

nccl-1_initialization & bootstrap
nccl学习-1: 初始化communicator与bootstrap 网络
NCCL版本:基于v2.28.9-1
图片制作:飞书
在nccl的例子中,当我们获取了设备的数量,为每一个设备分配了一个ncclComm_t后,需要根据已经固定的通信拓扑,对每一个算子进行配置。目前,针对communicator的初始化,我们具有四个函数:
ncclCommInitAllncclCommInitRankncclCommInitRankConfigncclCommInitRankScalable
在初始化communicator的过程中,我们需要完成:
- cuda环境/动态库的加载
- nccl环境的加载(gdr加载,外部动态库的加载)
- 网络自举和探测(bootStrap)
- 构建通信拓扑
ncclCommInitAll
利用一个进程,通过阻塞的方式创建一个通信群,将会为传入的comm指针进行初始化,通过一个进程来实现多个设备的communicator的初始化。因此接下来的讨论聚焦于单进程多设备。但是,即使是单进程,nccl也通过异步线程队列的方式来加速并发执行配置。因此我们仍然绕不开关于并发的讨论。
我们进入ncclCommInitAll中。首先我们将初始化Nvtx(用于profiling)相关参数的payload,并且初始化cudaLibrary(加载动态库,设置相关的设备,获取驱动等工作)。在这里,初始化采用了 std::call_once 操作。这个操作保证了在一台设备上,多个线程只会调用该函数一次。如果发生异常则将调用权转移给其他线程,这样他们就可以继续调用直到成功或者失败退出。
C++:
std::call_once在libc++中的实现
std::call_once通过一个once_flag结构,提供三种状态: 0: 未初始化。 1: 进行中。 2: 调用成功返回。在其中一个线程正在执行时,原子操作flag并且获取锁来保证线程唯一执行。通过
exception_guard,利用RAII特性,在抛出异常析构时调用guard的析构函数,释放锁同时将flag进行更改,将其修改成为“未初始化”模式,保证其他线程能重新获得锁进行执行。通过信号量来减少CPU占用。一个模拟的实现: call_once
在获取设备,进行指针检查和节点设备数量后,如果传入了对应的devList(用于确定节点内设备的rank号),则判断是否合法。否则接下来开始bootstrap网络,获取通信域,也即将开始进入核心部分:bootstrap 网络。
BootStrap network
ncclGetUniqueId
这部分将会为我们创建一个 ncclUniqueId, 用于标识我们的一个通信域。
首先我们执行ncclInitEnv。这一部分主要用于载入对应的插件/网络结构的动态库。例如ext-net中我们可以插入 collNet 用于在网集合通信运算,提升跨节点的一些集合通信速度。ext-profiler用于性能检测,ext-tuner用于性能调优。同样是call_once.
ncclInit
接着我们执行ncclInit。这一部分将执行三个部份,同样是call_once。
- 设置CPU栈的大小。对于nccl,他需要至少8M的安全栈空间。
- 初始化GdrCopy。加载gdr的相关内核模块和驱动。
- 初始化BootStrap网络。
我们来观察初始化bootStrap网络的过程。
-
ncclInit -> bootstrapNetInit -
首先,读取环境变量中的设定
NCCL_COMM_ID=<ipv4>:<port>,我们可以手动通过这个方式来设置通信子的相关信息。这样直接获取了信息后,将socket的相关地址转换成string并且在子网中进行匹配。这种使用的情况不多,因此我们不再赘述。 -
当没有设定上述环境变量的时候,我们就需要自行寻找interfaces了,执行
ncclFindInterfaces来寻找对应的接口信息。
ncclFindInterfaces
根据我们设定的socket来寻找,或者直接寻找所有的网卡。这里我们分别进行介绍。
- 在设置了
NCCL_SOCKET_IFNAME后,首先将会根据设定的网卡名进行前缀匹配。=为完全匹配,^则代表排除该网口。在寻找到网口后,存储他们的ipv4/ipv6信息。 - 否则,在没有设置的情况下,将会优先寻找
ib网口->排除docker, lo, virbr寻找->寻找docker,lo,virbr网口。 findInterfaces函数将会把网卡信息逐个进行填写。
执行完成后我们获得了多个网口的信息(网口名+ip地址),返回bootstrapNetInit。
bootstrapNetInit
在上述函数将网卡写好后,我们将网卡名转换成字符记录在log中,返回。于是初始化bootstrap网络完成。
bootstrapGetUniqueId
接下来我们将真正从我们的bootstrap网络中获取UniqueID。进入bootStrapGetUniqueId.
首先我们已经在bootstrapNetIfAddr中初始化了一系列的网口信息。因此,我们将会用第一个网口作为生成我们的ID的网口。我们可以看到:
- 首先我们利用随机数生成器,通过硬件从环境中获取噪声后生成。通过读取
/dev/urandom获取一个uinteger,填写到state->magic中。 - 随后将
bootstrapNetIfAddr中的第一个网卡地址读取到handle -> addr中。 - 开始执行
bootstrapCreateRoot。
bootstrapCreateRoot
将第一个网卡作为监听网卡,并且创建BootStrapRoot线程,该线程将会在background进行。我们可以看到执行了pthread_detach操作。于是主进程将直接返回继续其他工作,也就是初始化rank 0的comm。笔者的blog不能并发,因此我们会先进入到这其中。
进入bootstrapRoot中,我们准备好如下的相关数据:
- bootstrap相关:参数(刚刚生成的magic,以及确定的监听socket信息)
- bootstrap拓扑相关:nranks(总rank数量),iroot(其他rank的root),nroots(多少个root),localID(iroot下的rankID),n2send(将要传输给的rank)和nrecv(将要接受数据的rank),c(完成信息注册的其他rank的轮数)。
- info(root获取的特定rank的通信信息,包括了他监听root的socket地址和他进行p2p通信的地址)。
- ringConnectInfo(p2p之间进行通信的相关信息)。
- ncclSocketAddress (各个rank用于与root线程通信的地址)。
- 一个全零数据用于判断是否已经进行初始化。
接下来我们开始进行初始化过程。接下来是比较复杂的流程,需要更加耐心地理解。在初始化中,需要完成以下的目标:
- 每个root节点需要了解整体的rank信息和自己的子节点的相关信息。
- 告诉每个子节点ring逻辑拓扑关系,帮助他们建立p2p连接。
首先,我们初始化sock,建立与Root主进程中的listenSocket连接后(其实就是复制fd),开始等待其他rank发来的信息。这里我们发现,在创建sock的时候,async_flag设置成了阻塞模式,因此会在建立连接(过渡过程中等待完成)。这一部分在ncclSocketAccept中执行。
在ncclSocketAccept中,(1)首先将复制listenSocket的相关内容,随后开始尝试进行accept,进入socketProgressState中。在阻塞模式下,我们将等待直到完成。(2)在ncclSocketStateAccepting状态下,socketTryAccept将首先执行,用于在OS层面建立TCP连接。在获得对应的套接字fd后,我们将返回,说明完成了TCP连接。状态转换成ncclSocketStateAccepted。
(3)接着,继续执行socketFinalizeAccept。在这一步我们将会判断当前的socket是否真正地和主进程建立了一个连接。通过读取fd的方式来判断TCP连接是否合法,我们需要检查:1. fd中的magic是否正确,也就是主进程和线程的magic是否相同(判断TCP连接是否正常)。2. 判断socket类型是否相同。判断当前的socket是否为我们需要的ncclSocketTypeBootstrap,而非其他的服务socket。(4)在判断完成后,我们将进入ncclSocketRecv,循环等待其他线程的连接。
这时,我们收到了来自其他线程的连接后,首次获得了获得了其他线程的info信息。这里的info信息包含了:1.线程的rank。2.线程对应的root(iroot)。3. 线程中存储的系统nranks信息(有多少线程)和nroots(有多少root节点),4. 用于监听root信息的socket信息,5.用于p2p交换信息的socket信息。
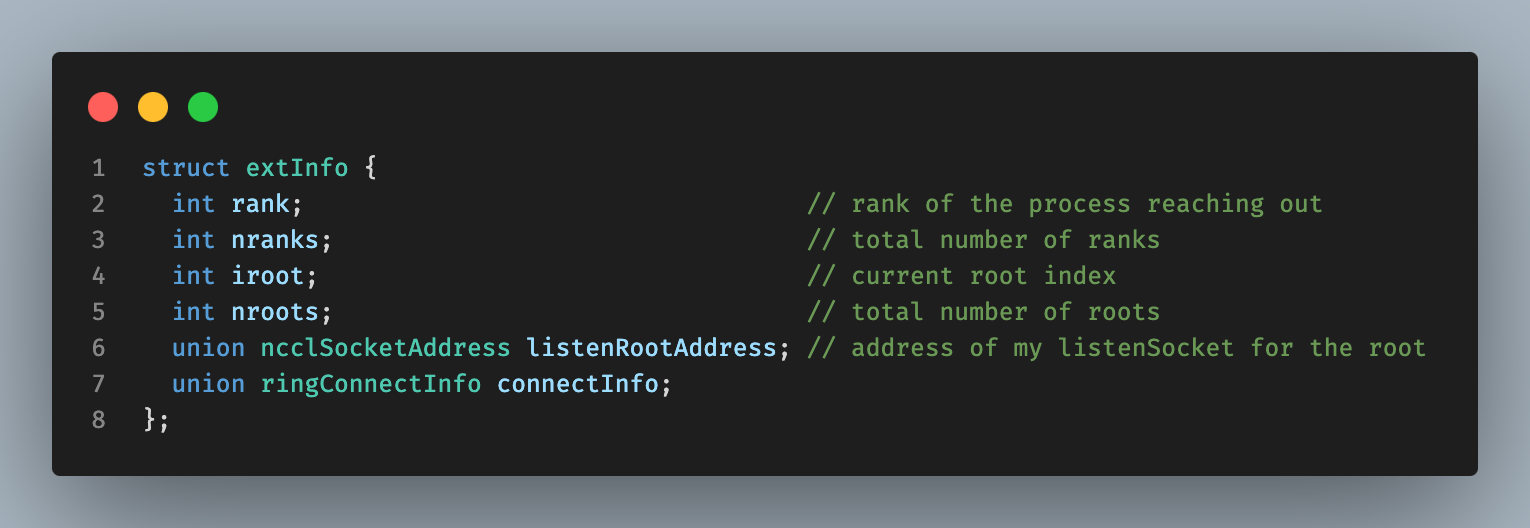
当第一个rank进入的时候,也就是 c==0,我们需要获取系统的整体信息。也就是nranks,nroots,并且和第一个iroot交换信息(当具有多个root的时候)。所有的root都需要了解自己的子节点信息和系统整体的信息,并且分配rankAddressesRoot用于存储自己管理的子节点信息,分配rankInfo来用于存储自己管理的子节点用于p2p的信息。
计算出对应的节点在其root节点下的rank号后,我们需要判断他是否已经完成过注册。这时前面全零数据就起到了作用。
接下来完善ring通信逻辑,需要判断当前新加入节点在ring逻辑拓扑中的前序节点和后序节点是否有没有加入过。
在前序节点已经加入的情况下:bootStrapRoot线程将直接通过rankAddressesRoot发送当前新加入节点的info给前序节点,供前序节点建立p2p通信。
在后序节点已经加入的情况下:bootStrapRoot线程将会直接通过info中记录的新加入节点监听root的socket,发送自己已经记录的后序节点的rankInfo给新加入的节点,从而帮助当前这两个节点构建p2p连接。
这样最后一个节点始终是最后的,没有收到任何信息的节点。因此将rank 0的信息发送给这个节点。
为了方便理解,我们构建了一个简单的图示。
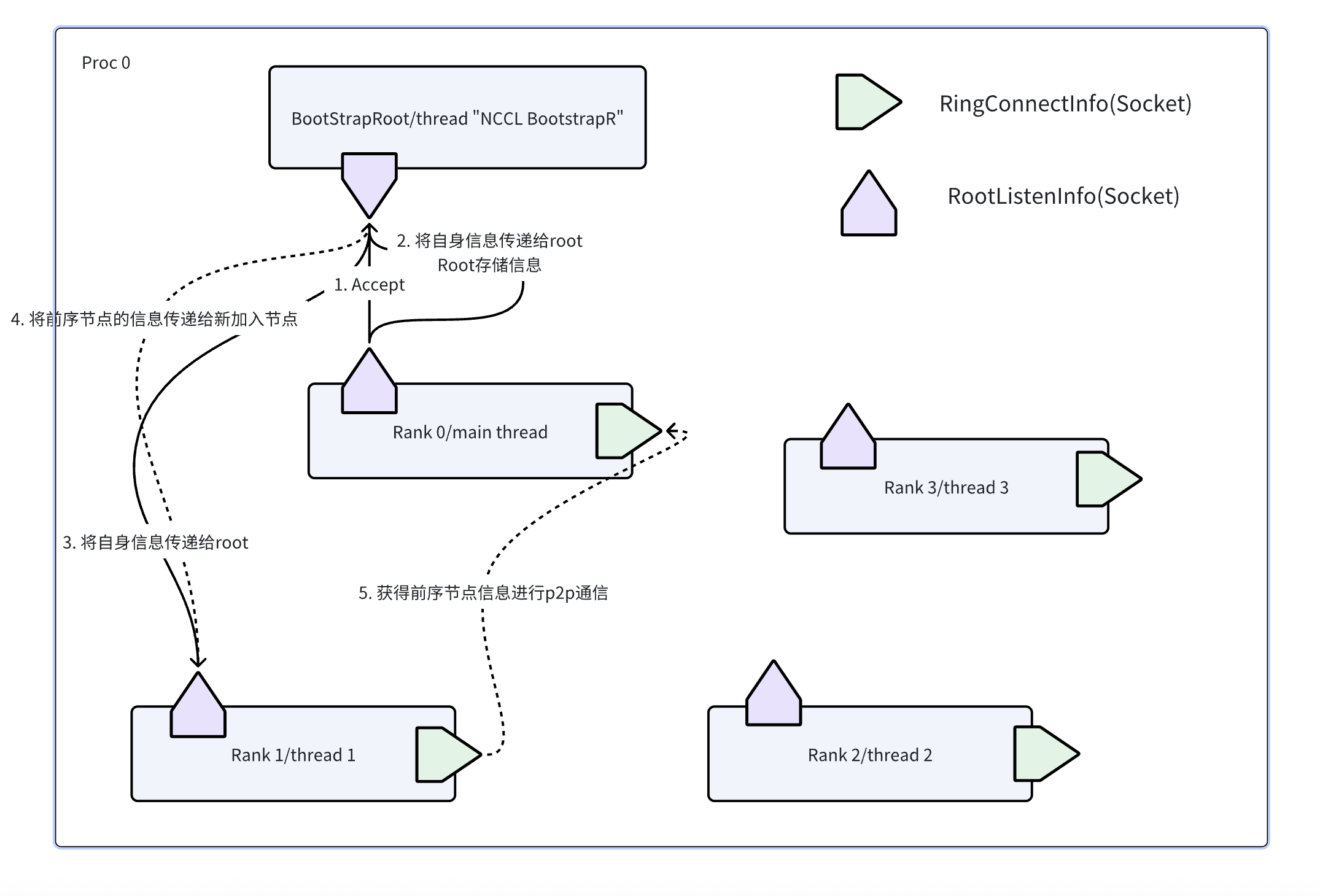
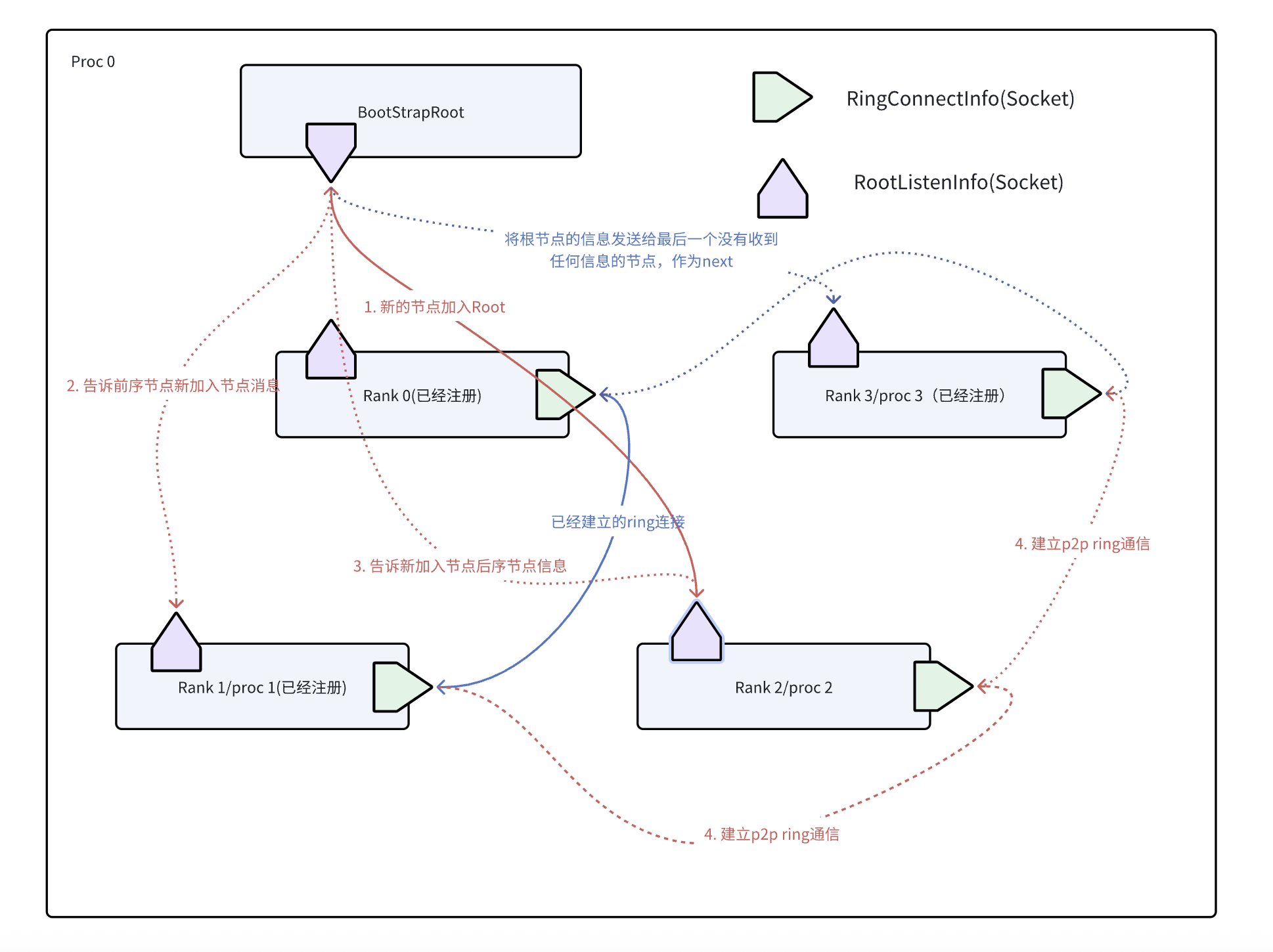
在进行bootstrap的过程中,通过ncclCommInitRancFunc函数中的bootstrapInit来构建p2p ring网络和与bootStrapRoot线程通信。此处之后的信息后面我们将会介绍。
ncclCommInitRankDev
在获取uniqueId的过程中,我们在bootStrapRoot中会创建一个线程在幕后执行BootStrapRoot,因此上述的GetUniqueId工作和现在的对每一个rank进行配置的工作是并发执行的。我们接着来看这部分是如何执行的。
在这里,我们可以看到所有的一些循环配置操作都被ncclGroupStartInternal和ncclGroupEndInternal包裹起来。这里涉及到了nccl的group操作和异步任务的同步。我们暂且按下不表,后面再来解释。
在进行cudaSetDevice之后,配置好GPU,我们就正式进入配置。对于每一个GPU,我们需要进行配置。我们调用ncclCommInitRankDev,正式踏上配置rank的道路。
ncclCommInitRankDev
同样地先进行ncclInit。由于这是一个call_once,因此很快将会返回。通过cudaFree判断cuda是否已经加载。然后为comm分配空间。comm->startMagic和comm->endMagic用于判断comm是否出现问题。然后通过parseCommConfig来读取相关配置。这里我们在ncclCommInitRankConfig中再提。在这里是默认的config。
接下来为ncclAsyncJob分配空间。这是即将提交给异步队列执行的任务。我们前面已经说明,nccl的一些操作通过异步方式完成。这里我们配置了 nID(代表通信域的数量,也就是uniqueId的数量,最多每个rank一个uniqueId),nranks具有多少rank设备,myrank当前任务的rank号,cudaDev所对应的实际设备,分配job->ncclUniqueId空间后将先前bootStrap获得的ID传递给job。随后,通过ncclAsyncLaunch的方式,将任务提交给工作队列,等待异步执行ncclCommInitRankFunc.
ncclCommInitRankFunc
首先仍然是初始化一系列的参数和cuda设备,并且设置cuda核的架构,最大共享内存和局部内存。随后,我们的ncclCommInitRankDev没有设置job->parent,因此我们直接从uniqueId的char buffer中获取我们的Hash作为comm的hash值,开始分配comm空间,初始化comm,进入commAlloc。
ncclCommInitRankFunc -> commAlloc
首先我们为communicator中的memPermanent, memScoped分配栈内存空间。
这里对于comm,nccl通过使用ncclMemoryStack的方式,可以通过LIFO的方式来管理内存(多个对象),这样通过帧的push和pop来管理内存(分配和释放)。一个帧内可能具有大量的object,因此这样的方式就可以快速地实现deallocation,减少开销。
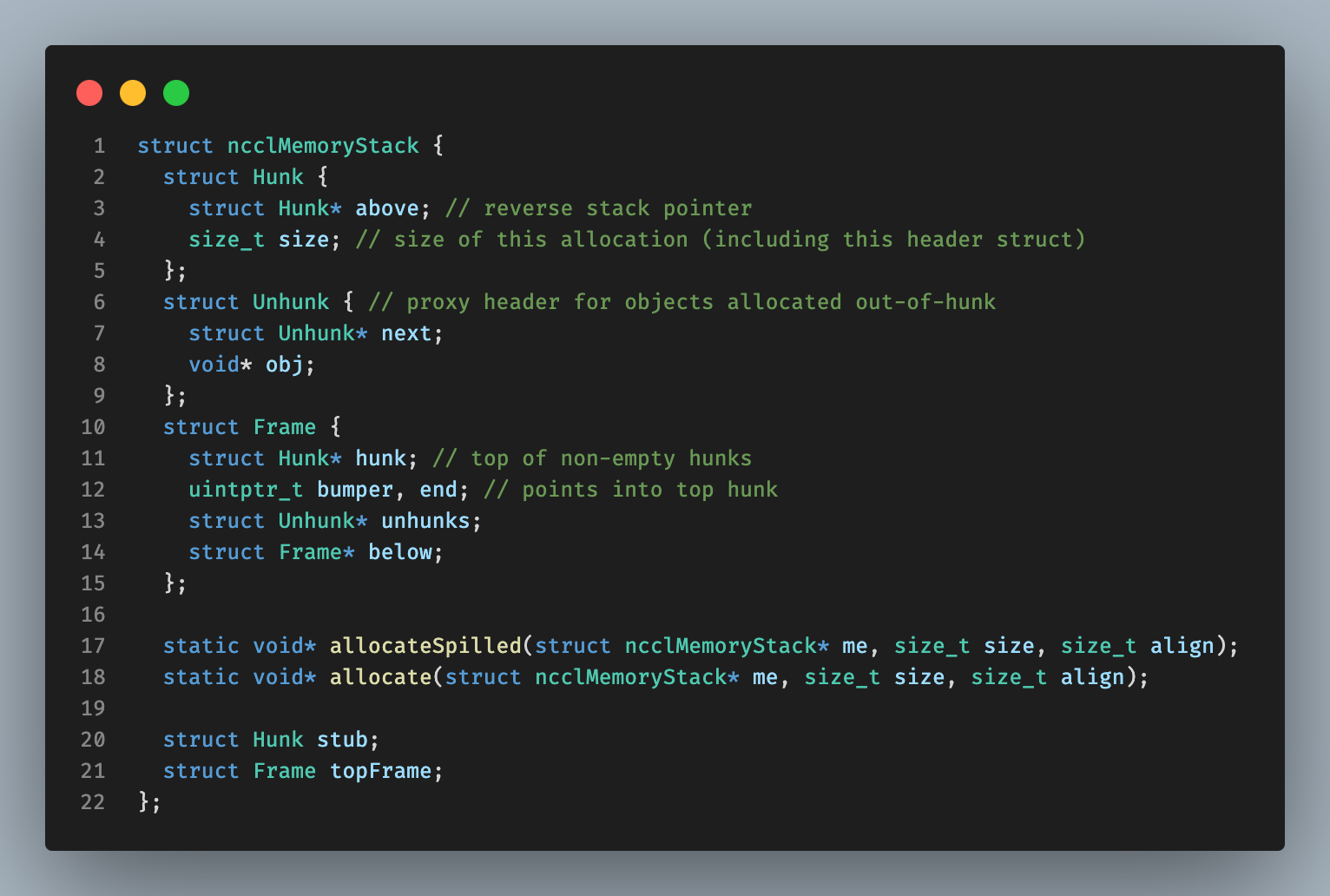
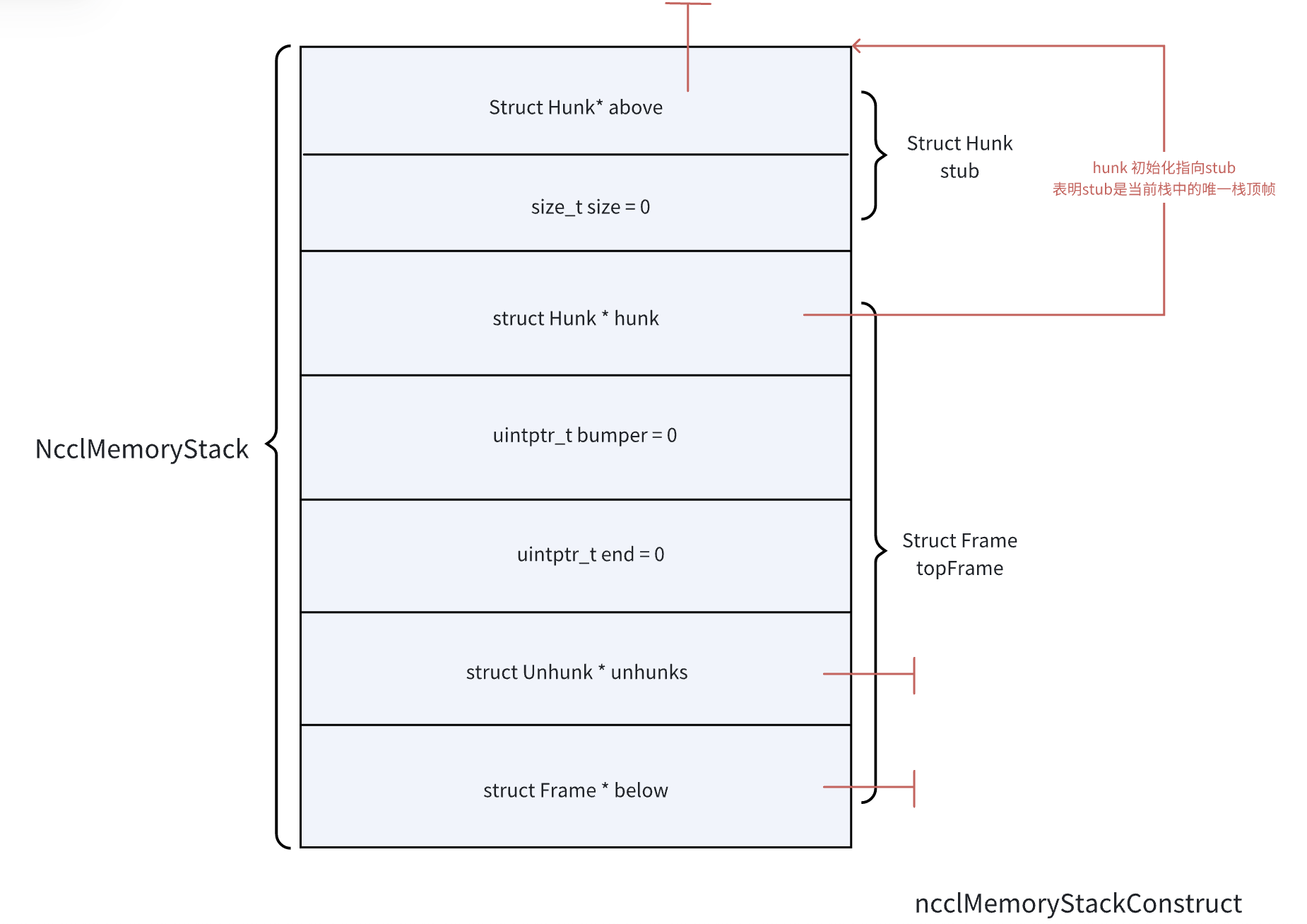
ncclMemoryStack
memoryStack中主要有:(1) Hunk: 栈指针。用来在压栈时记录上一个栈顶和当前的栈帧大小。(可以看作帧指针)(2) UnHunk: 栈帧外分配管理的对象指针,采用单链表的方式管理。(3) 帧:包括了栈指针(非空帧的帧顶),bumper(当前hunk的可存储起始地址),end(当前栈帧的结尾),以及unhunks(栈外的内存空间)。Below用于指向其他的,下一个栈。
Construct: 初始化ncclMemoryStack。这里将会设置栈大小为0,top为空nullptr。
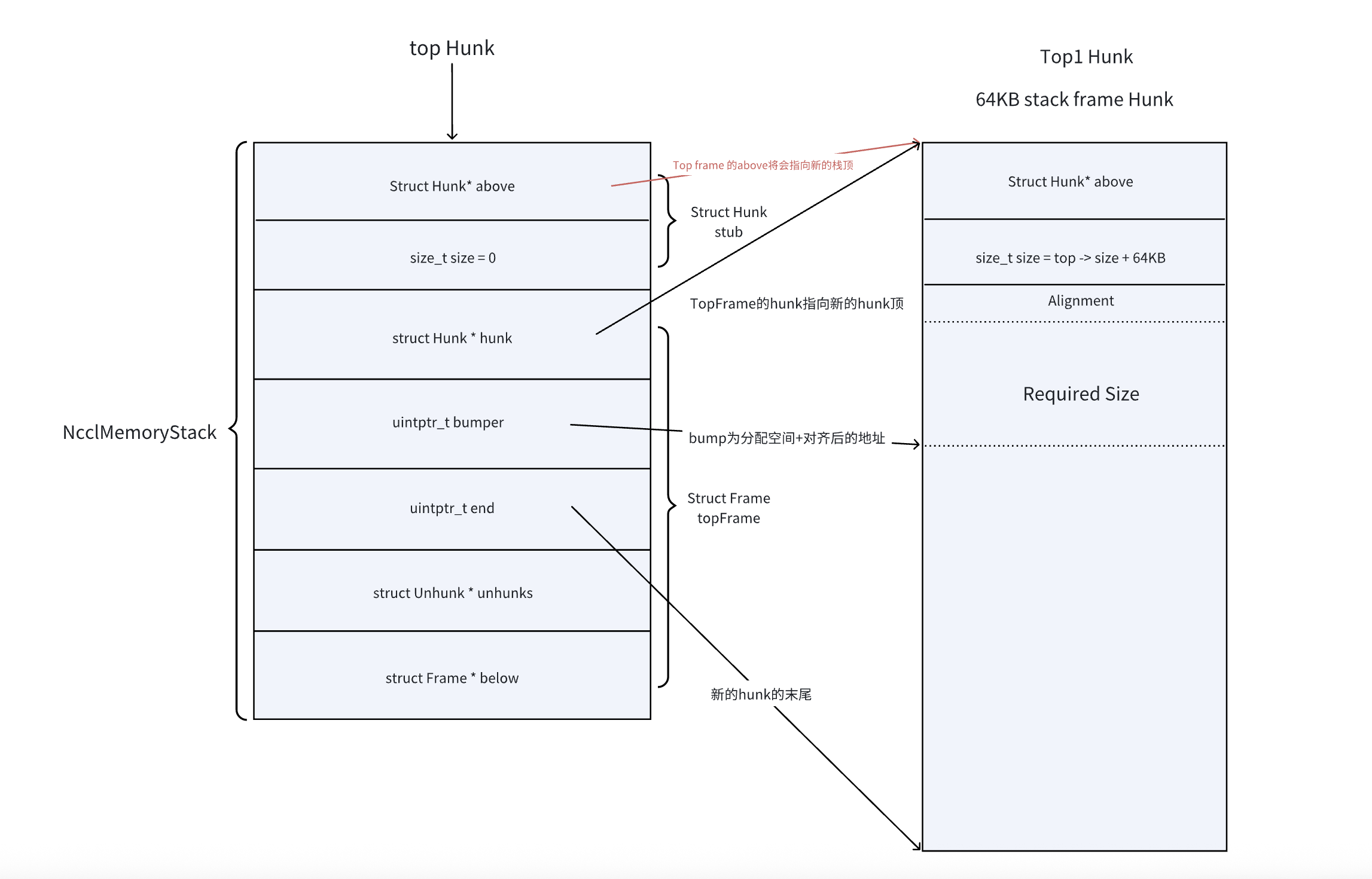
Allocate: 分配一个帧空间。在函数中,这里采用了两种优化:
(1)内存对齐
我们有:padding = -offset & (align - 1)
aligned = (offset + (align - 1)) & -align。
(2)分支预测优化
__builtin_expect将会让cpu执行过程中优先执行该分支,从而减少流水线阻塞。
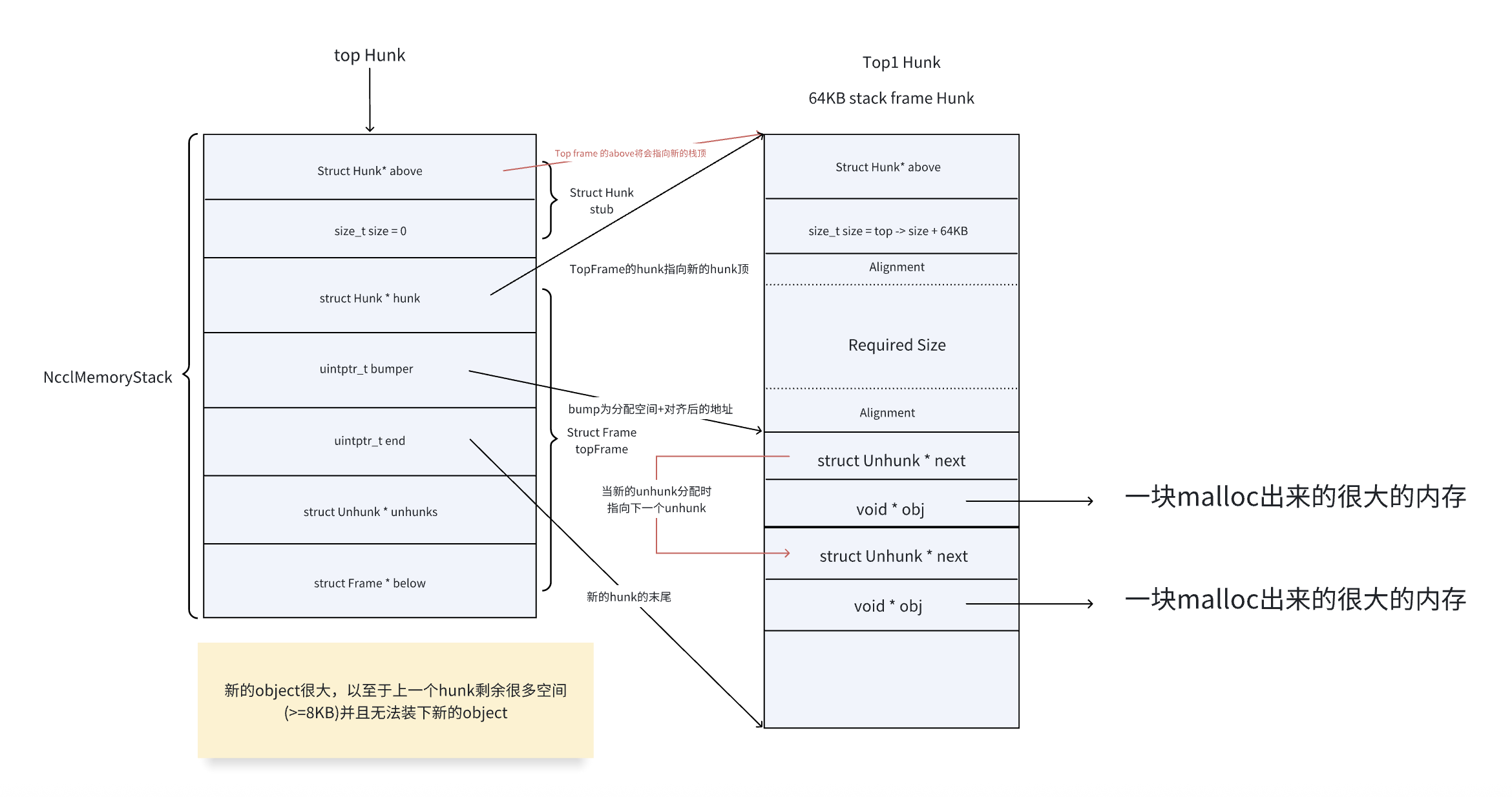
在当前栈帧空间不足时,我们需要分配新的栈帧提供给外部。这里我们将会采用allocateSpilled来进行分配。allocateSpilled: 首先如果栈帧仍然拥有超过8KB的空间,但是分配需要的空间太大,则跳转到unhunked分配(也就是栈帧外分配)。
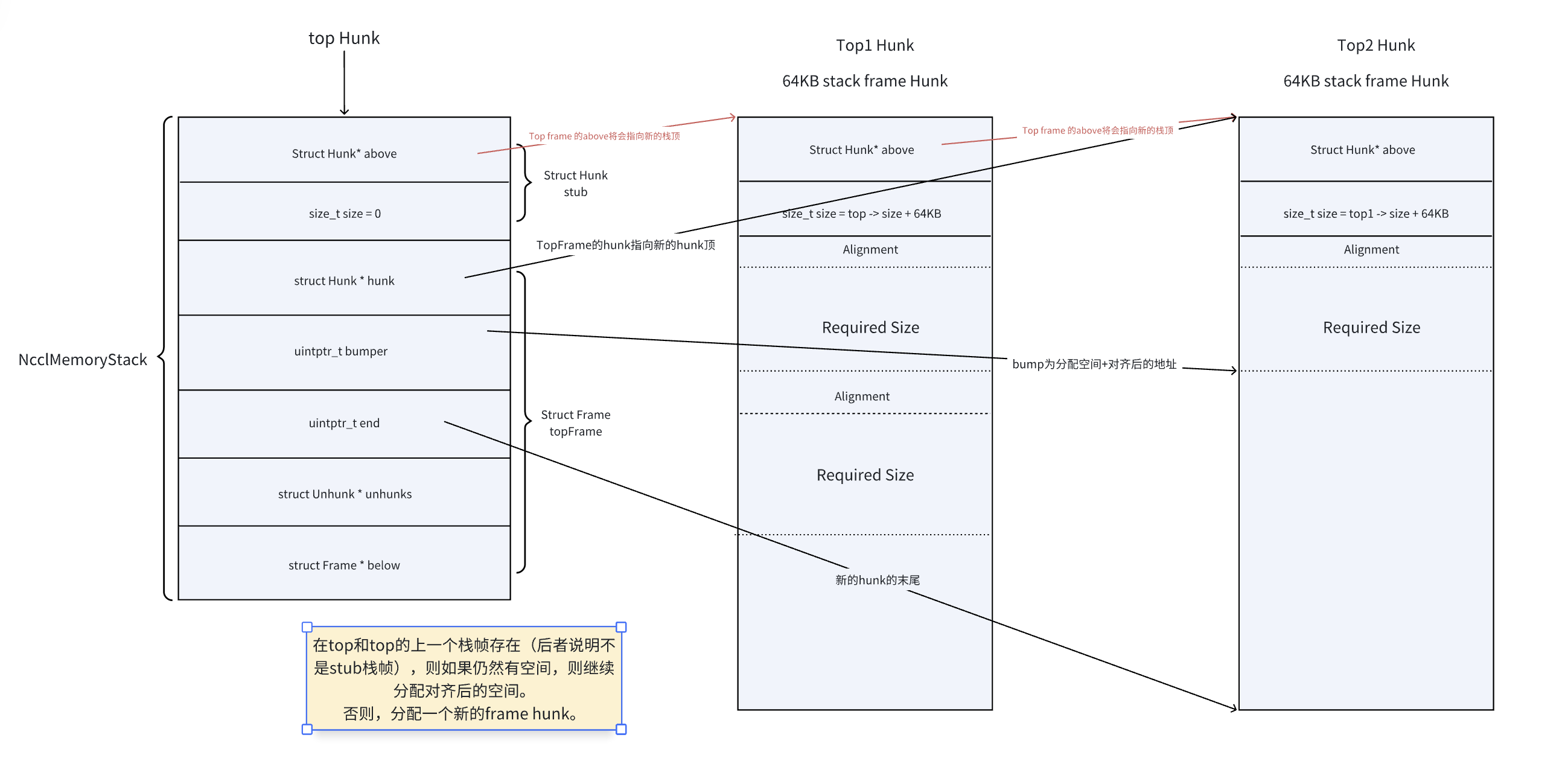
接着,判断我们是否有其他的hunk空间。如果有,我们则优先使用他们并且修改我们的栈顶可用指针(bumper和end)。
每个栈帧最多分配64KB的空间,因此超出64KB需要跳转到unhunked分配。
接着我们正式分配hunk空间,栈帧空间分配后,将top指针指向新分配的hunk块,修改可用区间。bumper指向这个hunk可用部分(排除掉hunk大小16byte的空间)后的开始地址,end指向这个hunk的末尾地址。
最后,通过align返回可以使用的起始地址,然后修改stack的bumper(分配空间预留给了obj)。unchunked: 对于栈帧外内存:通过unchunk的方式,利用传统的malloc和free分配堆上内存管理对象。同样,将unhunk的元数据存储在栈帧中,因此bumper也需要移动。
这样我们就大致了解了整个
ncclMemoryStack的过程。
ncclMemoryPool
这个就非常简单了,通过单链表的方式,将每一个ncclMemoryStack转换成Cell来进行管理。这里我们就不再赘述了。
回到正题。在给comm分配了memPermanent和memScoped这两个memoryStack后,对于通过split得到的comm(也就是parent != NULL),我们将直接共享父节点的相关资源并增加引用计数。否则,我们需要为我们的算子的共享资源进行分配。我们的算子中,sharedRes主要有以下的几部份:(1) 引用计数。继承类型的通信子需要多次重用资源。(2)channel相关信息:包括了设备peer和线程peer。(3)操作计数。包括了p2p和集合通信。(4) 张量并行相关。包括了张量并行中的相关信息:参与的rank数,本地的rank数,channel数,参与p2p的通道数量和块大小,将parentRank转换成localRank的转换表。(5) magic,用于检测资源是否损坏。(6) 内部的stream和event。用于跟踪设备/主机的stream,以及Event用于计量stream执行时间。(7) proxy相关服务。(8) GIN:GPU Initiated Networking. 这是NCCL的新的特性,可以参考论文. (8) 记录创建自己的comm。
TBD...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号