第四篇:SQL
前言
确实,关于SQL的学习资料,各类文档在网上到处都是。但它们绝大多数的出发点都局限在旧有关系数据库里,内容近乎千篇一律。而在当今大数据的浪潮下,SQL早就被赋予了新的责任和意义。
本篇中,笔者将结合过去在A公司和T公司大数据部门的学习工作经历,对传统SQL语法进行一次回顾性学习。同时,思考这门语言在大数据时代的重要意义。
大数据技术中SQL的作用
SQL的全称为Structured Query Language,也即结构化查询语言。关系数据库中,SQL是用户使用数据库的基本手段,它能用于创建数据库或者关系,能对数据库中各关系进行增删改查,还能对数据库进行维护和管理等等。而随着分布式计算平台如Hadoop,Spark的兴起,SQL的应用范围发生了较大变化,但它作为数据分析核心的地位,始终没有动摇。在新的背景下,SQL语言具有以下新的意义:
1. 管理大型分布式数据仓储系统中的"元仓"
所谓"元仓",可以理解为存放元数据的数据库。关系数据库中叫数据字典(data dictionary),而Hadoop平台的数据仓库工具Hive或Spark平台的Spark SQL则将其称为metastore。在这类分布式的仓储系统里,数据计算都是在分布式平台上进行,但其metastore几乎都是建立在传统的关系数据库(如MySQL)上。
那么元数据又是什么?对大数据计算分析平台重要吗?
举个例子,笔者之前所在的A公司其云计算系统可以说是国内业界最强。在该公司的某个巨型大数据离线计算平台的元仓里,主要存放的元数据有各关系的基本信息(表名列名等),数据血缘及调度依赖关系,数据权限关系,数据资产关系 ,数据监控关系等等,如下图所示:
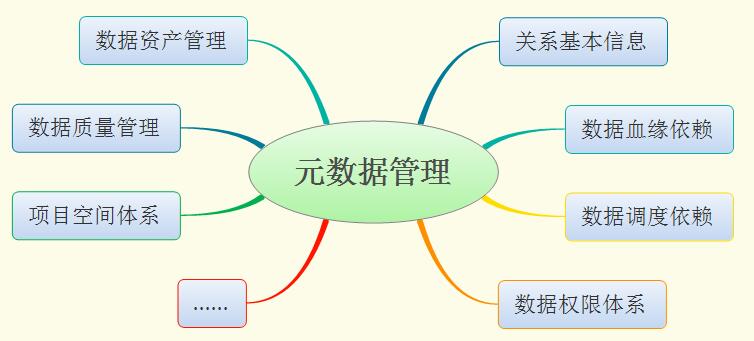
而基于元仓,还可以开发出类似数据地图系统,数据资产管理系统,数据质量工程系统等高级数据管理工具供公司各类开发人员使用。关于这些数据在分布式平台的采集、管理属于一个非常有趣而有挑战的话题,甚至可能是将来云计算发展的一个重要趋势所在。但由于这部分比较多的涉及到商业机密,本文点到为止了。
回到主题,读者想必对元仓的重要性有了感悟。而元仓又是存放在关系数据库里,因此要想管理好元仓,你需要熟练掌握SQL。
2. 操作大数据平台完成数据分析任务
了解大数据技术的童鞋想必清楚,Hadoop平台没有实现数据库,其核心只在于MapReduce编程框架和Hdfs文件系统。但如果每个计算任务都要写MR代码,那是很让人抓狂的。这点很快就被Apache公司注意到,并针对该问题发布了Hive数据仓库工具。这个工具提供一种类SQL的语言,用户能直接使用它进行数据分析,而它则负责将类SQL语言转化为MR代码,提交Hadoop平台执行。Hive在Hadoop生态圈中的意义恐怕不是最大也是最大之一,很多公司甚至就单纯为了使用Hive而搭建的Hadoop环境。所以为了不纠结于分布式代码缩减开发成本,你需要熟练掌握SQL。
3. 在线报表展示
再举个例子,笔者在T公司工作时,在利用大数据分析平台进行数据分析后,最终结果需要提交到在线报表系统以进行可视化展示。但由于数据分析结果的量并不大,同时为了利用关系数据库强一致性等优势,数据分析的结果都要先从大数据平台转入关系数据库,然后让报表系统从关系数据库中取数。所以为了顺利高效的在线发布数据分析结果,你需要熟练掌握SQL。
4. 其他
以上部分仅仅是SQL应用的冰山一角。对于从事数据研发的人来说,无论在什么环境框架下,都可能用到这门语言。以致于有些同事将之戏称为"西阔心经":)。
SQL命令综述
SQL虽然基础重要应用广泛,但学起来却比较容易。记得以前某人跟我说的,想成为一个特级厨师,基本刀功肯定不能差。那么在接下来学习数据仓库,数据挖掘,深度学习等"高大上"技术之前,还是先好好巩固一下"西阔心经"吧。
总的来说,SQL语法可以划分为几大块:
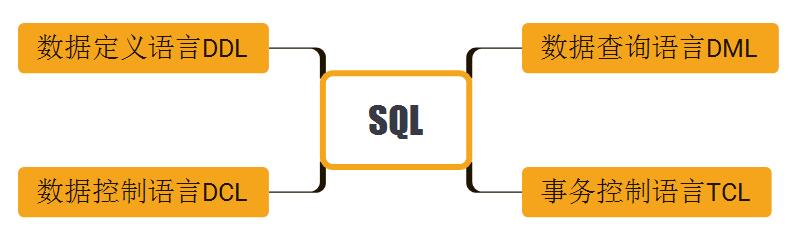
1. 数据定义语言DDL:用于具体实现关系,以及关系附带的一些结构,如索引等;
2. 数据查询语言DML:用于操作数据库,包括增删改查;
3. 数据控制语言DCL:用来帮助实现数据库的存取控制;
4. 事务控制语言TCL:用于数据库中的事务管理;
接下来本文将对几大类的SQL进行讲解,采用回顾总结型的讲解方式,不会涉及过多细节。
DDL
数据定义语言DDL(Data Definition Language)的组成部分并不多,主要涉及到的关键字有:CREATE, ALTER, DROP这三个。
1. CREATE
用于创建数据库,创建关系表,创建视图等。需要注意的是在建表的时候除了表本身,还要定义主外键约束,以及一些附带结构,如索引等。
2. ALTER
用于调整数据库/表/视图的结构信息。
3. DROP
用于删除数据库/表/视图。要注意删除的时候必须先删除外码所在关系,然后再删除被外码参照的主码的关系。
DML
数据查询语言DML(Data Manipulation Language)是SQL的主体成分,SQL的编写工作绝大部分都是在这一块。该部分知识比较杂而多,故本文选择从整体角度,以经验总结的形式进行讲解,相关语法细节请读者查询有关函数手册。
总的来说,DML有以下功能(底层项为功能所涉及关键字):

1. 基本检索
SELECT+WHERE+GROUP BY(聚集函数)+HAVING+ORDER BY是最常用的查询组合,要注意的是如果SELECT搭配了GROUP BY,那么GROUP BY后列也要是SELECT的一部分,这样查询结果才能清楚展示数据是按什么分组的。另一方面,如果使用了GROUP BY,那么出现在SELECT后不使用聚集函数的列必须也出现在GROUP BY里否则系统提示异常。新手常会犯这个错误,如以下代码:
SELECT id, name, count(*) GROUP BY id
name列没有使用聚集函数,且没有出现在GROUP BY后,因此系统必然提示出错。
因此请意识到GROUP BY后面跟了什么列,SELECT后面就单写什么列(不使用聚合函数),出现的其他列则必须使用聚合函数。
此外,HAVING后面跟着的约束对象必须是聚合函数列。虽然感觉是有点重复(聚合函数列写了两次),而且WHERE子句和HAVING子句中都不允许使用列别名...但若不满足这些约束,查询结果会混乱。
2. 高级检索
a) 嵌套查询:嵌套查询的层数尽量不要太高,否则会影响查询效率;
b) 连接查询:注意区分几种JOIN的不同含义;
c) 集合运算:集合运算的本质在于合并多条能"相融"的SQL语句;
3. 插入语句
插入语句的标准形式是INSERT INTO 表名 VALUES(表内容),没有外码的关系要优先执行插入。
4. 更新语句
更新语句的标准形式是UPDATE 表名 SET 列值='XX' WHERE 条件。
5. 删除语句
删除语句的标准形式DELETE FROM 表名 WHERE 条件。注意不要和删除表的命令DROP搞混。
6. 其他关键字
没啥好说的。
DCL & TCL
数据控制语言DCL(Data Control Language)主要是管理数据库权限,负责数据的安全。最常用的是GRANT和ROVOKE命令。
事务控制语言TCL(Transaction Control Language)则主要面向数据库的备份和恢复两大主题,常用命令为COMMIT和ROLLBACK。
小结
SQL的学习并不难,但是如果要在具体环境下写出高质量的SQL,则未必是一件容易的事情。不论是对于传统的关系型数据库,还是分布式仓储系统如Hive、Spark SQL,SQL的优化都可以再单独写一本书了。最好在明确了要长期使用的数据分析平台后,再深入针对性地学习专有SQL。比如选定了用Hive,那么就要狠下功夫研究怎么写SQL才能避免"数据倾斜"问题。
最后,一个优秀的厨师,基本刀功不会差;一个卓越的数据分析师,SQL功底也不会含糊。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号