

1. 基本信息

标题: ConDSeg: A General Medical Image Segmentation Framework via Contrast-Driven Feature Enhancement (ConDSeg: 一个经过对比驱动特征增强的通用医学图像分割框架)
论文来源:https://arxiv.org/pdf/2412.08345
2. 核心创新点
一致性强化 (CR) 训练策略: 提出一种两阶段训练策略,第一阶段利用强制模型对原图和强增强图像的输出保持一致,显著提升编码器在弱光、低对比度等恶劣环境下的特征提取鲁棒性。
语义信息解耦 (SID) 模块: 设计了一个能将特征图解耦为前景、背景和不确定性区域三个部分的模块。通过专门设计的损失函数,模型在训练中学会逐步减少不确定性,从而更清晰地区分前景与背景。
对比驱动特征聚合 (CDFA) 模块: 利用 SID 模块解耦出的前景和背景特征作为对比信息,指导多层次特征的融合与关键特征的增强,进一步强化目标与困难背景的区分度。
尺寸感知解码器 (SA-Decoder): 针对医学图像中普遍存在的共生现象(co-occurrence),设计了多个并行的、专注于不同尺寸目标的解码器,有效避免模型学习到错误的上下文关联,提高对独立出现病灶的识别准确率。
➔➔➔➔点击查看原文,获取本文及其他精选即插即用模块集合![]() https://mp.weixin.qq.com/s/aiF0bwZ1Z2LyDE4ZOyOYVQ
https://mp.weixin.qq.com/s/aiF0bwZ1Z2LyDE4ZOyOYVQ
3. 手段详解
整体结构概述: ConDSeg 是一个两阶段的分割框架。第一阶段,采用一致性强化 (CR)策略预训练编码器,以增强其在多变环境下的鲁棒性。第二阶段,将预训练好的编码器以较低学习率整合到完整网络中进行微调。完整网络由一个 ResNet-50 编码器、语义信息解耦 (SID) 模块、多个对比驱动特征聚合 (CDFA) 模块以及尺寸感知解码器 (SA-Decoder)组成。数据流先通过编码器提取多层次特征,然后顶层特征被送入 SID 模块解耦为前景、背景和不确定性信息;接着,这些对比信息被注入到 CDFA 模块中,引导各层级特征的聚合与增强;终于,增强后的特征被送入不同尺寸的 SA-Decoder 进行并行预测,融合成最终的分割结果。
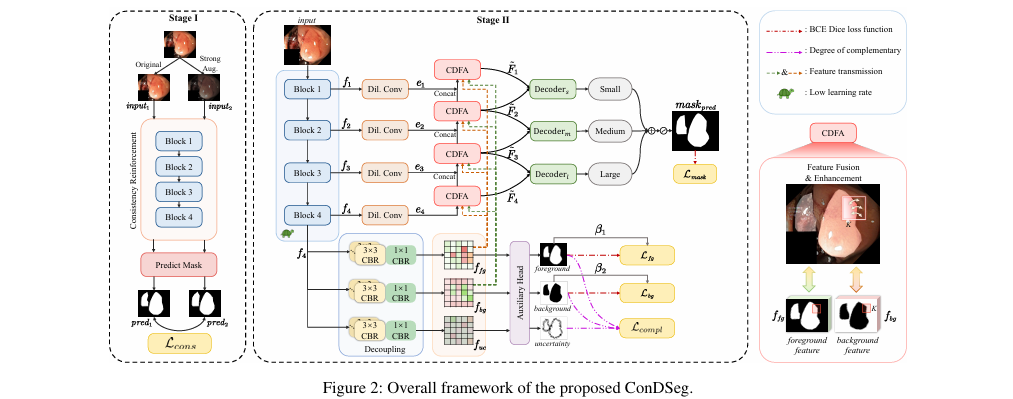
步骤分解:
- 第一阶段:一致性强化 (CR)
目的:提升编码器在弱光、低对比度等场景下的鲁棒性。
方法:将原始图像
X和经过强数据增强(如亮度、对比度、色调变换)的图像X'分别输入编码器和辅助预测头,得到两个预测结果M1和M2。优化:不仅要求
M1和M2逼近真实标签,还通过一个一致性损失函数L_cons来最大化它们之间的相似度,确保编码器对内容本身的特征提取不受外部环境变化的干扰。一致性损失
L_cons定义如下,它交替将一个输出二值化作为“伪标签”来监督另一个输出:
- 第二阶段:整体网络微调
- 语义信息解耦 (SID):
接收编码器最深层的特征
f4,通过三个并行分支将其解耦为前景特征f_fg、背景特征f_bg和不特定区域特征f_uc。通过一个辅助头和专门的损失函数进行约束。优化目标是让前景和背景预测分别逼近标签
Y和1-Y,同时三者满足互补关系,即每个像素点只属于三者之一。互补性关系理想上应满足:
为实现此目标,设计了互补性损失
L_compl:同时,引入动态惩罚项
β,对小目标区域的损失进行加权,以提高模型对小尺寸实体的关注度。
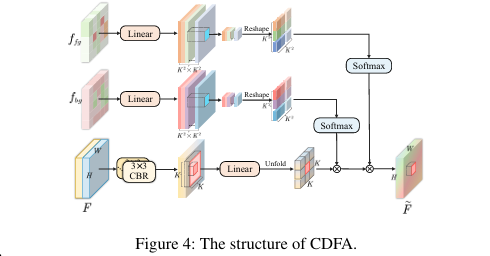
- 对比驱动特征聚合 (CDFA):
该模块接收来自编码器的各层级特征,并利用 SID 输出的前景特征
f_fg和背景特征f_bg作为对比引导。其核心思想是:利用
f_fg和f_bg生成两组独立的注意力权重,依次作用于特征图的局部窗口,从而实现对前景和背景信息的差异化增强和聚合。
- 语义信息解耦 (SID):
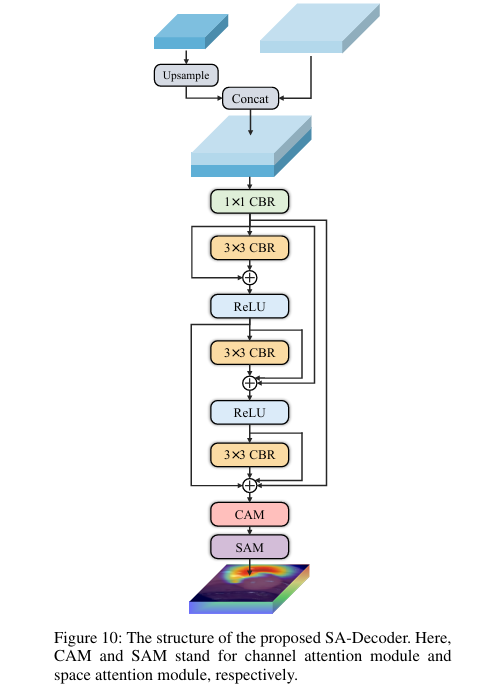
- 尺寸感知解码器 (SA-Decoder):
为解除共生现象导致的误判,设计了三个独立的解码器,分别负责小、中、大尺寸目标的分割。
Decoder_s接收较浅层的特征,Decoder_m和Decoder_l则接收更深层的特征,利用不同层级特征对不同尺寸目标的感知能力差异进行解耦。最终将三个解码器的输出融合,得到最终分割结果。
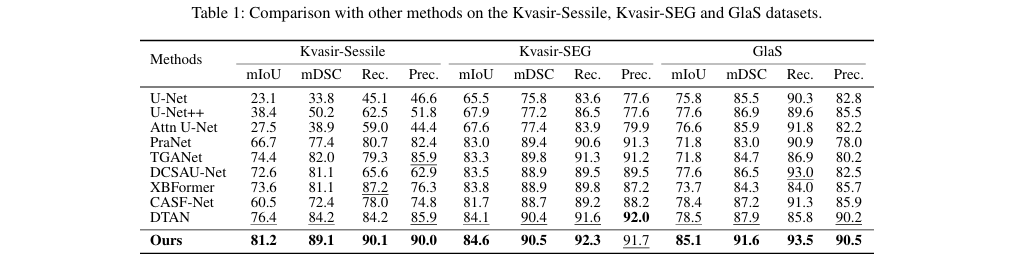
实验结果:
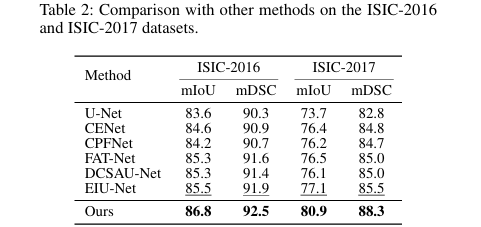
在 Kvasir-SEG、Kvasir-Sessile、GlaS、ISIC-2016、ISIC-2017 五个公开数据集上,ConDSeg 均取得了当前最优(SOTA)性能。
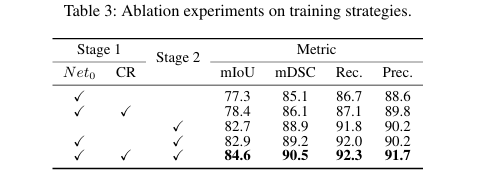
消融实验验证了 CR 策略、SID、CDFA 和 SA-Decoder 各个模块的有效性。

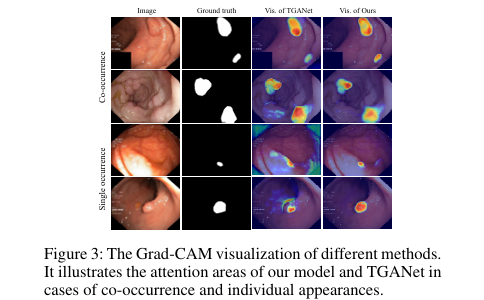
Grad-CAM 可视化结果表明,相比其他模型,ConDSeg 能有效避免共生现象的干扰,在病灶单独出现时也能准确定位。
4. 即插即用模块作用
本报告将整个ConDSeg 框架视为一个可用于医学图像分割任务的解决方案。
适用场景
- 医疗影像分割任务:
内窺鏡图像分割(如:结肠息肉分割)
皮肤镜图像分割(如:皮肤病变、黑色素瘤分割)
数字病理切片图像分割(如:腺体分割)
多类别3D图像分割(如:腹部多器官分割,需进行2D切片化处理)
- 行业场景:
临床辅助诊断
计算机辅助治疗规划
疾病自动监测与跟踪
主要作用
提升模型鲁棒性: 通过一致性强化训练,使模型能有效应对医学图像中常见的光照不均、对比度低、图像模糊等问题。
增强边界区分能力: 通过语义解耦和对比驱动聚合,模型能更精确地识别前景与背景之间的“软边界”,减少分割错误。
克服共生现象干扰: 依据尺寸感知解码器,模型不再依赖目标间的共生关系进行判断,显著降低了在目标单独出现时的漏检和误检率。
实现SOTA性能: 在多个标准数据集上超越了现有主流分割模型,证明了其先进性和泛化能力。
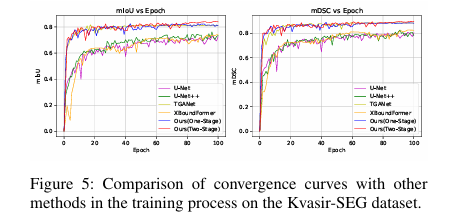
加速模型收敛: 两阶段训练策略不仅提升了最终性能,也加快了模型的收敛速度。
总结
一个依据解耦前景、背景和不确定性信息,并利用对比驱动机制来指导特征学习的分割新范式,它精准打击了医学图像分割中“边界模糊”和“共生陷阱”两大痛点。就是ConDSeg
➔➔➔➔点击查看原文,获取本文及其他精选即插即用模块集合![]() https://mp.weixin.qq.com/s/aiF0bwZ1Z2LyDE4ZOyOYVQ
https://mp.weixin.qq.com/s/aiF0bwZ1Z2LyDE4ZOyOYVQ
5. 即插即用模块
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
class CBR(nn.Module):
def __init__(self, in_c, out_c, kernel_size=3, padding=1, dilation=1, stride=1, act=True):
super().__init__()
self.act = act
self.conv = nn.Sequential(
nn.Conv2d(in_c, out_c, kernel_size, padding=padding, dilation=dilation, bias=False, stride=stride),
nn.BatchNorm2d(out_c)
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
if self.act == True:
x = self.relu(x)
return x
class ContrastDrivenFeatureAggregation(nn.Module):
def __init__(self, in_c, dim, num_heads, kernel_size=3, padding=1, stride=1,
attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.kernel_size = kernel_size
self.padding = padding
self.stride = stride
self.head_dim = dim // num_heads
self.scale = self.head_dim ** -0.5
self.v = nn.Linear(dim, dim)
self.attn_fg = nn.Linear(dim, kernel_size ** 4 * num_heads)
self.attn_bg = nn.Linear(dim, kernel_size ** 4 * num_heads)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.unfold = nn.Unfold(kernel_size=kernel_size, padding=padding, stride=stride)
self.pool = nn.AvgPool2d(kernel_size=stride, stride=stride, ceil_mode=True)
self.input_cbr = nn.Sequential(
CBR(in_c, dim, kernel_size=3, padding=1),
CBR(dim, dim, kernel_size=3, padding=1),
)
self.output_cbr = nn.Sequential(
CBR(dim, dim, kernel_size=3, padding=1),
CBR(dim, dim, kernel_size=3, padding=1),
)
def forward(self, x, fg, bg):
x = self.input_cbr(x)
x = x.permute(0, 2, 3, 1)
fg = fg.permute(0, 2, 3, 1)
bg = bg.permute(0, 2, 3, 1)
B, H, W, C = x.shape
v = self.v(x).permute(0, 3, 1, 2)
v_unfolded = self.unfold(v).reshape(B, self.num_heads, self.head_dim,
self.kernel_size * self.kernel_size,
-1).permute(0, 1, 4, 3, 2)
attn_fg = self.compute_attention(fg, B, H, W, C, 'fg')
x_weighted_fg = self.apply_attention(attn_fg, v_unfolded, B, H, W, C)
v_unfolded_bg = self.unfold(x_weighted_fg.permute(0, 3, 1, 2)).reshape(B, self.num_heads, self.head_dim,
self.kernel_size * self.kernel_size,
-1).permute(0, 1, 4, 3, 2)
attn_bg = self.compute_attention(bg, B, H, W, C, 'bg')
x_weighted_bg = self.apply_attention(attn_bg, v_unfolded_bg, B, H, W, C)
x_weighted_bg = x_weighted_bg.permute(0, 3, 1, 2)
out = self.output_cbr(x_weighted_bg)
return out
def compute_attention(self, feature_map, B, H, W, C, feature_type):
attn_layer = self.attn_fg if feature_type == 'fg'else self.attn_bg
h, w = math.ceil(H / self.stride), math.ceil(W / self.stride)
feature_map_pooled = self.pool(feature_map.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
attn = attn_layer(feature_map_pooled).reshape(B, h * w, self.num_heads,
self.kernel_size * self.kernel_size,
self.kernel_size * self.kernel_size).permute(0, 2, 1, 3, 4)
attn = attn * self.scale
attn = F.softmax(attn, dim=-1)
attn = self.attn_drop(attn)
return attn
def apply_attention(self, attn, v, B, H, W, C):
x_weighted = (attn @ v).permute(0, 1, 4, 3, 2).reshape(
B, self.dim * self.kernel_size * self.kernel_size, -1)
x_weighted = F.fold(x_weighted, output_size=(H, W), kernel_size=self.kernel_size,
padding=self.padding, stride=self.stride)
x_weighted = self.proj(x_weighted.permute(0, 2, 3, 1))
x_weighted = self.proj_drop(x_weighted)
return x_weighted
if __name__ == '__main__':
cdfa =ContrastDrivenFeatureAggregation(in_c=128, dim=128, num_heads=4)
# 输入特征图
x = torch.randn(1,128,32,32)
# 前景特征图
fg = torch.randn(1,128,32,32)
# 背景特征图
bg = torch.randn(1,128,32,32)
# 打印网络结构
print(cdfa)
#前向传播,输入张量x,fg,和bg
output = cdfa(x,fg,bg)
#打印输出张量的形状
print("input shape:", x.shape)
print("output shape:", output.shape)
 浙公网安备 33010602011771号
浙公网安备 33010602011771号