Fuzzing: a survey 简述
Fuzzing: a survey 简述
Backround
简要阐述了 静态分析 动态分析 符号执行 模糊测试 的概念与特点,做了一个对比,见图
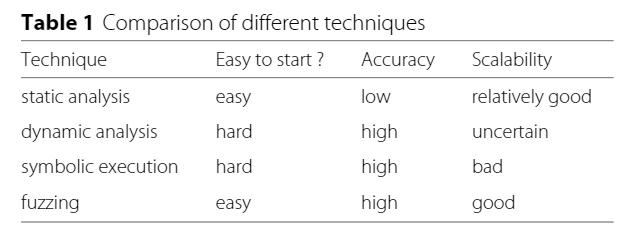
PS:个人以为 符号执行 可以算静态分析的一类 模糊测试 可以算 动态分析 不知道为什么要搞成四类
Fuzzing
Fuzzing的框架
个人以为给的不太好 ,不如 Fuzzing: State of the art 这篇论文的图 就不贴了
Fuzzing的分类
多种 Fuzzer 对比:


Fuzzing 关键挑战
主要有三大方面:
-
种子的变异
现在基于变异fuzzer广泛使用;如何变异,在哪变异 是很重要的问题,好的变异 节省资源 高效工作
-
代码覆盖低
对于基于代码覆盖的fuzzer ,覆盖越多的代码路径,发现漏洞的可能性越高
-
验证通过
程序的输入都会有输入验证,而测试样例需要通过这些验证,才能到达程序内部
基于覆盖的 Fuzzing
基于覆盖的 fuzzing目前被广泛使用,为了深入而彻底的对程序Fuzzing,需要尽可能地去遍历程序的运行状态,但是没有一个简单的度量方法。因此选择代码覆盖来做近似的判断,因为恒定的代码量不等于程序状态,所以会有一定的信息损失(个人理解,以 变量 距离,代码覆盖只是一个定义,但在运行中,不同的变量值会对应不同状态)
代码覆盖率计算
目前的方法都是将Basic Block 作为基本粒度(每个块只有一个入口和一个出口),有三大原因:
- 程序控制块(Basic Block)是程序程序执行的最小集合
- 以函数或者指令为单位 会导致 信息的确实或者冗余
- 基本块可以通过第一条指令的地址来识别,基本块信息可以通过代码指令轻松提取
基于Basic Block 有两种基本的测量控制方法,一种是计算 控制块的执行个数(针对CFG上的点),一种是计算 基本控制块的转换(针对CFG上的边)
基于代码覆盖的Fuzzer工作流程
如图所示

然后以AFL举例,给出了AFL的基本框架,可以对照来理解

关键问题
主要有以下几个方面:
-
如何得到初始的输入?
对于目前基于覆盖的fuzzer基本采用基于变异的方式,一个好的种子 会使fuzzing 有效而高效,目前主要采取 从网络上爬取样本或者POC
一个好的 输入有以下价值:
- 提供了关于种子的好的好格式,节省了CPU构造相关文件的计算力
- 会符合较为复杂的文件格式,而变异可能往往较难达到这种复杂格式
- 据此产生的变异能达到程序的深处和较少执行的路径
- 可以在多次实验重复利用
-
如何生成测试样例?
测试样例的好坏验证影响 fuzzing的作用,对于生成测试样例,有结合 动静态分析分析的 ,有结合机器学习的GAN,LSTM,以及PCSG 等等方法不一而足。
-
如何筛选种子?
模糊测试人员从种子库中反复选择种子,以在主模糊测试循环中进行新的轮次测试时进行变异
种子挑选策略影响着种子的选择,进一步影响 测试的效果
目前的种子挑选 有偏向执行低频路径的、有偏向消耗资源多的(容易出bug)、有采取静态分析找到特定代码,然后偏向执行改代码的种子 等等
-
如何高效的测试应用?
对于每一次测试,都需要运行程序,因此消耗资源较多,所以我们需要对测试的过程进行优化,节省资源,提高效率
目前有采用并行化的方法,或者引入 Intel’s Processor Trace(PT)机制,甚至对程序克隆的方法。
Fuzzing集成技术
在测试样例生成阶段,对于生成式的Fuzzer,主要是生成满足复杂数据结构的样例和触发难以到达的路径;对于变异式的,变异的位置(例如文件的魔数,加载时验证文件类型)和变异的值是关键(随机的还是特定的)。
在程序执行阶段,关键在于如何收集信息指导Fuzzing的过程和如何探索执行新的路径。 Instrumentation---->插桩技术

Fuzzing的不同应用
Fuzzing 一出现就被运用在不同的应用上。
文件格式Fuzzing
很多应用都涉及文件格式,因此有一定的发展空间,而目前进行的最多的一个分支是对 浏览器的Fuzzing,目前浏览器支持多种格式。有较大发展空间
内核Fuzzing
当前内核Fuzzing较为困难,主要是困难在于,错误会引起系统崩溃,工作在Ring3难以和内核沟通(当前的方式是通过调用内核API),以及部分系统 如Windows 和MacOS内核闭源。
目前内核Fuzzing 被分为两类:
-
基于知识的Fuzzer( knowledge based fuzzers)
主要利用了内核API的知识 ---->比较API的参数和调用顺序有一定要求
-
基于覆盖的Fuzzer(Coverage based fuzzing)
这种方式在用户态取得了较好的成果
协议Fuzzing
对于协议的Fuzzing 也是一个大方向,有了一些成果
新的发展趋势
主要是收集跟那个更多的反馈信息让fuzzer更智能,同时集成利用诸如机器学习的方法来改进,最后是 利用硬件或者系统特性来改进
总结
Fuzzing发展火热,没啥太多可说的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号