

除了革命性的 Bank Group 和全面的 RASR 功能,DDR4 还引入了其他多项关键技术,这些手艺共同支撑了其在频率、容量、功耗和信号完整性上的飞跃。
点对点拓扑与 DBI 技术
DDR3 及之前的标准通常支撑多通道(Multi-Drop)总线拓扑,即一个内存控制器通道连接多个内存条插槽。当频率提升到 DDR4 的水平时,这种拓扑会导致严重的信号完整性问题,如反射、振铃和串扰,限制了频率的进一步提升。
点对点拓扑:DDR4 为每个内存控制器通道采用了点对点 的连接方式。每个通道只连接一个内存条。在单通道系统中,就是一个通道连接一个DIMM;在双通道或四通道系统中,每个通道依然只连接一个DIMM。这极大地简化了信号路径,减少了阻抗不连续点,为高频信号供应了更干净的环境。
数据总线反转:这是一项信号完整性增强技术。在数据传输时,如果发现当前待传输的8位数据中,有超过4个位是‘1’(即高电平),DBI 电路会将整个字节反转(所有位取反),并置位 DBI 引脚,通知接收端。这样,总线上就有更多的‘0’(低电平),从而减少同时翻转的比特数。
1. 降低功耗:驱动低电平(‘0’)所需的电流通常小于高电平(‘1’)。
2. 改善信号完整性:减少同时翻转的比特数可以降低总线上的开关噪声和地弹噪声。
3. 简化接收端设计:由于‘0’的数量更多,数据眼图(Data Eye)的张开度可能更好。
分离的命令与地址总线
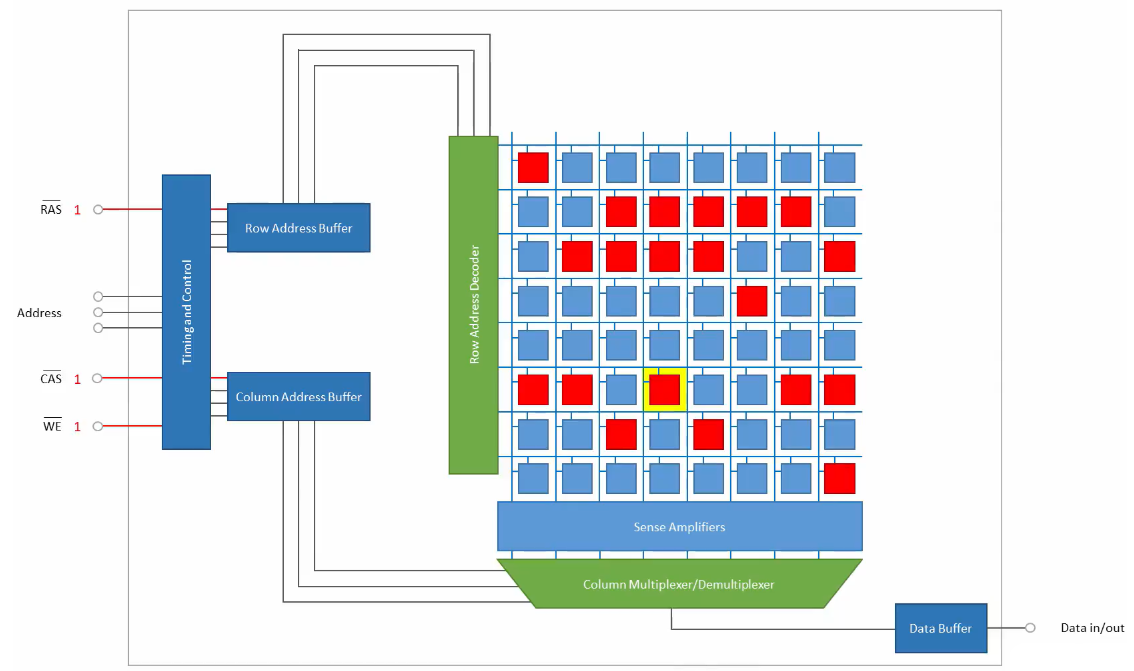
在DDR3中,命令和地址信号是共享同一组引脚,并在不同的时钟边沿被锁存。到了高频时代,这种时序控制变得非常苛刻。DDR4 引入了一个独立的 命令/地址总线时钟。
命令和地址信号现在拥有自己专用的时钟对(CK_t / CK_c)。所有CA信号都与这个CA时钟同步,简化了时序对齐的要求。
◦ 提高了命令/地址信号的速率和可靠性,使其能跟上核心数据速率的发展。
◦ 降低了主板布线的复杂性和控制器设计的难度。
◦ 这也是实现命令/地址奇偶校验的基础。
同时,为了减小Bank Group对性能的影响,借助合理的地址映射策略,可能有效地减少tCCD_L(Long Column to Column Delay)对DDR4性能的影响。tCCD_L是在同一个Bank Group内部进行连续列访问时的等待时间,通常比tCCD_S(Short Column to Column Delay)长,因此优化地址映射策略可以减少这种等待时间,提高内存系统的性能。
补充前文的Bank Group技术,详细解释几种有效的地址映射策略:
分散内存访问
交错地址映射:通过交错地址映射,将连续的内存地址分散到不同的Bank Group中,减少在同一Bank Group内的连续访问。
列地址使用最低位(实现缓存行内的顺序访问),Bank和Bank Group地址利用中间位(实现跨存储体的交织),行地址使用最高位(大块数据在同一行内);假设一个常见的8Gb DDR4芯片。注意列地址低10位,通常具备自动预充电位,并且突发传输会覆盖整个缓存行(通常64字节,所以列地址的低6位用于缓存行内字节选择,但假设大家按整体列地址看)。实际DDR4控制器的映射比该例子复杂得多,会考虑内存通道、Rank、芯片位宽等多种因素,但都遵循相同的"交织"设计哲学。
地址格式:
列地址选择:占用地址的最低位(例如 A[9:0]),用于定位Cache Line内的字节。
Bank地址选择:占用中间低位(例如 A[11:10])。
Bank Group地址选择:占用中间位(例如 A[13:12])。
行地址选择:占用高位(例如 A[29:14]),行地址,16位。
Rank选择:可能用于选择不同的Rank或芯片(例如 A[31:30])。地址映射:
地址 0x00000000 映射到 Bank Group 0, Bank 0, 行 0, 列 0。
地址 0x00000001 映射到 Bank Group 0, Bank 0, 行 0, 列 1。
地址 0x00000002 映射到 Bank Group 0, Bank 0, 行 0, 列 2。
...
地址 0x00001000 映射到 Bank Group 1, Bank 0, 行 0, 列 0。
地址 0x00001001 映射到 Bank Group 1, Bank 0, 行 0, 列 1。
...
依据这种方式,连续的内存访问会被分散到不同的Bank Group中,减少在同一Bank Group内的连续访问,从而减少tCCD_L的影响。实现了优秀的交织:注意,Bank Group地址夹在行地址和Bank地址之间。当你顺序增加内存地址时,假设A[12]位会频繁地在0和1之间切换。这导致你的顺序访问请求会自动地、交替地发送到Bank Group 0和Bank Group 1。这正是DDR4提升性能的关键——最大化Bank Group级别的并行性。
核心要点记住:真实的DDR4地址映射是复杂的,并且因平台而异,但其核心设计哲学是使用地址的中间位来选择Bank和Bank Group,以建立访问的均匀分布(交织)。行地址使用高位(多位),列地址使用低位。
优化数据布局
数据分块:将数据分成多个小块,每个小块分布在不同的Bank Group中。
将一个大的数据结构(如数组、矩阵)分成多个小块,每个小块分配到不同的Bank Group中。 假设有一个1024x1024的矩阵,允许将其分成4个256x256的小块,每个小块分配到一个不同的Bank Group中。
矩阵分块:
小块1(0-255, 0-255)分配到Bank Group 0。
小块2(0-255, 256-511)分配到Bank Group 1。
小块3(0-255, 512-767)分配到Bank Group 2。
小块4(0-255, 768-1023)分配到Bank Group 3。
通过这种方式,访问矩阵的不同部分时,可以利用多个Bank Group的并行操作能力,提高性能。
减少跨Bank Group的跳转
局部性优化:尽量访问相邻的内存地址,减少跨Bank Group的跳转。
通过依据优化数据访问模式,确保连续的访问尽可能在同一个Bank Group内完成。 假设有一个数组,能够通过循环访问数组的元素。为了减少跨Bank Group的跳转,能够优化循环的步长,确保每次访问的元素尽可能在同一个Bank Group内。
//假设数组长度为1024,Bank Group大小为256
for(int i = 0; i < 1024; i += 4){
//访问相邻的4个元素
int a = array[i];
int b = array[i + 1];
int c = array[i + 2];
int d = array[i + 3];//处理a,b,c,d
}通过这种方式,可以减少跨Bank Group的跳转。虽然tCCD_S较短,但频繁的跨Bank Group跳转仍然会增加额外的等待时间,影响内存访问的效率。
当然,这也离不开更高的密度与更先进的制造工艺
单颗芯片容量:DDR4 规范支持更高的单颗芯片密度,从 2Gb 到 16Gb,甚至 32Gb。这使得单条内存条的容量可以轻松达到 32GB、64GB,甚至 128GB(凭借3D堆叠),满足了大数据和云计算时代对海量内存的需求。
制造工艺:DDR4 颗粒普遍采用更先进的半导体工艺(如20nm级别)制造,这有助于在降低功耗和成本的同时,集成更多的晶体管和功能(如片上温度传感器)。
在基础层面也致力于降低功耗
核心电压降低:从 DDR3 的1.5V 降至 1.2V。这是最直接的功耗降低手段(功耗与电压的平方成正比)。
VPP 电压:DDR4 引入了一个独立的2.5V VPP电源,专门用于驱动字线(Wordline)的激活。这比使用核心电压(1.2V)来驱动效率更高,可以加快激活和预充电速度,从而在一定程度上降低延迟和功耗。
片上端接的优化:ODT 技术在DDR4中更加灵活,可以针对不同的操作模式(读、写、空闲)动态调整终端电阻值,以在信号完整性和功耗之间取得最佳平衡。
DDR4的这些技术并非孤立存在,而是相互关联、协同工作的。例如,没有点对点拓扑和DBI技术,Bank Group的高频率就无法实现;没有分离的CA总线,强大的RASR功能(如CA奇偶校验)也就无从谈起。正是这一整套技术的集体进化,才使得DDR4成为一代成功的内存标准,并为后续的DDR5奠定了基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号