

第三篇:爬虫框架 - Scrapy
前言
Python提供了一个比较实用的爬虫框架 - Scrapy。在这个框架下只要定制好指定的几个模块,就能实现一个爬虫。
本文将讲解Scrapy框架的基本体系结构,以及使用这个框架定制爬虫的具体步骤。
Scrapy体系结构
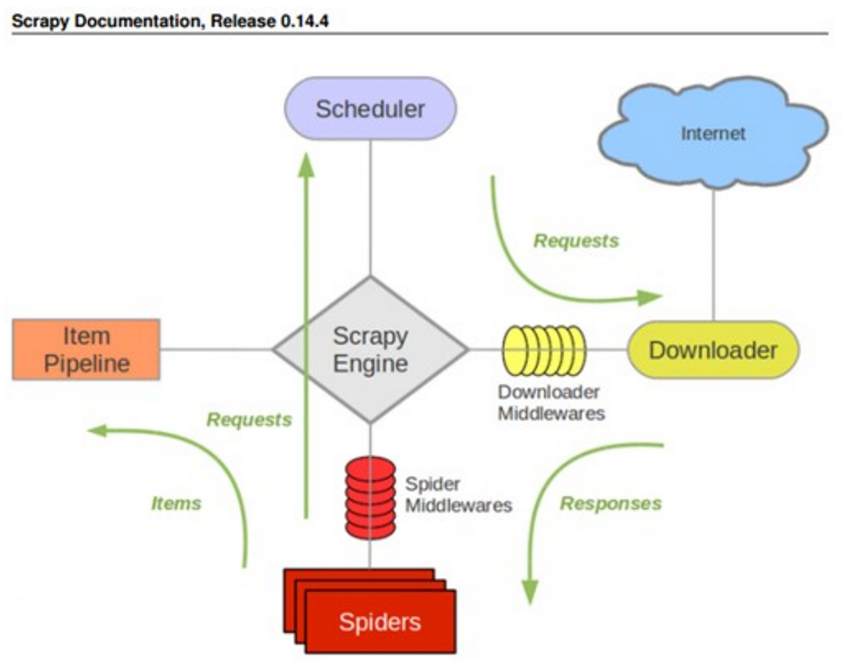
其具体执行流程如下:
1. 任务管理器Scheduler将初始下载任务递交给下载器Downloader;
2. 下载器Downloader将下载好了的页面传递给爬取分析器Spiders进行分析。
爬取分析器分析的结果分为两种:
a) 本次爬取所得数据 -> 它将传递给任务管理器Scheduler;
b) 需要进行下一级爬取的URL地址 -> 它将传递给数据管道进行相关的保存工作。
基于Scrapy框架的豆瓣网电影信息爬取器
1. 执行以下命令创建一个新的工程:
1 scrapy startproject doubanMovieSpider
doubanMovieSpider是工程名,工程包里将会有如下这些文件:
1) scrapy.cfg: 项目配置文件
2) items.py: 需要提取的数据结构定义文件
3) pipelines.py:管道定义,用来对items里面提取的数据做进一步处理,如保存等
4) settings.py: 爬虫配置文件
5) spiders: 放置spider的目录
该工程用于从豆瓣网爬取电影信息(如电影名,评分等等)。
2. 定义爬取结果数据结构Item --- 在items.py中编写如下代码:
1 # -*- coding: utf-8 -*- 2 # ================================================ 3 # 作者: 方萌 4 # 创建时间: 20**/**/** 5 # 版本号: 1.0 6 # 联系方式: 1505033833@qq.com 7 # ================================================ 8 # scrapy框架模块 9 import scrapy 10 class DoubanmoviespiderItem(scrapy.Item): 11 # 主题 12 title = scrapy.Field() 13 # 评分 14 rate = scrapy.Field() 15 # ID 16 id = scrapy.Field()
Item其实从本质来说,就是Scrapy框架自己实现的字典,需要继承scrapy.Item类。上述代码定义的字典表示要爬取的电影信息有:电影主题,电影评分,以及电影ID。
3. 实现爬取分析器Spider --- 在spiders目录下增加一个python文件MovieSpider.py:
在这个文件中自定义一个爬取分析器,该分析器为一个继承自scrapy.spider.BaseSpider(或者Scrapy框架下其他抽象爬取器)的类,它起码要实现以下几个字段:
1) name:spider的标识
2) start_urls:起始爬取URL
3) parse():爬取对象解析函数
实现代码如下:
1 # -*- coding: utf-8 -*- 2 # ================================================ 3 # 作者: 方萌 4 # 创建时间: 20**/**/** 5 # 版本号: 1.0 6 # 联系方式: 1505033833@qq.com 7 # ================================================ 8 # scrapy框架模块 9 import scrapy 10 # json解析模块 11 import json 12 # 系统模块 13 import sys 14 # items模块 15 import doubanMovieSpider.items 16 # 爬虫类 17 class MovieSpider(scrapy.spider.BaseSpider): 18 # 爬虫名 19 name = "douban" 20 # 域名限定 21 allowed_domains = ["www.douban.com"] 22 # 爬取URL队列 23 start_urls = [ 24 "http://movie.douban.com/j/serch_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=200&page_start=0" 25 ] 26 def parse(self, response): 27 """ 28 函数功能: 29 解析爬取到的数据 30 输入: 31 response -> 爬取返回数据对象 32 输出: 33 空 34 """ 35 # 将爬取到的电影信息存入json容器 36 json_container = json.loads(response.body) 37 # 构建items。该模块具体含义请查询相关文档。 38 items = [] 39 for movie_elem in json_container['subjects']: 40 item = doubanMovieSpider.items.DoubanmoviespiderItem() 41 for key in movie_elem: 42 if key == 'title': 43 item['title'] = movie_elem[key] 44 print movie_elem[key] 45 if key == 'rate': 46 item['rate'] = movie_elem[key] 47 if key == 'id': 48 item['id'] = movie_elem[key] 49 items.append(item) 50 # 返回items 51 return items
4. 实现PipeLine --- 修改items.py文件:
1 # -*- coding: utf-8 -*- 2 # Define your item pipelines here 3 # 4 # Don't forget to add your pipeline to the ITEM_PIPELINES setting 5 # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html 6 class DoubanmoviespiderPipeline(object): 7 def __init__(self): 8 pass 9 def process_item(self, item, spider): 10 pass
PipeLine用来对Spider返回的Item列表进行保存操作,可以写入到文件、或者数据库等。
我们可以在其中的__init__方法内编写打开文件部分代码,在process_item方法内编写具体的写入函数(可直接将数据写入进远程数据库);也可以不实现这个模块,scrapy会有其默认的写入机制(本系统采用默认写入机制)
5. 在项目当前目录下执行如下命令即可启动此爬虫系统:
1 scrapy crawl douban -o items.json -t json
该命令表示启动爬取分析器“douban”,并将爬取到的items以json格式保存到items.json文件中。“douban” 即是在爬取分析器中由name域指定的。
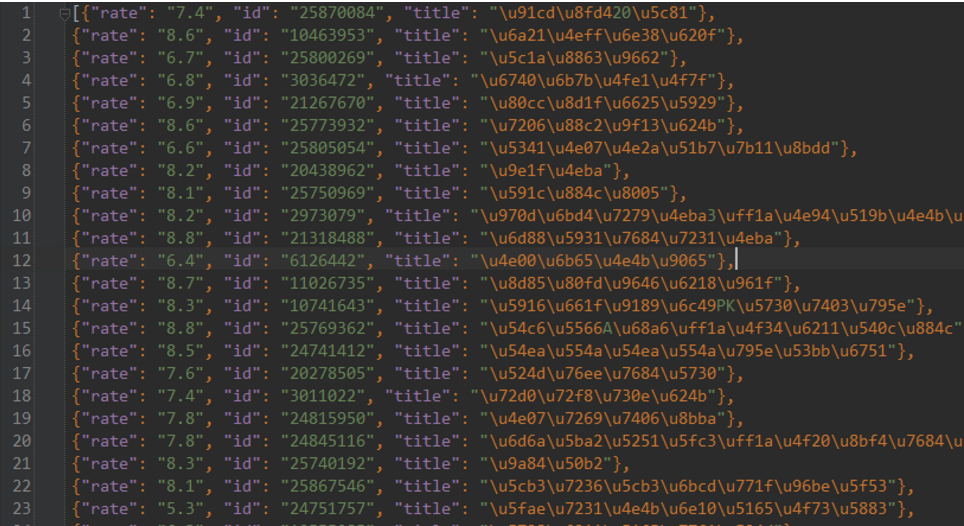
下图为爬取到的结果:
小结
本文仅仅给出Scrapy框架的基本使用。如果要实现生产级别的项目,还需对该框架内的一些具体设置,各种抽象爬取分析器进行深入研究。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号