


背景
因为某种需要,需要将在tuleap上的用例导出给外部人员。但是tuleap导出用例时存在以下几种问题:
1、有些用例因为使用的是html文本编辑框输出,所以导出时会带有标签<p></p>等之类的问题,不美观
2、用例模块都是一般都用【】写在标题上,想着将【】的内容直接单独放入某一列中,但是还有一个问题是,之前研发将研发名字和周几开发用【】括起来
3、目前用例已经有几千条,人工修改用例和维护成本大
为了解决上述问题,考虑写个python解决。
tuleap导出的用例格式如下:
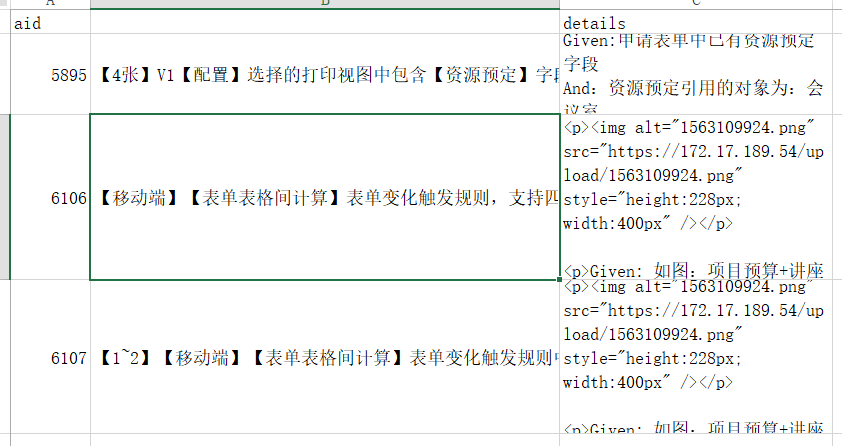
解决方案
导出的用例是xlsx格式,需要读取excel并且写入Excel,所以使用了openpyxl模块
下载模块:
pip intall openpyxl
读取excle数据和写入excle数据封装:
from openpyxl import load_workbook,Workbook
class Xlsx(ReadParam):
def __init__(self, filepath):
self.path = filepath
self.data = load_workbook(self.path)
self.w_data = Workbook()
def read_sheet_row(self, sheetname, start_row):
'''
:param start_row: 开始的行数
:return:
'''
sheet = self.data[sheetname]
# sheet = self.data.active
#两个写法都可以获取excle页签的内容
max_row = sheet.max_row
min_row = sheet.min_row
max_column = sheet.max_column
data_list = []
for row in sheet.iter_rows(min_row=start_row+1, min_col=1, max_row=max_row, max_col=max_column):
# 循环读取页签的每一行
temlist=[]
# 循环读取每行的每个单元格的内容,并追加到temlist
for cell in row:
temlist.append(cell.value)
# 将每行的内容添加到data_list中
data_list.append(temlist)
return data_list
def save(self,file_name):
# 写入数据后需要保存
self.w_data.save(file_name)
def w_data_to_excle(self, data):
ws = self.w_data.active
# 因为上面获取元素的方法返回的是[[a,b],[a1,b1]]的格式,所以需要循环读取每一行的数据再写入
if isinstance(data, list):
for i in data:
ws.append(i)
else:
ws.append(data)
清除标签并且把读取【】的内容作为模块
from open_file.open_xls import Xlsx
import re
filename = 'D:/jiaoben/test_util/data/测试用例带html标签.xlsx'
sheetname = 'tuleap测试用例'
xlsx = Xlsx(filename)
data = xlsx.read_sheet_row(sheetname, 1)
split_list = ['<p>', '</p>', ' ', '<img.*/>']
data = xlsx.read_sheet_row(sheetname, 1)
#替换image <img.*/>
def split_data():
for i, k in enumerate(data):
for j in split_list:
# 循环替换第二列标题中的html标签
b = re.sub(j, '', k[2])
k[2] = b
data[i] = k
return data
# 将【】内容作为单独的列,并去除名字、周几等标记
clear_list = ['张','[1-9]','周']
def search_model(search_list):
search_new = []
for i, k in enumerate(search_list):
# 正则中的?表示非贪婪模式,所以可以找到相邻的【】内容
a = re.findall('【.*?】', k[1])
# 以下会带有姓名
# for a1 in a:
# k.append(a1)
for a1 in a:
list_c = []
for c in clear_list:
# 将【】的内容循环判断是否包含clear_list的内容,如果包含在list_中追加1
list_c.append(1) if re.findall(c, a1) else list_c.append(0)
# 只有【】中全部不包含clear_list的内容时,才会更新到search_new
0 if 1 in list_c else k.append(a1)
search_new.append(k)
return search_new
new_data = split_data()
new_data1 = search_model(new_data)
# 将包含模块的数据写入到表格中,并保存
xlsx.w_data_to_excle(new_data1)
xlsx.save('D:/jiaoben/test_util/data/new4.xlsx')
最终的excel显示如下:

涉及知识点
1、openpyxl读取数据、将表格写入数据
读取数据使用:load_workbook(),确认读取哪一个sheet页的数据,再使用iter_rows循环读取表格中的行,在循环读取行中的单元格的值
写入数据使用Workbook(),传入的数据可以是list类型,list里面的元素代表一行,且传入单元格的格式需要是str类型。所以当多行多列的数据需要循环读取 [[a,b],[a1,b1]]
最后调用save方法保存写入的数据,这样是创建一个新建的excle,如果是已存在的元素会报错
2、正则表达式
查找匹配的元素:可以使用 re.findall(正则表达式,要查找的原始数据),返回的是所有匹配条件的数据,是一个list
替换元素:re.sub(需要替换的正则表达式,新的内容,要查找的原始数据)
*表示匹配前面的子表达式零次或多次
.表示匹配除换行符 \n 之外的任何单字符
?表示匹配前面的子表达式为0次或者1次,或者指明一个非限定的贪婪字符
【a】c【b】d
假设要查找两端【】是这样的字符,那么
【.*】匹配到的是【a】c【b】
【.*?】匹配到的是【a】,【b】
正则表达式测试工具:https://c.runoob.com/front-end/854/
3、三元运算符
4、列表推导式,上述例子用用到了很多list,后期可以考虑尝试使用列表推导式处理
5、文件路径,使用的是绝对路径,可以尝试优化成相对路径
----记:本次初衷在于加强python代码动手能力,还有许多可优化的点,期望日后可以一一优化~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号