第二篇:智能电网(Smart Grid)中的数据工程与大数据案例分析
前言
上篇文章中讲到,在智能电网的控制与管理侧中,数据的分析和挖掘、可视化等工作属于核心环节。除此之外,二次侧中需要对数据进行采集,数据共享平台的搭建显然也涉及到数据的管理。那么在智能电网领域中,数据工程到底是如何实施的呢?
本文将以IBM的Itelligent Utility Network产品为例阐述智能电网中的数据工程,它是IBM声称传统电网向智能电网转变的整体方案(看过上篇文章的童鞋想必会清楚这样的说法是片面狭隘的,它只能算是智能电网中的数据工程)。
另一方面,如今是一个数据爆炸的时代,电力领域也不例外。随着大量高级传感器、智能量测系统投入使用,大量的设备状态数据、用户用电数据、电网运营数据等被汇集到电网数据中心,这就需要先进大数据技术对这些海量数据进行实时分析,并实时挖掘出其潜在价值。
所幸目前已有不少大数据技术成功应用到电网,促进了电网的智能化发展。本文也将重点分析两个经典大数据应用案例,让读者品味电网领域中大数据的味道。
智能电网中的数据工程 - Intelligent Utility Network@IBM

Itelligent Utility Network是IBM公司提出的一个很不错的智能电网数据工程方案,笔者认为IBM作为全球商用软件巨头,提出的这套方案质量还是比较高的,起码看起来像那么回事。当然这款产品也只是IBM在智能电网领域的初期尝试,随着智能电网的迅速发展,IBM必然会推出更新更强大的数据产品。另外SAP、Oracle、华为、阿里等公司想必也不会放过这块蛋糕,加入进来也应该是迟早的事情。
接下来是该款产品的定义:Itelligent Utility Network首先利用传感器对发电、输电、配电、供电等关键设备的运行状况进行监控,其次将获得的数据通过网络系统进行收集、整合,最后通过对数据的分析、挖掘,达到对整个电力系统的优化管理。显然在IBM的眼里,智能电网的数据工程就是各种信息收集基础设施(如传感器)+中央数据分析运营平台,以实现对电力客户、电力资产、电力运营的持续监视,进而提高电网公司的管理、工作水平。
IBM认为智能电网数据工程主要分成以下五大组成部分:
1. 数据采集
IBM认为智能电网中的数据相比传统电网来源要更加广泛,它主要分为三个部分:
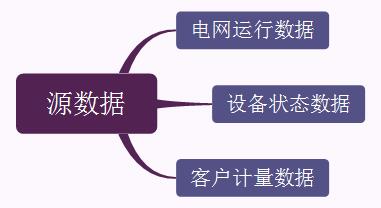
其中,电网运行数据可用于电网调度中心制定输电配电策略;设备状态数据可用于开展设备状态检修和状态评估;客户计量数据能加强电网公司对用户用电行为的检测,强化需求侧管理。管理好这些数据,就能实时掌握电网的运行状态,及时地制定电力调度、设备维修等策略。
2. 数据传输
在数据采集方面,IBM认为智能电网中数据量大、采集点多且分散,且实时性要求较高。针对这种情况,应当摒弃现有基于SCADA的采集方式,改用基于IP的实时数据传输方式进行传输。PS.笔者前段时间去参加亚洲智能电网展的时候,看过不少公司专门负责做电网中的数据通信,不知这个模块IBM是不是找其他公司来做的。
3. 数据集成
这个应该算是IBM的老本行了,他们在世界各地都有开设些讲座、研讨会,有空可以去听一听了解下。在传统数据集成这一块,IBM做的是真的不错。笔者过去在A公司工作的时候,主管就是来自IBM的,他对数据的思考非常独到,非常犀利。
不扯远了......针对电网中的数据集成,IBM提出了建立企业信息总线(ESB)以实现企业的数据集成:将各业务系统的数据集成到统一数据仓库里,底层建模遵照CIM标准。
4. 分析优化
分析优化环节显然是最核心的环节,IBM提出将智能电网的优化分为四个层次,建立了分析层次结构,从而指导用户对电力数据进行深层次利用。该部分涉及到很多电力系统的具体业务细节,本文篇幅所限不对此进行深入研究。但对于电网公司的数据工作人员,笔者认为应该掌握、精通类似工具。
5. 数据展现
数据展现是智能电网面向用户或者电网工作人员的接口,用户/工作人员可根据自身需求配置需要展示的各种信息及可视化方式。
智能电网中的大数据技术体系
1. 工程框架
不论是电力领域的大数据,还是诸如运营商、电商等领域的大数据,其基本架构都大抵相同:
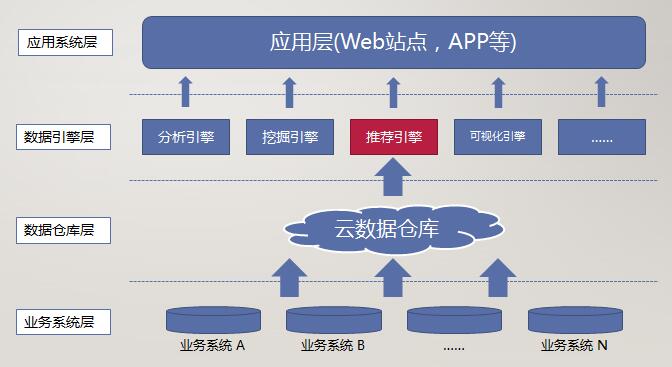
最底层的业务系统层包含电网中各种不同类型的数据源;数据仓库层用于实现ETL以及相应的数据质量保障工作,并对电力数据进行各种建模以满足多种分析统计的需要;数据引擎层包含从上层应用系统中提炼出的一些数据开发工作,常见的有数据分析引擎、数据挖掘引擎、数据可视化引擎、推荐引擎等等;应用系统层则是面向用户的系统,以网站或APP、专业客户端等形式向用户提供数据服务。
2. 关键技术
主要包含传统的数据管理领域技术,以及当今比较火热的Hadoop/Spark生态圈提供的各种分布式数据分析、数据挖掘、推荐系统等工具。其中前者相关技术通常来说比较专有化,大都由类似IBM这样的商用软件公司负责,并不具备太多理论研究价值;后者则是这几年大数据领域兴起的产物,一般我们所说的电力大数据,都是和这些技术息息相关。有兴趣的读者可关注Hadoop、Spark生态圈,某种程度上来说,电力大数据就是这些技术在电力行业的应用:

非常有趣的是,上述这两类关键技术所代表的公司近几年开始有了"融合"的趋势。IBM等传统数据领域巨头开始拥抱Hadoop、Spark等开源工具,而一些大数据领域的巨头公司,如阿里云,也开始注重其大数据平台上的元数据管理,主数据管理,数据生命周期等传统数据管理话题。相信不久以后就能看到他们碰撞的火花~(~o ̄▽ ̄)~o
智能电网中的大数据案例:大电网中的居民用电负荷预测
对居民用电负荷做预测是电网公司的经典需求,它能为电网调度中心提供决策支持,能指导发电厂给出指导意见,还有助于电力系统提升安全性和稳定性:比如"重点关照"负荷较大区域的输电设备和线路。这个需求也是现在大数据在电力行业应用得较为成功的一个案例,目前应该有很多乙方公司来做了,但具体的效果如何笔者还不是特别清楚,欢迎同行来和我交流探讨。
该系统的总体思路是对每个用户进行独立预测,最后累加得到各区域或者电网总用电量,总体步骤如下图:
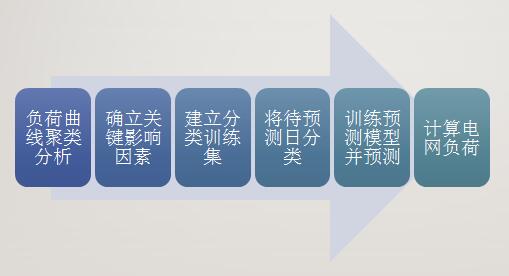
1. 负荷曲线聚类分析
使用聚类技术将各用户用电规律相近的负荷日期归为一类。聚类的特征可设定为和用电有关的所有因素;聚类结束后,应使用可视化的方式观察不同簇内的负荷曲线是不是长得比较像,不是的话请调整簇个数。
PS.系统的研究对象是日负荷曲线而不是用户,这点请读者不要搞混。
2. 确立关键影响因素
采用关联分析(如灰色关联度)的方法确定对负荷影响最大的几个因素。一般来说,气温、风速、雨量等是对负荷的影响比较大。如何提取关键特征是数据挖掘领域一个比较热门的话题,R语言、Ptyhon、Mahout、MLLib都应该有封装好的实现,读者也可前往有关技术交流群和同行进一步交流探讨,本文点到为止。
3. 建立分类训练集
这一步工作将基于1和2的结果产出后面用于预测负荷曲线所属分类的训练集。新的训练集的特征是2中选中的关键特征,标签则是1中日期负荷曲线的聚类结果。
4. 将待预测日分类
提取待遇侧日的关键特征,以3中构建的新训练集为基础进行分类,判断出当前负荷曲线所属类别。好吧,读者有没有发现1-4的过程其实就是一个【无监督在线分类学习】过程。
5. 训练预测模型并预测
选择训练集中待预测日所属分类(4中计算得出)的子集为新训练集,对待预测日的负荷进行回归预测。可考虑采用线性回归、SVR、GBDT等回归算法,而特征依然选定为2中提取出的关键特征。
6. 计算电网负荷
利用Hadoop/Spark大数据平台对所有用户进行预测,并累加得到电网系统的负荷情况。至此,该系统就能预测出未来电网各区域,总区域的总用电负荷。
智能电网中的大数据案例:基于海量红外图像分析的电气设备故障检测
近些年来,越来越多的智能变电站采用智能机器人、无人机进行巡检。这些巡检设备通过高清摄像头、红外摄像头等捕获输变电设备的可见光、红外等设备检测图像。通过对设备红外成像的分析,我们能获知设备各区域的温度情况,进而对设备故障进行分析。
用较为专业的话来说,该系统是"利用非接触式的红外热成像仪实现电器设备的在线监测,获得实时的红外图像,并提取电气设备典型温度数据,在此基础上建立电气设备温度的历史和实时数据库,再结合数据挖掘技术,最终建立电气设备故障诊断与报警自动决策系统"。听起来很流弊(☆゚∀゚)。
其实该系统的总体架构并不算很复杂,如下图所示:
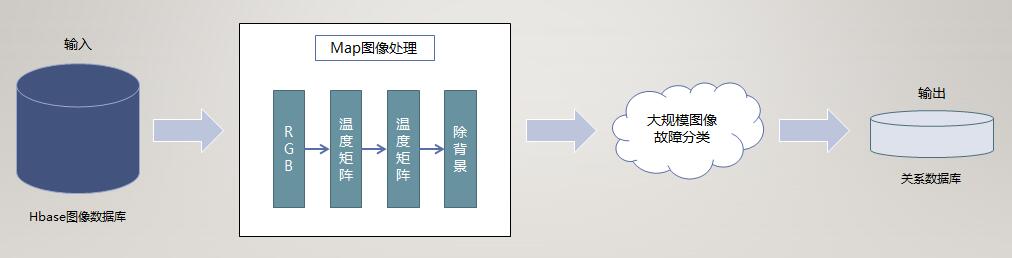
1. 将海量红外图像存放到HBase数据库里。HBase是分布式的NoSQL数据库,是Hadoop生态圈里的标杆项目之一,有关它以及NoSQL数据库介绍请读者自行查阅有关资料。
2. 采用MapReduce的方式访问该数据库,以数据并行化的方式对各个图像进行预处理。这一步将矩阵格式的图像转换为指定规则的向量,并对采用人工方式对其中一部分抽样图像打上标签(正常/故障0/故障1...)。
3. 最后采用神经网络或者SVM等算法对格式化后(未被标记)的红外图像进行故障分类预测。相比于2,这一步的并行可以称之为任务、或者计算并行。
小结
随着科技的不断进步,各种各样的数据(传感器数据、设备数据、用电数据、资产数据......)都将更快更准地汇总到电网的数据中心,构建电网新一代数据工程越来越迫切。说得通俗些,我们将散布在南方五省区域的所有数据汇集起来,形成资产化的管理,直观地可视化分析,对大电网的一切了若指掌,这不是一件很有意义的事情吗?
另一方面,大数据在电力行业的发展很有潜力。据笔者了解,除本文讲到的两个案例,目前电力大数据的应用还有不少,如配电网低电压预测、线损计算分析、乃至电力资产系统、语音投诉系统等。但由于一些传统原因,应用的深度远远不够,电网距离"多指标,自趋优"的终极目标也还很远,同志们仍须努力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号