别再人云亦云了!!!你真的搞懂了RDD、DF、DS的区别吗?
几年前,包括最近,我看了各种书籍、教程、官网。但是真正能够把RDD、DataFrame、DataSet解释得清楚一点的、论据多一点少之又少,甚至有的人号称Spark专家,但在这一块根本说不清楚。还有国内的一些书籍,小猴真的想问一声:Are you OK?书名别再叫精通xxx技术了,请改名为 xxx技术从入门到放弃。这样可以有效避免耽误别人学习,不好吗?
大家都在告诉我们结论,但其实,小猴作为一名长期混迹于开源社区、并仍在一线大数据开发的技术人,深谙技术文化之一:
To experience | 去经历
这是我要提倡的技术文化之一。之前有人把Experience译为体验,但在小猴的技术世界里,Experience更多的是自己去经历,而不能跟团去旅游一样,那样你只能是一个外包而已,想要做到卓越,就得去经历。技术,只有去经历才会有成长。
目录
RDD、DataFrame、DataSet介绍
我们每天都在基于框架开发,对于我们来说,一套易于使用的API太重要了。对于Spark来说,有三套API。

分别是:
- RDD
- DataFrame
- DataSet
三套的API,开发人员就要学三套。不过,从Spark 2.2开始,DataFrame和DataSet的API已经统一了。而编写Spark程序的时候,RDD已经慢慢退出我们的视野了。
但Spark既然提供三套API,我们到底什么时候用RDD、什么时候用DataFrame、或者DataSet呢?我们先来了解下这几套API。
RDD
RDD的概念
- RDD是Spark 1.1版本开始引入的。
- RDD是Spark的基本数据结构。
- RDD是Spark的弹性分布式数据集,它是不可变的(Immutable)。
- RDD所描述的数据分布在集群的各个节点中,基于RDD提供了很多的转换的并行处理操作。
- RDD具备容错性,在任何节点上出现了故障,RDD是能够进行容错恢复的。
- RDD专注的是How!就是如何处理数据,都由我们自己来去各种算子来实现。
什么时候使用RDD?
- 应该避免使用RDD!
RDD的短板
- 集群间通信都需要将JVM中的对象进行序列化和反序列化,RDD开销较大
- 频繁创建和销毁对象会增加GC,GC的性能开销较大
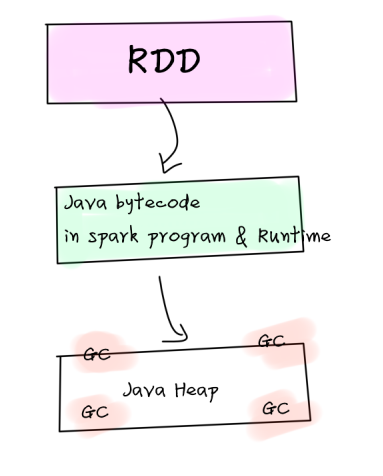
Spark 2.0开始,RDD不再是一等公民
从Apache Spark 2.0开始,RDD已经被降级为二等公民,RDD已经被弃用了。而且,我们一会就会发现,DataFrame/DataSet是可以和RDD相互转换的,DataFrame和DataSet也是建立在RDD上。
DataFrame
DataFrame概念
- DataFrame是从Spark 1.3版本开始引入的。
- 通过DataFrame可以简化Spark程序的开发,让Spark处理结构化数据变得更简单。DataFrame可以使用SQL的方式来处理数据。例如:业务分析人员可以基于编写Spark SQL来进行数据开发,而不仅仅是Spark开发人员。
- DataFrame和RDD有一些共同点,也是不可变的分布式数据集。但与RDD不一样的是,DataFrame是有schema的,有点类似于关系型数据库中的表,每一行的数据都是一样的,因为。有了schema,这也表明了DataFrame是比RDD提供更高层次的抽象。
- DataFrame支持各种数据格式的读取和写入,例如:CSV、JSON、AVRO、HDFS、Hive表。
- DataFrame使用Catalyst进行优化。
- DataFrame专注的是What!,而不是How!
DataFrame的优点
- 因为DataFrame是有统一的schema的,所以序列化和反序列无需存储schema。这样节省了一定的空间。
- DataFrame存储在off-heap(堆外内存)中,由操作系统直接管理(RDD是JVM管理),可以将数据直接序列化为二进制存入off-heap中。操作数据也是直接操作off-heap。
DataFrane的短板
- DataFrame不是类型安全的
- API也不是面向对象的
Apache Spark 2.0 统一API
从Spark 2.0开始,DataFrame和DataSet的API合并在一起,实现了跨库统一成为一套API。这样,开发人员的学习成本就降低了。只需要学习一个High Level的、类型安全的DataSet API就可以了。——这对于Spark开发人员来说,是一件好事。
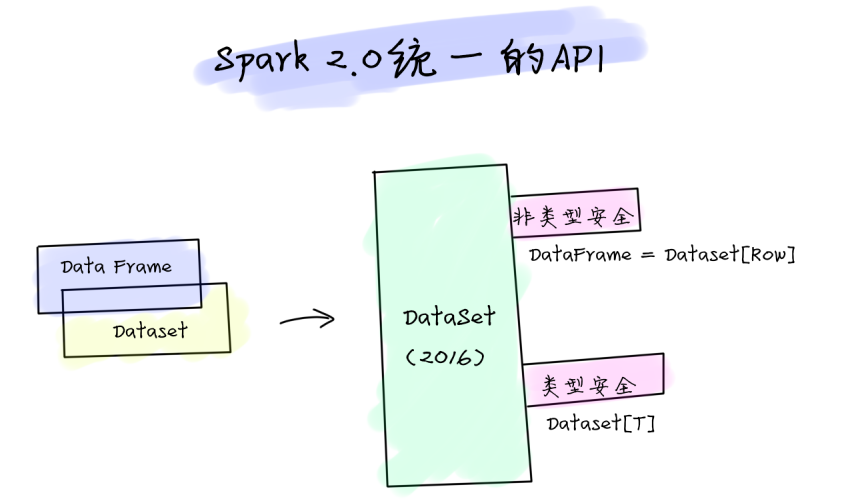
上图我们可以看到,从Spark 2.0开始,Dataset提供了两组不同特性的API:
- 非类型安全
- 类型安全
其中非类型安全就是DataSet[Row],我们可以对Row中的字段取别名。这不就是DataFrame吗?而类型安全就是JVM对象的集合,类型就是scala的样例类,或者是Java的实体类。
有Spark 2.0源码为证:
package object sql {
// ...
type DataFrame = Dataset[Row]
}
也就是说,每当我们用导DataFrame其实就是在使用Dataset。
针对Python或者R,不提供类型安全的DataSet,只能基于DataFrame API开发。
什么时候使用DataFrame
DataSet
- DataSet是从Spark 1.6版本开始引入的。
- DataSet具有RDD和DataFrame的优点,既提供了更有效率的处理、以及类型安全的API。
- DataSet API都是基于Lambda函数、以及JVM对象来进行开发,所以在编译期间就可以快速检测到错误,节省开发时间和成本。
- DataSet使用起来很像,但它的执行效率、空间资源效率都要比RDD高很多。可以很方便地使用DataSet处理结构化、和非结构数据。
DataSet API的优点
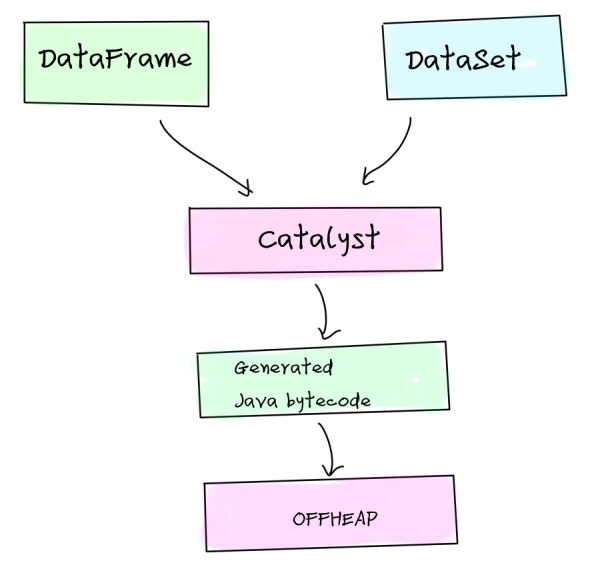
- DataSet结合了RDD和DataFrame的优点。
- 当序列化数据时,Encoder生成的字节码可以直接与堆交互,实现对数据按需访问,而无需反序列化整个对象。
类型安全
写过Java或者C#的同学都会知道,一旦在代码中类型使用不当,编译都编译不过去。日常开发中,我们更多地是使用泛型。因为一旦我们使用非类型安全的类型,软件的维护周期一长,如果集合中放入了一些不合适的类型,就会出现严重的故障。这也是为什么Java、C#还有C++都要去支持泛型的原因。
在Spark中也会有类型安全的问题。而且,一旦在运行时出现类型安全问题,会影响整个大规模计算作业。这种作业的错误排除难度,要比单机故障排查起来更复杂。如果在运行时期间就能发现问题,这很美好啊。
DataFrame中编写SQL进行数据处理分析,在编译时是不做检查的,只有在Spark程序运行起来,才会检测到问题。
| SQL | DataFrame | Dataset | |
|---|---|---|---|
| 语法错误 | 运行时 | 编译时 | 编译时 |
| 解析错误 | 运行时 | 运行时 | 编译时 |
对结构化和半结构化数据的High Level抽象
例如:我们有一个较大的网站流量日志JSON数据集,可以很容易的使用DataSet[WebLog]来处理,强类型操作可以让处理起来更加简单。
以RDD更易用的API
DataSet引入了更丰富的、更容易使用的API操作。这些操作是基于High Level抽象的,而且基于实体类的操作,例如:进行groupBy、agg、select、sum、avg、filter等操作会容易很多。
性能优化
使用DataFrame和DataSet API在性能和空间使用率上都有大幅地提升。
-
DataFrame和DataSet API是基于Spark SQL引擎之上构建的,会使用Catalyst生成优化后的逻辑和物理执行计划。尤其是无类型的DataSet[Row](DataFrame),它的速度更快,很适合交互式查询。
-
由于Spark能够理解DataSet中的JVM对象类型,所以Spark会将将JVM对象映射为Tungsten的内部内存方式存储。而Tungsten编码器可以让JVM对象更有效地进行序列化和反序列化,生成更紧凑、更有效率的字节码。
![RDD存储效率 VS DataSet存储效率]() 通过上图可以看到,DataSet的空间存储效率是RDD的4倍。RDD要使用60GB的空间,而DataSet只需要使用不到15GB就可以了。
通过上图可以看到,DataSet的空间存储效率是RDD的4倍。RDD要使用60GB的空间,而DataSet只需要使用不到15GB就可以了。
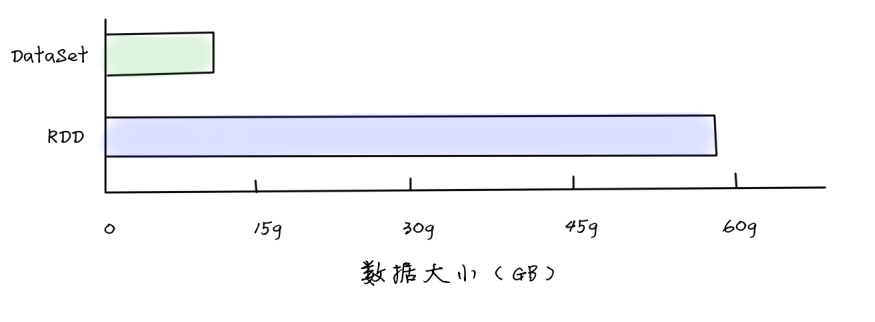 通过上图可以看到,DataSet的空间存储效率是RDD的4倍。RDD要使用60GB的空间,而DataSet只需要使用不到15GB就可以了。
通过上图可以看到,DataSet的空间存储效率是RDD的4倍。RDD要使用60GB的空间,而DataSet只需要使用不到15GB就可以了。Youtube视频分析案例
数据集
去Kaggle下载youtube地址:
https://www.kaggle.com/datasnaek/youtube-new?select=USvideos.csv
每个字段的含义都有说明。
Maven开发环境准备
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<scala.version>2.12</scala.version>
<spark.version>3.0.1</spark.version>
</properties>
<repositories>
<repository>
<id>central</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>central</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>com.opencsv</groupId>
<artifactId>opencsv</artifactId>
<version>5.3</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
</build>
RDD开发
/**
* Spark RDD处理示例
*/
object RddAnalysis {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD Process").setMaster("local[*]")
val sc = new SparkContext(conf)
// 读取本地文件创建RDD
val youtubeVideosRDD = {
sc.textFile("""E:\05.git_project\dataset\youtube""")
}
// 统计不同分类Youtube视频的喜欢人数、不喜欢人数
// 1. 添加行号
// 创建计数器
val rownumAcc = sc.longAccumulator("rownum")
// 带上行号
youtubeVideosRDD.map(line => {
rownumAcc.add(1)
rownumAcc.value -> line
})
// 过滤掉第一行
.filter(_._1 != 1)
// 去除行号
.map(_._2)
// 过滤掉非法的数据
.filter(line => {
val fields = line.split("\001")
val try1 = scala.util.Try(fields(8).toLong)
val try2 = scala.util.Try(fields(9).toLong)
if(try1.isFailure || try2.isFailure)
false
else
true
})
// 读取三个字段(视频分类、喜欢的人数、不喜欢的人数
.map(line => {
// 按照\001解析CSV
val fields = line.split("\001")
// 取第4个(分类)、第8个(喜欢人数)、第9个(不喜欢人数)
// (分类id, 喜欢人数, 不喜欢人数)
(fields(4), fields(8).toLong, fields(9).toLong)
})
// 按照分类id分组
.groupBy(_._1)
.map(t => {
val result = t._2.reduce((r1, r2) => {
(r1._1, r1._2 + r2._2, r1._3 + r2._3)
})
result
})
.foreach(println)
}
}
运行结果如下:
("BBC Three",8980120,149525)
("Ryan Canty",11715543,80544)
("Al Jazeera English",34427,411)
("FBE",9003314,191819)
("Sugar Pine 7",1399232,81062)
("Rob Scallon",11652652,704748)
("CamilaCabelloVEVO",19077166,1271494)
("Grist",3133,37)
代码中做了一些数据的过滤,然后进行了分组排序。如果Spark都要这么来写的话,业务人员几乎是没法写了。着代码完全解释了How,而不是What。每一个处理的细节,都要我们自己亲力亲为。实现起来臃肿。
查看下基于RDD的DAG
打开浏览器,输入:localhost:4040,来看下DAG。
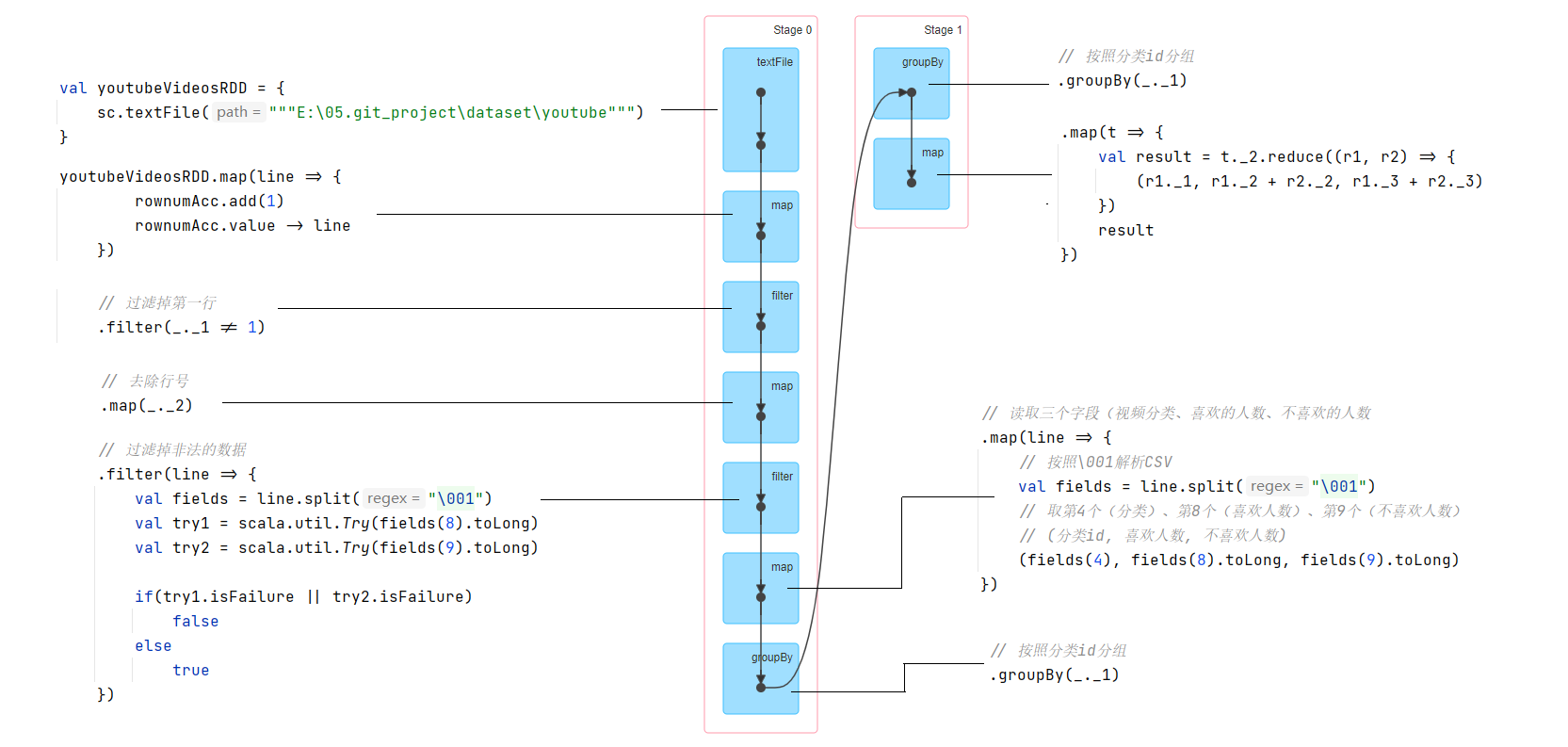
DAG非常的直观,按照shuffle分成了两个Stage来执行。Stage中依次执行了每个Operator。程序没有经过任何优化。我把每一个操作都和DAG上的节点对应了起来。
DataFrame开发
object DataFrameAnalysis {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("Youtube Analysis")
.master("local[*]")
.config("spark.sql.shuffle.partitions",1)
.getOrCreate()
import spark.sqlContext.implicits._
// 读取CSV
val youtubeVideoDF = spark.read.option("header", true).csv("""E:\05.git_project\dataset\USvideos.csv""")
import org.apache.spark.sql.functions._
// 按照category_id分组聚合
youtubeVideoDF.select($"category_id", $"likes".cast(LongType), $"dislikes".cast(LongType))
.where($"likes".isNotNull)
.where( $"dislikes".isNotNull)
.groupBy($"category_id")
.agg(sum("likes"), sum("dislikes"))
.show()
}
}
大家可以看到,现在实现方式非常的简单,而且清晰。
查看下基于DataFrame的执行计划与DAG
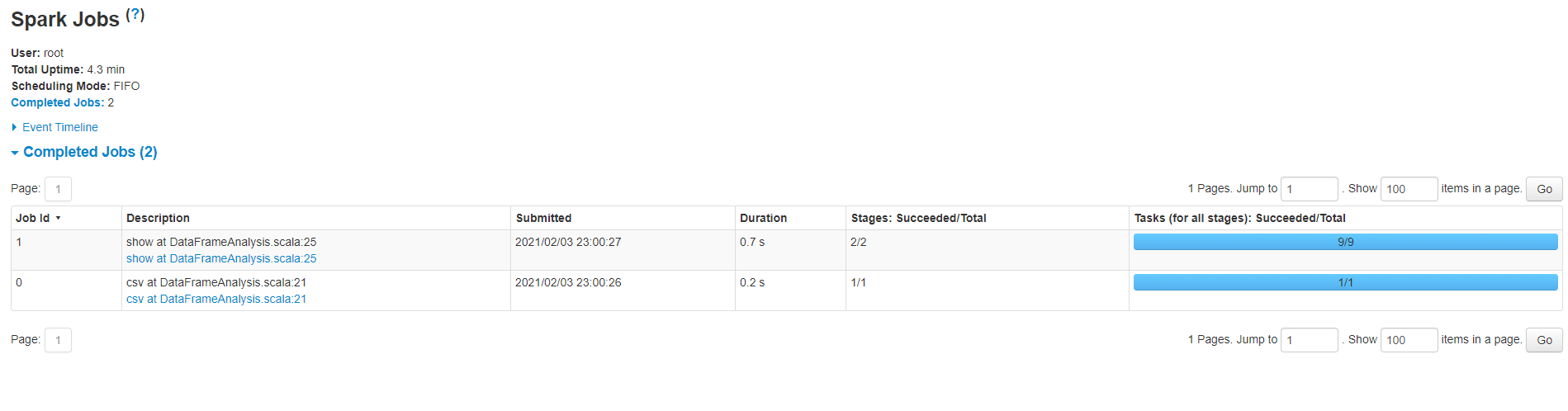
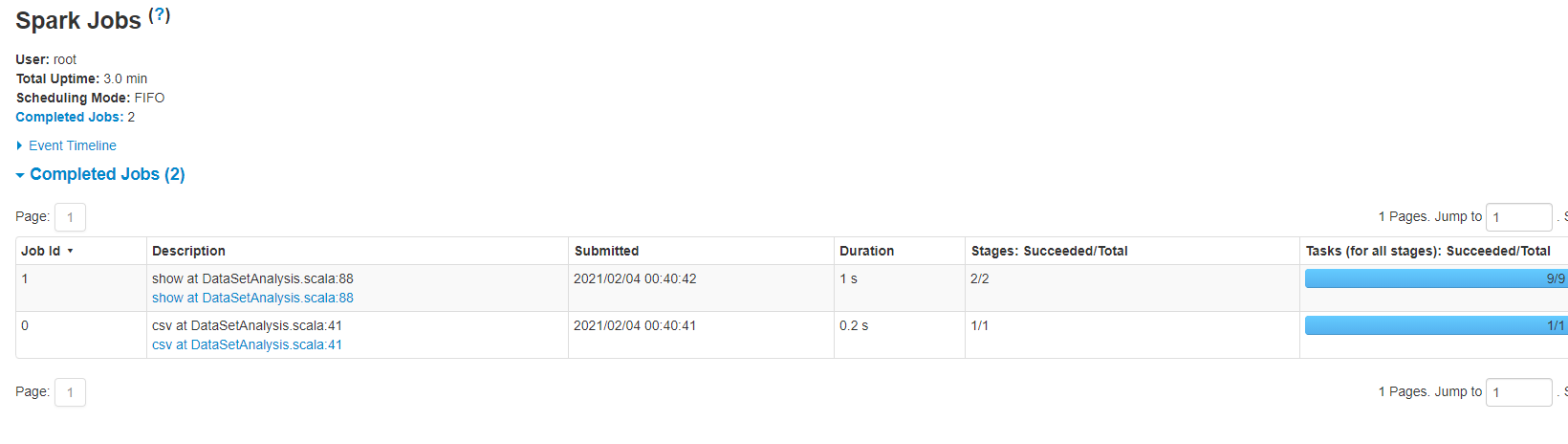
但我们运行上面的Spark程序时,其实运行了两个JOB。
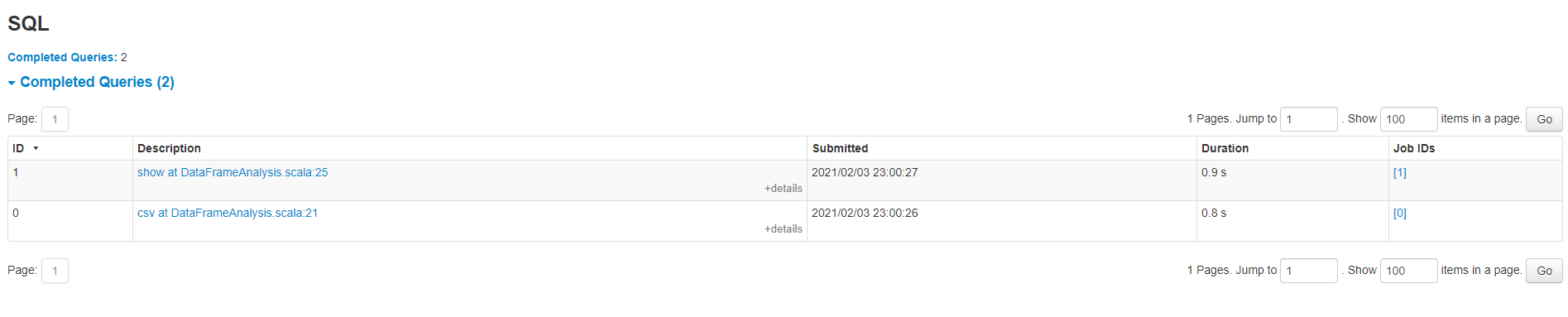
下面这个是第一个Job的DAG。我们看到只有一个Stage。这个DAG我们看得不是特别清楚做了什么,因为Spark SQL是做过优化的,我们需要查看Query的详细信息,才能看到具体执行的工作。
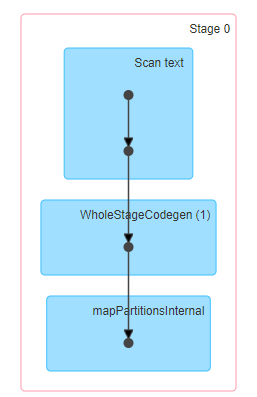
第一个Job的详细执行信息如下:
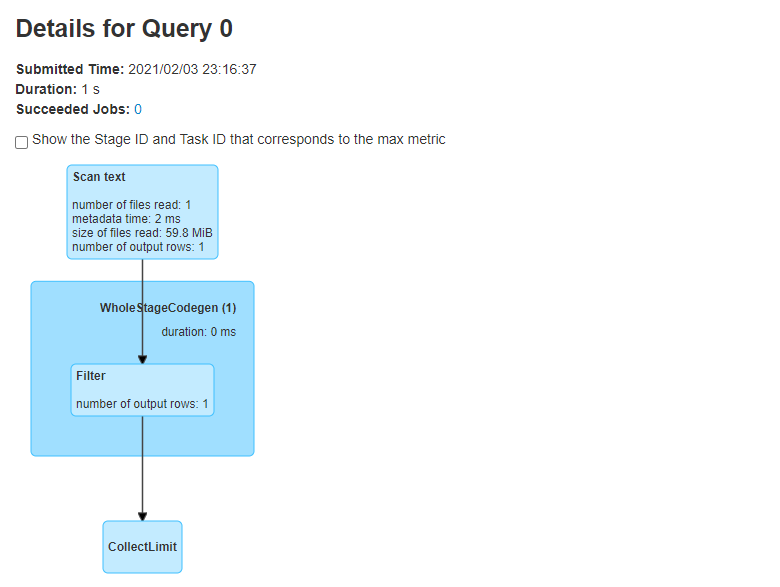
哦,原来这个JOB扫描了所有的行,然后执行了一个Filter过滤操作。再查看下查询计划:
== Parsed Logical Plan ==
GlobalLimit 1
+- LocalLimit 1
+- Filter (length(trim(value#6, None)) > 0)
+- Project [value#0 AS value#6]
+- Project [value#0]
+- Relation[value#0] text
== Analyzed Logical Plan ==
value: string
GlobalLimit 1
+- LocalLimit 1
+- Filter (length(trim(value#6, None)) > 0)
+- Project [value#0 AS value#6]
+- Project [value#0]
+- Relation[value#0] text
== Optimized Logical Plan ==
GlobalLimit 1
+- LocalLimit 1
+- Filter (length(trim(value#0, None)) > 0)
+- Relation[value#0] text
== Physical Plan ==
CollectLimit 1
+- *(1) Filter (length(trim(value#0, None)) > 0)
+- FileScan text [value#0] Batched: false, DataFilters: [(length(trim(value#0, None)) > 0)], Format: Text, Location: InMemoryFileIndex[file:/E:/05.git_project/dataset/USvideos.csv], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<value:string>
可以非常清晰地看到,我们说看到的DAG是经过优化后的。
第二个JOB的DAG如下,同样,我们也只能看到个大概。例如:Scan csv读取csv文件,然后执行Spark SQL自动生成、优化后的Codegen阶段,再执行了一次Shuffle(Exchange),然后再执行Spark SQL的codegen,最后执行mapPartition操作。
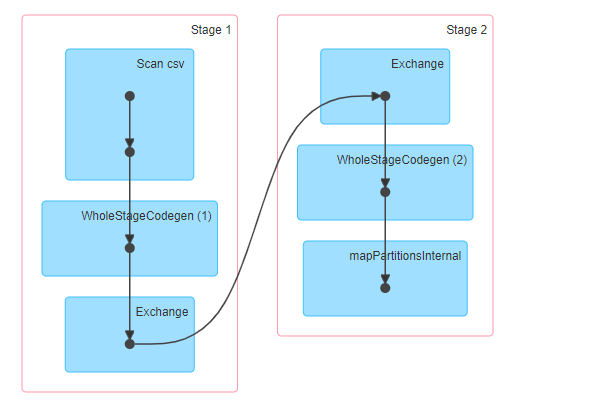
为了一探究竟,我们依然得去查看Query Detail。这个Query Detail图稍微长一点。我们很两个部分来讲解。
第一部分:
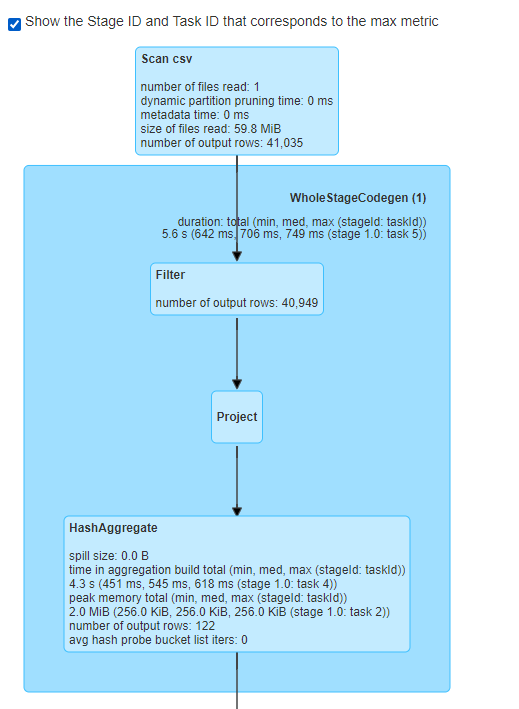
-
扫描csv文件,一共读取了一个文件,大小是59.8MB,一共有41035行。鼠标移上去,可以看到读取的文件路径、读取的schema是什么。
![image-20210203234552243]()
-
执行过滤操作(Filter)过滤出来的结果是40949行。把鼠标放在该操作,可以看到具体过滤的内容。
![image-20210203234453182]()
-
执行Project投影查询。其实就是执行select语句。
![image-20210203235430045]()
-
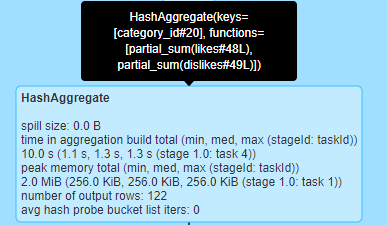
然后开始执行Hash聚合。按照category_id进行分组,并执行了partial_sum。
![image-20210203235623836]()
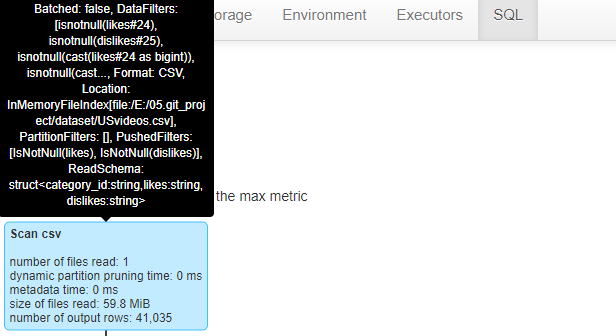


第二部分:
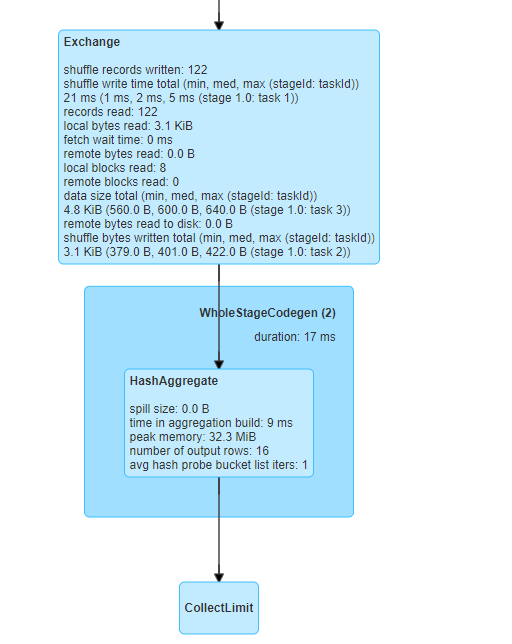
- Exchange表示进行数据交换(其实就是shuffle),shuffle一共读取了122行。
- 接着进行Hash聚合,按照category分组,并进行sum求和,计算得到最终结果。
- 最后输出21行,多出来的一行显示的第头部。

虽然DataFrame我们使用的是DSL方式,但我们可以感受这个过程处理起来比较简单。根据列进行分组聚合的时候,在编译时期是对类型不敏感的、非安全的。我们要保证列名、类型都是正确的。同时,我们可以清晰的看到Spark SQL对程序执行过程的优化。
DataSet开发
要使用DataSet开发,我们先来看一下csv读取数据成为DataFrame的spark源码。
def csv(path: String): DataFrame = {
// This method ensures that calls that explicit need single argument works, see SPARK-16009
csv(Seq(path): _*)
}
我们可以看到csv返回的是一个DataFrame类型。而进一步查看DataFrame的源码,我们发现:
type DataFrame = Dataset[Row]
而Row是非类型安全的,就有点像JDBC里面的ResultSet那样。我们为了操作起来更顺手一些,定义一个实体类来开发。
上代码:
case class YoutubeVideo(video_id: String
, trending_date: String
, title: String
, channel_title: String
, category_id: String
, publish_time: String
, tags: String
, views: Long
, likes: Long
, dislikes: Long
, comment_count: String
, thumbnail_link: String
, comments_disabled: Boolean
, ratings_disabled: Boolean
, video_error_or_removed: String
, description: String)
case class CategoryResult(categoryId:String
, totalLikes:Long
, totalDislikes:Long)
object DataSetAnalysis {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("Youtube Analysis")
.master("local[*]")
.config("spark.sql.shuffle.partitions",1)
.getOrCreate()
import spark.sqlContext.implicits._
// 读取CSV
val youtubeVideoDF:DataFrame = spark.read.option("header", true).csv("""E:\05.git_project\dataset\USvideos.csv""")
// 转换为DataSet
youtubeVideoDF.printSchema()
// 转换为Dataset[YoutubeVideo]
val youtubeVideoDS = youtubeVideoDF.filter(row => {
if(row.getString(7) != null && !row.getString(7).isBlank
&& row.getString(8) != null && !row.getString(8).isBlank
&& row.getString(9) != null && !row.getString(9).isBlank) {
if(util.Try(row.getString(7).toLong).isSuccess
&& util.Try(row.getString(8).toLong).isSuccess
&& util.Try(row.getString(9).toLong).isSuccess) {
true
}
else {
false
}
}
else {
false
}
})
.map(row => YoutubeVideo(row.getString(0)
, row.getString(1)
, row.getString(2)
, row.getString(3)
, row.getString(4)
, row.getString(5)
, row.getString(6)
, row.getString(7).toLong
, row.getString(8).toLong
, row.getString(9).toLong
, row.getString(10)
, row.getString(11)
, row.getString(12).toLowerCase().toBoolean
, row.getString(13).toLowerCase().toBoolean
, row.getString(14)
, row.getString(15)
))
youtubeVideoDS.groupByKey(_.category_id)
.mapValues(y => CategoryResult(y.category_id, y.likes, y.dislikes))
.reduceGroups{(cr1, cr2) => {
CategoryResult(cr1.categoryId, cr1.totalLikes + cr2.totalLikes, cr1.totalDislikes + cr2.totalDislikes)
}}
// 只获取Value部分,key部分过滤掉
.map(t => t._2)
.toDF()
.show()
TimeUnit.HOURS.sleep(1)
}
}
可以看到,我们对DataFrame进行了类型的安全转换。来看一下Spark SQL执行的JOB。
同样,基于DataSet的代码,也执行了两个JOB。
第一个JOB是一样的,因为我们一样要处理CSV的header。
而第二部分,命名我们了用了很多的groupByKey、mapValues、reduceGroups、map等操作。但其底层,执行的还是与DataFrame一样高效的DAG。
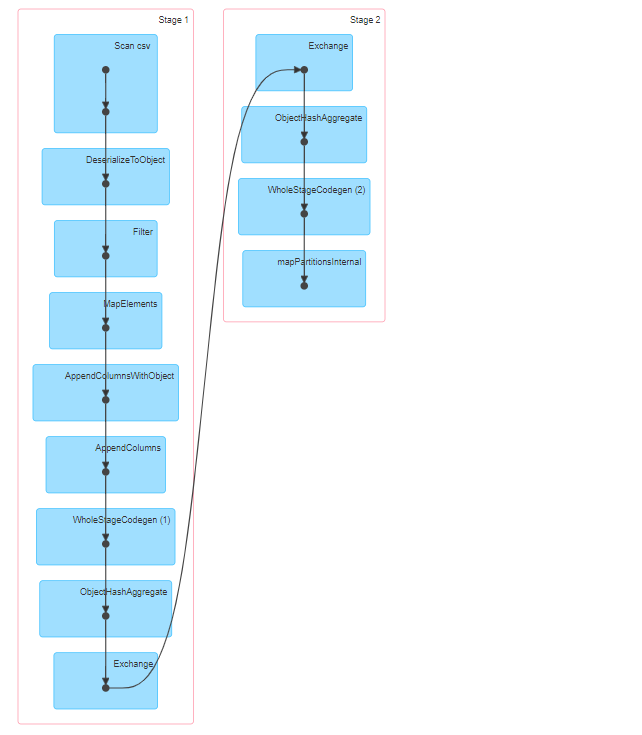
很明显,这个部门是我们编写的DSL得到的DAG代码。查看详细的执行过程:
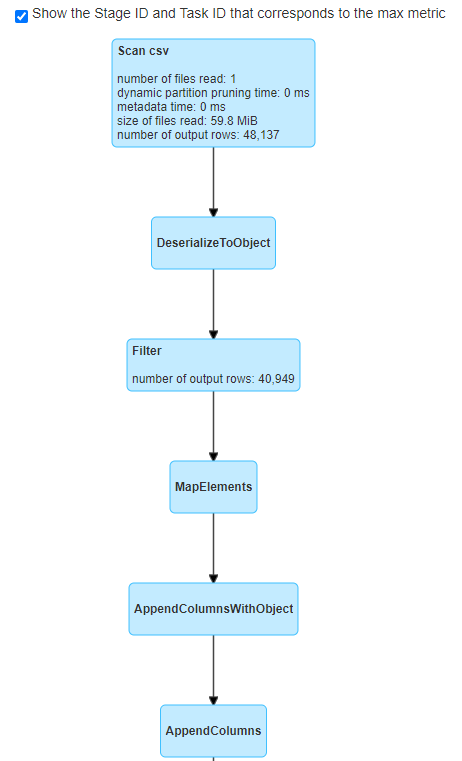
Spark依然给我们做了不少的一些优化动作。

看一下执行计划。
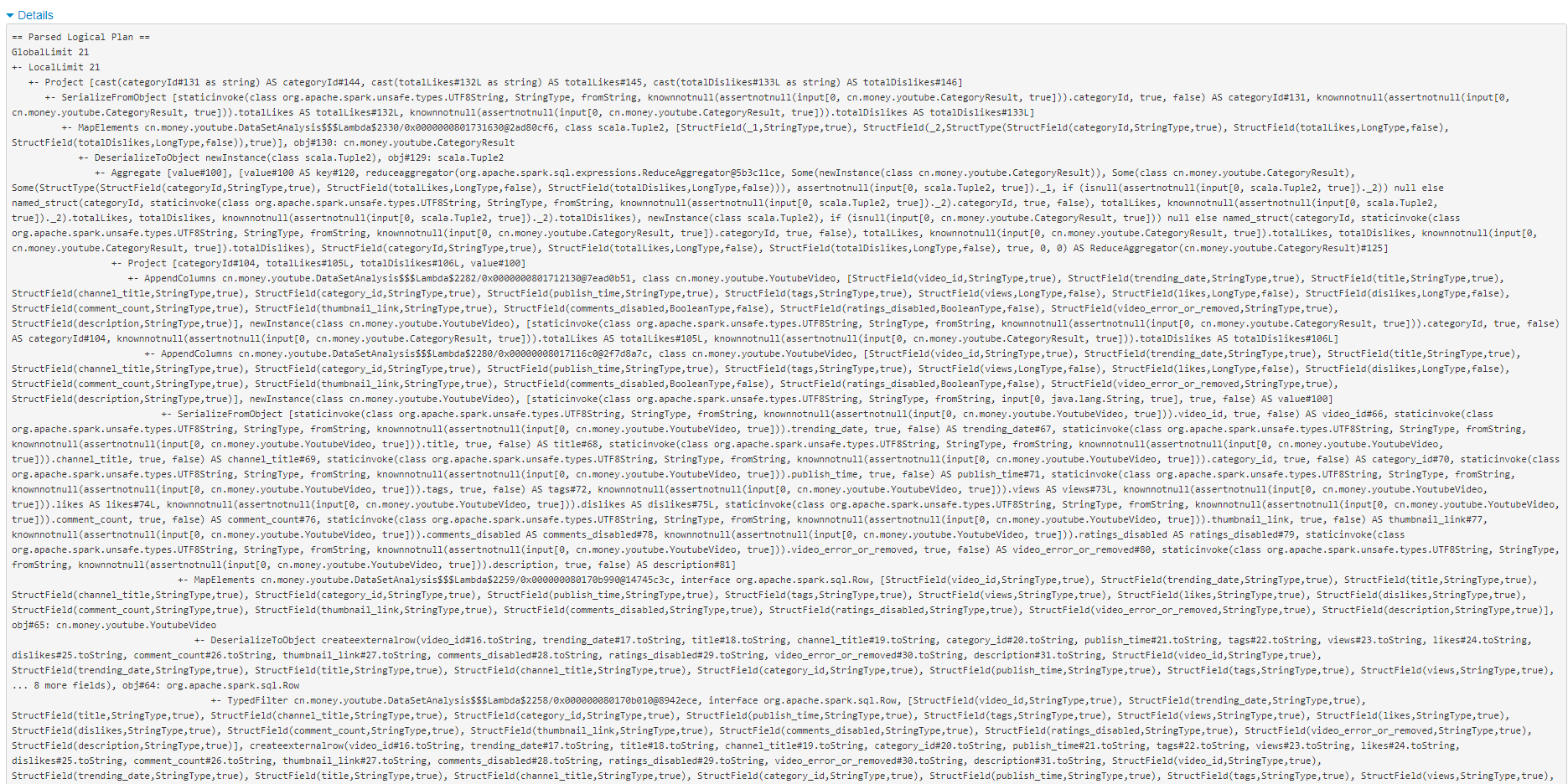
基于DataSet依然是有执行计划的。依然会基于Catalyst进行优化。但可以看到,这个实现明显比基于DataFrame的逻辑更加复杂,虽然做的事情差不太多。
对比RDD和DataSet的API
- RDD的操作都是最底层的,Spark不会做任何的优化。是low level的API,无法执行schema的高阶声明式操作
- DataSet支持很多类似于RDD的功能函数,而且支持DataFrame的所有操作。其实我们前面看到了DataFrame就是一种特殊的、能力稍微弱一点的DataSet。DataSet是一种High Level的API,在效率上比RDD有很大的提升。
对比RDD、DataFrame、DataSet
| RDD | DataFrame | DataSet | |
|---|---|---|---|
| schema | 无 需要自己建立shcema |
有 支持自动识别schema |
有schema 支持自动识别schema |
| 聚合操作 | 慢 | 最快 | 快 |
| 自动性能优化 | 无 开发人员自己优化 |
有 | 有 |
| 类型安全 | 安全 | 非安全 | 安全 |
| 序列化 | Java序列化,存储/读取整个Java对象 | Tungsten,堆外内存,可以按需存储访问属性 | Tungsten,堆外内存,可以按需存储访问属性 |
| 内存使用率 | 低 | 高 | 高 |
| GC | 创建和销毁每一个对象都有GC开销 | 无需GC,使用堆外存储 | 无需GC,使用堆外存储 |
| 懒执行 | 支持 | 支持 | 支持 |
参考文献
[1]https://spark.apache.org/docs/latest/rdd-programming-guide.html
[2]https://spark.apache.org/docs/latest/sql-programming-guide.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号