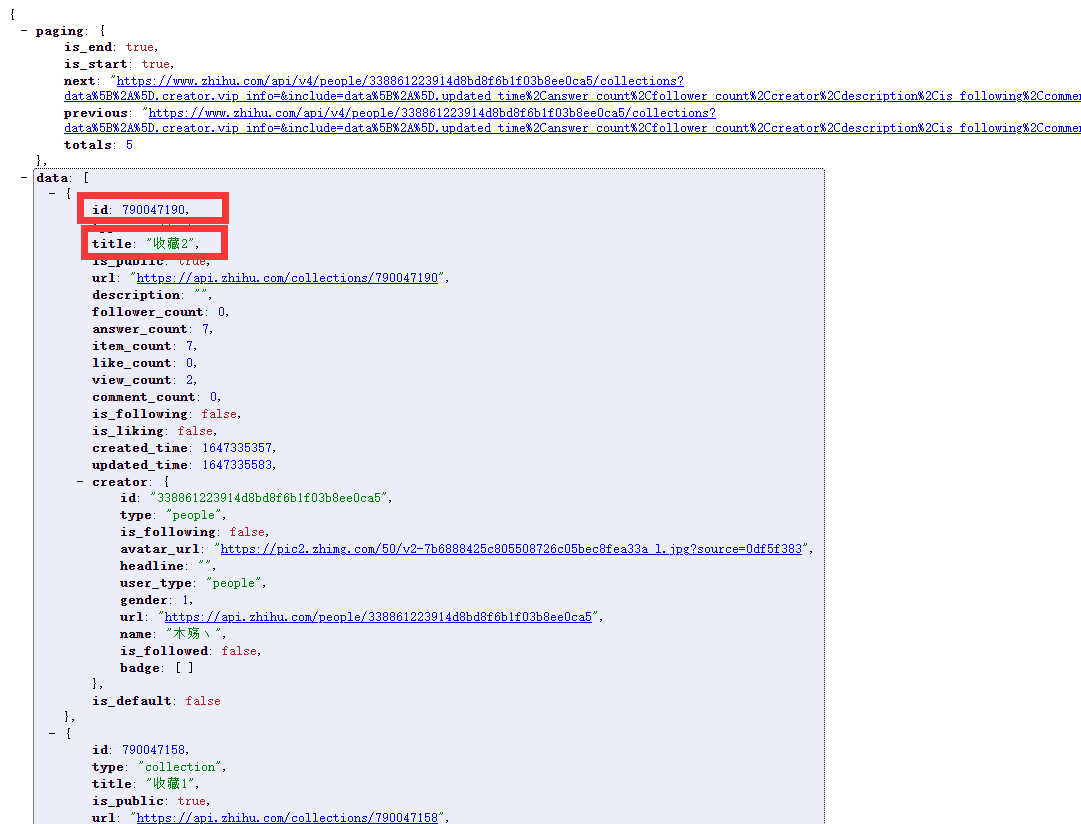
此接口我们主要的目的是获取所有收藏夹的名称及id可通过json数据查看该数据对应的key为id及title,获取到id后我们可以再次进行接口的获取,此时点击进入某个收藏夹的页面,可以获取到收藏夹内所有收藏文章的接口
接口地址:https://www.zhihu.com/api/v4/collections/790047190/items
其中790047190为我们由上个接口获取到的收藏夹id
同样,我们将它放到浏览器中,可以清楚的查看json数据
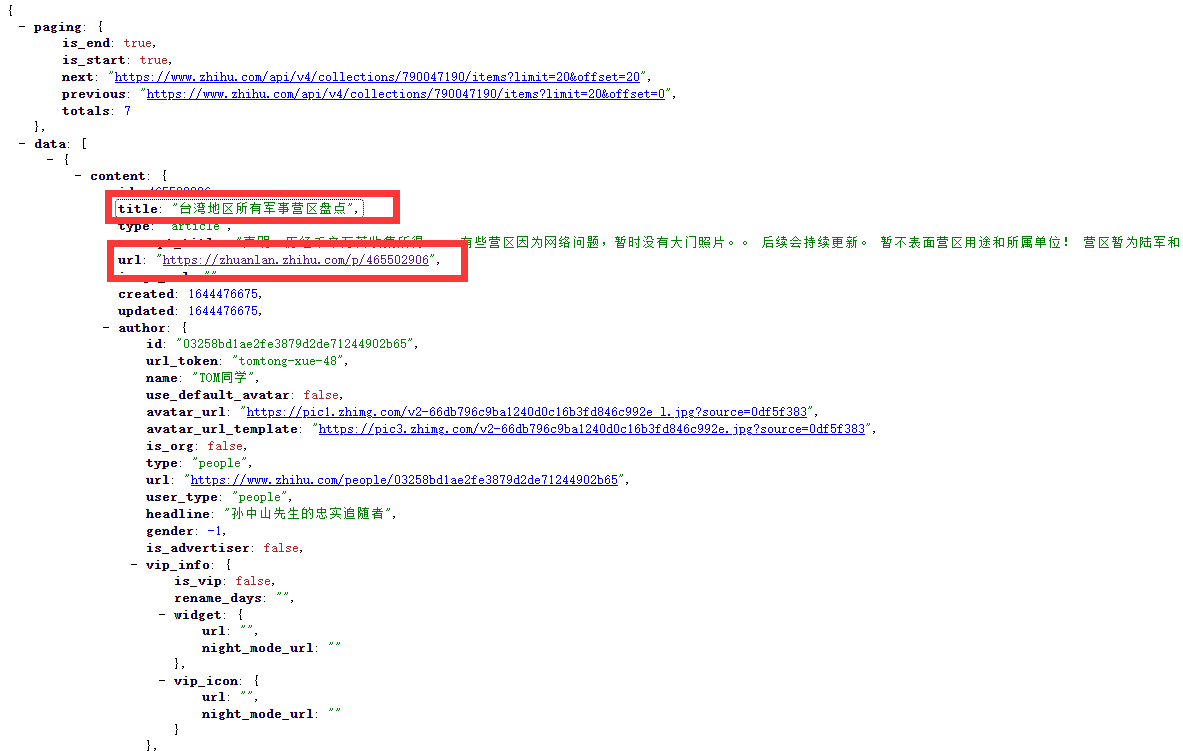
我们可以在其中清楚的看到我们所需要的数据,标题和链接,此刻我们就可以使用python去进行数据的爬取及解析,但在此前,我们需要考虑的是收藏文章的类型,在进行检验时可以发现,收藏的分为两种类型【文章和问答】,而问答所获取的json数据和文章有所不同,如下:
此为收藏文章的json数据:
content: {
id: 465502906,
title: "台湾地区所有军事营区盘点",
type: "article",
.......
url: "https://zhuanlan.zhihu.com/p/465502906",
.......
}
此为收藏问答的json数据:
content: {
id: 2382903605,
type: "answer",
answer_type: "NORMAL",
url: "https://www.zhihu.com/question/520705594/answer/2382903605",
created_time: 1646898142,
updated_time: 1646898391,
question: {
type: "question",
id: 520705594,
title: "应届生加了 HR 的微信,应该称呼她为什么?",
question_type: "normal",
created: 1646708241,
updated_time: 1646879369,
url: "https://www.zhihu.com/question/520705594",
},
由上我们可以清楚的看到,如果是问题的标题,它会存储在content->question中,所以再用python进行爬取、解析数据的时候我们应该添加判断
articleTitle = article['content']['title']
if articleTitle=='':
articleTitle = article['content']['question']['title']
以上分析完毕,可以开始编写代码:
import requests
# 获得用户数据
def getUserDate():
url = 'https://www.zhihu.com/api/v4/people/mu-shang-zhu-42/collections'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36',
# 如果要获取自己私有的收藏夹,需要添加cookie
# 'cookie':''
}
res = requests.get(url=url, headers=headers)
return res.json()
if __name__ == '__main__':
userDate=getUserDate()
for colData in userDate['data']:
print('------------收藏夹标题:【%s】------------'%colData['title'])
url = "https://www.zhihu.com/api/v4/collections/%s/items" % colData['id']
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36',
}
res = requests.get(url=url, headers=headers).json()
i=1
for article in res['data']:
articleTitle = article['content']['title']
if articleTitle=='':
articleTitle = article['content']['question']['title']
articleLink = article['content']['url']
print('--%s:%s\t%s' % (i,articleTitle, articleLink))
i+=1
运行结果如下:

三、爬取拉勾网某个职位,某个公司规模,在某个城市的应届生薪资信息,并按照同等条件下,展示不同城市的应届生主要薪资范围分布情况。
进入拉勾网网站使用开发者工具进行网络数据的传输监控,可以发现拉勾网的接口的信息
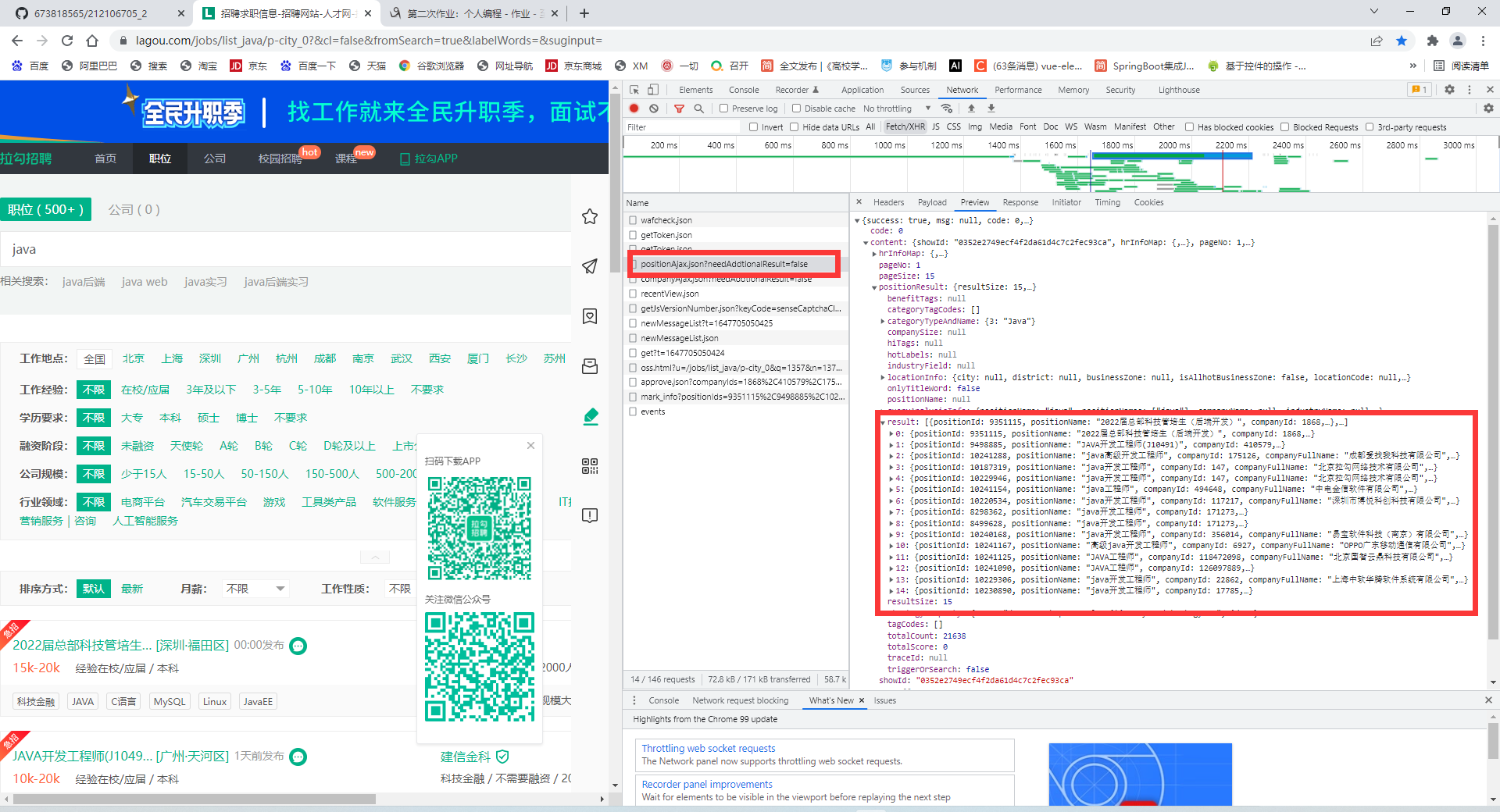
该接口采用POST提交的方式,其中一些基本的选择信息【如地点、工作经验、学历等】存放在url params,而其他的数据【搜索内容,页码】存放在data中进行提交,提交请求后能够获得JSON数据,结构大致如下:
{
"success": true,
"msg": null,
"code": 0,
"content": {
"positionResult": {
"resultSize": 15,
"result": [{
"positionId": 9351115,
"positionName": "2022届总部科技管培生(后端开发)",
......
},
},
"pageSize": 15
},
"resubmitToken": null,
"requestId": null
}
可以发现,我们需要的数据存放在content->positionResult->result中,可以使用那个代码进行json解析并输出,代码如下:
import requests
from pyecharts.charts import Bar
import pyecharts.options as opts
import re
class CityData(object):
def __init__(self,salary):
self.__salary=salary
self.__count=0
def addCount(self):
self.__count+=1
def getSalary(self):
return self.__salary
def getCount(self):
return self.__count
list=[]
def getData(page,city):
url = "https://www.lagou.com/jobs/positionAjax.json?gj=在校/应届&px=default&gm=50-150人&city=%s&needAddtionalResult=false"%city
headers = {
'accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '25',
'content-type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Host': 'www.lagou.com',
'Origin': 'https://www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_java/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=',
'sec-ch-ua':'" Not A;Brand";v="99", "Chromium";v="99", "Google Chrome";v="99"',
'sec-ch-ua-mobile':'?0',
'sec-ch-ua-platform':'"Windows"',
'Sec-Fetch-Dest':'empty',
'Sec-Fetch-Mode':'cors',
'Sec-Fetch-Site':'same-origin',
'traceparent':'00-06bc3b8a19f3c6e98fe7c56d9adcae1d-4ba823c5c818d9e9-01',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36',
'x-anit-forge-code': '0',
'x-anit-forge-token': 'None',
'x-requested-with': 'XMLHttpRequest',
'cookie':'RECOMMEND_TIP=true; privacyPolicyPopup=false; _ga=GA1.2.1516507538.1647096956; user_trace_token=20220312225557-abb182ce-3f92-4651-9c39-31ebb4c7bdfe; LGUID=20220312225557-bfa9a12c-1d6b-4ade-b9e6-dc95c59fde8b; index_location_city=%E5%85%A8%E5%9B%BD; LG_HAS_LOGIN=1; hasDeliver=0; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; _gid=GA1.2.2010130206.1647242956; __lg_stoken__=18ffbcf2b7cde16a48df0c80069759da64ed5d3427729eae87b1361b2b93ca241428d2ab358fc4b718c2b81d7decdd559a6de084027f5186c937c0190a93eda797ccccb64bc2; JSESSIONID=ABAAABAABAGABFA2095E281A00B43C351EE0D9C94CFC176; WEBTJ-ID=20220315163755-17f8cba0528482-0092a2ae47748d-977173c-2073600-17f8cba0529ca8; LGSID=20220315163755-9896ef8f-e708-40b9-bf90-ecce6c733ae5; PRE_UTM=; PRE_HOST=; PRE_SITE=https%3A%2F%2Fwww.lagou.com; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Fjobs%2Flist%5Fjava%2Fp-city%5F0%3F%26cl%3Dfalse%26fromSearch%3Dtrue%26labelWords%3D%26suginput%3D; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1647096956,1647242956,1647333476; gate_login_token=71c896588f9d88913074ddb57f208ae34641bab2fbec2a76d1a12fb63ec712ba; LG_LOGIN_USER_ID=2234f9799e36703943b23a21a509e8f4687aa0619f3e24f8880f5ebf36b5544f; _putrc=D8327F539A6189C2123F89F2B170EADC; login=true; unick=%E7%94%A8%E6%88%B73109; __SAFETY_CLOSE_TIME__24047327=1; sensorsdata2015session=%7B%7D; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2224047327%22%2C%22first_id%22%3A%2217f7ea105d34c1-087ef7f3a3bbec-977173c-2073600-17f7ea105d4d5b%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24os%22%3A%22Windows%22%2C%22%24browser%22%3A%22Chrome%22%2C%22%24browser_version%22%3A%2299.0.4844.51%22%2C%22lagou_company_id%22%3A%22%22%7D%2C%22%24device_id%22%3A%2217f7ea105d34c1-087ef7f3a3bbec-977173c-2073600-17f7ea105d4d5b%22%7D; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1647333501; SEARCH_ID=05344f68061c476ea546377ac0563232; LGRID=20220315164348-7553573f-0e4d-4a0e-a1cc-d63cbd50d2f7; X_HTTP_TOKEN=dbf713b0116db3ca8283337461a6ef4a1a8eafd163'
}
datas = {
'first': 'true',
'pn': page,
'kd': 'java工程师'
}
res=requests.post(url=url,headers=headers,data=datas,timeout=4)
return res.json()['content']['positionResult']['result']
def yanzheng(salary,list):
flag=True
for item in list:
if salary==item.getSalary():
flag=False
break
if flag:
list.append(CityData(salary))
def addCount(salary,list):
for item in list:
if salary==item.getSalary():
item.addCount()
break
if __name__ == '__main__':
try:
i=1
while True:
data=getData(i,'北京')
for item in data:
yanzheng(item['salary'],list)
addCount(item['salary'],list)
print(item['positionName'],item['workYear'], item['salary'], item['companySize'], item['city'],item['companyFullName'])
i+=1
except:
print('结束')
for x in range(len(list)):
for y in range(x+1,len(list)):
tempx = int(re.search('(\d+).*?(\d+).', list[x].getSalary()).group(1))+int(re.search('(\d+).*?(\d+).', list[x].getSalary()).group(2))
tempy = int(re.search('(\d+).*?(\d+).', list[y].getSalary()).group(1))+int(re.search('(\d+).*?(\d+).', list[y].getSalary()).group(2))
if tempx/2>tempy/2:
temp=list[x]
list[x]=list[y]
list[y]=temp
# for item in list:
# print(item.getSalary(),item.getCount())
salaryList=[]
countList=[]
for item in list:
salaryList.append(item.getSalary())
countList.append(item.getCount())
bar = Bar()
bar.add_xaxis(salaryList)
bar.add_yaxis('北京',countList)
bar.set_global_opts(xaxis_opts=opts.AxisOpts(name='薪资'),
yaxis_opts = opts.AxisOpts(name='招聘公司数量'))
bar.render("北京.html")
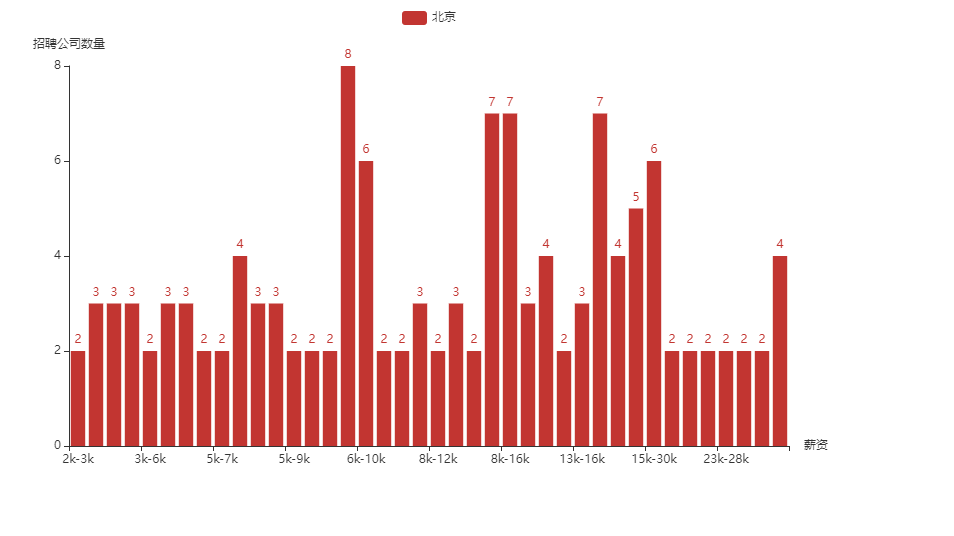
执行代码返回如下:
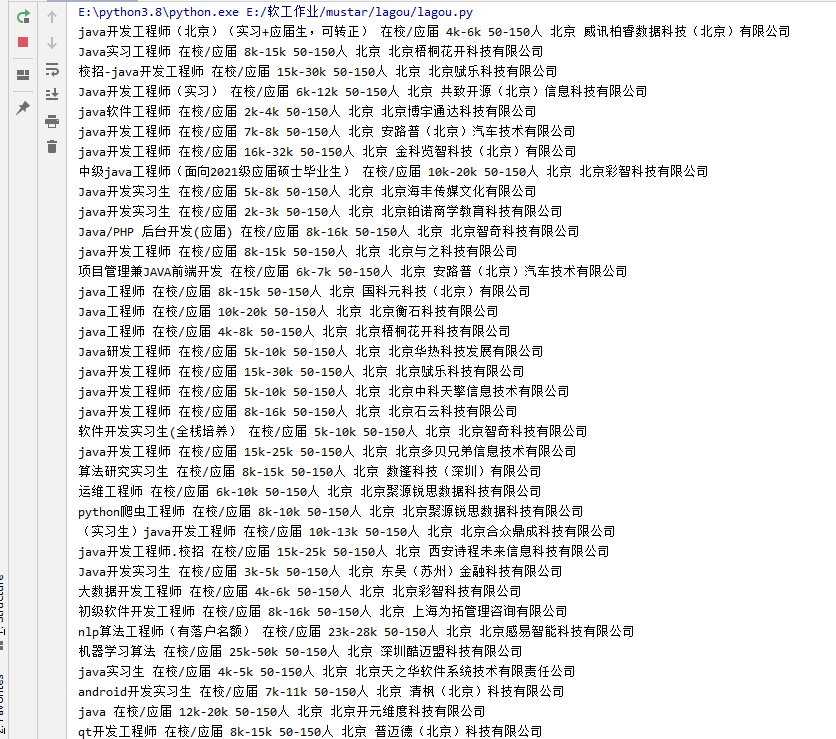
同时,我们需要对获取的数据进行可视化解析,采用pyecharts,可以达到如下效果