第一篇:查阅数据
前言
本文讲解如何使用 R 语言对数据集进行总体上的了解。
在进行数据挖掘之前,我们有必要对挖掘的数据集对象有一个总体的了解。本文采用具体实例讲解的方式,详细演示对一个数据集的分析过程。
Step 1:载入数据集

命令data("数据集名")可载入指定数据集。
Step 2:查看行列名

命令attributes("数据集")可打印出数据集的行/列名。本例中,bmi和chl是numeric类型,而另外两个变量是factor类型。
Step 3:查看特征类型信息
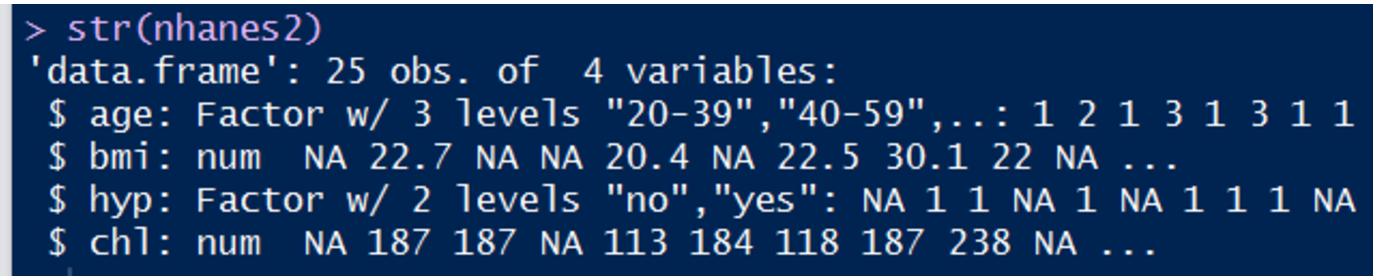
命令str("数据集")可以查看到特征的具体类型信息。本例中,bmi和chl是numeric类型,而另外两个变量是factor类型。
Step 4:查看特征值的总体分布情况

summary("数据集")可查看到特征值的总体分布情况。它会打印出各列的最大,最小,平均值,缺失值个数等信息。
需要特别说明的是 1st Qu,2 st Qu,3 st Qu 分别表示一分位点,二分位点,三分位点。一分位点表示四分之一处的数,二分位点表示中位数,三分位点表示四分之三处的数。
此外,Na's 是缺失值个数。
Step 5:数据可视化
这部分将在下文中详细讲解。
小结
本文只讲解了数据集的总体大致流程。针对某些实际情况,也许需要掌握一些关于分布,或者稀疏度之类的信息,这时需要查阅其他数据分析API,这里不再过细讲述。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号