python笔记
主要看的是菜鸟教程。Python3 教程 | 菜鸟教程
这个记录什么呢?各种东西都摆在那里,我要全部复制下来毫无意义,就重点记录一下经常或者可能要用的东西以及理论。
一,运算:
通常由于使用的场景是写解密脚本,那就讲讲通常要用的东西:
|
运算符 |
描述 |
实例 |
|
& |
按位与运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0 |
(a & b) 输出结果 12 ,二进制解释: 0000 1100 |
|
^ |
按位异或运算符:当两对应的二进位相异时,结果为1 |
(a ^ b) 输出结果 49 ,二进制解释: 0011 0001 |
|
~ |
按位取反运算符:对数据的每个二进制位取反,即把1变为0,把0变为1。~x 类似于 -x-1 |
(~a ) 输出结果 -61 ,二进制解释: 1100 0011, 在一个有符号二进制数的补码形式。 |
|
<< |
左移动运算符:运算数的各二进位全部左移若干位,由"<<"右边的数指定移动的位数,高位丢弃,低位补0。 |
a << 2 输出结果 240 ,二进制解释: 1111 0000 |
|
>> |
右移动运算符:把">>"左边的运算数的各二进位全部右移若干位,">>"右边的数指定移动的位数 |
a >> 2 输出结果 15 ,二进制解释: 0000 1111 |
二,字符串:
字符串一旦建立,那就不能后续修改了
h='hello'
h[2]='w'
print(h)
1.转义字符
|
\r |
回车,将 \r 后面的内容移到字符串开头,并逐一替换开头部分的字符,直至将 \r 后面的内容完全替换完成。 |
print("hello,,\rworldd")
经常测试,这个替换会先跳过符号,优先去取代字符串,如果前面的字符串不够,就会往后取代符号。
实现百分比进度
import time
for i in range(101):
print("\r{:3}%".format(i),end=' ')
time.sleep(0.05)这个会从0%输出到100%,但不会把所有的都输出来,最后只会得到1个数,而不是100个数,感觉很使用,使用别的方法似乎做不到。
2.Python 字符串运算符
这个偶尔会用到,节约手。
|
操作符 |
描述 |
实例 |
|
+ |
字符串连接 |
a + b 输出结果: HelloPython |
|
* |
重复输出字符串 |
a*2 输出结果:HelloHello |
|
[] |
通过索引获取字符串中字符 |
a[1] 输出结果 e |
|
[ : ] |
截取字符串中的一部分,遵循左闭右开原则,str[0:2] 是不包含第 3 个字符的。 |
a[1:4] 输出结果 ell |
|
in |
成员运算符 - 如果字符串中包含给定的字符返回 True |
'H' in a 输出结果 True |
3.Python 字符串格式化
|
符 号 |
描述 |
|
%c |
格式化字符及其ASCII码 |
|
%s |
格式化字符串 |
|
%d |
格式化整数 |
|
%u |
格式化无符号整型 |
|
%o |
格式化无符号八进制数 |
|
%x |
格式化无符号十六进制数 |
|
%X |
格式化无符号十六进制数(大写) |
|
%f |
格式化浮点数字,可指定小数点后的精度 |
例子:输出百分比:
import time
for i in range(101):
print("%d%%"% i)
time.sleep(0.01)会得到像这样输出:
打两个百分号才能输出%,只有一个的话会报错

4.f-string
f-string 是 python3.6 之后版本添加的,称之为字面量格式化字符串,是新的格式化字符串的语法。
之前我们习惯用百分号 (%):
f-string 格式化字符串以 f 开头,后面跟着字符串,字符串中的表达式用大括号 {} 包起来,它会将变量或表达式计算后的值替换进去,实例如下:
>>> w = {'name': 'Runoob', 'url': 'www.runoob.com'}
>>> f'{w["name"]}: {w["url"]}'
'Runoob: www.runoob.com'5.函数:
函数及例子:
print("A 对应的 ASCII 值为:", ord('A')) # 输出:A 对应的 ASCII 值为: 65
print("\x41 为 A 的 ASCII 代码") # 输出:A 为 A 的 ASCII 代码
decimal_number = 42
binary_number = bin(decimal_number) # 十进制转换为二进制
print('转换为二进制:', binary_number) # 转换为二进制: 0b101010
octal_number = oct(decimal_number) # 十进制转换为八进制
print('转换为八进制:', octal_number) # 转换为八进制: 0o52
hexadecimal_number = hex(decimal_number) # 十进制转换为十六进制
print('转换为十六进制:', hexadecimal_number) # 转换为十六进制: 0x2a
len(string)#返回字符串长度三,列表
列表是最常用的 Python 数据类型,它可以作为一个方括号内的逗号分隔值出现。
列表的数据项不需要具有相同的类型
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。如下所示:
list1 = ['Google', 'Runoob', 1997, 2000]
1.列表的更新
列表的的大小一旦确定,就只能通过append添加元素:
list=[]
for i in range(101):
#list[i]=i,错误示范
list.append(i)#正确添加错误示范会爆出超过列表大小的错误,如果非要用第一种方法更改也行下面是例子。
list=[0]*101
for i in range(101):
list[i]=i要提前定好大小
四,推导式:
列表推导式
列表推导式格式为:
[表达式 for 变量 in 列表]
[out_exp_res for out_exp in input_list]
或者
[表达式 for 变量 in 列表 if 条件]
[out_exp_res for out_exp in input_list if condition]- out_exp_res:列表生成元素表达式,可以是有返回值的函数。
- for out_exp in input_list:迭代 input_list 将 out_exp 传入到 out_exp_res 表达式中。
- if condition:条件语句,可以过滤列表中不符合条件的值。
例子:
计算 30 以内可以被 3 整除的整数:
实例
>>> multiples = [i for i in range(30) if i % 3 == 0]
>>> print(multiples)
[0, 3, 6, 9, 12, 15, 18, 21, 24, 27]
yield
在 Python 中,使用了 yield 的函数被称为生成器(generator)。
yield 是一个关键字,用于定义生成器函数,生成器函数是一种特殊的函数,可以在迭代过程中逐步产生值,而不是一次性返回所有结果。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
当在生成器函数中使用 yield 语句时,函数的执行将会暂停,并将 yield 后面的表达式作为当前迭代的值返回。
然后,每次调用生成器的 next() 方法或使用 for 循环进行迭代时,函数会从上次暂停的地方继续执行,直到再次遇到 yield 语句。这样,生成器函数可以逐步产生值,而不需要一次性计算并返回所有结果。
调用一个生成器函数,返回的是一个迭代器对象。
例子:
def text(n):
i=1
while n > 0:
yield n
n -= 1
print("第{}次".format(i))
i+=1
c= text(5)
for i in range(5):
print(next(c))结果:
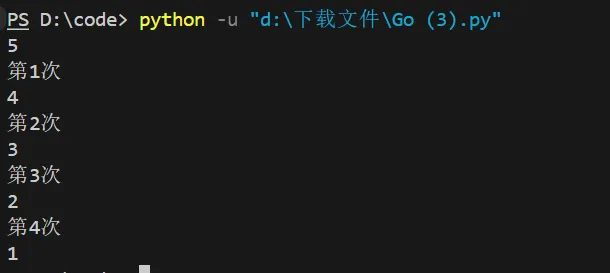
可以看到最后一次的“第5次”没有打印出来,说明当最后一运行时,n=1,输出完后运行到n-=1,使n=0,接着就不运行后面的东西了。但是将n-=1放到最后面仍然会出现这样的情况。(我这个说明可能是错的)
自己动调一遍就明白为什么会这样了,就不详细解释了。
五,函数
1.不定长参数函数:
当需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数
语法如下:
def functionname([formal_args,] *var_args_tuple ):
"函数_文档字符串"
function_suite
return [expression]参数前加一个*会被认为是元组,所以才有这样的效果
例子:
def printme(*args):
print("输出:")
for arg in args:
print(arg,end=" ")
printme("hello", "world", "!")
带两个**会被认为是字典:
def functionname([formal_args,] **var_args_dict ):
"函数_文档字符串"
function_suite
return [expression]例子:
def printme(**args):
print("输出:")
print(args,end=" ")
printme(a="hello",b="world",c="python")
六,lambda(匿名函数)
lambda 函数是一种小型、匿名的、内联函数,它可以具有任意数量的参数,但只能有一个表达式。
匿名函数不需要使用 def 关键字定义完整函数。
例子:
x = lambda a, b : a * b
print(x(5, 6))七,模块
Python 中的模块(Module)是一个包含 Python 定义和语句的文件,文件名就是模块名加上 .py 后缀。
模块可以包含函数、类、变量以及可执行的代码。通过模块,我们可以将代码组织成可重用的单元,便于管理和维护。
模块的作用
- 代码复用:将常用的功能封装到模块中,可以在多个程序中重复使用。
- 命名空间管理:模块可以避免命名冲突,不同模块中的同名函数或变量不会互相干扰。
- 代码组织:将代码按功能划分到不同的模块中,使程序结构更清晰。
import
可以使用import来实现
我有一个名为 support的py文件,里面的代码为:
def zhe_shi_yi_ge_func(a,b):
print(a+b)如果我想在其他的文件里用这个函数,可以这样用:
import support
support.zhe_shi_yi_ge_func(5,6)如果要经常使用这个函数,可以给函数起个别名从而节约手
import support
a=support.zhe_shi_yi_ge_func
a(5,6)from … import 语句
Python 的 from 语句让你从模块中导入一个指定的部分到当前命名空间中,语法如下:
from modname import name1[, name2[, ... nameN]]例子:
from support import zhe_shi_yi_ge_func
zhe_shi_yi_ge_func(5,6)八,__name__ 与 __main__
__name__ 是一个内置变量,用于表示当前模块的名称。
__name__ 的值取决于模块是如何被使用的:
当模块作为主程序运行时:__name__ 的值被设置为 "__main__"。
当模块被导入时:__name__ 的值被设置为模块的文件名(不包括 .py 扩展名)。
例子:
def greet():
print("来自 example 模块的问候!")
if __name__ == "__main__":
print("该脚本正在直接运行。")
greet()
else:
print("该脚本作为模块被导入。")直接运行会输出“该脚本正在直接运行”
而作为模块导入则会运行else
九,File(文件) 方法
这个在misc应该很常用,在re中我也用过几次,但都是看别人WP抄的,完全不知道什么意思,等以后再次遇到相关的东西后再补充例子吧。
open() 方法
Python open() 方法用于打开一个文件,并返回文件对象。
在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
注意:使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。
open(file, mode='r')mode 参数有:
|
模式 |
描述 |
|
wb+ |
以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
|
r |
以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
|
w |
打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
|
a |
打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
file 对象
file 对象使用 open 函数来创建,下表列出了 file 对象常用的函数:
|
序号 |
方法及描述 |
|
1 |
关闭文件。关闭后文件不能再进行读写操作。 |
|
6 |
从文件读取指定的字节数,如果未给定或为负则读取所有。 |
|
12 |
将字符串写入文件,返回的是写入的字符长度。 |
十,异常处理:
估计开发游戏的时候要用到很多,就详细的记下了
try/except

异常捕捉可以使用 try/except 语句。
while True:
try:
x=int(input())
print(5/x)
break
except ValueError:
print("请输入有效的整数")
except ZeroDivisionError:
print("除数不能为0")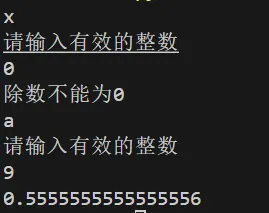
try 语句按照如下方式工作;
- 首先,执行 try 子句(在关键字 try 和关键字 except 之间的语句)。
- 如果没有异常发生,忽略 except 子句,try 子句执行后结束。
- 如果在执行 try 子句的过程中发生了异常,那么 try 子句余下的部分将被忽略。如果异常的类型和 except 之后的名称相符,那么对应的 except 子句将被执行。
- 如果一个异常没有与任何的 except 匹配,那么这个异常将会传递给上层的 try 中。
一个 try 语句可能包含多个except子句,分别来处理不同的特定的异常。最多只有一个分支会被执行。
处理程序将只针对对应的 try 子句中的异常进行处理,而不是其他的 try 的处理程序中的异常。
一个except子句可以同时处理多个异常,这些异常将被放在一个括号里成为一个元组
try/except...else
try/except 语句还有一个可选的 else 子句,如果使用这个子句,那么必须放在所有的 except 子句之后。
else 子句将在 try 子句没有发生任何异常的时候执行。

try-finally 语句
try-finally 语句无论是否发生异常都将执行最后的代码。

try:
runoob()
except AssertionError as error:
print(error)
else:
try:
with open('file.log') as file:
read_data = file.read()
except FileNotFoundError as fnf_error:
print(fnf_error)
finally:
print('这句话,无论异常是否发生都会执行。')raise:
Python 使用 raise 语句抛出一个指定的异常。
raise语法格式如下:
raise [Exception [, args [, traceback]]]以下实例如果 x 大于 5 就触发异常:
x = 10
if x > 5:
raise Exception('x 不能大于 5。x 的值为: {}'.format(x))raise 唯一的一个参数指定了要被抛出的异常。它必须是一个异常的实例或者是异常的类(也就是 Exception 的子类)。
如果你只想知道这是否抛出了一个异常,并不想去处理它,那么一个简单的 raise 语句就可以再次把它抛出。
>>> try:
raise NameError('HiThere') # 模拟一个异常。
except NameError:
print('An exception flew by!')
raise
An exception flew by!
Traceback (most recent call last):
File "<stdin>", line 2, in ?
NameError: HiThere所有的内置错误类型:
BaseException 所有异常的基类
+-- SystemExit 解释器请求退出
+-- KeyboardInterrupt 用户中断执行(通常是输入^C)
+-- GeneratorExit 生成器(generator)发生异常来通知退出
+-- Exception 常规错误的基类
+-- StopIteration 迭代器没有更多值
+-- StopAsyncIteration 必须通过异步迭代器对象的__anext__()方法引发以停止迭代
+-- ArithmeticError 所有数值计算错误的基类
| +-- FloatingPointError 浮点计算错误
| +-- OverflowError 数值运算超出最大限制
| +-- ZeroDivisionError 除(或取模)零 (所有数据类型
+-- AssertionError 断言语句失败
+-- AttributeError 对象没有这个属性
+-- BufferError 与缓冲区相关的操作时引发
+-- EOFError 没有内建输入,到达EOF 标记
+-- ImportError 导入失败
| +-- ModuleNotFoundError 找不到模块
+-- LookupError 无效数据查询的基类
| +-- IndexError 序列中没有此索引(index)
| +-- KeyError 映射中没有这个键
+-- MemoryError 内存溢出错误
+-- NameError 未声明、初始化对象
| +-- UnboundLocalError 访问未初始化的本地变量
+-- OSError 操作系统错误,
| +-- BlockingIOError 操作将阻塞对象设置为非阻塞操作
| +-- ChildProcessError 子进程上的操作失败
| +-- ConnectionError 与连接相关的异常的基类
| | +-- BrokenPipeError 在已关闭写入的套接字上写入
| | +-- ConnectionAbortedError 连接尝试被对等方中止
| | +-- ConnectionRefusedError 连接尝试被对等方拒绝
| | +-- ConnectionResetError 连接由对等方重置
| +-- FileExistsError 创建已存在的文件或目录
| +-- FileNotFoundError 请求不存在的文件或目录
| +-- InterruptedError 系统调用被输入信号中断
| +-- IsADirectoryError 在目录上请求文件操作
| +-- NotADirectoryError 在不是目录的事物上请求目录操作
| +-- PermissionError 在没有访问权限的情况下运行操作
| +-- ProcessLookupError 进程不存在
| +-- TimeoutError 系统函数在系统级别超时
+-- ReferenceError 弱引用试图访问已经垃圾回收了的对象
+-- RuntimeError 一般的运行时错误
| +-- NotImplementedError 尚未实现的方法
| +-- RecursionError 解释器检测到超出最大递归深度
+-- SyntaxError Python 语法错误
| +-- IndentationError 缩进错误
| +-- TabError Tab 和空格混用
+-- SystemError 一般的解释器系统错误
+-- TypeError 对类型无效的操作
+-- ValueError 传入无效的参数
| +-- UnicodeError Unicode 相关的错误
| +-- UnicodeDecodeError Unicode 解码时的错误
| +-- UnicodeEncodeError Unicode 编码时错误
| +-- UnicodeTranslateError Unicode 转换时错误
+-- Warning 警告的基类
+-- DeprecationWarning 关于被弃用的特征的警告
+-- PendingDeprecationWarning 关于构造将来语义会有改变的警告
+-- RuntimeWarning 可疑的运行行为的警告
+-- SyntaxWarning 可疑的语法的警告
+-- UserWarning 用户代码生成的警告
+-- FutureWarning 有关已弃用功能的警告的基类
+-- ImportWarning 模块导入时可能出错的警告的基类
+-- UnicodeWarning 与Unicode相关的警告的基类
+-- BytesWarning bytes和bytearray相关的警告的基类
+-- ResourceWarning 与资源使用相关的警告的基类。。后记:
还是没有完成原本的要求——不大段的复制粘贴,我还是太懒了,而且好多东西没有例子,使用的方法也没有很好的去写出来,后面肯定会更新,不过得等我的经验更加丰富之后。
而且感觉是成片的抄菜鸟教程啊
本文来自博客园,作者:漫宿骄盛,转载请注明原文链接:https://www.cnblogs.com/msjs/p/18797005
都是顺手发的,写的时候可能有错误,如果发现了,望各位指出。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号