project3
Query Execution
忙里偷闲终于把p3搞完啦,感觉这个project很有意思,做完后基本把一条sql的执行流程串通了。对于像我这种数据库小白来说,加深了对经典pull-base火山模型的理解。下面开始记录记录自己的实现历程~
前言
刚开始这个project时,我还是花了不少时间看代码,梳理下大体的执行流程。课程网站上有BusTub的架构图,这里贴下与p3相关的部分。可以看出一条sql语句进来后,会经过Parser->Binder->Planner->Optimizer->Executors几个阶段,最后生成一颗executor算子树。结合课上的ppt,个人理解每个阶段的功能是:
- Parser:根据sql语句生成一颗抽象语法树(Abstract Syntax Tree)
- Binder:结合数据库的元信息,将抽象语法树转成一个具有库表信息的语义语法树
- Planner:根据语义语法树生成逻辑执行计划树,也叫查询计划
- Optimizer:根据某些优化规则,重写等价的查询计划
- Executors:根据查询计划,生成具体的算子执行树
纸上得来终觉浅,以上流程可以通过阅读bustub_instance.cpp文件中BustubInstance::ExecuteSql函数串一起。在理解了整体流程后,会发现最终的执行就是通过不断调用算子执行树根节点的Next函数来获取数据结果,p3主要做的就是实现各种executor算子。
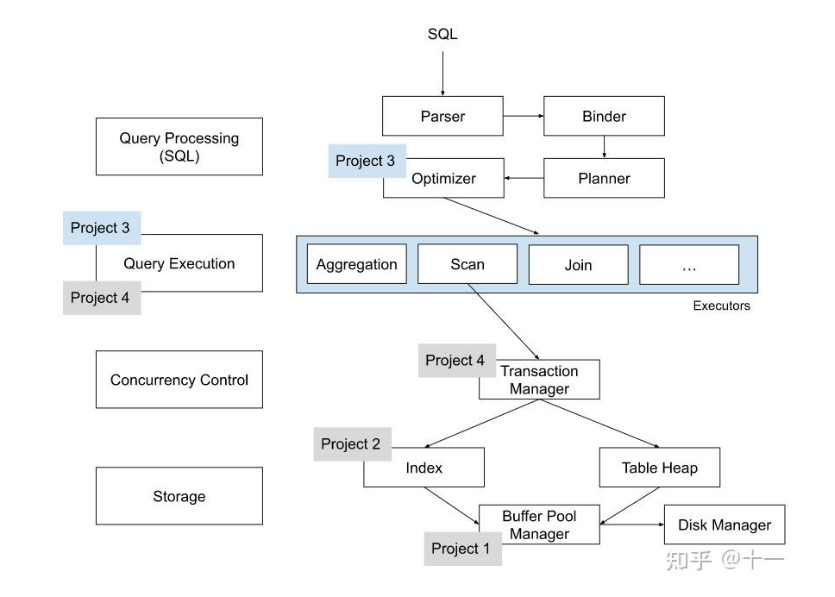
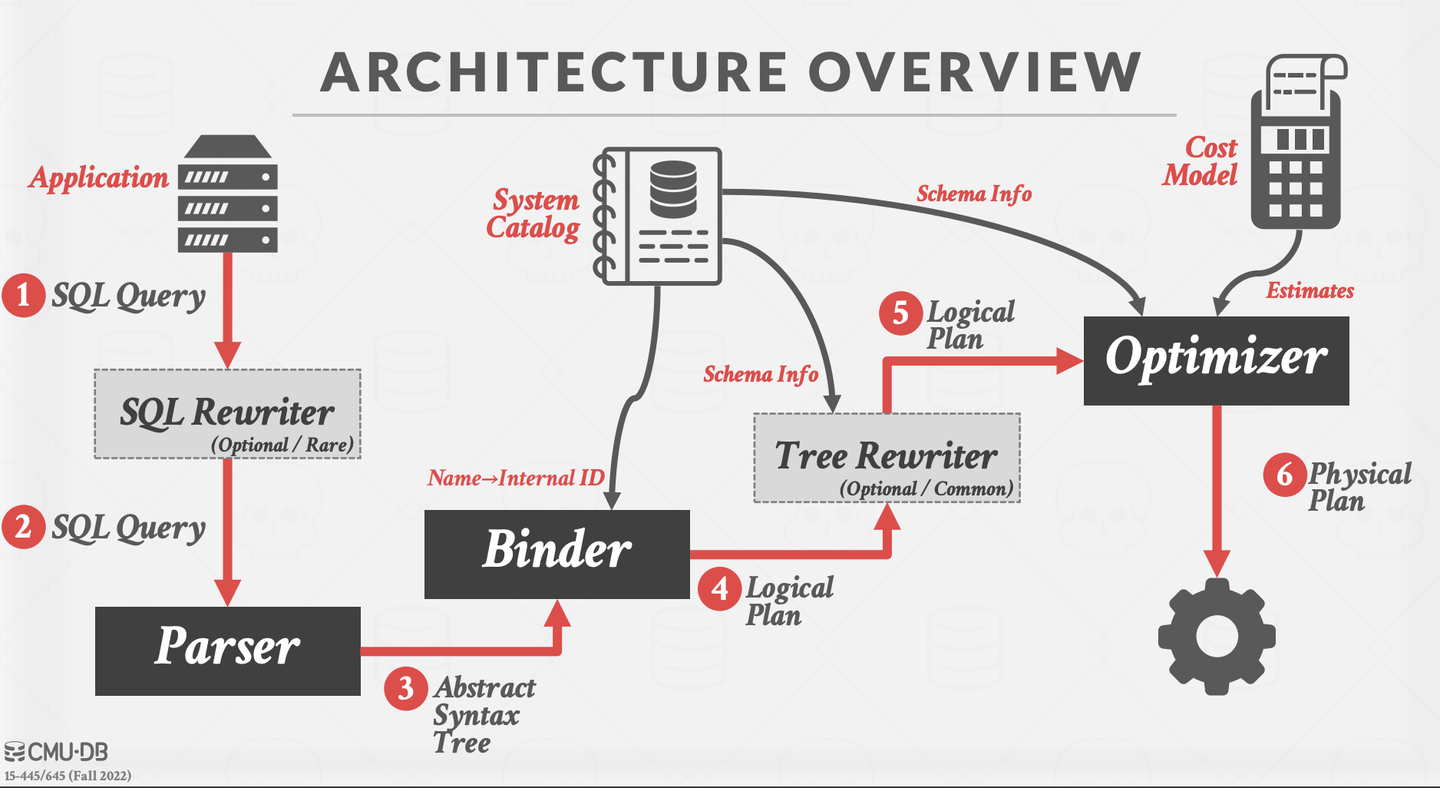
这是课程官网的一张图,清晰地介绍了 Bustub 的整体架构。在 Project 3 中,我们需要实现一系列 Executors,以及为 Optimizer 添加新功能。
- Task1:Access Method Executors. 包含 SeqScan、Insert、Delete、IndexScan 四个算子。
- Task2:Aggregation and Join Executors. 包含 Aggregation、NestedLoopJoin、NestedIndexJoin 三个算子。
- Task3:Sort + Limit Executors and Top-N Optimization. 包含 Sort、Limit、TopN 三个算子,以及实现将 Sort + Limit 优化为 TopN 算子。
- Leaderboard Task:为 Optimizer 实现新的优化规则,包括 Hash Join、Join Reordering、Filter Push Down、Column Pruning 等等,让三条诡异的 sql 语句执行地越快越好。
算子实现
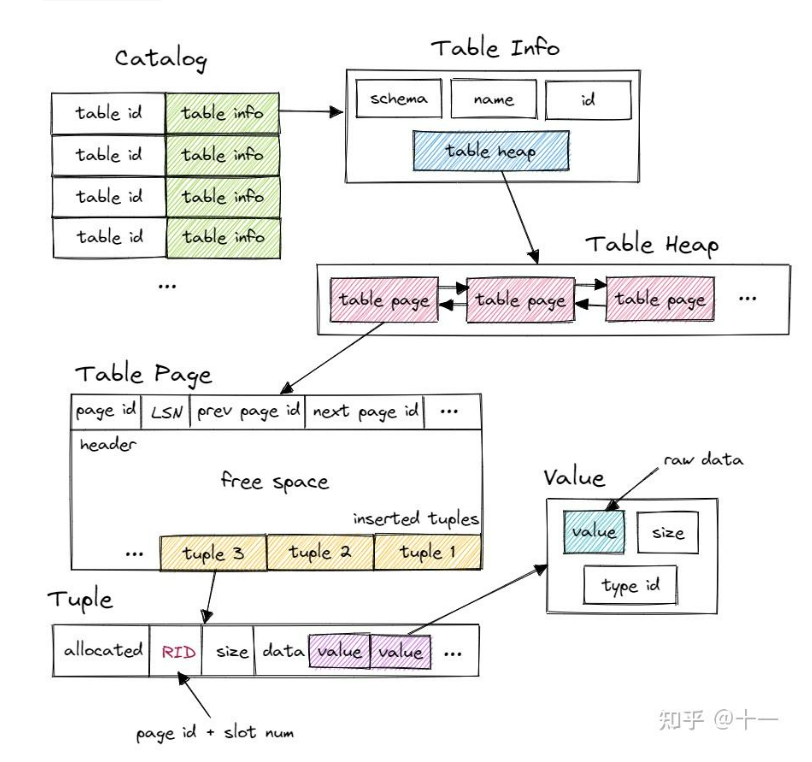
每个算子主要实现Init函数和Next函数,下面记录一下自己实现的一些理解把。
SeqScanExecutor
这个比较简单,在Init阶段从ExecutorContext的GetCatalog中拿到遍历table的迭代器,在Next阶段使用迭代器遍历并返回结果。
InsertExecutor
插入的时候还需考虑表是否建有索引,若有索引还得同步更新索引信息。所以在Init阶段去拿table和索引信息,在Next阶段调用TableHeap的InsertTuple新增tuple;若有索引信息,调用上projcet实现的InsertEntryt添加索引信息。
DeleteExecutor
和插入类似,在Init阶段拿table和索引信息,在Next阶段调用TableHeap的MarkDelete删除tuple和调用DeleteEntry删除索引信息。
IndexScanExecutor
在Init阶段拿到索引树的迭代器,然后在Next阶段使用迭代器遍历并返回结果。注意的是,这里迭代器返回的只是一个RID(page_id + slot_num),所以还得通过RID去找到对应的tuple,这里也是通过TableInfo中TableHeap的GetTuple来操作。
AggregationExecutor
实现该算子前,要先理解已提供SimpleAggregationHashTable类的作用,其实就是通过unordered_map来完成对数据的聚合。先实现好SimpleAggregationHashTable中的CombineAggregateValues函数,这里可以多看下Value类的代码,Value已经支持了add、max、min等函数操作,需要时直接调用就行。
在AggregationExecutor的Init阶段,通过遍历child算子提前聚合好数据,完成对SimpleAggregationHashTable的构建,记录好相关迭代器,然后在Next阶段通过迭代器遍历SimpleAggregationHashTable并返回结果。其中注意一下官网上说的一些边界条件,如空表输出格式等。
NestedLoopJoinExecutor
个人觉得在这个project中,Join有两种实现:一种是在Init阶段提前把Join结果生成了并用vector保存着,在Next阶段直接遍历vector并返回结果。因为测试的数据量不大,数据能全存内存,所以该方法可行且实现简单。另一种是在Next阶段才去遍历左表和和右表的数据,然后比较完再返回结果。第二种方式不需要考虑数据量能否全存内存,但会写的比较复杂,因为要记录好上一次调用Next时左表和右表的遍历状态。两种方式我都实现了,但后续为了优化hash join的速度,用第一种比较方便,所以这里我只说第一种方式把。
在Init阶段,通过两个while循环遍历左右表提前生成好结果集,然后在Next阶段通过迭代器返回结果即可。需注意右表遍历完要重新调用其子算子的Init函数,也注意下left_join输出的schema格式。
NestIndexJoinExecutor
当join的右表带有索引,并且join的条件命中右表索引key时,可以通过查看左表数据是否命中右表索引来加快join结果生成,因此有了NestIndexJoinExecutor,具体可以看OptimizeNLJAsIndexJoin函数的实现。
在NestIndexJoinExecutor的Init阶段,遍历child算子看结果是否命中索引树,从而构造好结果集。在Next阶段通过迭代器返回结果。
SortExecutor
我是自定义了一个数据结构保存如下,order_keys保存需排序的键,tuple保存从child算子得到的完整结果。在Init阶段遍历child算子,为每个结果tuple生成一个OrderKeyWithTuple,并用vector存起来。接着自定义一个cmp比较函数,对vector进行排序。在Next阶段,通过迭代器返回vector结果。
struct OrderKeyWithTuple {
std::vector<Value> order_keys_;
Tuple tuple_;
};
LimitExecutor
这个比较简单,在Next阶段发现输出数量已大于limit时返回false即可。
TopNExecutor
这里需先实现优化计划OptimizeSortLimitAsTopN,简单来说就是当LimitPlanNode后面是SortPlanNode时,就合并成TopNPlanNode并返回。
TopNExecutor的实现与SortExecutor类似,只是在Init阶段用priority_queue来存OrderKeyWithTuple。
其他
- 每个算子在Init时,也把定义的成员变量重新初始化。因为像NestedLoopJoinExecutor的实现会多次调用child算子的Init。
- 对于table相关的信息,可以多看看GetCatalog中提供的函数,很多能直接使用。
- 多参考已有代码的实现,如FilterExecutor的实现,ValueFactor的使用等。
- 多看看官网的实现要求,注意下每个算子输出的schema,有利于理解实现。
查询计划优化
实现完算子开始尝试做查询优化打榜了。这里讲讲自己的优化思路把,有点面向用例来优化,可能会缺少一些普适性,不过官网也说不用实现完备的优化~
Query 1
语句:
create table t1_50k(x int, y int);
create index t1x on t1_50k(x);
explain select count(*), max(t1_50k.x), max(t1_50k.y), max(__mock_t2_100k.x), max(__mock_t2_100k.y), max(__mock_t3_1k.x), max(__mock_t3_1k.y) from (
t1_50k inner join __mock_t2_100k on t1_50k.x = __mock_t2_100k.x
) inner join __mock_t3_1k on __mock_t2_100k.y = __mock_t3_1k.y;
优化点有两个:
- 本着join左表应该是小表的原则,因为t3表就1k,优先让t3表和t2表进行join操作,如下图优化1所示。
- 实现HashJoin替换NestedLoopJoin。由于join顺序重排后,t1表为右表且带有索引,所以还会进一步优化成NestedIndexJoin,最终查询计划如下图优化2所示。
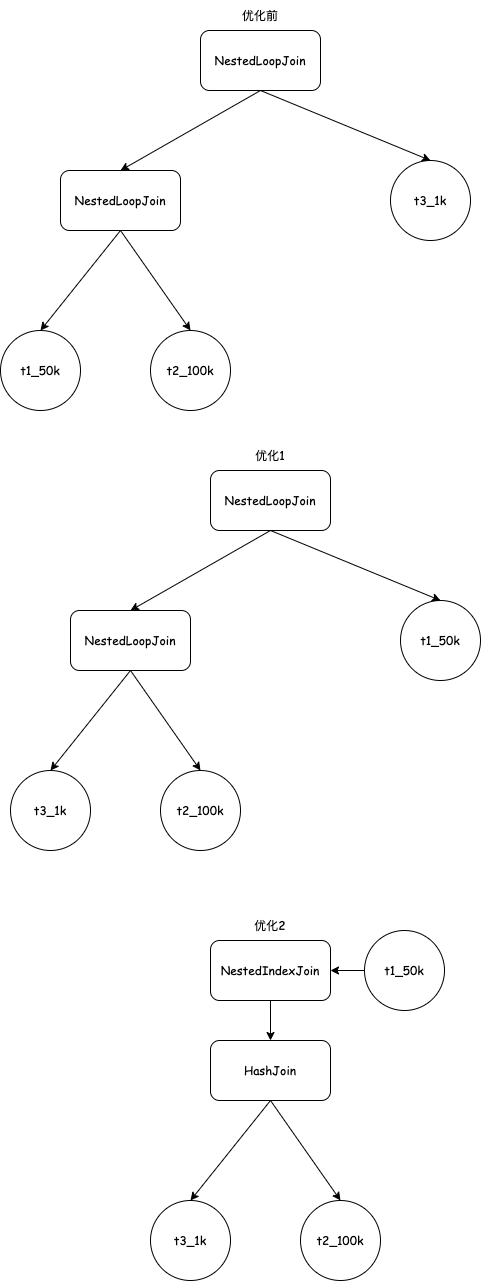
实现上,首先实现了一个OptimizeReorderJoin优化,将t3与t1交换。这里用到了提供的EstimatedCardinality函数来判断表数量的大小,里面其实就是根据表名来判断的。具体实现比较麻烦的就是怎么重写join中的predicate,因为join表顺序变了,predicate中表达式的索引也变了。
接着是实现HashJoinExecutor算子。我是用一个unordered_multimap来构建hash_table,其中key的hash可以参考SimpleAggregationHashTable中AggregateKey的实现。HashJoinExecutor的实现就是在Init阶段,先遍历左子算子生成hash_table,然后遍历右子算子来probe hash_table,提前生成好结果集。在Next阶段通过迭代器返回结果集。
这里还有一点注意的是,优化前查询计划输出的schema应该是t1_t2_t3,但是优化后会输出t3_t2_t1。当join都是inner join,我在join算子里做了些判断,如果左子算子的schema不在outputschema的左边,就在输出tuple时交换左右表的tuple,以保证ouputschema与输出tuple顺序一致。但是在没做这个改动之前测试好像也能通过,有点迷惑,需找时间再细看。
Query 2
语句
select count(*), max(__mock_t4_1m.x), max(__mock_t4_1m.y), max(__mock_t5_1m.x), max(__mock_t5_1m.y), max(__mock_t6_1m.x), max(__mock_t6_1m.y)
from (select * from __mock_t4_1m, __mock_t5_1m where __mock_t4_1m.x = __mock_t5_1m.x), __mock_t6_1m
where (__mock_t6_1m.y = __mock_t5_1m.y)
and (__mock_t4_1m.y >= 1000000) and (__mock_t4_1m.y < 1500000) and (__mock_t6_1m.x < 150000) and (__mock_t6_1m.x >= 100000);
这里优化点也有两个:
- 优化前,即使使用了HashJoin,顶层也有一个NestedLoopJoin不能优化成HashJoin,因为该Join中还有很多过滤条件。第一个优化点就是把过滤条件下推,一个是为了减少scan表的数量,一个是为了让顶层NestedLoopJoin也优化成HashJoin,如下图优化1所示。
- 从过滤条件来看,t6表过滤的范围大小是50000,t4表过滤范围大小是500000,本着join左表是小表的原则,可以优先让t6表和t5表先join,最终查询计划优化成下图优化2所示。
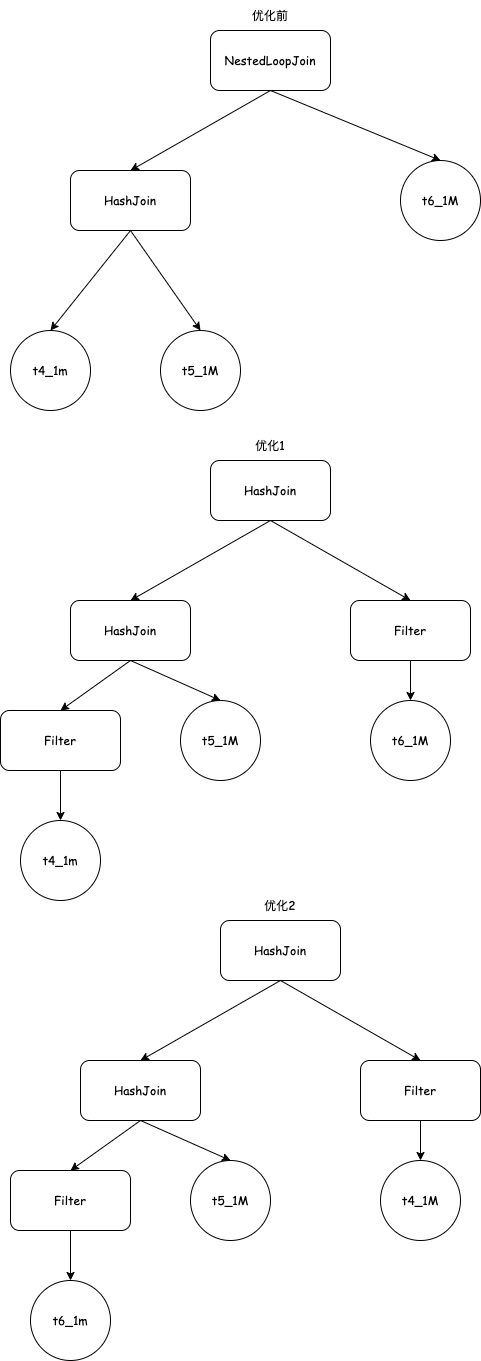
实现难点主要是看怎么把顶层NestedLoopJoin的过滤条件抽出来,这里可以多参考下已有代码的实现和各种Expression的使用方式。
Query 3
语句
select v, d1, d2 from (
select
v, max(v1) as d1, max(v1) + max(v1) + max(v2) as d2,
min(v1), max(v2), min(v2), max(v1) + min(v1), max(v2) + min(v2), min(v1), max(v2), min(v2), max(v1) + min(v1), max(v2) + min(v2), min(v1), max(v2), min(v2), max(v1) + min(v1), max(v2) + min(v2), min(v1), max(v2), min(v2), max(v1) + min(v1), max(v2) + min(v2), min(v1), max(v2), min(v2), max(v1) + min(v1), max(v2) + min(v2), min(v1), max(v2), min(v2), max(v1) + min(v1), max(v2) + min(v2), min(v1), max(v2), min(v2), max(v1) + min(v1), max(v2) + min(v2), min(v1), max(v2), min(v2), max(v1) + min(v1), max(v2) + min(v2)
from __mock_t7 left join (select v4 from __mock_t8 where 1 == 2) on v < v4 group by v
);
优化点:
- 由于该NestedLoopJoin是left join,而且右表还是个空表,所以直接scan t7表得了,如下图优化1所示。
- 由于最后输出的列较少,所以还能做column裁剪,最终查询计划优化如下图优化2所示。
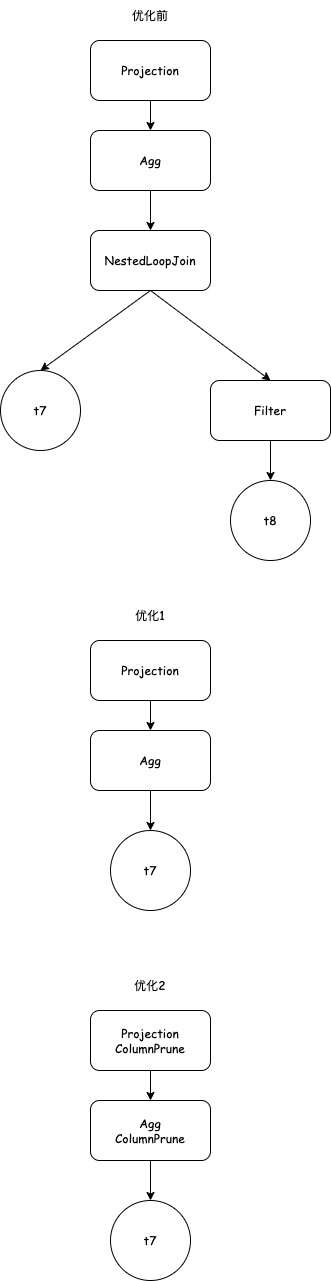
实现上主要难点是重写column裁剪时要重写ProjectionPlanNode和AggregationPlanNode中的表达式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号