python——关于简单爬取博客园班级成员发的博文的题目、发布人、阅读、评论,再存到csv文件中
因为老师要以班里每个人发的博客质量作为最后总成绩的评定的一部分,就要把班上所有同学发的博客都统计起来,可以用来评定的因素有:阅读、评论、推荐等,但因为今天只是做一个简单的爬取,推荐这个元素在班级博客中需要点开每一篇博文才能看到获取,就不爬取了,只爬取阅读和推荐,加上每篇博文的发布人和标题。
我先会放上代码,再逐条解释其含义及作用。
代码如下(其中爬取的网页是以我自己的班级为例):
1 from bs4 import BeautifulSoup 2 import pandas as pd 3 import requests 4 import csv,time 5 6 def get_url(n): 7 urls=[] 8 for i in range(1,n+1): 9 urls.append("https://edu.cnblogs.com/campus/hbsfxy/DayDayUp?page=%s" %i) 10 return urls 11 12 def parse_HTML(url): 13 req = requests.get(url) 14 req.encoding = req.apparent_encoding 15 soup = BeautifulSoup(req.text, 'lxml') 16 data=[] 17 li_list = soup.find_all('li',class_="am-g am-list-item-desced am-list-item-thumbed am-list-item-thumb-bottom-right") 18 for li in li_list: 19 if len(li.find("div",class_="am-text-sm").get_text())>0: 20 print("ok") 21 dic={} 22 dic["博客提目"]=li.find("a",target="_blank").get_text() 23 dic["发布人"]=li.find("a",title="发布人").get_text().replace(" ","").replace("\n","") 24 dic["评论"]=li.find("span",title="评论").get_text().replace("\ue606","").replace(" ","") 25 dic["阅读"]=li.find("span",title="阅读").get_text().replace("\ue641","").replace(" ","") 26 data.append(dic) 27 time.sleep(1) 28 return data 29 30 def get_alldata(n): 31 alldata=[] 32 for url in get_url(n): 33 alldata.extend(parse_HTML(url)) 34 return alldata 35 36 37 if __name__ == "__main__": 38 39 dp=pd.DataFrame(get_alldata(11)) 40 dp.to_csv("博客data.csv",encoding='utf_8_sig')
开头是将要用到的库文件导入。
from bs4 import BeautifulSoup import pandas as pd import requests import csv,time
这段代码是定义了一个函数,将要遍历的网址储存在一个列表里,因为班级博客不止一页,有很多页,每一页都有一个网址,但这些网址都是有规律的,可以鼠标右击页面,点击检查,再右边出来的审查元素框上方,点击这个![]() ,然后放到网面页数那
,然后放到网面页数那![]() ,在审查元素框内就会出现相应的每页网址的对应代码,如下图:
,在审查元素框内就会出现相应的每页网址的对应代码,如下图:
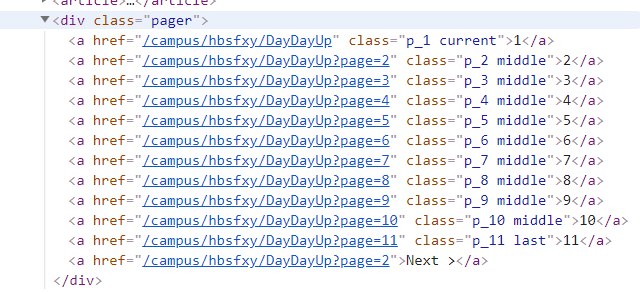 从网页中可以看出每页的网址只有后面的page=的数不一样
从网页中可以看出每页的网址只有后面的page=的数不一样
def get_url(n): urls=[] for i in range(1,n+1): urls.append("https://edu.cnblogs.com/campus/hbsfxy/DayDayUp?page=%s" %i) return urls
这句最后page=%s 的意思是每次循环用i的值来替换%s的位置,因为range(1,n)的意思是从1到n-1,所以我们要遍历到所有页就要n+1,这样就可以将所有要爬取的页面地址存到我们定义的urls列表里,然后返回urls列表。
urls.append("https://edu.cnblogs.com/campus/hbsfxy/DayDayUp?page=%s" %i)
这段代码是定义了一个函数用于将从传入的网址爬取的数据存在列表字典里。首先是请求网址;将网址返回的响应内容的字符编码设置成和网页一样的,以免乱码;然后创建一个beautifulsoup对象soup并初始化,然后从网页源代码中可以看出所有我们要爬取的内容都包含在class属性为"am-g am-list-item-desced am-list-item-thumbed am-list-item-thumb-bottom-right"的一对对<li> 标签里,我们先找出所有这样标签。
def parse_HTML(url): req = requests.get(url) req.encoding = req.apparent_encoding soup = BeautifulSoup(req.text, 'lxml') data=[] li_list = soup.find_all('li',class_="am-g am-list-item-desced am-list-item-thumbed am-list-item-thumb-bottom-right") for li in li_list: if len(li.find("div",class_="am-text-sm").get_text())>0: print("ok") dic={} dic["博客提目"]=li.find("a",target="_blank").get_text() dic["发布人"]=li.find("a",title="发布人").get_text().replace(" ","").replace("\n","") dic["评论"]=li.find("span",title="评论").get_text().replace("\ue606","").replace(" ","") dic["阅读"]=li.find("span",title="阅读").get_text().replace("\ue641","").replace(" ","") data.append(dic) time.sleep(1) return data
下面的截图是我截取要爬取我们信息的页面的截图,下面有三对class属性相同<li>标签,但第一个是没有我们要爬取的内容的,当我们遍历所有我们筛选出来的标签时爬到第一个<li>标签时,没有我们要爬取的<a>、<span>标签的内容就会报错,所以我们必须加以控制,我这里加了一个if循环,如果<div>标签爬出来不为空才能继续下面的爬取操作。从图中可以看出在名字、评论、阅读那有许多空格和其他符号,我用了replace()函数来筛选文字。最后sleep函数用来调整我们访问服务器的时间,以防访问过于频繁被封。

这段代码定义了一个函数,并分别调用了前两个函数,for循环用于将之前存的网页列表一个一个拿出来访问,然后将每个页面访问信息存在一个总的列表里。
def get_alldata(n): alldata=[] for url in get_url(n): alldata.extend(parse_HTML(url)) return alldata
这个就是main函数了,调用get_alldata()函数,并将最后列表用DataFrame函数变为二维表,pd是之前在导入pandas库时定义的。最后再将二维表存入csv表就行了!
if __name__ == "__main__": dp=pd.DataFrame(get_alldata(11)) dp.to_csv("博客data.csv",encoding='utf_8_sig')
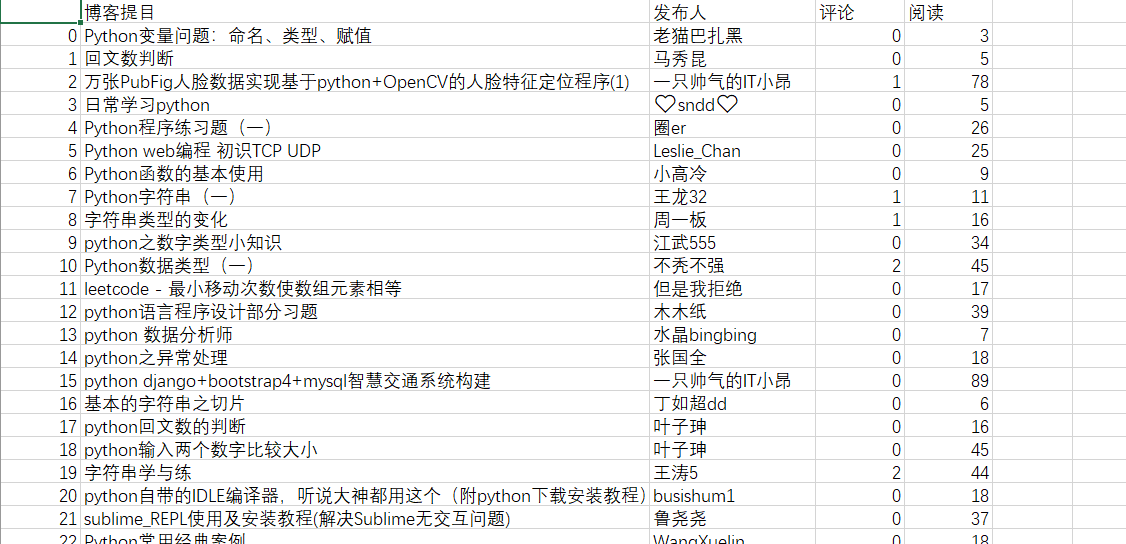
打开csv文件,这就是最后大概爬出来的样子了~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号