ORACLE表类型、索引类型和表分区详解
ORACLE表、索引和分区
看完这篇总结,胜读十天书
一、数据库表
每种类型的表都有不同的特性,分别应用与不同的领域
堆组织表
聚簇表(共三种)
索引组织表
嵌套表
临时表
外部表和对象表
1.行迁移
建表过程中可以指定以下两个参数:
PCTFREE:自由空间,默认值10
PCTUSED(只适用于MSSM):默认值40
设置这两个参数很重要:
一方面避免迁移过多的行,影响性能
一方面避免浪费太多的空间
当自由空间存不下更新后的某一行时,这一行将会发生行迁移,在两个块上存储这一行数据,如下图:

2.堆组织表
基本上我们使用的表都是堆组织表(heap organized table),堆是无序的数据结构,数据的存取都是随机的,想要排序必须使用order by子句
对于ASSM有三个重要的选项:
PCTFREE
INITRANS:默认值 2,高并发会设置更大一些
COMPRESS/NOCOMPRESS:启用/禁用压缩
3.索引组织表(IOT)
以索引结构存储的表
使用场景:
信息检索
空间数据
OLAP应用
创建,使用organization index子句:
create table tbl( name varchar2(20), age int ) organization index
与堆组织表对比:
提高缓冲区缓存效率,因为需要的块更少
减少缓冲区缓存访问
获取数据快,工作量少
完成查询的物理I/O更少
因为所有数据都放入索引,所以当表的数据量很大时,会降低索引组织表的查询性能
4.散列聚簇表
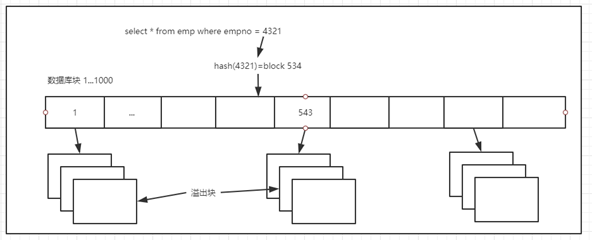
散列聚簇表与索引聚簇表非常相似,一个主要区别就是:聚簇索引被一个散列函数所取代,表中的数据就是索引,散列聚簇表会预分配(hashkeys/trunc(blocksize/SIZE))个块的存储空间,SIZE为设置的SIZE向上取最小的质数,当hash冲突时会分配溢出块与原来的块连接起来
创建步骤:
创建聚簇对象:create cluster hash_cluster(hash_key number) hashkeys 1000 size 1024;
创建表: create table hash_table(x number, y varchar2(4000), z varchar2(400)) cluster hash_cluster(x);
注意:
无法对散列聚簇中的表进行区间扫描来定位数据,需要建立传统索引实现
建立散列聚簇表的目的是根据散列值快速定位数据,减少缓冲区缓存链闩,而不是平凡的全表扫描
散列是CPU密集型操作,但索引所需的I/O会是散列的3倍,可以根据I/O和CPU资源选择
5.有序散列聚簇表
有序散列聚簇不仅有散列聚簇的特性,还结合了IOT的一些性质
场景:
按照某个键查询在按某一列排序
select * from where key=:x order by sorted_column;
创建步骤:
创建聚簇:create cluster shc(clust_id number, order_col number sort) hashkeys 100 hash is cust_id size 8192;
创建表:create table cust_orders(clust_id number, order_col number, z varchar2(400)) cluster shc(clust_id, order_col);
6.对象表
一种基于Oracle类型的表
特点:
由于对象表实际上就是伪装的关系表,这么做与Oracle表功能没什么区别,但效率更高
创建:
create or replace type address_type as object(city varchar2(20), street varchar2(20));
create or replace type person_type as object(name varchar2(20), home_addr address_type, work_addr address_type);
create table people of person_type;
插入:
Insert into people values(‘ruphy’, address_type(‘gy’, ‘zunyi’), address_type(‘sz’, ‘bantian’));
查询:
Select name, p.home_addr home, p.work_addr work from people p;
7.嵌套表

创建:
create or replace type emp_type as object(empno number, ename varchar2(40), job varchar(9));
create or replace type emp_tab_type as table or emp_type;--对象表
create table dept(deptno number primary key, dname varchar2(40), emps emp_tab_type);
查询:
Select d.deptno, d.dname, emp.* from dept d, table(d.emps) emp;
插入:
Insert into table(select emps from dept where deptno = 10) values(123, ‘new’, ‘java’);
更新/删除
update/delete table(select emps from dept where deptno = 10) set job = ‘C#’;
8.临时表
可以使用临时表(temporary table)来保存事务或者会话内的临时结果集
特点:
隔离性
无并发性问题
静态定义
效率高,产生重做日志少
可以有触发器、检查约束、索引,但不能有完整性约束、不能有嵌套列、不能是IOT、不能有聚簇、不能分区、不能使用analyze命令生成统计信息
类型:
基于会话:create global temporary table temp_table_session on commit preserve rows ;
基于事务:create global temporary table temp_table_session on commit delete rows ;
二、数据库索引
最好在应用设计期间考虑索引应该如何设计,不要事后才想起来,这样有助于清楚地知道需要建立什么样的索引
Oracle提供几种类型的索引:
B*TREE索引
T*TREE聚簇索引
降序索引
反向键索引
IOT位图索引
位图级联索引
函数索引
应用域索引
1.B*TREE索引
--类似于二叉树结构的索引,扩展性非常
分析一下几种情况:
Where x between 20 and 30
Where x = 10047
2.反向键索引
--对B*TREE索引键反转建立的索引
主要用途是减少“右手”索引中索引页块的竞争
创建: create index idx on t(x,y) reverse;
分析一下几种情况:
Where x > 5
Where x = 5
3.降序索引
--对B*TREE索引扩展,以从大到小的方式存储
主要用途是对多个列进行排序,且顺序要求不一致时使用降序索引可以避免数据库额外的排序
创建:create index desc_t_idx on t(owner desc, object_type asc)
分析:select * from t where owner between ‘T’ and ‘Z’ order by owner desc, object_type asc;
4.什么时候走B*TREE索引
两个“经验”:
访问表中非常少的部分,到底多少与列数有关
访问表中大量数据时,数据可以直接从索引中拿到(覆盖索引)
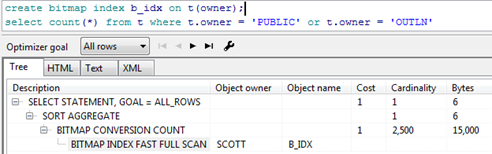
5.位图索引
--位图索引是为数据仓库/即席查询设计
与B*TREE索引不同,位图索引的一个索引键会指向多行数据
位图索引特别不适用于OLTP系统(平凡的更新)
创建:create bitmap index b_idx on t(owner);
位图索引对or and not会执行位操作,存储结构如下:

6.位图级联索引
在一个表上建立的索引基于另一个表的列(主键或者唯一键),将数据在索引中逆规范化
场景:销售部门多少人?谁在销售部工作?销售部业绩最好的三个人?
创建:create bitmap index ed_idx on emp(d.dname) from emp e, dept d where e.deptno = d.deptno

7.什么时候位图索引
位图索引特别适用于低基数(相异基数低)
相异基数大小取决于结果集行数,相异基数与总行数之比趋近与0才算低相异基数,如2000行的表,相异基数为3,那么3/2000=0.0015很小,适合位图索引
系统会运行大量的即席查询,特别是查询会使用多列数据或者使用诸如count之类的聚合函数
8.函数索引
可以基于函数建立索引,本质上也是位图索引或者B*TREE索引的扩展
使用场景:
通过计算结果建立索引,方便需要使用函数计算后比叫时能够立即用上
不用修改任何逻辑或查询,就可以加快现有应用
只对感兴趣的值键索引
创建:
create index f_idx on t(lower(owner));
create index f_idx on t(case owner when ‘PUBLIC’ then ‘PUBLIC’ end);
9.虚拟列索引
虚拟列
不占用存储过程,在查询表数据时sql函数动态计算的返回值,不超过6398字节
创建:alter table t add cal as (lower(owner));
可以在虚拟列建立一个索引,以提高查询效率
创建: create index v_idx on t(cal);
10.组合索引
联合索引时列的选择原则
最左匹配原则
最左匹配原则
最少空间原则
创建如下索引:
alter table T add constraint id_key primary key (OBJECT_ID);
create index u_idx on t(upper(object_type), owner);
create index f_idx on t(owner);
分析:
Select * from t where object_id = 5;
Select * from t where owner = ‘SYS’;
Select * from t where object_type = ‘INDEX’;
Select * from t where upper(object_type) = ‘INDEX’;
Select * from t where upper(object_type) = ‘INDEX’ and owner = ‘SYS’;
Select count(*) from t;
11.不走索引原因
谓词不在组合索引的最前列(最前列值比较少也会走索引)
Select count(*) from t;有索引但没有索引列没有非空约束
Select * from t where f(x) = :x;对非函数索引列使用了函数
Select * from t where y = 5; (y为字符串)发生了隐式转换
查询的结果集超过了阈值
表上的统计信息不是最新的,dbms_stats.gather_table_stats(user, ‘T’);
将索引标记为invisible
三、数据库表分区
分区将一个表或索引物理地分解为多个更小、更易管理的部分,使用了一种“分而治之”的方法,设用于管理非常大的表
注意,分区不一定能提高性能,会产生三种情况:
应用可能运行更慢
可能运行更快
也可能没有任何变化
1.分区的优势
提高数据可用性(独立性)
将大段分解为小段,从而减轻管理负担
改善某些SQL语句(SIUD)性能性能(读取信息语句、修改信息语句(PDML))
把数据修改分散,减少并发下系统的竞争
实现数据滑动窗口(去除旧数据,加载新数据并建立索引,将新数据纳入分区表)
2.分区机制
区间分区(范围分区)
散列分区
列表分区
间隔分区:区间分区+自动创建分区
引用分区
间隔引用分区
虚拟列分区
组合分区
系统分区:比较少见
3.区间分区
创建:
create table range_t(range_key_column data not null, data varchar2(20)) partition by range(range_key_column)(partition part_1 values less than(to_date(‘20180101’, ‘yyyymmdd’)) ,partition part_2 values less than(to_date(‘20190101’, ‘yyyymmdd’)),partition part_3 values less(maxvalue));
4.散列分区
创建:
create table hash_t(range_key_column date, data varchar2(20)) partition by hash(range_key_column) (partition part_1 tablespace p1,partition part_2 tablespace p2);
5.列表分区
创建:
create table list_t(list_key_column varchar(2), data varchar2(20)) partition by list(list_key_column)(partition part_1 values('A', 'B'),partition part_2 values('C'));
6.虚拟列分区
创建:
create table res(res_code varchar(2), region as (decode(substr(res_code,1,1), 'A', 'NE', 'C', 'NE','B','SW','D','NW'))) partition by list(region)(partition p1 values('NE'), partition p2 values('SW'), partition p3 values('NW'));
7.组合分区
创建:
create table composite_t(range_c date, hash_c int, data varchar(2)) partition by range(range_c) interval (numtoyminterval(1, ‘year’)) subpartition by hash(hash_c) subpartitions 2 (partition p1 values less than(to_date(‘20180101’, ‘yyyymmdd’))(subpartition p1s1,subpartition p1s2), partition p2 values less than(to_date(‘20190101’, ‘yyyymmdd’))(subpartition p2s1,subpartition p2s2));
8.索引分区
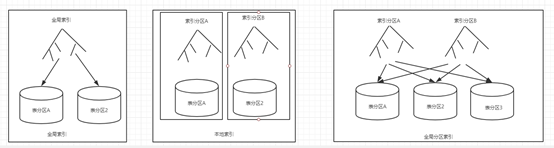
本地索引:按表分区的方式对所有分区
本地前缀索引
本地非前缀索引
创建: create index l_idx on t(owner, object_type) local;
全局分区索引:按区间或散列对索引分区
创建:create index g_p_idx on t(owner, object_type, object_name) global partition by hash(owner) partitions 16;
全局索引

 浙公网安备 33010602011771号
浙公网安备 33010602011771号