

Conga:分布式拥塞感知与负载均衡数据中心(Sigcomm'14)
Conga: Distributed Congestion-Aware Load Balancing for Datacenters
分布式拥塞感知与负载均衡数据中心(Sigcomm'14)
目录
关键词
分布式,全局拥塞感知,小流,快速响应,网络层部署。
摘要
-
提出了CONGA的设计,部署和评估。
-
conga是一个基于网络的,分布式的,拥塞可感知的,负载均衡的针对数据中心的一个机制。
- 利用了当时
最先进的常规clos拓扑结构和上层网络虚拟化(overlay network virtualization)。 - 将TCP流分成小流(flowlet),估计在fabric path上的真实时间开销。
- 允许基于远程交换机的反馈来将小流分配到链路上。
- 利用了当时
-
这样,conga就能够有效地做到平衡负载并且无缝处理不对称性,无需任何TCP更改。
-
conga已经部署在自定义的ASIC上,作为新的数据中心通路。
-
在测试中,实现了即使在有一条链路故障的情况下仍然比ECMP快5倍的流完成时间(FCT),并且在incast(多对一, 参考)场景下实现了比MPTCP还要高2-8倍的吞吐率。
-
并且,CONGA架构的开销在Leaf-Spine拓扑中的开销很小,因此CONGA几乎和中心化的调度器一样有效,并且可以在微秒级别对拥塞做出反应。
-
我们的主要理论是数据中心fabric负载均衡最有效的实现应在网络中,并且需要全局架构例如CONGA来处理不对称性。
P.S. 对分带宽:用一截面将网络划分为对等的两半时(或者两个节点数目都相同的子网时),穿过该截面的最大传输率。对分带宽越大,网络通信能力越强。(bisectional bandwidth)。
引入
背景
- 数据中心必须提供具有高对分带宽的服务来支撑大量的大数据类型应用。
- 并且他们必须提供便捷性,以便于应用可以在任意的服务器上部署,用于实现操作有效性,降低开销。
- 先前的工作(VL2,Portland)展示了如何在clos上达到这一效果,ECMP(均等开销多路)负载均衡,以及将终端地址与他们的位置相互解耦。这些设计的原理都遵循了下一代上层网络技术,例如VXLAN和NVGRE采用标准封装来实现高对分带宽和便捷性。
先前工作的不足
ECMP:Equal Cost MultiPath
- ECMP可能会在负载均衡上表现很差。
- ECMP随机地通过哈希将流分配到通路,当有一些大流时,哈希碰撞将会导致严重的负载不均。
- 并且更重要的是,ECMP仅仅考虑了局部决策,将流量沿着均等通路进行分割,而没有考虑到潜在的通路下游的拥塞影响。
- 因此ECMP在链路故障后导致的不对称情况下表现出来的均衡性很差(链路故障导致的不对称性又是经常发生的)。会导致在链路故障时即使有内建冗余的情况下送达流量下降40%。
解决ECMP问题的其他尝试
- 主要可以分为以下三类解决方案。但这些方案都各自存在不足。
- 中心化调度(Hedera)。中心化方案相较于于数据中心中流量的变化性反应过慢,并且局部拥塞感知机制是次优的并且在不对称场景下表现甚至差于ECMP。
- 局部路由机制(Flare)。
- 基于主机的传输层协议(MPTCP)。这样的协议难以部署因为网络操作一般不控制终端栈。并且高性能应用(低延迟系统)将会绕开内核并且自行部署协议栈。再者,基于主机的负载均衡为本就复杂的传输层增加了复杂度,并且数据中心内仍然需要低延时和爆发冗余。在实验中也表现了MPTCP的脆弱性。
需要解决的问题
- 网络均衡能够在不增加传输层复杂度的情况下完成吗?
- 这样的基于网络的方法是否能够计算全局最优分配,并且可以在可以实现的,分布式的场景下部署,实现在微秒级别的快速反应?
- 这样的机制能否在采用标准封装格式的上层网络中部署?
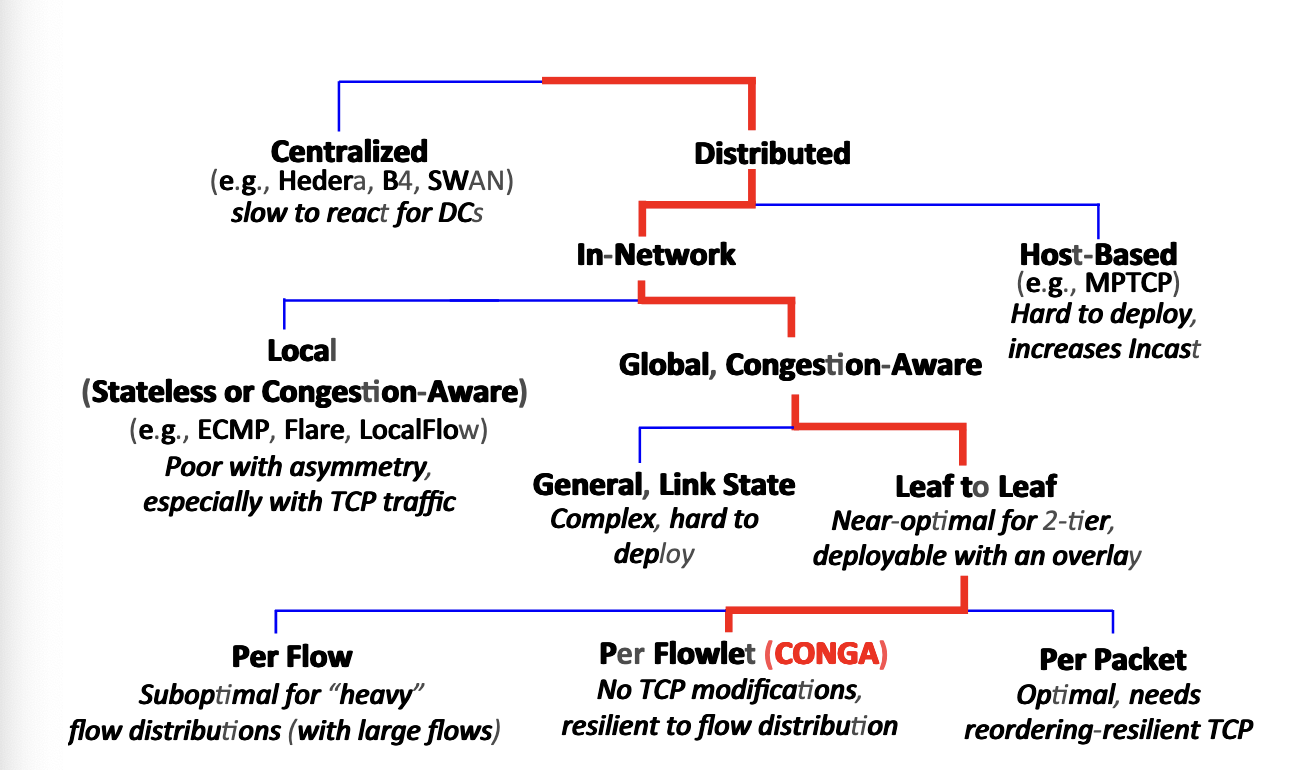
Conga设计
- 分布式框架,允许快速的在RRT时间尺度的对拥塞的反应来解决突发数据中心流量。
- 获取全局拥塞信息。
- 在网络层中,避免了在端侧主机的部署,也没有引入传输层的复杂性。
如何感知拥塞
- 常见的设计方式是感知所有链路的拥塞情况,并且发送整体的链路状态包来计算拥塞敏感的路由。然而,这是一个N-方协议,具有复杂的控制循环。脆弱并且难以部署,并且也具有不稳定性。
- Conga采用双方叶-叶机制(2 party leaf-leaf)来在每对叶节点交换机(ToR)中逐个传递每条通路的拥塞指标。在普通的2-层clos(Leaf-Spine)架构中被证明接近最优。并且容易部署,也可以应用于标准封装上层网络,用于网络的工作负载灵活性。
分离TCP流成为小流
- Conga被设计成在小流上工作,来实现更细粒度的控制和对流大小分布的容忍。而没有其他的针对TCP的修改。
贡献总结
- 分布式,拥塞感知,易部署,对链路故障造成的不对称性鲁棒,微秒级拥塞反应,无终端修改。
- 拓展硬件上测试,包级别仿真。
- 证明在2层Leaf-Spine拓扑上接近最优。证明了负载均衡行为与小流有效性取决于流大小分布的相关系数。
设计决策
五个关键的性质
设计过程中conga需要遵守以下的五个关键性质:
- 高效性。数据中心中的数据非常多变且突发并且交换机的缓存很浅。需要在RRT尺度下做出反应。
- 传输层独立。最为网络层机制需要对传输层独立。
- 不对称性稳定。面临链路故障的时候需要更加稳健。
- 可增量部署。conga需要可以在一部分流量与一部分交换机上能够部署。
- 对Leaf-Spine拓扑能够优化。
五个设计的动机
为什么分布式负载均衡
- 目前分布式负载感知方法较少。
- 数据中心的流量突发并且难以预测。需要在很短的时间内进行响应。
- 数据中心采用非常规则的网络拓扑结构。对于常见的Leaf-Spine架构,所有的道路仅有两条。并且实验和分析均证明了分布式方案在规则拓扑下是接近最优的。
- 当然,针对WAN这种流量是稳定、可预测并且网络拓扑任意的场景,可以使用集中式方法。
为什么在网络层部署负载均衡(方案)
主要从Sota的MPTCP入手解释为什么在网络层而不在传输层入手。
- 在MPTCP对负载均衡有效的情况下,对许多小流的使用实际上增加了在互联网端侧的拥塞,并且在incast(多打一)场景下表现下降。
- 尽管在搭配拥塞控制算法上,用于处理共享瓶颈,这样的情况仍会出现,因为原算法仅仅在流量稳定的场景下成立,对于实际的数据中心负载,许多流生命周期短且为瞬态爆发流。
- 更大的架构问题:数据中心的通路负载均很在传输栈上太过于详细无法部署。这些通路是高度工程化,异构的系统。在端点处相当于一个巨大的交换机。并且会需要平衡其他高性能需求,也要求应用不绕开应用栈。因此不能在传输层部署。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号