
面试题总集
OSPF
1.OSPF是什么
开放最短路径优先,一种链路状态路由协议,使用SPF算法寻址
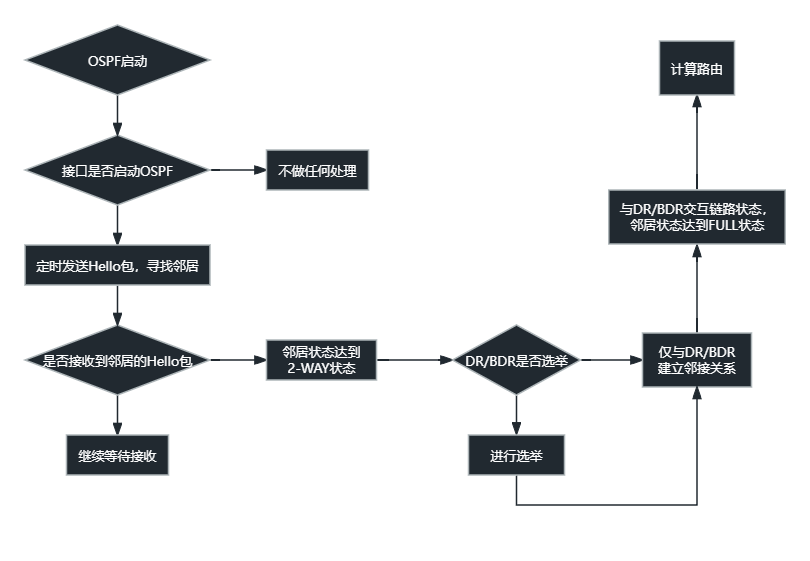
2.工作过程
先建立邻居,然后同步链路状态数据库,再计算最优路由路径
3.如何更改OSPF域中的Route ID
#clear IP OSPF process authority
4.关键属性
- Equal Cost Routes管理: CEF Load对应
- 协议类型:链路状态
- 传输:IP(89)
- 度量:const(带宽)
- 标准:RFC2328(OSPFv2)、RFC2740(OSPFv3/IPv6)
5.邻居关系变为邻接关系 - LSR数据包、链路状态、LSU数据包
- 双向通告
- 数据库同步,描述数据包的切换、链接
- 数据库同步完成,两个Router被测量为相邻
6.哪四种路由器类型 - 自治系统边界路由器,将外部路由通告到OSPF域的路由器
- 内部路由器,所有接口都属于同一区域的路由器
- 区域边界路由器,在多个区域中具有接口的路由器
- 骨干路由器,在区域0的路由器内部的路由器
7.特点是什么 - OSPF使用成本作为其度量,它是根据链路的带宽计算的
- OSPF是一个支持VLSM和CIDR的无类路由过程
- OSPF路由的距离为110
- 没有跳数限制
- 允许创建区域和独立系统
8.解释不同OSPF的功能和工作原理,并且什么类型用于OSPF中的协议间通信 - 使用LSA(Link-State Advertisements)通告直接相关链路状态
- 其中一个链接发生更改时,OSPF会通知更新,并且只会通过更新发送差异,LSA每30分钟额外刷新一次
- 使用SPF算法决定最短路径
- Type 3 LSA 用于区域间通信,其他协议和外部路由的通信使用Type4和5
9.是否可以让一侧编号而另一侧未编号 - 不能,不起作用,会导致数据库不一致,从而阻止将路由安装在引导表中
10.DR和BDR解决了什么 - 过渡LSA泛洪
- 邻接数高
11.邻接是什么意思 - 邻接指的是到邻居的理论上的链路,可以通过链路发送链路状态通告
12.链路状态重传间隔是什么 - OSPF必须发送对每个新的常规LSA的识别,LSA被重新传输,直到它们被批准,链路状态重传间隔定义重传之间的时间
- IP OSPF retransmit-interval
13.说出五种OSPF数据包类型 - DBD、HELLO、LSU、LSR、LSack
14.子网关键字有什么用 - 没有子网关键字,则只会重新分配未直接连接到路由器的主网络地址
15.有几种LSA - External LSA、Network LSA、ASBR Summary LSA、Network Summary LSA、Router LSA
16.将优先级设为“0”的Route会发生什么 - 不参与DR/BDR的选举
17.没有骨干区域能使用OSPF吗 - 可以,但只有区域内通信,没有骨干区域就无法实现区域之间的通信
18.多播地址 - 224.0.0.5和224.0.0.6
19.Route ID是什么 - 用于识别路由器的标识符,是一个32位数字
20.OSPF定时器 - Dead Interval:定义了扩展路由器在宣布邻居死亡之前将如何等待hello数据包
- Hello Interval:定义了OSPF路由器向其他OSPF路由器发送hello数据包的频率
Bash
find
找出/test.dir目录下的文件名中包含test关键字的文件并将其全部删除
方法一:使用 find 命令和通配符配合删除文件
find /test.dir -type f -name '*test*' -exec rm {} +
解释:
find /test.dir:在/test.dir目录下进行查找。-type f:只查找普通文件。-name '*test*':查找文件名中包含关键字 "test"。-exec rm {} +:删除找到的文件。
方法二:使用 grep 命令和 xargs 命令配合删除文件
ls /test.dir | grep 'test' | xargs -I {} rm /test.dir/{}
解释:
ls /test.dir:列出/test.dir目录下的所有文件。grep 'test':筛选包含关键字 "test" 的文件名。xargs -I {} rm /test.dir/{}:通过管道将文件名传递给 xargs 命令,并使用{}表示文件名,执行rm删除文件。
请注意,在使用以上方法删除文件之前,一定要确保你理解并验证了要删除的文件,并且确保没有重要文件会被误删除。
查找/etc目录下以tions结尾的目录或者文件然后把其详细信息保存到/tmp/下的test.txt文件下
find /etc -type d -name '*tions' -o -type f -name '*tions' -exec ls -l {} \; > /tmp/test.txt
解释:
find /etc:在/etc目录下进行查找。-type d:查找目录。-name '*tions':查找名字以 "tions" 结尾的目录。-o:表示“或”的逻辑操作符。-type f:查找文件。-exec ls -l {} \;:对于找到的目录或文件,使用ls -l命令显示详细信息。> /tmp/test.txt:将详细信息输出到/tmp/test.txt文件中。
请注意,在运行该命令之前,请确保你有足够的权限来访问/etc目录和创建/写入/tmp/test.txt文件。
查找/etc/下大于5M的文件或目录并显示其详细信息
你可以使用 find 命令来查找 /etc 目录下大于 5M 的文件或目录,并显示其详细信息。以下是示例命令:
find /etc -size +5M -exec ls -lh {} \;
解释:
find /etc:在/etc目录下进行查找。-size +5M:查找大于 5M 的文件或目录。-exec ls -lh {} \;:对于找到的文件或目录,使用ls -lh命令显示详细信息。
请注意,查找和显示/etc目录下大于 5M 的文件或目录可能需要较长的时间,具体取决于目录层次结构的大小和系统性能。也可以根据自己的需要调整文件大小的表示方式,如使用G表示 GB 或K表示 KB。
查找并删除/etc目录下小于1M大小的文件或目录
find /etc -size -1M -delete
查找/var目录下属主为root,且属组为mail的所有文件或目录
find /var -user root -group mail
find /var -user root -group mail -ls
find /var -maxdepth 1 -user root -group mail
查找/usr目录下不属于root、bin、.或hadoop的所有文件和目录
find /usr -type d ! -user root ! -user bin ! -user . ! -user hadoop -o -type f ! -user root ! -user bin ! -user . ! -user hadoop
find来遍历/usr目录下的文件和目录。-type d表示查找目录,-type f表示查找文件。
! -user root ! -user bin ! -user . ! -user hadoop表示排除属主为root、bin、.或hadoop的文件和目录。
-o表示或运算,将目录和文件的查找结果合并在一起。
这将显示不属于root、bin、.或hadoop的所有文件和目录。
find /usr -type d ! -user root ! -user bin ! -user . ! -user hadoop -o -type f ! -user root ! -user bin ! -user . ! -user hadoop -ls
find /usr -maxdepth 1 -type d ! -user root ! -user bin ! -user . ! -user hadoop -o -type f ! -user root ! -user bin ! -user . ! -user hadoop
查找/etc目录中一周以来内容被修改过,并且属主不为root和hadoop的所有文件和目录
find /etc -type d -not -user root -not -user hadoop -or -type f -not -user root -not -user hadoop -mtime -7
find来遍历/etc目录下的文件和目录。-type d表示查找目录,-type f表示查找文件。
-not -user root -not -user hadoop表示排除属主为root和hadoop的文件和目录。
-mtime -7表示查找一周以来内容被修改过的文件和目录。这里的"7"表示7天,也可以根据需要进行调整。
这将显示满足这些条件的所有文件和目录。
find /etc -type d -not -user root -not -user hadoop -or -type f -not -user root -not -user hadoop -mtime -7 -ls
查找当前系统中没有属主和属组,并且最近一个周被访问过的文件和目录
find / -nouser -nogroup -atime -7
find来遍历整个系统中的文件和目录。-nouser表示查找没有属主的文件和目录,-nogroup表示查找没有属组的文件和目录。
-atime -7表示查找最近一个周内被访问过的文件和目录。这里的"7"表示7天,也可以根据需要进行调整。
查找/etc/目录下大于1M且类型为普通文件(regular file)的文件或目录
find /etc -type f -size +1M
find来遍历/etc/目录下的文件和目录。-type f表示仅查找普通文件,-size +1M表示查找大小大于1M的文件。
这将显示满足这些条件的所有文件和目录。
find /etc -maxdepth 1 -type f -size +1M
查找/etc目录下所有用户都没有写权限的文件
find /etc -type f -not -perm /u=w
find来遍历/etc目录下的文件。-type f表示查找普通文件,-not -perm /u=w表示排除用户拥有写权限的文件。
查找/etc/init.d目录下所有用户都有执行权限,且其它用户有写权限的文件
find /etc/init.d -type f -perm /u=x,g=w,o=w
find来遍历/etc/init.d目录下的文件。-type f表示查找普通文件,-perm /u=x,g=w,o=w表示查找用户有执行权限且其它用户有写权限的文件。
查看/etc/目录下修改时间是三天前的文件或目录
find /etc -mtime +3
find来遍历/etc/目录下的文件和目录。-mtime +3表示查找修改时间是三天前的文件和目录。这里的"3"表示三天,也可以根据需要进行调整。
find /etc -mtime +3 -ls
sed
只显示处理过的行
sed -n -f script.sed input.txt
在这里,-n选项告诉sed只打印被脚本处理的行。-f script.sed指定使用名为script.sed的脚本文件。input.txt是要处理的输入文件。
在script.sed中,你可以使用不同的sed命令来对行进行处理。在行的处理结束之前,使用p命令来打印它。
每一行打印出行内容
#!/bin/sed -nf
p
支持扩展的正则表达式
sed -n -r -f script.sed input.txt
在这里,-r选项告诉sed使用扩展的正则表达式语法。-f script.sed指定使用名为script.sed的脚本文件。input.txt是要处理的输入文件。
此外,如果你使用的是macOS上的BSD版sed,则-r选项不可用,你需要使用-E选项代替。例如:
sed -n -E -f script.sed input.txt
更改文件内容
sed -i -f script.sed input.txt
在这里,-i选项告诉sed直接修改input.txt文件。-f script.sed指定使用名为script.sed的脚本文件。
请注意,这种原位修改文件的方式是不可逆的,请在使用之前备份你的文件。如果你想保留原始文件,并将修改后的内容输出到另一个文件中,可以使用重定向操作符>。
sed -f script.sed input.txt > output.txt
显示文件中的特定行
要显示第二行,可以使用以下命令:
sed -n '2p' file.txt
要显示第二行和第三行,可以使用以下命令:
sed -n '2,3p' file.txt
要显示最后一行,可以使用以下命令:
sed -n '$p' file.txt
在这些命令中,-n选项用于关闭默认输出,以便只输出所需行。2p表示打印第二行,2,3p表示打印第二行和第三行,$p表示打印最后一行。file.txt是要处理的文件。
请注意,这些命令仅显示特定行,并不会修改文件本身。如果你想将结果保存到新文件中而不是直接显示在终端上,可以使用重定向操作符>将输出重定向到新文件中。
sed -n '2p' file.txt > output.txt
sed -n '2,3p' file.txt > output.txt
sed -n '$p' file.txt > output.txt
找出 /etc/passwd 文件中以"test"关键字开头的行
sed -n '/^test/p' /etc/passwd
在这里,/^test/p是正则表达式,并且它匹配以"test"开头的行。使用-n选项关闭sed的默认输出,然后使用p命令打印匹配的行。/etc/passwd是要处理的文件。
请注意,^是正则表达式中的元字符,用于匹配行的开始位置。这样,只会匹配以"test"开头的行。如果你想寻找包含"test"的任意位置,而不仅限于行首,可以省略^。
找出 /etc/passwd 文件中以"/bin/bash"结尾的行
sed -n '/\/bin\/bash$/p' /etc/passwd
在 sed 脚本中,/\/bin\/bash$/p是一个正则表达式,用于匹配以 "/bin/bash" 结尾的行。使用 -n 选项关闭 sed 的默认输出,然后使用 p 命令打印匹配的行。/etc/passwd 是待处理的文件。
请注意,正斜杠/是正则表达式中的特殊字符,需要用反斜杠\进行转义。因此,\/bin\/bash$ 匹配一行结尾是 "/bin/bash" 的行。
找出 /etc/passwd 文件中以"root"或"test"开头的行
sed -n '/^root\|^test/p' /etc/passwd
在sed脚本中,/^root\|^test/p是一个正则表达式,用于匹配以"root"或"test"开头的行。使用-n选项关闭sed的默认输出,然后使用p命令打印匹配的行。/etc/passwd是待处理的文件。
请注意,^是正则表达式中的开始位置元字符,用于匹配行的开头。由于管道符|是特殊字符,需要用反斜杠\进行转义。因此,/^root\|^test/匹配以"root"或"test"开头的行。
找出从以"root"开头的行开始到以"nologin"结尾的行之间的行
sed -n '/^root/,/nologin/p' /etc/passwd
在这里,/^root/,/nologin/p表示匹配以"root"开头的行和以"nologin"结尾的行之间的所有行。使用-n选项关闭sed的默认输出,然后使用p命令打印匹配的行。/etc/passwd是要处理的文件。
运行命令后,sed将会输出从以"root"开头的行到以"nologin"结尾的行之间的所有行。
请注意,^和/是正则表达式中的特殊字符,在使用sed命令时需要进行转义。
在文本的第3行下面添加两行内容
sed '3a\
Line1\
Line2' file.txt
在开头是root的行下面添加两行内容test,test
sed '/^root/a\
test\
test' file.txt
把第一行整体替换成test,这是替换的一整行
sed '1s/.*/test/' file.txt
在/etc/passwd文件里面匹配到以root开头的行,然后这一行的下一行添加/tmp/text.txt里面的内容
sed '/^root/{n;r /tmp/text.txt' -e '}' /etc/passwd
/^root/{n;r /tmp/text.txt表示匹配以"root"开头的行,然后n命令读取并跳过该行,r /tmp/text.txt命令在匹配的行的下一行插入/tmp/text.txt文件的内容。-e是一个选项,用于指定紧跟其后的命令,是sed的编辑命令。
把text.txt文件里面包括my的行放置到text2.txt里面,注意这里面的顺序
sed -n '/my/p' text.txt > text2.txt
/my/p表示匹配包含"my"的行
将前10行当中的所有小写的s转换成大写的S
sed '1,10s/s/S/g' file.txt
1,10s/s/S/g表示替换文件的第1行到第10行中的所有小写字母"s"为大写字母"S"。
将全文所有小写的s转换成大写的S
sed 's/s/S/g' file.txt
s/s/S/g表示替换文件中所有的小写字母"s"为大写字母"S"。
删除第一行
sed '1d' file.txt
1d表示删除文件的第一行。
删除1、2、3行
sed '1,3d' file.txt
1,3d表示删除文件的第1行到第3行。
删除开头的root的行一直到结尾是nologin的行
sed '/^root/,/nologin/d' file.txt
/^root/,/nologin/d表示删除匹配以"root"开头的行和以"nologin"结尾的行之间的所有行。
删除开头是#号的行
sed '/^#/d' file.txt
/^#/d表示删除匹配以"#"开头的行。
删除空白行
sed '/^\s*$/d' file.txt
/^\s*$/d表示删除空白行,包括只包含空格、制表符或空白字符的行。
^表示行的开始\s*表示匹配零个或多个空白字符(例如,空格、制表符等)$表示行的结束
删除带空格的假空行
sed '/^[[:space:]]*$/d' file.txt
/^[[:space:]]*$/d表示删除带有空格的空行,包括只包含空格、制表符或空白字符的行。
将一个文本中所有的大写字母替换为小写字母
sed 'y/ABCDEFGHIJKLMNOPQRSTUVWXYZ/abcdefghijklmnopqrstuvwxyz/' file.txt
y/ABCDEFGHIJKLMNOPQRSTUVWXYZ/abcdefghijklmnopqrstuvwxyz/ 使用 sed 命令中的 y 命令将大写字母转换为小写字母。
将一个文件中所有的小写 root 替换为大写 ROOT
sed 's/root/ROOT/g' file.txt
s/root/ROOT/g 使用 sed 命令中的 s 命令将文件中的所有小写 root 替换为大写 ROOT。
整行替换,将第二行无论什么内容都替换为 888
sed '2c\888' file.txt
2c\888 使用 sed 命令中的 c 命令替换文件的第二行为 888。
仅替换第三列的某些内容
sed 's/\(\([^[:blank:]]\+[[:blank:]]\+\)\{2\}\)\(old_value\)/\1new_value/' file.txt
使用 sed 命令中的 s 命令和正则表达式来选择第三列的内容。将 old_value 替换为 new_value。
s/是 sed 命令的替换操作符。\(和\)是用来定义一个捕获组,它可以保存匹配的内容供后续引用。[^[:blank:]]匹配任意非空白字符(空格、制表符等)。+表示匹配一个或多个前面的字符。[[:blank:]]匹配一个空白字符。\{2\}表示前面的模式匹配出现两次。\1引用第一个捕获组,即匹配前两列的内容。old_value是要替换的旧值。new_value是替换后的新值。
利用 sed 命令删除 history 开头的空白字符
sed 's/^[[:blank:]]*history/history/' file.txt
使用 sed 命令中的 s 命令和正则表达式来选择以空白字符开头的 history 并将其替换为 history。这将删除 history 开头的所有空白字符。
删除 /etc/grub.conf 文件中行首的空白字符
sed 's/^[[:blank:]]*//' /etc/grub.conf
s/^[[:blank:]]*// 表达式,将行首的任何空白字符替换为空,从而删除了行首的空白字符。
替换 /etc/inittab 文件中 id:3:initdefault: 行中的数字为 5
sed 's/\(id:3:initdefault:\)[0-9]/\15/' /etc/inittab
s/\(id:3:initdefault:\)[0-9]/\15/ 表达式,捕获了 id:3:initdefault: 这个文本,并在替换时引用了它(\1),将后面的数字替换为 5。
删除 /etc/inittab 文件中的空白行
sed '/^[[:blank:]]*$/d' /etc/inittab
/^[[:blank:]]*$/d 表达式,匹配空白行并将其删除(d)。
删除 /etc/inittab 文件中以 # 开头的行
sed '/^#/d' /etc/inittab
/^#/d 表达式,匹配以 # 开头的行并将其删除(d)。
删除某文件中开头的 # 及后面的空白字符的行,但要求 # 号后面必须有空白字符
sed '/^#[[:blank:]]*$/d' file.txt
/^#[[:blank:]]*$/d 表达式,匹配以 # 开头,并且后面跟零个或多个空白字符的行,并将其删除(d)。
删除某文件中以空白字符后面跟 # 号的行中开头的空白字符及 #
sed 's/^[[:blank:]]*\(#\)//' file.txt
s/^[[:blank:]]*\(#\)// 表达式,匹配以零个或多个空白字符开头,并且后面跟 # 号的行,并将开头的空白字符及 # 替换为空。
取出一个文件路径的目录名称
echo "/path/to/directory/file.txt" | sed 's|\(.*/\).*|\1|'
这个命令将输出 /path/to/directory/,使用 s|\(.*/\).*|\1| 表达式,捕获了从开头到最后一个斜杠之间的内容,并使用后向引用 (\1) 将其输出。
取出一个目录的基名和目录名
dirname="/path/to/directory"
echo "$dirname" | sed 's|\(.*\)/\(.*\)|Directory: \1\nBase Name: \2|'
这个命令的含义是,通过 sed 命令的替换操作 (s),使用正则表达式匹配目录路径中的内容并进行捕获,然后将其替换为格式化的输出。
\(.*\)/\(.*\):使用括号\( \)来捕获内容。第一个.*表示匹配任意字符(除换行符外)零次或多次,表示目录路径部分(即目录名和基名之前的部分),/表示斜杠分隔,第二个.*表示匹配任意字符(除换行符外)零次或多次,表示基名部分。
因此,该命令将输出以下内容:
Directory: /path/to
Base Name: directory
使用 dirname 命令可以获取目录的路径,然后使用 basename 命令获取目录的基名。
把 /etc/fstab 文件中的空行和开头是空格的、开头是 # 号的行都删除掉
sed '/^[[:blank:]]*$/d' /etc/fstab | sed '/^[[:blank:]]\|#/d'
两个 sed 命令,首先 /^[[:blank:]]*$/d 会删除空行,然后 /^[[:blank:]]\|#/d 会删除开头是空格或 # 号的行。
常见问题
一、网络基础
1. OSI七层模型
- 各层协议与设备:
- 物理层(中继器、集线器)
- 数据链路层(交换机)→ ARP、VLAN
- 网络层(路由器)→ IP、ICMP
- 传输层→ TCP、UDP
- 会话层→ NetBIOS
- 表示层→ SSL/TLS
- 应用层→ HTTP、DNS
- PDU数据单元:比特(物理层)、帧(数据链路层)、包(网络层)、段(传输层)、报文(应用层)。
2. TCP/UDP区别
- TCP:可靠、面向连接、流量控制(三次握手/四次挥手)。
- UDP:不可靠、无连接、低延迟(适用于视频/直播)。
3. TCP/IP四层模型
- 网络接口层(链路层)→ MAC地址
- 网络层→ IP协议
- 传输层→ TCP/UDP
- 应用层→ HTTP/FTP/DNS
4. 其他网络问题
- CDN原理:就近缓存静态资源,降低延迟(DNS解析导向边缘节点)。
- ping协议:ICMP(网络层)。
- 阿里云CDN配置:控制台配置域名、CNAME解析、缓存策略。
二、Linux系统
1. 常用命令与故障处理
- 磁盘空间满但显示未满:可能为小文件占满inode →
df -i。 - 僵尸进程:
ps aux | grep Z→ 杀死父进程。 - 实时网卡流量:
nload或iftop;历史流量:sar -n DEV。 - 文件内容分页查看:
less 文件名。 - CPU/核数查看:
lscpu或cat /proc/cpuinfo。
2. Shell脚本与变量
- 变量类型:环境变量、位置变量(
$1,$2)、预定义变量($?,$$)。 - 位置变量:脚本参数(如
$0为脚本名)。
3. 服务与日志管理
- 保留最近7天日志:
find /app/logs -name "*.log" -mtime +7 -exec rm -f {} \;
- 定时备份:
0 0 * * * tar -zcvf /data/backup_$(date +\%Y\%m\%d).tar.gz /var/www/html
三、Web服务与代理
1. Nginx反向代理
- 流程:接收请求 → 匹配location规则 → 转发到后端 → 返回响应。
- 仅用IP反向代理:可配置
proxy_pass http://IP:端口。
2. Apache工作模式
- prefork(多进程)、worker(多线程)、event(异步)。
3. 并发连接统计
- netstat/ss命令:
netstat -ant | grep :80 | wc -l# 统计TCP连接数
ss -s | grep "Total:" # 显示总连接数
四、数据库与监控
1. MySQL主从同步
- 原理:主库binlog → 从库IO线程拉取 → SQL线程重放。
- 延迟解决:优化SQL、并行复制、半同步复制。
2. Zabbix监控
- 监控项:CPU/内存/磁盘、MySQL(慢查询、连接数)、Redis(内存使用、命中率)。
3. RDS内网访问
- ECS内网直连 → 安全组放行3306端口。
五、容器与云原生
1. Docker网络模式
- bridge(默认)、host、overlay、none。
2. LVS/Nginx/HAProxy区别
- LVS:四层负载(IP层)、高并发。
- Nginx:七层负载(HTTP)、灵活配置。
- HAProxy:四层/七层、支持TCP/HTTP。
六、安全与故障排查
1. 服务器攻击处理
- 步骤:断网 → 排查日志(
lastlog,/var/log/secure) → 杀进程 → 修复漏洞 → 备份重装。
2. 网站打开慢排查
- 链路分析:客户端 → CDN → 服务器 → 数据库(慢查询、索引优化)。
3. Linux系统调优
- 内核参数:
sysctl.conf优化(TCP连接复用、文件句柄数)。
七、自动化与运维管理
1. 300台服务器管理
- 工具:Ansible/SaltStack(批量操作)、Prometheus(监控)、ELK(日志)。
2. 灰度发布
- 定义:逐步向部分用户发布新版本,验证稳定性。
OSPF
1.OSPF是什么
开放最短路径优先,一种链路状态路由协议,使用SPF算法寻址
2.工作过程
先建立邻居,然后同步链路状态数据库,再计算最优路由路径
3.如何更改OSPF域中的Route ID
#clear IP OSPF process authority
4.关键属性
- Equal Cost Routes管理: CEF Load对应
- 协议类型:链路状态
- 传输:IP(89)
- 度量:const(带宽)
- 标准:RFC2328(OSPFv2)、RFC2740(OSPFv3/IPv6)
5.邻居关系变为邻接关系 - LSR数据包、链路状态、LSU数据包
- 双向通告
- 数据库同步,描述数据包的切换、链接
- 数据库同步完成,两个Router被测量为相邻
6.哪四种路由器类型 - 自治系统边界路由器,将外部路由通告到OSPF域的路由器
- 内部路由器,所有接口都属于同一区域的路由器
- 区域边界路由器,在多个区域中具有接口的路由器
- 骨干路由器,在区域0的路由器内部的路由器
7.特点是什么 - OSPF使用成本作为其度量,它是根据链路的带宽计算的
- OSPF是一个支持VLSM和CIDR的无类路由过程
- OSPF路由的距离为110
- 没有跳数限制
- 允许创建区域和独立系统
8.解释不同OSPF的功能和工作原理,并且什么类型用于OSPF中的协议间通信 - 使用LSA(Link-State Advertisements)通告直接相关链路状态
- 其中一个链接发生更改时,OSPF会通知更新,并且只会通过更新发送差异,LSA每30分钟额外刷新一次
- 使用SPF算法决定最短路径
- Type 3 LSA 用于区域间通信,其他协议和外部路由的通信使用Type4和5
9.是否可以让一侧编号而另一侧未编号 - 不能,不起作用,会导致数据库不一致,从而阻止将路由安装在引导表中
10.DR和BDR解决了什么 - 过渡LSA泛洪
- 邻接数高
11.邻接是什么意思 - 邻接指的是到邻居的理论上的链路,可以通过链路发送链路状态通告
12.链路状态重传间隔是什么 - OSPF必须发送对每个新的常规LSA的识别,LSA被重新传输,直到它们被批准,链路状态重传间隔定义重传之间的时间
- IP OSPF retransmit-interval
13.说出五种OSPF数据包类型 - DBD、HELLO、LSU、LSR、LSack
14.子网关键字有什么用 - 没有子网关键字,则只会重新分配未直接连接到路由器的主网络地址
15.有几种LSA - External LSA、Network LSA、ASBR Summary LSA、Network Summary LSA、Router LSA
16.将优先级设为“0”的Route会发生什么 - 不参与DR/BDR的选举
17.没有骨干区域能使用OSPF吗 - 可以,但只有区域内通信,没有骨干区域就无法实现区域之间的通信
18.多播地址 - 224.0.0.5和224.0.0.6
19.Route ID是什么 - 用于识别路由器的标识符,是一个32位数字
20.OSPF定时器 - Dead Interval:定义了扩展路由器在宣布邻居死亡之前将如何等待hello数据包
- Hello Interval:定义了OSPF路由器向其他OSPF路由器发送hello数据包的频率
Kubernetes
一个目标:容器操作
自动化容器操作的开源平台。这些容器操作包括:部署、调度和节点集群间扩展。
具体功能:
- 自动化容器部署和复制。
- 实时弹性收缩容器规模。
- 容器编排成组,并提供容器间的负载均衡。
- 调度:容器在哪个机器上运行。
组成:
- kubectl:客户端命令行工具,作为整个系统的操作入口。
- kube-apiserver:以 REST API 服务形式提供接口,作为整个系统的控制入口。
- kube-controller-manager:执行整个系统的后台任务,包括节点状态状况、Pod 个数、Pods 和Service 的关联等。
- kube-scheduler:负责节点资源管理,接收来自 kube-apiserver 创建 Pods 任务,并分配到某个节点。
- etcd:负责节点间的服务发现和配置共享。
- kube-proxy:运行在每个计算节点上,负责 Pod 网络代理。定时从 etcd 获取到 service 信息来做相应的策略。
- kubelet:运行在每个计算节点上,作为 agent,接收分配该节点的 Pods 任务及管理容器,周期性获取容器状态,反馈给 kube-apiserver。
- DNS:一个可选的 DNS 服务,用于为每个 Service 对象创建 DNS 记录,这样所有的 Pod 就可以通过 DNS 访问服务了。
两地三中心
两地三中心包括本地生产中心、本地灾备中心、异地灾备中心。
k8s 使用 etcd 组件作为一个高可用、强一致性的服务发现存储仓库。用于配置共享和服务发现。
它作为一个受到 Zookeeper 和 doozer 启发而催生的项目。除了拥有他们的所有功能之外,还拥有以下 4 个特点:
- 简单:基于 HTTP+JSON 的 API 让你用 curl 命令就可以轻松使用。
- 安全:可选 SSL 客户认证机制。
- 快速:每个实例每秒支持一千次写操作。
- 可信:使用 Raft 算法充分实现了分布式。
四层服务发现
k8s 提供了两种方式进行服务发现:
环境变量:当创建一个 Pod 的时候,kubelet 会在该 Pod 中注入集群内所有 Service 的相关环境变量。需要注意的是,要想一个 Pod 中注入某个 Service 的环境变量,则必须 Service 要先比该 Pod 创建。这一点,几乎使得这种方式进行服务发现不可用。 比如,一个 ServiceName 为 redis-master 的 Service,对应的 ClusterIP:Port 为 10.0.0.11:6379,则对应的环境变量为:
- REDIS_MASTER_SERVICE_HOST=10.0.0.11
- REDIS_MASTER_SERVICE_PORT=6379
- REDIS_MASTER_PORT=tcp://10.0.0.11:6379
- REDIS_MASTER_PORT_6379_TCP=tcp://10.0.0.11:6379
- REDIS_MASTER_PORT_6379_TCP_PROTO=tcp
- REDIS_MASTER_PORT_6379_TCP_PORT=6379
- REDIS_MASTER_PORT_6379_TCP_ADDR=10.0.0.11
DNS:可以通过 cluster add-on 的方式轻松的创建 KubeDNS 来对集群内的 Service 进行服务发现。
以上两种方式,一个是基于 TCP,DNS 基于 UDP,它们都是建立在四层协议之上。
五种 Pod 共享资源
Pod 是 k8s 最基本的操作单元,包含一个或多个紧密相关的容器。
一个 Pod 可以被一个容器化的环境看作应用层的“逻辑宿主机”;一个 Pod 中的多个容器应用通常是紧密耦合的,Pod 在 Node 上被创建、启动或者销毁;每个 Pod 里运行着一个特殊的被称之为 Volume 挂载卷,因此他们之间通信和数据交换更为高效。在设计时我们可以充分利用这一特性将一组密切相关的服务进程放入同一个 Pod 中。
一个 Pod 中的应用容器共享五种资源:
- PID 命名空间:Pod 中的不同应用程序可以看到其他应用程序的进程 ID。
- 网络命名空间:Pod 中的多个容器能够访问同一个IP和端口范围。
- IPC 命名空间:Pod 中的多个容器能够使用 SystemV IPC 或 POSIX 消息队列进行通信。
- UTS 命名空间:Pod 中的多个容器共享一个主机名。
- Volumes(共享存储卷):Pod 中的各个容器可以访问在 Pod 级别定义的 Volumes。
- Pod 的生命周期通过 Replication Controller 来管理;通过模板进行定义,然后分配到一个 Node 上运行,在 Pod 所包含容器运行结束后,Pod 结束。
Kubernetes 为 Pod 设计了一套独特的网络配置,包括为每个 Pod 分配一个IP地址,使用 Pod 名作为容器间通信的主机名等。
同一个 Pod 里的容器之间仅需通过 localhost 就能互相通信。
六个 CNI 常用插件
CNI(Container Network Interface)容器网络接口是 Linux 容器网络配置的一组标准和库,用户需要根据这些标准和库来开发自己的容器网络插件。CNI 只专注解决容器网络连接和容器销毁时的资源释放,提供一套框架。所以 CNI 可以支持大量不同的网络模式,并且容易实现。
- Loopback
- Bridge
- PTP
- MACvlan
- IPvlan
- 3rd-party
七层负载均衡
提负载均衡就不得不先提服务器之间的通信。
IDC(Internet Data Center)也可称数据中心、机房,用来放置服务器。IDC 网络是服务器间通信的桥梁。
路由器、交换机、MGW/NAT 都是网络设备,按照性能、内外网划分不同的角色。
-
内网接入交换机:也称为 TOR(top of rack),是服务器接入网络的设备。每台内网接入交换机下联 40-48 台服务器,使用一个掩码为 /24 的网段作为服务器内网网段。
-
内网核心交换机:负责 IDC 内各内网接入交换机的流量转发及跨 IDC 流量转发。
-
MGW/NAT:MGW 即 LVS 用来做负载均衡,NAT 用于内网设备访问外网时做地址转换。
-
外网核心路由器:通过静态互联运营商或 BGP 互联美团统一外网平台。
-
二层负载均衡:基于 MAC 地址的二层负载均衡。
-
三层负载均衡:基于 IP 地址的负载均衡。
-
四层负载均衡:基于 IP+端口 的负载均衡。
-
七层负载均衡:基于 URL 等应用层信息的负载均衡。
上面四层服务发现讲的主要是 k8s 原生的 kube-proxy 方式。k8s 关于服务的暴露主要是通过 NodePort 方式,通过绑定 minion 主机的某个端口,然后进行 Pod 的请求转发和负载均衡,但这种方式有下面的缺陷:
- Service 可能有很多个,如果每个都绑定一个 Node 主机端口的话,主机需要开放外围的端口进行服务调用,管理混乱。
- 无法应用很多公司要求的防火墙规则。
理想的方式是通过一个外部的负载均衡器,绑定固定的端口,比如 80;然后根据域名或者服务名向后面的 Service IP 转发。
Kubernetes 给出的方案就是 Ingress(1.30.x版本改为Gateway API)。这是一个基于七层的方案。
八种隔离维度
LVS、Keepalived、Nginx及负载均衡相关问题
一、LVS(Linux Virtual Server)
1. LVS负载均衡策略
- 调度算法:
- 静态算法:轮询(RR)、加权轮询(WRR)、目标地址哈希(DH)
- 动态算法:最小连接(LC)、加权最小连接(WLC)、最短延迟(SED)
- 模式:NAT、DR(直接路由)、TUN(IP隧道)
2. LVS的组成
- 内核模块:
ipvs(实现负载均衡核心逻辑) - 用户空间工具:
ipvsadm(配置管理工具)
3. 三种模式对比
| 模式 | 原理 | 特性 | 适用场景 |
|---|---|---|---|
| NAT | 修改目标IP为Real Server,响应通过LVS返回 | 支持端口映射,LVS是瓶颈 | 小规模、需端口转换 |
| DR | 数据包MAC地址重写,Real Server直接响应客户端 | 高性能,LVS仅处理请求 | 高并发、低延迟 |
| TUN | IP隧道封装,Real Server可跨网络 | 支持跨机房,配置复杂 | 分布式部署 |
4. LVS相关术语
- DS(Director Server):负载均衡调度器
- RS(Real Server):后端真实服务器
- VIP(Virtual IP):对外服务的虚拟IP
- DIP(Director IP):LVS与RS通信的IP
- RIP(Real Server IP):后端服务器IP
二、Nginx负载均衡
1. Nginx分发策略
- 轮询(默认)、加权轮询、IP哈希、最小连接、响应时间(需第三方模块)
2. 四层负载实现
- 使用
stream模块,配置示例:
stream {
upstream backend {
server 192.168.1.1:80;
server 192.168.1.2:80;
}
server {
listen 80;
proxy_pass backend;
}
}
3. 核心模块
ngx_http_upstream_module(七层负载)ngx_stream_core_module(四层负载)
三、Keepalived与脑裂问题
1. Keepalived
- 基于VRRP协议实现高可用,通过主备节点选举保证VIP的连续性。
2. VRRP协议
- 虚拟路由冗余协议,通过多播心跳包(默认组播地址
224.0.0.18)选举Master节点。
3. 脑裂原因
- 网络隔离导致主备节点同时认为自己是Master。
4. 解决方案
- 增加心跳线冗余、配置优先级差异、脚本检测并强制关闭次要节点。
5. Zabbix监控脑裂
- 监控VIP是否在多个节点同时存活,或检测
keepalived进程状态。
四、负载均衡基础
1. 负载均衡原理
- 将请求分发到多个服务器,提升系统吞吐量、可用性和容错性。
2. 实现方式
- 硬件:F5、A10
- 软件:LVS(四层)、Nginx(七层)、HAProxy
- DNS轮询、客户端负载均衡
3. 作用
- 流量分发、故障转移、横向扩展、安全防护(如DDoS缓解)。
五、LVS vs Nginx对比
| 维度 | LVS | Nginx |
|---|---|---|
| 层级 | 四层(传输层) | 七层(应用层) |
| 性能 | 更高(内核态转发) | 较低(用户态解析) |
| 功能 | 简单转发 | 支持HTTP协议处理、缓存 |
| 配置复杂度 | 复杂(需内核模块) | 简单(配置文件驱动) |
六、脑裂监控示例(Zabbix)
# 检测VIP是否存在于多个节点
vip="192.168.1.100"
if ip addr show | grep -q "$vip"; then
# 检查其他节点是否也持有VIP
if ping -c 1 other_node &>/dev/null && ssh other_node "ip addr show | grep -q '$vip'"; then
echo "脑裂发生!"
fi
fi
Web服务
一、Web服务与服务器对比
1. 常见的Web服务
- 静态服务:Nginx、Apache、Caddy
- 动态服务:Tomcat(Java)、Resin(Java)、Gunicorn(Python)、PHP-FPM(PHP)
- 代理/缓存:Squid(正向代理)、Varnish(HTTP加速)、Traefik(反向代理)
2. Nginx vs Apache
| 维度 | Nginx | Apache |
|---|---|---|
| 架构 | 事件驱动(epoll) | 多进程/多线程(MPM) |
| 性能 | 高并发、低内存占用 | 动态资源处理更稳定 |
| 配置 | 简洁,模块化 | .htaccess支持,灵活 |
| 适用场景 | 静态资源、反向代理 | 动态内容(如PHP) |
3. Nginx性能优势
- 事件驱动模型:基于epoll的非阻塞I/O,单线程处理大量连接。
- 内存消耗低:连接复用,无需为每个请求创建进程/线程。
- 热部署:支持不重启服务更新配置和二进制文件。
4. Epoll的组成
- 事件表:内核维护的红黑树,高效管理文件描述符。
- 就绪列表:当I/O事件就绪时,内核将描述符加入列表并通知用户。
- 边缘触发(ET):仅在状态变化时触发,需一次处理完所有数据。
二、Nginx核心功能与配置
1. 常用命令
nginx -s reload# 重载配置
nginx -s stop# 快速停止
nginx -t # 检查配置语法
nginx -V # 查看编译参数(含模块)
2. 反向代理 vs 正向代理
| 类型 | 正向代理 | 反向代理 |
|---|---|---|
| 客户端感知 | 客户端配置代理服务器 | 客户端无感知 |
| 用途 | 突破访问限制(如FQ) | 负载均衡、隐藏后端 |
3. Nginx处理HTTP请求流程
- 接收请求并解析请求头。
- 匹配
server块(基于域名/IP+端口)。 - 匹配
location规则(优先级:精确 > ^~ > 正则 > 通用)。 - 执行代理、重定向或返回静态文件。
4. 虚拟主机类型
- 基于域名:
server_name a.com b.com; - 基于IP/端口:
listen 192.168.1.1:80;
5. 健康检查
- 被动检查:通过失败重试机制(
max_fails和fail_timeout)。 - 主动检查:使用
nginx_upstream_check_module模块定时探测后端。
6. 防盗链配置
location ~* \.(jpg|png)$ {
valid_referers none blocked *.example.com;
if ($invalid_referer) {
return 403;
}
}
7. Location规则优先级
= /path>^~ /path>~* \.jpg$>/path
三、Tomcat与动态资源处理
1. Tomcat端口
- HTTP默认端口:8080(修改:
<Connector port="8080">) - Shutdown端口:8005(发送SHUTDOWN命令)
- AJP端口:8009(连接Apache等前端代理)
2. Tomcat工作模式
- BIO:阻塞式I/O(旧版本默认)。
- NIO:非阻塞I/O(高并发推荐)。
- APR:基于本地库的高性能模式(需安装apr库)。
3. Tomcat优化建议
- 调整JVM内存参数(
-Xms,-Xmx)。 - 启用NIO或APR模式。
- 禁用不必要的Web应用(如
examples)。
4. FastCGI vs CGI
| 维度 | CGI | FastCGI |
|---|---|---|
| 进程模型 | 每次请求创建新进程 | 长驻进程,复用处理 |
| 性能 | 低(频繁创建进程) | 高 |
| 适用场景 | 简单脚本 | 高并发PHP/Python |
四、网络与协议
1. 三次握手与四次挥手
- 三次握手:SYN → SYN-ACK → ACK(建立连接)。
- 四次挥手:FIN → ACK → FIN → ACK(释放连接)。
2. 访问网站流程
- DNS解析域名→IP
- TCP三次握手建立连接
- 发送HTTP请求
- 服务器处理并返回响应
- 浏览器渲染页面
- TCP四次挥手断开连接
3. 静态资源 vs 动态资源
- 静态资源:HTML/CSS/JS/图片(直接返回文件)。
- 动态资源:由服务器脚本生成(如PHP/Java)。
五、性能优化与监控
1. Nginx优化
- 调整
worker_processes(CPU核数)、worker_connections(单进程并发数)。 - 启用Gzip压缩、静态文件缓存。
- 使用
sendfile和tcp_nopush提升传输效率。
2. 监控Tomcat内存
- 使用
jconsole或jvisualvm连接Tomcat JVM。 - 配置JMX远程监控:
-Dcom.sun.management.jmxremote.port=9010
-Dcom.sun.management.jmxremote.authenticate=false
3. Nginx Session不同步问题
- 方案1:使用IP哈希策略保持会话粘滞。
- 方案2:共享Session存储(如Redis)。
六、工具与日志分析
1. 统计IP访问量Top 10
awk '{print $1}' access.log | sort | uniq -c | sort -nr | head -10
2. 灰度发布
- 逐步将新版本部署到部分服务器或用户,验证稳定性后全量上线。
3. Squid/Varnish/Nginx区别
| 工具 | 核心用途 | 特点 |
|---|---|---|
| Squid | 正向代理、缓存 | 支持HTTPS、ACL控制 |
| Varnish | HTTP加速(反向代理缓存) | 高性能、内存缓存 |
| Nginx | 反向代理、负载均衡 | 轻量级、高并发处理 |
七、其他高频问题
1. Nginx默认配置文件路径
/etc/nginx/nginx.conf(主配置)/etc/nginx/conf.d/*.conf(子配置)
2. Nginx常用状态码
499:客户端主动关闭请求。502:后端服务无响应。504:后端服务超时。
3. Worker最大并发数
- 计算公式:
worker_processes * worker_connections
MySQL、Redis、Memcache、MongoDB及Kafka相关问题
一、MySQL数据库
1. 数据删除操作对比
| 操作 | 类型 | 是否记录日志 | 是否可回滚 | 特点 |
|---|---|---|---|---|
| DELETE | DML | 是 | 是 | 逐行删除,保留表结构,可带WHERE条件 |
| TRUNCATE | DDL | 否 | 否 | 快速清空表,重置自增ID,释放空间 |
| DROP | DDL | 否 | 否 | 删除表结构+数据,不可恢复 |
2. 主从复制
- 原理:
- 主库将变更写入Binlog;
- 从库IO线程拉取Binlog到Relay Log;
- 从库SQL线程重放Relay Log中的事件。
- 问题:主从延迟、数据冲突、复制中断。
- 解决延迟:优化慢查询、并行复制、半同步复制、硬件升级。
3. 备份与恢复
- 备份方式:
- 逻辑备份:
mysqldump(全量/单表) - 物理备份:
xtrabackup(热备,支持增量) - 恢复误删数据:
- 停止MySQL;
- 使用xtrabackup还原全量备份;
- 应用增量Binlog到误操作前的时间点。
4. 引擎对比(InnoDB vs MyISAM)
| 维度 | InnoDB | MyISAM |
|---|---|---|
| 事务 | 支持ACID | 不支持 |
| 锁 | 行级锁 | 表级锁 |
| 外键 | 支持 | 不支持 |
| 崩溃恢复 | 支持 | 需修复表 |
| 适用场景 | 高并发写、事务 | 读多写少、静态数据 |
5. 索引与优化
- 索引类型:B+树(主键/唯一/普通)、哈希(MEMORY引擎)、全文索引。
- 安全措施:
- 限制远程访问IP;
- 定期备份;
- 使用SSL加密连接;
- 审计日志监控。
二、Redis缓存
1. 核心特性
- 单线程模型:基于事件循环(I/O多路复用),避免上下文切换。
- 数据结构:String、Hash、List、Set、ZSet、Stream。
- 持久化:
- RDB:定时快照,恢复快但可能丢数据;
- AOF:追加日志,数据安全但文件大。
2. 高可用架构
- 主从复制:从库异步复制主库数据。
- 哨兵模式:监控主节点,自动故障转移。
- Cluster模式:分片存储,支持水平扩展。
3. 缓存问题及解决
| 问题 | 现象 | 解决方案 |
|---|---|---|
| 缓存雪崩 | 大量Key同时过期 | 随机过期时间、集群部署、熔断机制 |
| 缓存穿透 | 查询不存在的数据 | 布隆过滤器、空值缓存 |
| 缓存击穿 | 热点Key失效后高并发查询 | 互斥锁、永不过期 |
三、Memcache
- 特点:多线程、纯内存、Key-Value存储,不支持持久化。
- 应用场景:会话缓存、高频读低一致性数据。
- 与Redis区别:无持久化、不支持复杂数据结构。
四、MongoDB
- 优势:文档存储(BSON格式)、动态Schema、水平扩展(分片)。
- 场景:日志存储、实时分析、非结构化数据(如JSON)。
五、Kafka消息队列
1. 核心概念
- Broker:Kafka服务节点,负责消息存储和转发。
- ISR(In-Sync Replicas):与Leader保持同步的副本集合。
- AR(All Replicas):所有副本(包括ISR和落后副本)。
2. 高性能原因
- 顺序写入磁盘:利用磁盘顺序I/O的高吞吐。
- 零拷贝技术:减少数据在内核态与用户态间复制。
- 分区并行处理:消息按分区分布,多消费者并行消费。
3. 写入流程
- Producer发送消息到指定Topic分区;
- Leader副本写入本地Log;
- Follower副本异步拉取数据;
- Leader确认写入成功(ACK机制)。
4. 适用场景
- 日志收集、流处理、实时监控、事件溯源。
六、高频问题速答
1. MySQL忘记root密码
# 1. 停止MySQL服务
systemctl stop mysqld
# 2. 启动跳过权限验证
mysqld_safe --skip-grant-tables &
# 3. 修改密码
mysql -u root
UPDATE mysql.user SET authentication_string=PASSWORD('newpass') WHERE User='root';
FLUSH PRIVILEGES;
2. 主从数据一致性校验
pt-table-checksum --user=root --password=xxx --databases=db1
pt-table-sync --execute --user=root --password=xxx
3. Kafka为什么快?
- 顺序I/O、批量发送/消费、页缓存优化、分区并行。
监控系统
一、Zabbix监控系统
1. 核心组件
- Zabbix Server:核心服务,负责数据处理、告警触发。
- Zabbix Proxy:分布式代理,分担Server压力,缓存和转发数据。
- Zabbix Agent:部署在被监控主机,采集数据(如CPU、内存)。
- Database:存储配置、监控数据(MySQL/PostgreSQL等)。
- Web UI:配置管理、数据可视化。
2. 监控模式
- 被动模式:Server主动向Agent拉取数据(默认)。
- 主动模式:Agent主动将数据推送到Server(适合跨网络环境)。
3. 工作流程
- Agent采集数据 → 2. Server处理并存储 → 3. 触发告警规则 → 4. 通知用户(邮件/微信等)。
4. 常用术语
- Host:被监控设备。
- Item:监控项(如CPU利用率)。
- Trigger:告警条件(如CPU > 90%持续5分钟)。
- Action:触发后的动作(发送告警、执行脚本)。
5. 自定义发现(LLD)
- 步骤:
- 编写自动发现脚本(如发现磁盘分区);
- 创建Discovery Rule,解析脚本输出的JSON;
- 基于发现结果生成监控项。
- 示例脚本输出:
{"data":[{"{#DISK}":"sda1"},{"{#DISK}":"sdb1"}]}
6. 微信报警集成
- 方法:通过Zabbix的
Media Type调用企业微信API:
curl -d '{"msgtype":"text","text":{"content":"报警内容"}}' -H "Content-Type: application/json" "https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=xxx"
7. 批量安装Agent
- 工具:Ansible/SaltStack/Shell脚本。
- Ansible示例:
- hosts: all
tasks:
- name: Install Zabbix Agent
yum: name=zabbix-agent state=present
- name: Configure Agent
template: src=zabbix_agentd.conf.j2 dest=/etc/zabbix/zabbix_agentd.conf
- name: Start Agent
service: name=zabbix-agent state=started
8. 分布式部署
- 架构:
- 中心Server → 多个Proxy → 各区域Agent。
- Proxy场景:
- 跨机房监控;
- 网络隔离环境;
- 分担Server负载。
二、Prometheus监控系统
1. 工作原理
- 拉取模型:Prometheus Server定期从目标(Exporters/应用)拉取指标(HTTP接口)。
- 存储:时间序列数据库(TSDB)。
- 告警:通过Alertmanager处理告警路由和通知。
2. 核心组件
- Prometheus Server:数据采集、存储、查询。
- Exporters:暴露监控指标(如Node Exporter采集主机指标)。
- Pushgateway:临时任务指标推送。
- Alertmanager:告警去重、分组、通知。
三、ELK日志系统
1. 工作流程
- Logstash:采集日志 → 过滤处理(如解析JSON) → 输出到Elasticsearch。
- Elasticsearch:存储、索引日志数据。
- Kibana:可视化查询、生成仪表盘。
2. Logstash输入源
- 文件(
file)、Syslog、Kafka、Beats(Filebeat)、数据库等。
3. Logstash架构
- Input:定义数据来源。
- Filter:解析和转换数据(如Grok、Date插件)。
- Output:发送到目标(如ES、Kafka)。
4. Elasticsearch插件
- IK分词器:中文分词。
- Head插件:集群管理可视化。
- X-Pack:安全、监控、告警功能(商业版)。
四、监控参数示例(Zabbix)
1. 主机层监控
- CPU:利用率、负载、上下文切换。
- 内存:使用量、Swap使用率。
- 磁盘:空间、IOPS、读写延迟。
- 网络:带宽、TCP连接数、丢包率。
2. 服务层监控
- Web服务:HTTP状态码、响应时间。
- 数据库:连接数、慢查询、锁等待。
- 中间件:Kafka堆积量、Redis内存占用。
3. 应用层监控
- JVM:堆内存、GC时间、线程数。
- 自定义业务指标:订单处理延迟、API错误率。
五、高频问题速答
1. Zabbix工作进程
poller:数据采集;trapper:处理主动推送的数据;alerter:告警通知;history syncer:数据写入数据库。
2. Prometheus vs Zabbix
| 维度 | Prometheus | Zabbix |
|---|---|---|
| 数据模型 | 多维标签、时序数据 | 结构化主机-监控项模型 |
| 部署 | 轻量级、适合云原生 | 集中式、适合传统架构 |
| 灵活性 | 查询语言强大(PromQL) | 配置复杂,功能全面 |
DevOps
一、MySQL同步机制
1. 同步与半同步复制
| 类型 | 原理 | 特点 | 适用场景 |
|---|---|---|---|
| 异步复制 | 主库提交事务后直接返回成功,不等待从库确认。 | 高性能,但存在数据丢失风险。 | 对一致性要求不高的场景。 |
| 半同步复制 | 主库提交事务后,至少等待一个从库接收并写入Relay Log后才返回成功。 | 平衡性能与一致性,轻微延迟。 | 要求较高数据一致性的业务。 |
| 全同步复制 | 主库提交事务后,必须等待所有从库确认写入后才返回成功。 | 强一致性,但延迟高,可用性降低。 | 金融级强一致性需求。 |
- 半同步配置示例:
# 主库配置
plugin-load=rpl_semi_sync_master=semisync_master.so
rpl_semi_sync_master_enabled=1
# 从库配置
plugin-load=rpl_semi_sync_slave=semisync_slave.so
rpl_semi_sync_slave_enabled=1
二、CI/CD流程
1. CI/CD核心流程
- 持续集成(CI):
- 代码提交 → 自动构建 → 单元测试 → 代码扫描 → 生成制品。
- 工具:Jenkins、GitLab CI、CircleCI。
- 持续交付/部署(CD):
- 自动部署到测试环境 → 集成测试 → 人工审核 → 生产环境发布。
- 工具:Argo CD、Spinnaker、Tekton。
2. CI/CD Pipeline示例(GitLab):
stages:
- build
- test
- deploy
build-job:
stage: build
script:
- mvn clean package
test-job:
stage: test
script:
- mvn test
deploy-job:
stage: deploy
script:
- kubectl apply -f k8s-manifest.yaml
三、Kubernetes监控与日志
1. 监控指标
- 集群层面:节点CPU/内存利用率、Pod调度失败率、存储卷使用量。
- 应用层面:Pod状态(Running/Pending)、容器资源占用、HTTP请求延迟。
- 工具:Prometheus(采集)+ Grafana(可视化)。
2. 日志监控方案
- Sidecar模式:每个Pod部署日志收集容器(如Fluentd)。
- DaemonSet模式:在每个节点部署日志Agent(如Filebeat)。
- 日志系统:ELK(Elasticsearch + Logstash + Kibana)或 Loki + Grafana。
3. Service vs Ingress
| 维度 | Service | Ingress |
|---|---|---|
| 功能 | 内部服务发现、负载均衡(TCP/UDP)。 | 外部HTTP/HTTPS路由、SSL终止、路径重写。 |
| 暴露方式 | ClusterIP、NodePort、LoadBalancer。 | 依赖Ingress控制器(如Nginx Ingress)。 |
| 适用场景 | 集群内服务通信。 | 外部访问管理、多域名路由。 |
四、Kubernetes核心组件
1. Master节点组件
- API Server:集群入口,处理REST请求。
- Scheduler:Pod调度到合适节点。
- Controller Manager:维护集群状态(如Deployment、Node生命周期)。
- etcd:分布式键值存储,保存集群状态。
2. Node节点组件
- kubelet:管理Pod生命周期、监控容器状态。
- kube-proxy:维护节点网络规则(Service IP转发)。
- 容器运行时:Docker、containerd、CRI-O。
五、TCP/IP协议
1. 四层模型
| 层级 | 协议示例 | 功能 |
|---|---|---|
| 应用层 | HTTP、DNS、FTP | 应用程序数据格式和会话管理。 |
| 传输层 | TCP、UDP | 端到端连接、可靠传输。 |
| 网络层 | IP、ICMP | 数据包路由和寻址。 |
| 链路层 | Ethernet、ARP | 物理网络设备通信。 |
2. TCP三次握手与四次挥手
- 三次握手:SYN → SYN-ACK → ACK(建立连接)。
- 四次挥手:FIN → ACK → FIN → ACK(释放连接)。
六、CDN工作原理
1. CDN核心机制
- 边缘节点缓存:将静态资源(图片、视频)缓存到离用户最近的节点。
- DNS智能解析:根据用户IP返回最近的节点IP。
- 回源机制:节点未命中缓存时,从源站拉取数据。
2. 应用场景
- 静态资源加速:网站图片、CSS/JS文件。
- 流媒体分发:直播、点播视频。
- 安全防护:DDoS防御、防盗链。
3. CDN工作流程:
- 用户请求资源 → 2. DNS解析到最近CDN节点 → 3. 节点返回缓存内容 → 4. 若未命中,回源站获取并缓存。
Ansible专题
Ansible 面试题总结
1. 简述 Ansible 及其优势?
Ansible 是一款开源的自动化运维工具,基于 Python 开发,用于批量系统配置、程序部署和任务执行。
优势:
- 无代理架构:无需在目标主机安装客户端,仅依赖 SSH 和 Python。
- 基于模块化:通过模块实现功能,支持丰富的内置模块和自定义扩展。
- YAML 语法:Playbook 使用人类可读的 YAML 文件,易于编写和维护。
- 跨平台支持:适用于物理机、虚拟机、云环境和网络设备。
- 幂等性:任务可重复执行,确保系统状态一致性。
- 动态库存:支持从外部系统(如云平台)动态获取主机清单。
2. 简述 Ansible 工作机制及其特性?
工作机制:
- 用户编写 Playbook 或执行 Ad-Hoc 命令。
- Ansible 解析任务并生成临时脚本。
- 通过 SSH 将脚本发送到目标主机执行。
- 返回执行结果并汇总输出。
特性:
- 无代理、无服务端(仅需控制节点)。
- 基于 SSH 协议(默认使用密钥认证)。
- 支持多级编排(通过 Roles 组织复杂任务)。
3. 如何保存敏感数据?
使用 Ansible Vault 加密敏感数据:
# 加密文件
ansible-vault encrypt secret.yml
# 在 Playbook 中使用加密文件
ansible-playbook --ask-vault-pass playbook.yml
- 支持加密变量文件、Playbook 或任意文本文件。
- 通过密码或密钥文件解密。
4. Ansible 适用场景
- 配置管理:统一管理服务器配置(如 Nginx、MySQL)。
- 应用部署:自动化部署代码或容器(如 Docker、Kubernetes)。
- 持续交付:集成 CI/CD 工具(如 Jenkins),实现自动化测试和发布。
- 安全合规:批量修复漏洞、审计配置。
- 编排多服务:协调复杂应用的多层依赖关系(如微服务架构)。
5. 简述 Ansible Inventory
Inventory 定义 Ansible 管理的主机列表,支持静态和动态两种形式:
- 静态 Inventory:文本文件定义主机和组。
[web]
web1.example.com
web2.example.com
[db]
db1.example.com
- 动态 Inventory:通过脚本从外部系统(如 AWS EC2)动态获取主机信息。
6. 配置文件优先级
从高到低优先级:
- 环境变量
$ANSIBLE_CONFIG指定的文件。 - 当前目录下的
ansible.cfg。 - 用户主目录的
~/.ansible.cfg。 - 全局配置文件
/etc/ansible/ansible.cfg。
7. Ad-Hoc 命令
Ad-Hoc 用于快速执行一次性任务:
ansible web -m ping # 检查主机连通性
ansible db -m yum -a "name=httpd state=latest"# 安装软件包
特点:无需编写 Playbook,适合简单任务。
8. Ad-Hoc 与 Playbook 的区别
| 维度 | Ad-Hoc | Playbook |
|---|---|---|
| 用途 | 临时执行简单任务 | 定义复杂任务流程 |
| 复用性 | 不可复用 | 可复用,支持版本控制 |
| 功能 | 单模块调用 | 多任务组合,支持条件、循环等 |
9. Ansible 变量
- 全局变量:通过命令行
-e或配置文件定义。 - Play 变量:在 Playbook 的
vars或vars_files中定义。 - 主机变量:在 Inventory 中为主机或组定义变量。
- Facts 变量:通过
setup模块自动收集目标主机信息(如 IP、OS 版本)。
10. 任务循环
- 简单循环:使用
loop遍历列表。
tasks:
- name: Create users
user:
name: "{{ item }}"
state: present
loop:
- alice
- bob
- 嵌套循环:使用
with_nested处理多列表组合。
tasks:
- name: Create directories
file:
path: "/data/{{ item.0 }}/{{ item.1 }}"
state: directory
with_nested:
- ["app", "log"]
- ["2023", "2024"]
11. Handler
Handler 是仅在任务触发时执行的特殊任务,用于处理服务重启、配置生效等操作。
tasks:
- name: Update Nginx config
template:
src: nginx.conf.j2
dest: /etc/nginx/nginx.conf
notify: Restart Nginx# 触发 Handler
handlers:
- name: Restart Nginx
service:
name: nginx
state: restarted
12. 错误处理
- 忽略错误:使用
ignore_errors: yes跳过失败任务。 - 块处理:通过
block、rescue、always管理错误流程。
- block:
- name: Task 1
command: /bin/false
rescue:
- name: Task failed, run recovery
debug:
msg: "Recovering..."
always:
- name: Always run this
debug:
msg: "Cleanup"
13. 角色(Roles)
角色 用于组织 Playbook,将任务、变量、文件等按目录结构分类:
roles/
webserver/
tasks/
main.yml
handlers/
main.yml
templates/
nginx.conf.j2
vars/
main.yml
- 通过
roles关键字在 Playbook 中调用。
14. Ansible Galaxy
Galaxy 是 Ansible 的公共角色仓库:
# 安装角色
ansible-galaxy install geerlingguy.nginx
# 创建新角色模板
ansible-galaxy init my_role
15. 并行执行控制
- forks:控制同时执行任务的主机数(默认 5)。
# ansible.cfg
[defaults]
forks = 10
- serial:滚动更新时限制每次更新的主机数量。
- name: Rolling update
hosts: web
serial: 2# 每次更新 2 台主机
16. 故障排查
- 日志:通过
log_path配置日志文件。 - 语法检查:
ansible-playbook --syntax-check playbook.yml - Dry Run:
ansible-playbook --check playbook.yml - Debug 模块:输出变量或任务结果。
tasks:
- name: Debug variable
debug:
var: ansible_facts.os_family
Dubbo专题
1. 基础概念
- 定义: 高性能Java RPC框架 → Apache孵化项目
- 核心功能:
- ✔️ 远程调用(基于接口)
- ✔️ 服务注册发现
- ✔️ 负载均衡(随机/轮询/最少活跃)
- 应用场景:
- 🏢 阿里/京东/美团等互联网公司
- 🌐 微服务架构下的服务治理
2. 架构设计
关键组件
- 注册中心:
- 🐜 Zookeeper(默认)/Redis/Nacos
- 🔄 临时节点机制(心跳检测)
- 监控中心:
- 📊 调用次数统计
- ⏱️ 响应时间监控
3. 配置管理
配置优先级
JVM -D参数(最高)- XML配置
dubbo.properties- 硬编码配置
特殊配置
// 直连配置示例
@Reference(url = "dubbo://192.168.1.1:20880")
private UserService userService;
4. 负载均衡
| 策略 | 特点 | 适用场景 |
|---|---|---|
| Random | 默认策略,权重随机 | 常规场景 |
| RoundRobin | 加权轮询 | 均匀分配 |
| LeastActive | 最少活跃调用 | 高性能节点优先 |
| ConsistentHash | 一致性哈希 | 参数路由 |
5. 序列化机制
- 支持协议:
- 🔄 Hessian2(默认)
- 🚀 JSON/FastJson
- 🧬 Protobuf/Thrift
- 性能对比:
- Kryo > FST > Hessian2 > JDK
6. 高级特性
SPI扩展机制
// META-INF/dubbo/com.xxx.LoadBalance
random=com.alibaba.dubbo.rpc.cluster.loadbalance.RandomLoadBalance
集群容错
- Failover(默认)
- Failfast
- Failsafe
- Failback
- Forking
7. 运维监控
常用命令
telnet localhost 20880
> status -l# 查看服务状态
> ls -l# 列出所有方法
故障排查
- 🔍 日志分析(配置log4j)
- 🧪 本地直连测试
- 📉 监控平台集成(Prometheus)
8. 版本演进
- Dubbo 2.x:
- 🌐 支持REST协议
- 🔄 增强异步调用
- Dubbo 3.x:
- 🚀 应用级服务发现
- 🛡️ 云原生支持
Kafka 核心知识体系总结
基础篇
1. Kafka 的核心用途
- 消息系统:解耦、流量削峰、异步通信。
- 存储系统:持久化到磁盘,支持长期存储和多副本机制。
- 流式处理平台:为流处理框架(如 Flink、Spark)提供数据源,内置流处理类库。
2. 核心概念
- ISR(In-Sync Replicas):与 Leader 保持同步的副本集合。
- AR(Assigned Replicas):分区的所有副本。
- HW(High Watermark):消费者可见的最大消息偏移量。
- LEO(Log End Offset):当前日志最后一条消息的偏移量+1。
- LSO(Log Start Offset):日志的起始偏移量。
3. 消息顺序性
- 实现方式:通过分区策略(如按消息键哈希)保证同一键的消息进入同一分区,实现分区内有序。
4. 生产者组件
- 分区器(Partitioner):决定消息发送到哪个分区。
- 序列化器(Serializer):将对象转换为字节数组。
- 拦截器(Interceptor):预处理或后处理消息。
- 处理顺序:拦截器 → 序列化 → 分区。
5. 消费者
- 非线程安全:需通过单线程消费或线程隔离实现并行。
- 消费者组(Consumer Group):组内消费者竞争分区,实现负载均衡。
- Rebalance:触发条件包括消费者加入/退出、分区数变化等。
6. 分区与副本
- 分区数调整:
- 扩容:支持动态增加(
kafka-topics.sh --alter)。 - 缩容:不支持(因数据迁移复杂)。
- 优先副本(Preferred Replica):AR 列表的第一个副本,用于 Leader 均衡。
进阶篇
1. 存储机制
- 日志目录结构:
topic-partition/
├── segment-1.log # 日志文件
├── segment-1.index # 偏移量索引
└── segment-1.timeindex # 时间戳索引
- 索引文件:
- 偏移量索引:快速定位消息物理位置。
- 时间戳索引:按时间戳查找偏移量。
2. 日志管理
- 日志删除(Log Retention):
- 基于时间:默认7天(
log.retention.hours=168)。 - 基于大小:删除超出阈值(
log.retention.bytes)的旧日志。 - 基于起始偏移量:删除早于
logStartOffset的日志。 - 日志压缩(Log Compaction):保留相同 key 的最新 value。
3. 副本机制
- Leader/Follower:Leader 处理读写,Follower 异步同步。
- 失效副本:判定条件(如
replica.lag.time.max.ms=10s滞后超时)。 - HW 同步:Leader 维护 ISR,所有副本 HW 取 ISR 中最小 LEO。
4. 高性能设计
- 零拷贝(Zero-Copy):通过
sendfile系统调用减少数据拷贝。 - 页缓存(Page Cache):利用操作系统缓存提升 IO 性能。
- 批量处理:生产者批量发送,消费者批量拉取。
高级篇
1. 可靠性保障
- 幂等性:
- 实现:通过
PID(生产者 ID)和序列号去重。 - 事务:
- 跨分区原子性:使用事务协调器(TransactionCoordinator)管理事务状态。
- 隔离级别:
read_committed仅消费已提交消息。
2. 容灾与监控
- Leader Epoch 机制:解决 HW 截断导致的数据不一致问题。
- 延时操作:通过时间轮(TimingWheel)管理超时任务。
- 监控指标:
- 关键指标:
BytesIn/BytesOut、UnderReplicatedPartitions、ISR变化频率。 - 工具:Prometheus + Grafana 监控集群状态。
3. 扩展应用
- 延迟队列:
- 实现:消息投递到内部主题(
delay_topic),由独立服务转发。 - 死信队列:消息重试多次后转入死信主题(需自定义处理逻辑)。
- 消息轨迹:通过埋点记录消息生命周期(如时间戳、唯一 ID)。
4. 常见问题
- 重复消费:Rebalance、手动提交偏移量失败。
- 消息丢失:生产者未确认(
acks=all)、消费者提前提交偏移量。 - Lag 计算:
read_uncommitted:Lag = HW - ConsumerOffset。read_committed:Lag = LSO - ConsumerOffset。
性能优化实践
- 分区策略:根据业务需求选择哈希或轮询,避免数据倾斜。
- 批量压缩:启用
compression.type(如snappy)减少网络传输。 - JVM 调优:调整堆内存、GC 参数(如 G1 收集器)。
- 操作系统优化:调整文件描述符限制、网络缓冲区大小。
数据库基础与优化总结
1. 数据库三范式
- 第一范式 (1NF)
- 要求:字段具有原子性,不可再分。
- 示例:
地址字段拆分为省、市、区。
- 第二范式 (2NF)
- 要求:每行数据有唯一标识(主键),消除部分依赖。
- 示例:订单表中,主键为
订单ID,避免非主键字段依赖主键的一部分。
- 第三范式 (3NF)
- 要求:消除传递依赖,非主键字段直接依赖主键。
- 示例:学生表中,
学院名称不应直接依赖学生ID,而应依赖学院ID。
2. 数据库优化经验
- 使用
PreparedStatement:预编译 SQL,提升性能。 - 减少外键约束:程序保证数据完整性时,可移除外键以提高插入/删除效率。
- 适度冗余:如主题帖的回复数,避免频繁 JOIN 查询。
- 优先
UNION ALL:避免UNION的去重和排序开销。
3. 索引类型
| 索引类型 | 特点 | 适用场景 |
|---|---|---|
| 普通索引 | 加速查询 | 高频查询字段 |
| 唯一索引 | 字段值唯一,允许空值 | 唯一性约束字段 |
| 主键索引 | 唯一且非空,表级唯一标识 | 主键字段 |
| 组合索引 | 多个字段联合索引 | 多条件查询优化 |
工作机制:B+树结构,通过二分查找快速定位数据,减少全表扫描。
4. MySQL 操作命令
-- 检查 MySQL 状态
service mysql status
-- 启停 MySQL
service mysql start
service mysql stop
-- 登录并操作数据库
mysql -u root -p
SHOW DATABASES;
USE database_name;
SHOW TABLES;
DESCRIBE table_name;
5. MySQL 复制原理
- 主从架构:
- 主库写二进制日志(Binlog)。
- 从库拉取 Binlog 到中继日志(Relay Log),重放日志同步数据。
- 复制类型:
- 基于语句:同步 SQL 语句(默认,高效但不保证幂等)。
- 基于行:同步数据变化(数据一致性强)。
- 混合模式:灵活选择复制方式。
6. InnoDB vs MyISAM
| 维度 | InnoDB | MyISAM |
|---|---|---|
| 事务支持 | 支持(ACID) | 不支持 |
| 锁机制 | 行级锁 | 表级锁 |
| 外键 | 支持 | 不支持 |
| 崩溃恢复 | 支持 | 不支持 |
| 全文索引 | 支持(5.6+) | 支持 |
| 存储结构 | 共享表空间/独立表空间 | 三个文件(.frm/.MYD/.MYI) |
7. 数据类型与设计
VARCHAR(50)vsCHAR:VARCHAR:变长字符串,节省空间(如存储邮箱)。CHAR:定长字符串,查询快(如存储固定长度国家代码)。- 大字段优化:拆分子表,减少主表 IO 压力(如文本内容单独存储)。
8. 事务隔离级别
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 实现方式 |
|---|---|---|---|---|
| Read Uncommitted | ✔️ | ✔️ | ✔️ | 无锁 |
| Read Committed | ❌ | ✔️ | ✔️ | 行级锁(写时加锁) |
| Repeatable Read | ❌ | ❌ | ✔️ | MVCC + 间隙锁 |
| Serializable | ❌ | ❌ | ❌ | 表级锁 |
InnoDB 默认:Repeatable Read,通过 MVCC 解决大部分幻读。
9. SQL 优化技巧
- 避免
SELECT *:明确字段列表,减少网络传输和解析开销。 - 使用
JOIN替代子查询:优化器更容易优化 JOIN。 - 索引覆盖:查询字段均在索引中,避免回表。
- 分页优化:
-- 低效
SELECT * FROM table LIMIT 1000000, 10;
-- 高效(基于主键)
SELECT * FROM table WHERE id > 1000000 LIMIT 10;
10. 高级操作
INSERT ... ON DUPLICATE KEY UPDATE:存在重复键时更新。
INSERT INTO users (id, name) VALUES (1, 'Alice')
ON DUPLICATE KEY UPDATE name = 'Alice';
UPDATE联表更新:
UPDATE orders o
JOIN users u ON o.user_id = u.id
SET o.status = 'paid'
WHERE u.email = 'alice@example.com';
11. 内存参数调优
| 参数 | 作用 | 建议值 |
|---|---|---|
key_buffer_size |
MyISAM 索引缓存 | 物理内存的 1/4 |
innodb_buffer_pool_size |
InnoDB 数据和索引缓存 | 物理内存的 70%-80% |
query_cache_size |
查询结果缓存 | 小型系统可开启,大型系统关闭 |
read_buffer_size |
顺序扫描数据缓冲区 | 按需调整(默认 128KB) |
Redis 核心知识点总结
1. Redis 简介
- 定位:基于内存的键值数据库,支持多种数据结构,用于缓存、分布式锁、消息队列等。
- 特点:
- 高性能(内存存储)、高并发(单线程模型 + I/O 多路复用)。
- 支持持久化(RDB/AOF)、事务、Lua 脚本、集群。
- 提供多种数据淘汰策略(LRU、LFU 等)。
2. Redis vs Memcached
| 维度 | Redis | Memcached |
|---|---|---|
| 数据类型 | 支持 6 种(String、List、Hash、Set、Sorted Set、Bitmap) | 仅 String |
| 持久化 | 支持(RDB/AOF) | 不支持 |
| 集群 | 原生支持 Cluster 模式 | 依赖客户端分片 |
| 线程模型 | 单线程(6.0+ 引入多线程 I/O) | 多线程 |
| 适用场景 | 复杂业务(如排行榜、会话缓存) | 简单键值缓存 |
3. 缓存处理流程
- 读请求:
- 缓存命中 → 直接返回数据。
- 缓存未命中 → 查数据库 → 写入缓存 → 返回数据。
- 写请求:
- 更新数据库 → 删除缓存(或更新缓存)。
4. Redis 数据结构与使用场景
| 数据结构 | 特点 | 典型场景 |
|---|---|---|
| String | 简单键值,支持自增 | 计数器(如用户访问次数) |
| List | 双向链表,支持阻塞操作 | 消息队列、最新消息列表 |
| Hash | 键值对集合 | 存储对象(如用户信息) |
| Set | 无序集合,支持交并差运算 | 共同关注、标签系统 |
| Sorted Set | 有序集合,按 Score 排序 | 排行榜、延迟队列 |
| Bitmap | 位操作 | 签到统计、用户在线状态 |
5. Redis 线程模型
- 单线程模型(6.0 前):
- 通过 I/O 多路复用处理并发连接。
- 避免线程切换开销,保证原子性操作。
- 多线程优化(6.0+):
- 网络 I/O 使用多线程,命令执行仍为单线程。
- 提升吞吐量,但线程安全问题由框架处理。
6. 过期策略与内存淘汰
- 过期策略:
- 惰性删除:访问时检查过期并删除。
- 定期删除:随机抽取键检查,分批删除。
- 内存淘汰策略(内存不足时触发):
volatile-lru/allkeys-lru:淘汰最近最少使用的键。volatile-ttl:淘汰即将过期的键。volatile-random/allkeys-random:随机淘汰。volatile-lfu/allkeys-lfu(4.0+):淘汰使用频率最低的键。
7. 持久化机制
| 机制 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| RDB | 定时生成内存快照 | 文件紧凑,恢复速度快 | 可能丢失最后一次快照后的数据 |
| AOF | 记录写操作日志 | 数据安全(可配置每秒同步) | 文件较大,恢复较慢 |
| 混合模式(4.0+) | RDB + AOF 结合 | 快速恢复 + 低数据丢失 | 文件可读性差 |
8. 事务
- 基本命令:
MULTI:开启事务。EXEC:执行事务。DISCARD:取消事务。WATCH:监听键,若被修改则事务失败。- 特点:
- 不支持回滚(命令错误需开发阶段发现)。
- 保证命令顺序执行,无隔离级别。
9. 使用场景与优化
- 高性能缓存:
- 缓存热点数据(如商品信息),减少数据库压力。
- 使用
EXPIRE设置合理过期时间,避免内存耗尽。 - 分布式锁:
- 通过
SET key value NX EX实现,确保原子性。 - 消息队列:
- 使用
LPUSH/BRPOP实现简单队列,或使用 Stream(5.0+)。
10. 常见问题
- 缓存穿透:查询不存在的数据,导致频繁访问数据库。
- 解决:布隆过滤器拦截非法请求,缓存空值。
- 缓存雪崩:大量缓存同时失效。
- 解决:随机过期时间,或使用集群高可用。
- 缓存击穿:热点数据失效后高并发请求数据库。
- 解决:互斥锁(如 Redis
SETNX)重建缓存。
缓存穿透、雪崩与击穿
- 缓存穿透:
- 现象:请求不存在的数据,绕过缓存直达数据库。
- 解决:
- 布隆过滤器:预存所有可能存在的 key,拦截无效请求。
- 缓存空值:对不存在的 key 设置短时间空值(如
SET key null EX 60)。
- 缓存雪崩:
- 现象:大量缓存同时失效,请求涌入数据库。
- 解决:
- 随机过期时间:避免集中失效(如
EXPIRE key 60 + random(60))。 - 集群高可用:通过 Redis 集群分散风险。
- 缓存击穿:
- 现象:热点 key 过期后高并发请求数据库。
- 解决:
- 互斥锁:使用
SETNX或分布式锁重建缓存。 - 永不过期:逻辑上更新值,不依赖过期时间。
数据一致性策略
- 策略:Cache-Aside Pattern(旁路缓存):
- 读:先查缓存,未命中则查数据库并回填。
- 写:更新数据库后删除缓存(而非更新)。
- 失败处理:引入重试机制(如消息队列补偿)。
持久化机制
- RDB(快照):
- 原理:定时全量备份到磁盘(
bgsave)。 - 优点:文件紧凑,恢复速度快。
- 缺点:可能丢失最后一次快照后的数据。
- AOF(日志追加):
- 原理:记录写操作命令(支持每秒同步或每次同步)。
- 优点:数据安全,可恢复性强。
- 缺点:文件较大,恢复速度慢。
- 混合模式(4.0+):
- 结合 RDB 和 AOF,全量快照 + 增量日志。
事务与锁
- 事务命令:
MULTI(开启)、EXEC(执行)、DISCARD(取消)、WATCH(监听)。 - 限制:不支持原子性回滚,需业务补偿。
- CAS 乐观锁:通过
WATCH监听 key,若被修改则事务失败。
分布式锁实现
- 核心命令:
SET key value NX EX 30(原子性设置锁并指定超时)。 - 问题:锁超时后业务未完成,导致并发问题。
- 解决:引入 Redlock 算法或多节点锁。
集群与高可用
- 主从复制:
- 同步流程:全量同步(RDB) + 增量同步(AOF)。
- 作用:数据冗余、读写分离。
- 哨兵(Sentinel):
- 监控主节点故障,自动切换从节点为主。
- Cluster 模式:
- 分片存储(16384 个哈希槽),支持水平扩展。
- 节点间通过 Gossip 协议通信,自动故障转移。
性能优化
- Pipeline:批量执行命令,减少网络往返次数。
- Lua 脚本:原子性执行复杂逻辑,减少网络开销。
- 内存管理:
- 淘汰策略:按场景选择 LRU、LFU 或随机淘汰。
- 大 Key 拆分:避免单 Key 数据过大影响性能。
应用场景
- 会话缓存(Session):替代传统 Session 存储,支持分布式。
- 排行榜:使用
ZSET实现实时排序(如游戏积分)。 - 消息队列:
- 简单队列:
LPUSH/BRPOP。 - 延迟队列:
ZSET按时间戳排序。
- 计数器:
INCR实现原子性计数(如文章阅读量)。 - 布隆过滤器:快速判断元素是否存在(如爬虫去重)。
常见问题解决方案
- 大量 Key 同时过期:随机化过期时间,避免雪崩。
- 内存不足:配置合理淘汰策略,监控内存使用。
- 命令延迟:避免长耗时的
KEYS操作,使用SCAN分批次处理。
Redis 6.0 新特性
- 多线程 I/O:处理网络请求,提升吞吐量(命令执行仍为单线程)。
- SSL/TLS 支持:增强通信安全性。
- 客户端缓存:客户端本地缓存热点数据,减少网络请求。
高可用架构建议
- 多副本部署:主从复制 + 哨兵,保障故障自动切换。
- 异地多活:通过 Cluster 模式跨机房部署。
- 监控告警:定期检查 CPU、内存、网络延迟等关键指标。
1. Pipeline 优势
- 减少网络开销:将多个命令打包一次发送,减少多次往返时间(RTT)。
- 提升吞吐量:适合批量操作无依赖的命令(如
MSET、MGET)。 - 示例:
# 非 Pipeline
SET key1 value1 → GET key1 → SET key2 value2 → GET key2
# Pipeline
(SET key1 value1, GET key1, SET key2 value2, GET key2)
2. Redis 集群方案
- 主从复制(Replication):
- 主节点:处理写请求,异步复制数据到从节点。
- 从节点:处理读请求,故障时可提升为主节点。
- 哨兵(Sentinel):
- 监控主节点,自动故障转移(主节点宕机时选举新主)。
- 提供高可用,但不解决数据分片问题。
- Cluster 模式:
- 分片存储:将数据分到 16384 个哈希槽,每个节点负责部分槽。
- 自动故障转移:节点故障时,槽迁移至其他节点。
- 数据冗余:每个主节点有多个从节点,确保高可用。
3. 集群不可用条件
- 槽不完整:若某节点故障且未配置副本,其负责的哈希槽不可用。
- 例如:3 节点集群,节点 B 负责 5501-11000 槽,若 B 宕机且无副本,集群不可用。
4. Java 客户端对比
| 客户端 | 特点 |
|---|---|
| Jedis | 直连模式,API 全面但线程不安全,需配合连接池使用。 |
| Lettuce | 基于 Netty,支持异步和响应式编程,线程安全。 |
| Redisson | 提供分布式对象(如锁、队列),支持高并发,适合复杂分布式场景。 |
5. 内存优化与回收
- 优化策略:
- 使用 Hash 存储小对象(如用户信息),减少键数量。
- 合理设置过期时间,避免长期占用内存。
- 内存淘汰策略(
maxmemory-policy): allkeys-lru:淘汰最近最少使用的键(推荐)。volatile-ttl:淘汰即将过期的键。noeviction:禁止淘汰,新写入操作报错(慎用)。
6. 分布式锁实现
- 基础命令:
SET lock_key unique_value NX PX 30000# 原子性加锁并设置过期时间
- 问题解决:
- 锁续期:使用 Redisson 的 WatchDog 机制自动续期。
- 误删锁:通过 Lua 脚本确保只有锁持有者能释放锁。
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end
7. 延时队列实现
- 方案:
- Sorted Set:消息时间戳作为 Score,
ZADD生产,ZRANGEBYSCORE消费。
ZADD delay_queue <timestamp> "message"
ZRANGEBYSCORE delay_queue -inf <current_timestamp>
- 优点:天然支持按时间排序,避免消息丢失。
8. 大 Key 问题处理
- 扫描大 Key:
- 避免使用
KEYS *:改用SCAN分批次扫描,减少阻塞。 - 工具分析:
redis-cli --bigkeys或自定义脚本统计。 - 拆分策略:
- 大 Hash/List 拆分为多个小键。
- 使用分片存储(如 Cluster 模式)。
9. 高并发场景优化
- 热点 Key:
- 本地缓存:结合 Guava Cache 或 Caffeine 减少 Redis 访问。
- 分片:对 Key 加随机后缀,分散到不同节点。
- 缓存穿透:
- 布隆过滤器:预校验 Key 是否存在。
- 空值缓存:数据库查不到的 Key 缓存空值并设置短过期时间。
10. 集群管理命令
- 检查状态:
CLUSTER INFO # 查看集群信息
CLUSTER NODES# 列出节点信息
- 槽迁移:
CLUSTER ADDSLOTS <slot># 分配槽
CLUSTER SETSLOT <slot> NODE <node_id># 迁移槽
MongoDB 核心知识点总结
1. MongoDB 简介
- 定义:基于分布式文件存储的 NoSQL 数据库,数据以 BSON(类似 JSON)形式存储。
- 特点:
- 文档存储:数据以键值对形式组成文档(Document),支持嵌套结构。
- 高性能:水平扩展(分片)应对高负载。
- 高可用:副本集(Replica Set)自动故障转移。
- 灵活查询:支持丰富查询和聚合操作(如 MapReduce)。
2. NoSQL 对比 RDBMS
| 维度 | NoSQL (MongoDB) | RDBMS (MySQL) |
|---|---|---|
| 数据模型 | 非结构化/动态 Schema | 结构化,固定表结构 |
| 扩展性 | 水平扩展(分片) | 垂直扩展(硬件升级) |
| 事务支持 | 有限(单文档事务) | ACID 事务支持 |
| 适用场景 | 大数据、高并发、灵活 Schema | 复杂查询、事务性系统 |
3. 核心概念
- Document:基本存储单元,类似 JSON 对象。
- Collection:文档集合,类比 RDBMS 中的表。
- Database:多个 Collection 的容器。
- 索引:
- 支持单字段、复合、地理空间索引等。
- 查询优化器自动选择最优索引。
- 分片(Sharding):
- 将数据分布到多个节点,解决单机存储限制。
- 按范围(Range)或哈希(Hash)分片键(Shard Key)划分数据。
- 副本集(Replica Set):
- 主节点(Primary)处理写操作,从节点(Secondary)异步复制数据。
- 自动选举新主节点(故障转移)。
4. 查询与聚合
- 查询语法:基于 JSON 的查询表达式。
db.users.find({ age: { $gt: 20 }, status: "active" });
- 聚合框架:
$match、$group、$sort等操作符处理数据。
db.orders.aggregate([
{ $match: { status: "completed" } },
{ $group: { _id: "$user_id", total: { $sum: "$amount" } } }
]);
- MapReduce:批量数据处理,适合复杂聚合(但性能较低)。
5. 性能与优化
- 索引策略:
- 避免全集合扫描,为高频查询字段建立索引。
- 复合索引顺序遵循 ESR 规则(等值、排序、范围)。
- 写入优化:
- 批量插入(
insertMany)减少网络开销。 - 写关注(Write Concern)配置平衡性能与数据安全。
- 分片策略:
- 选择高基数分片键(如用户 ID)避免数据倾斜。
- 预分片(Pre-splitting)减少迁移开销。
6. 高可用与备份
- 副本集:
- 最小配置:1 主 + 2 从,容忍单节点故障。
- 读偏好:
primary(默认)、secondary、nearest。 - Journaling:
- 预写日志(WAL)确保数据持久性。
- 日志刷新频率可配置(
commitIntervalMs)。 - 备份恢复:
- mongodump/mongorestore:逻辑备份。
- 文件系统快照:物理备份(需停机或锁定写入)。
7. 分片集群管理
- 分片键选择:
- 影响数据分布和查询路由(如
user_id分片键)。 - 避免单调递增键(如时间戳)导致写入热点。
- 均衡器(Balancer):
- 自动迁移 Chunk(默认 64MB)保持分片均衡。
- 手动干预:冻结分片、调整 Chunk 大小。
- 故障处理:
- 分片节点宕机:触发 Chunk 迁移至其他节点。
- 配置服务器(Config Server)宕机:集群元数据不可用。
8. 常见问题与解决方案
- 大文件存储:使用 GridFS 分块存储(默认 255KB/块)。
- 数据文件膨胀:预分配机制导致,可通过压缩(
compact)回收空间。 - 慢查询:通过
explain()分析执行计划,优化索引。 - 连接数限制:调整
net.maxIncomingConnections参数。
9. 典型应用场景
- 日志存储:高写入吞吐,灵活 Schema。
- 内容管理:嵌套文档存储文章、评论。
- 实时分析:聚合框架快速统计。
- 地理数据:地理空间索引支持附近查询。
、
10. 操作命令示例
- 启动分片:
mongos --configdb config-srv1:27019,config-srv2:27019
- 添加分片节点:
sh.addShard("shard-srv1:27017");
- 分片集合:
sh.shardCollection("db.users", { user_id: 1 });
1. 分析器(Profiler)
- 功能:记录数据库操作的性能数据,帮助识别慢查询。
- 使用:
// 开启分析器(0:关闭,1:记录慢查询,2:记录所有操作)
db.setProfilingLevel(2, 100);// 记录所有耗时超过100ms的操作
// 查看分析结果
db.system.profile.find().sort({ ts: -1 }).limit(10);
2. 事务与加锁
- 事务支持:MongoDB 4.0+ 支持多文档 ACID 事务(需副本集)。
session.startTransaction();
try {
db.collection1.insertOne({ a: 1 }, { session });
db.collection2.updateOne({ b: 2 }, { $set: { c: 3 } }, { session });
session.commitTransaction();
} catch (error) {
session.abortTransaction();
}
- 锁机制:MongoDB 使用多粒度锁(全局、数据库、集合级别),支持并行读写。
3. 索引管理
- 创建索引:
// 单字段索引
db.users.createIndex({ email: 1 });
// 复合索引
db.orders.createIndex({ customer_id: 1, order_date: -1 });
// 文本索引
db.articles.createIndex({ content: "text" });
- 索引类型:
- 唯一索引:
db.collection.createIndex({ field: 1 }, { unique: true }) - TTL 索引:自动删除过期文档(如日志)。
- 地理空间索引:
2dsphere、2d。
4. 查询优化与聚合
- 查询条件:
- AND 查询:逗号分隔多个条件。
db.products.find({ category: "Electronics", price: { $lt: 1000 } });
- OR 查询:使用
$or操作符。
db.products.find({
$or: [
{ category: "Books" },
{ price: { $gt: 50 } }
]
});
- 聚合管道:
db.sales.aggregate([
// 按日期分组并计算总销售额
{ $match: { date: { $gte: ISODate("2023-01-01") } } },
{ $group: { _id: "$product", total: { $sum: "$amount" } } },
{ $sort: { total: -1 } },
{ $limit: 10 }
]);
5. 数据更新与删除
- 更新操作:
// 更新单个文档
db.users.updateOne(
{ _id: ObjectId("...") },
{ $set: { status: "active" } }
);
// 替换整个文档
db.users.replaceOne(
{ _id: ObjectId("...") },
{ name: "Alice", age: 30 }
);
- 删除文档:
// 删除匹配条件的所有文档
db.logs.deleteMany({ createdAt: { $lt: ISODate("2022-01-01") } });
6. 副本集(Replica Set)
- 角色:
- Primary:处理所有写操作,数据同步到 Secondaries。
- Secondary:异步复制数据,可处理读请求(需配置读偏好)。
- 选举机制:基于 Raft 算法,主节点宕机时自动选举新主。
- 配置:
// 初始化副本集
rs.initiate({
_id: "rs0",
members: [
{ _id: 0, host: "mongo1:27017" },
{ _id: 1, host: "mongo2:27017" },
{ _id: 2, host: "mongo3:27017", arbiterOnly: true }
]
});
7. 分片集群(Sharded Cluster)
- 组件:
- Router(mongos):路由查询到对应分片。
- Config Server:存储集群元数据(分片键、Chunk 分布)。
- Shard:存储数据分片,每个 Shard 可为副本集。
- 分片策略:
- Hash 分片:均匀分布数据,适合随机访问。
- Range 分片:按范围分布,适合范围查询。
- 平衡器:自动迁移 Chunk 确保各分片负载均衡。
8. 数据建模
- 嵌套文档:适用一对少关系(如用户与地址)。
{
_id: "user123",
name: "Bob",
addresses: [
{ city: "Beijing", street: "Main St" }
]
}
- 引用文档:适用一对多关系(如用户与订单)。
// users 集合
{ _id: "user123", name: "Bob" }
// orders 集合
{ _id: "order1", user_id: "user123", total: 100 }
9. 安全性
- 认证:启用
security.authorization,创建用户。
use admin;
db.createUser({
user: "admin",
pwd: "password",
roles: [ { role: "root", db: "admin" } ]
});
- 加密:
- 传输加密:TLS/SSL 配置。
- 存储加密:使用 WiredTiger 加密引擎。
10. 备份与恢复
- mongodump/mongorestore:
mongodump --uri="mongodb://user:pass@host:27017/db" --out=/backup
mongorestore --uri="mongodb://user:pass@host:27017/db" /backup/db
- 文件系统快照:适用于大型集群,需与存储引擎协调。
Prometheus
1. 监控系统设计原则
- 简洁性:避免不必要的指标采集,关注核心指标(如 RED: Rate, Errors, Duration)。
- 可用性:监控系统自身需高可用,优先于业务系统。
- 告警有效性:仅发送需处理的告警,确保告警被及时响应。
- 架构简单性:避免过度依赖复杂系统(如 AI 运维初期可能增加复杂度)。
2. Prometheus 的局限性
- 数据类型:仅适用于时序指标(Metrics),不适合日志、跟踪。
- 采集模型:默认 Pull 模型,需规划网络拓扑,避免转发瓶颈。
- 扩展性:集群化方案(如 Thanos、Cortex)需谨慎选型。
- 数据精度:统计函数(如
rate())可能产生推断结果,长时间查询需降采样。
3. K8S 监控组件与 Exporter
- 核心 Exporter:
- Node-exporter:机器指标(CPU、内存、磁盘)。
- Kube-state-metrics:K8S 资源状态(Pod、Deployment)。
- cAdvisor:容器资源使用(集成于 Kubelet)。
- Blackbox-exporter:网络探测(HTTP、DNS)。
- 应用层 Exporter:MySQL、Nginx 等需按业务需求部署。
4. K8S 核心组件监控
- APIServer:请求速率、延迟、错误率。
- etcd:写入延迟、存储容量。
- Scheduler/Controller Manager:调度性能、队列深度。
- Kubelet:容器生命周期、资源使用。
Grafana 面板示例:
- 使用 Kubernetes Administrator Dashboards 模板。
- 调整报警阈值(如 APIServer 请求延迟 > 1s 触发告警)。
5. All-in-One 采集方案
- Telegraf:集成多数据源(如进程、GPU 指标),减少 Exporter 数量。
- 自定义组合:主进程管理多个 Exporter,简化升级维护。
- 资源控制:限制 Exporter 内存/CPU 使用,避免影响主机。
6. 黄金指标选择
- USE 方法(资源):
- Utilization:使用率(如 CPU 利用率)。
- Saturation:饱和度(如磁盘 IO 队列)。
- Errors:错误数(如网络丢包)。
- RED 方法(服务):
- Rate:请求速率。
- Errors:错误率。
- Duration:延迟。
7. 多集群与外部采集配置
- 外部 Prometheus 配置:
- job_name: 'k8s-cadvisor'
kubernetes_sd_configs:
- role: node
api_server: https://<apiserver>:6443
bearer_token_file: /path/to/token
scheme: https
tls_config:
insecure_skip_verify: true
relabel_configs:
- source_labels: [__address__]
regex: (.+):10250
replacement: "${1}:10255"
target_label: __address__
- action: replace
source_labels: [__meta_kubernetes_node_name]
target_label: node
- 多集群策略:为每个集群配置独立 Job,分类采集(node、endpoint、service)。
8. GPU 监控
- NVIDIA DCGM Exporter:提供详细 GPU 指标(内存、利用率)。
- cAdvisor 指标:
container_accelerator_duty_cycle:GPU 利用率。container_accelerator_memory_used_bytes:显存使用。
9. Prometheus 时区处理
- 默认 UTC:所有时间戳以 Unix Time 存储。
- Grafana 时区转换:在面板设置中指定本地时区。
- 新版 Web UI:2.16+ 支持本地时区显示。
10. 高可用与存储
- Thanos:
- 全局视图:聚合多 Prometheus 实例数据。
- 去重:根据时间范围和副本策略合并数据。
- 长期存储:对接对象存储(如 S3、MinIO)。
- Cortex:水平扩展,支持多租户。
11. 告警管理
- Alertmanager:
- 路由分组:按集群、服务分类告警。
- 抑制规则:避免重复告警(如节点宕机抑制 Pod 告警)。
- 静默:维护窗口期内屏蔽非关键告警。
1. 负载均衡(LB)后的 Metric 采集
- 问题:Prometheus 无法直连 LB 后的服务端点(RS)。
- 解决方案:
- Sidecar Proxy:在 RS 容器内运行代理,暴露 Metric 端口。
- LB 路径转发:配置 LB 将特定路径(如
/metrics)转发到后端节点。 - 服务发现:使用 K8S Service Discovery 绕过 LB,直接采集端点。
# 示例:LB 路径转发配置
- job_name: 'backend-metrics'
static_configs:
- targets: ['lb.example.com']
metrics_path: '/backend1/metrics'
2. Prometheus 大内存问题
- 原因:时序数据在落盘前驻留内存,查询历史数据时加载至内存。
- 优化方案:
- 分片:拆分任务到多个 Prometheus 实例,使用 Thanos 聚合。
- 指标精简:通过
metric_relabel_configs过滤无用指标。 - 查询优化:避免大范围
rate()和group by。
# 示例:过滤无用指标
metric_relabel_configs:
- source_labels: [__name__]
regex: 'up|process_.*'
action: keep
- 容量规划工具:
- Prometheus 内存计算器:估算理论内存需求。
- 本地存储估算:
磁盘大小 = 保留时间(s) × 每秒样本数 × 样本大小(1-2字节)
3. K8S APIServer 性能影响
- 问题:大规模集群中频繁服务发现导致 APIServer 负载升高。
- 优化:
- 直接采集节点:绕过 APIServer Proxy,减少请求。
- 调整采集间隔:非核心指标拉取间隔从 30s 提升至 60s。
4. rate() 函数的逻辑与最佳实践
- 处理 Counter 重置:自动推断值变化,忽略计数器重置。
- 时间范围选择:区间至少为采集间隔的 4 倍(如 1 分钟采集间隔用 5 分钟范围)。
- 示例:
rate(http_requests_total[5m])# 推荐:5分钟区间
5. Prometheus 重启与热加载
- 优化重启:
- 热加载:开启
web.enable-lifecycle,通过 API 重新加载配置。
curl -X POST http://prometheus:9090/-/reload
- 避免长时间停机:使用 Thanos 实现高可用,分片存储。
6. 应用指标暴露建议
- 数量控制:核心服务保持约 100 个指标,大型应用不超过 10,000。
- Label 设计:避免高基数(如用户 ID 作为 Label)导致存储膨胀。
- 命名规范:遵循 Prometheus 命名规则(如
http_requests_total)。
7. Node-exporter 最佳实践
- 版本选择:使用较新版(≥0.16)以获得命名规范改进。
- 指标转换:旧版指标名通过
metric_relabel_configs转换。
metric_relabel_configs:
- source_labels: [__name__]
regex: 'node_memory_MemTotal'
replacement: 'node_memory_total_bytes'
target_label: __name__
8. Kube-state-metrics 使用场景
- 资源关联:结合 cAdvisor 指标,扩展 Label(如 Deployment 名称)。
# 关联Pod所属Deployment
sum by (deployment) (
kube_pod_info{namespace="default"} * on(pod) group_left(deployment)
kube_replicaset_owner{namespace="default"}
)
- 避免高基数:不暴露 Pod Annotation,仅保留必要元数据。
9. Relabel 配置技巧
relabel_configsvsmetric_relabel_configs:- 采集前:修改 Target 元数据(如替换标签)。
- 采集后:过滤或重命名指标。
# 示例:替换服务发现标签
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app]
target_label: app
# 示例:过滤指标
metric_relabel_configs:
- source_labels: [__name__]
regex: 'go_memstats_.*'
action: drop

 浙公网安备 33010602011771号
浙公网安备 33010602011771号