【PAT甲级】1053 Path of Equal Weight (30分):DFS(树的先序遍历)
题目:https://pintia.cn/problem-sets/994805342720868352/problems/994805424153280512
1053 Path of Equal Weight (30分)
Given a non-empty tree with root R, and with weight W**i assigned to each tree node T**i. The weight of a path from *R* to *L* is defined to be the sum of the weights of all the nodes along the path from R to any leaf node L.
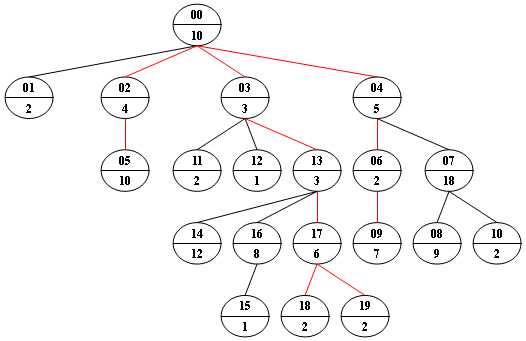
Now given any weighted tree, you are supposed to find all the paths with their weights equal to a given number. For example, let's consider the tree showed in the following figure: for each node, the upper number is the node ID which is a two-digit number, and the lower number is the weight of that node. Suppose that the given number is 24, then there exists 4 different paths which have the same given weight: {10 5 2 7}, {10 4 10}, {10 3 3 6 2} and {10 3 3 6 2}, which correspond to the red edges in the figure.
Input Specification:
Each input file contains one test case. Each case starts with a line containing 0<N≤100, the number of nodes in a tree, M (<N), the number of non-leaf nodes, and 0<S<230, the given weight number. The next line contains N positive numbers where W**i (<1000) corresponds to the tree node T**i. Then M lines follow, each in the format:
ID K ID[1] ID[2] ... ID[K]
where ID is a two-digit number representing a given non-leaf node, K is the number of its children, followed by a sequence of two-digit ID's of its children. For the sake of simplicity, let us fix the root ID to be 00.
Output Specification:
For each test case, print all the paths with weight S in non-increasing order. Each path occupies a line with printed weights from the root to the leaf in order. All the numbers must be separated by a space with no extra space at the end of the line.
Note: sequence {A1,A2,⋯,A**n} is said to be greater than sequence {B1,B2,⋯,B**m} if there exists 1≤k<min{n,m} such that A**i=B**i for i=1,⋯,k, and A**k+1>B**k+1.
Sample Input:
20 9 24
10 2 4 3 5 10 2 18 9 7 2 2 1 3 12 1 8 6 2 2
00 4 01 02 03 04
02 1 05
04 2 06 07
03 3 11 12 13
06 1 09
07 2 08 10
16 1 15
13 3 14 16 17
17 2 18 19
Sample Output:
10 5 2 7
10 4 10
10 3 3 6 2
10 3 3 6 2
分析:DFS(树的先序遍历)
题意:输出点权和为S的路径,以字典序。
- DFS遍历时计算一条路径的weight,只需要在每次递归DFS时传参
weight+Node[index].data即可。
不要单独拿出来一句语句weight+=Node[index].data,因为和临时路径temp一样(每次push新节点后还要pop以保证其他路径没有收到影响),相应语句weight-=Node[index].data 很容易忘记写导致错误。
- 最后路径需要按照字典序输出,有两种方法:
- 方一:设置变量
vector<vector<int>> ans,将所有路径加到ans,最后用sort()对ans元素进行排序。 - 方二:在未进行DFS前,用sort()先对输入的树的数据进行结构调整,使路径一开始按照字典序排列的,之后进行DFS遍历时就可以直接输出路径了。
- 方一:设置变量
代码
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
const int maxN=110;
struct node {
int data=0;
vector<int> child;
} Node[maxN];
int N,M,S;
vector<vector<int>> ans;//路径集合
vector<int> temp;//临时路径
void DFS(int root,int weight) {
if(weight>S) {
return;
}
if(weight==S) {
if(Node[root].child.size()==0) {
ans.push_back(temp);
}
return;
}
for(int i=0; i<Node[root].child.size(); i++) {
int index=Node[root].child[i];
temp.push_back(Node[index].data);
DFS(index,weight+Node[index].data);
temp.pop_back();
}
}
int main() {
scanf("%d%d%d",&N,&M,&S);
for(int i=0; i<N; i++) {
scanf("%d",&Node[i].data);
}
int index,childNum,childNo;
for(int i=0; i<M; i++) {
scanf("%d%d",&index,&childNum);
for(int j=0; j<childNum; j++) {
scanf("%d",&childNo);
Node[index].child.push_back(childNo);
}
}
temp.push_back(Node[0].data);
DFS(0,Node[0].data);
sort(ans.begin(),ans.end(),greater<vector<int>>());//从大到小排序ans
for(int i=0; i<ans.size(); i++) {
for(int j=0; j<ans[i].size(); j++) {
printf("%d",ans[i][j]);
if(j<ans[i].size()-1)
printf(" ");
else
printf("\n");
}
}
return 0;
}
注意
-
[Error] base operand of '->' has non-pointer type 'node'
”->“前不是指针。
对象调用成员变量用.
struct node {
int data=0;
vector<int> child;
} Node[maxN];
//Node[root].data
指针引用成员变量->
struct node {
int data;
node* lchild;
node* rchild;
}Node;
//Node->rchild
- 用sort()对vector<vector<int>>排序
- sort()参数写ans.begin()和ans.end()。
- 注意比较器的写法
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
vector<int> v1= {10,5,2,7};
vector<int> v2= {10,3,3,6,2};
vector<int> v3= {10,3,3,6,2};
vector<int> v4= {10,4,10};
vector<vector<int>> ans;
bool cmp(vector<int> v1,vector<int> v2) {
return v1>v2;
}
//比较器的错误写法
//bool cmp(vector<int> v1,vector<int> v2) {
// if(v1>v2) return v1>v2;
// else return v1<v2;
//}
int main() {
ans.push_back(v1);
ans.push_back(v2);
ans.push_back(v3);
ans.push_back(v4);
// sort(ans[0],ans[0]+2*2,cmp);//错误:取到了一个vector,是对象
sort(ans.begin(),ans.end(),cmp);//取到了一个迭代器//方一
// sort(ans.begin(),ans.end(),greater<vector<int>>());//方二
for(int i=0; i<ans.size(); i++) {
vector<int> temp=ans[i];
for(auto x:temp)
cout<<x<<" ";
cout<<endl;
}
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号