第一次个人编程作业
作业概述
| 这个作业属于哪个课程 | 班级链接 |
|---|---|
| 这个作业要求在哪里 | 作业链接 |
| 这个作业的目标 | 实现论文查重作业,掌握单元测试,以及commit语法 |
一.github作业链接
二.PSP表格
| 这个作业属于哪个课程 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 30 |
| ·Estimate | 估计这个任务需要多少时间 | 250 | 270 |
| Development | 开发 | 100 | 120 |
| ·Analysis | ·需求分析(包括学习新技术) | 30 | 25 |
| ·Design Sepc | ·生成设计文档 | 15 | 14 |
| ·Design Review | ·设计复审 | 20 | 25 |
| ·Coding Standard | ·代码规范(为目前的开发制定 合适的规范) | 60 | 45 |
| ·Design | ·具体设计 | 20 | 25 |
| ·Coding | ·具体编码 | 150 | 160 |
| ·Coding Review | ·代码复审 | 40 | 45 |
| ·Test | ·测试(自我测试,修改代码,提交修改) | 50 | 60 |
| Reporting | 报告 | 30 | 40 |
| ·Test Report | ·测试报告 | 60 | 65 |
| ·Size Measurement | ·计算工作量 | 20 | 25 |
| ·Postmortem & Process Improvement Plan | ·事后总结,并提出进程修改计划 | 30 | 35 |
| ·合计 | 895 | 984 |
三.实现思路
程序使用KMP算法在第一个文本中寻找第二个文本的子串,KMP算法通过构建部分匹配表(Partial Match Table)来避免不必要的回溯,提高字符串匹配的效率,然后程序使用动态规划算法计算两个文本之间的编辑距离。动态规划算法通过填充一个二维数组来记录状态值,其中dp[i][j]表示将第一个文本的前i个字符转换为第二个文本的前j个字符所需的最少操作次数。
具体计算步骤如下:
- 初始化数组的第一行和第一列,表示将一个空字符串转换为另一个字符串所需的操作次数。
- 从第二行和第二列开始,遍历数组的每个元素。
- 如果第一个文本的第i个字符等于第二个文本的第j个字符,则dp[i][j]等于dp[i-1][j-1],表示不需要进行任何操作。
- 如果第一个文本的第i个字符不等于第二个文本的第j个字符,则dp[i][j]等于左边、上边和左上角三个元素中的最小值加1,表示需要进行插入、删除或替换操作。
- 最后,dp[len1][len2]即为两个文本之间的编辑距离,其中len1和len2分别表示两个文本的长度。
四.模块实现
chesischeck类的重要函数:
- 传入命令行参数
ChesisCheck(const std::string& origTxtPath, const std::string& orig_addTxtPath, const std::string& ansTxtPath); - 计算编辑距离
float CalEditDIstance(const wstring& str1,const wstring& str2); - 计算运行时间
void CalRunTime();
main函数
int main(int argc,char*argv[])
{
ChesisCheck chesischeck(argv[1],argv[2],argv[3]);
chesischeck.Init(argc, argv);
chesischeck.Start();
return 0;
}
计算编辑距离
float CalEditDIstance(const wstring& str1,const wstring& str2)
{
int len1 = str1.size();
int len2 = str2.size();
vector<vector<int>> dp(len1 + 1, vector<int>(len2 + 1));
// KMP 算法
vector<int> lps(len1);
int len = 0;
int i = 1;
while (i < len1) {
if (static_cast<int>(str1[i]) == static_cast<int>(str1[len])) {
len++;
lps[i] = len;
i++;
}
else {
if (len != 0) {
len = lps[len - 1];
}
else {
lps[i] = 0;
i++;
}
}
}
for (int i = 1; i <= len1; i++) {
for (int j = 1; j <= len2; j++) {
if (static_cast<int>(str1[i - 1]) == static_cast<int>(str2[j - 1])) {
dp[i][j] = dp[i - 1][j - 1];
}
else {
dp[i][j] = min(min(dp[i][j - 1], dp[i - 1][j]), dp[i - 1][j - 1]) + 1;
}
}
}
return dp[len1][len2];
}
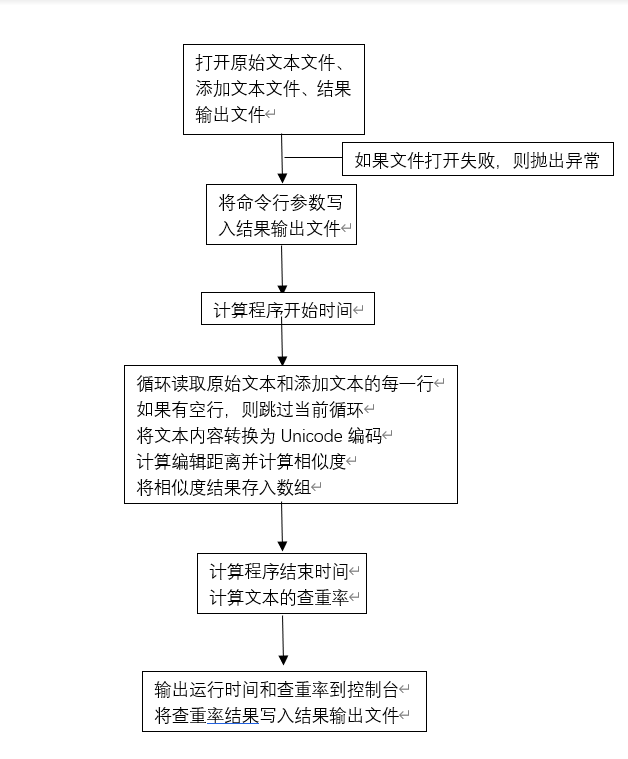
程序流程图
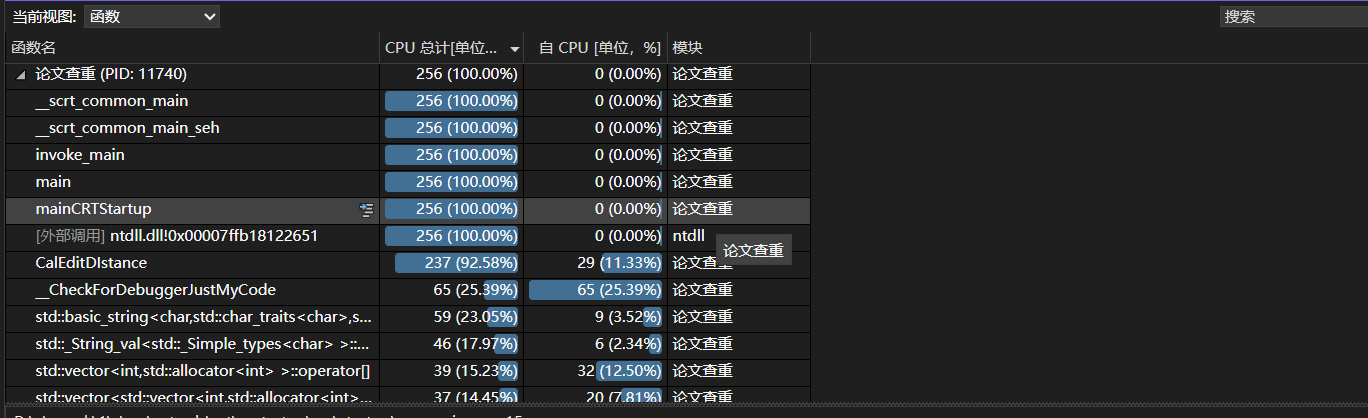
性能测试
最初性能

最初函数用时
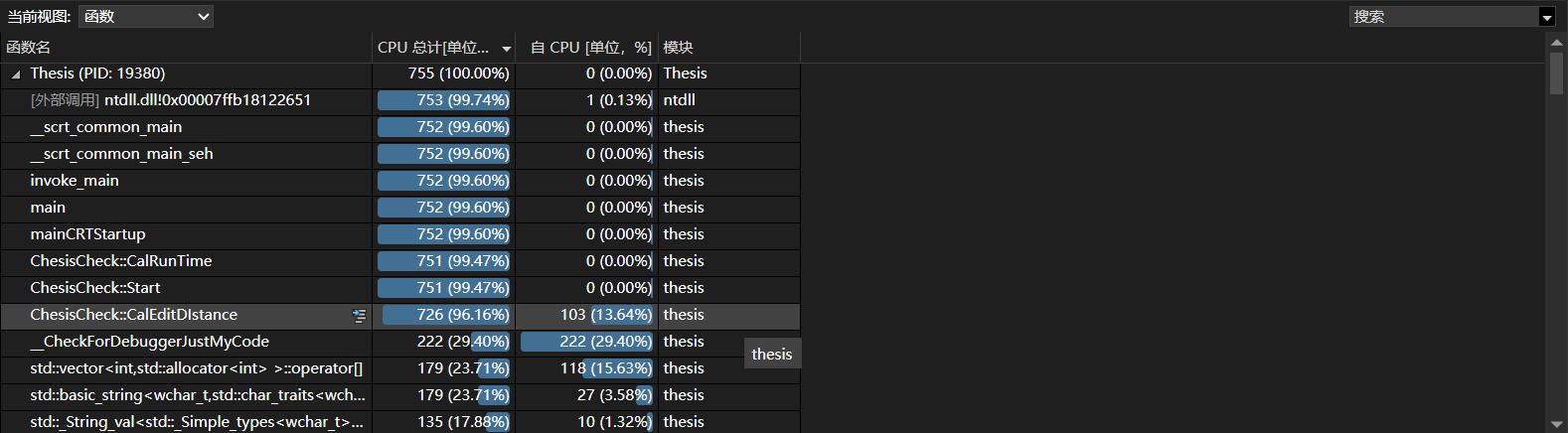
优化性能思路
采用智能指针来优化内存管理,同时将utf-8码转换成Unicode码,初始版本未采用kmp+动态规划算法进行设计,现采用此方法提高效率。
优化后性能

优化后函数用时
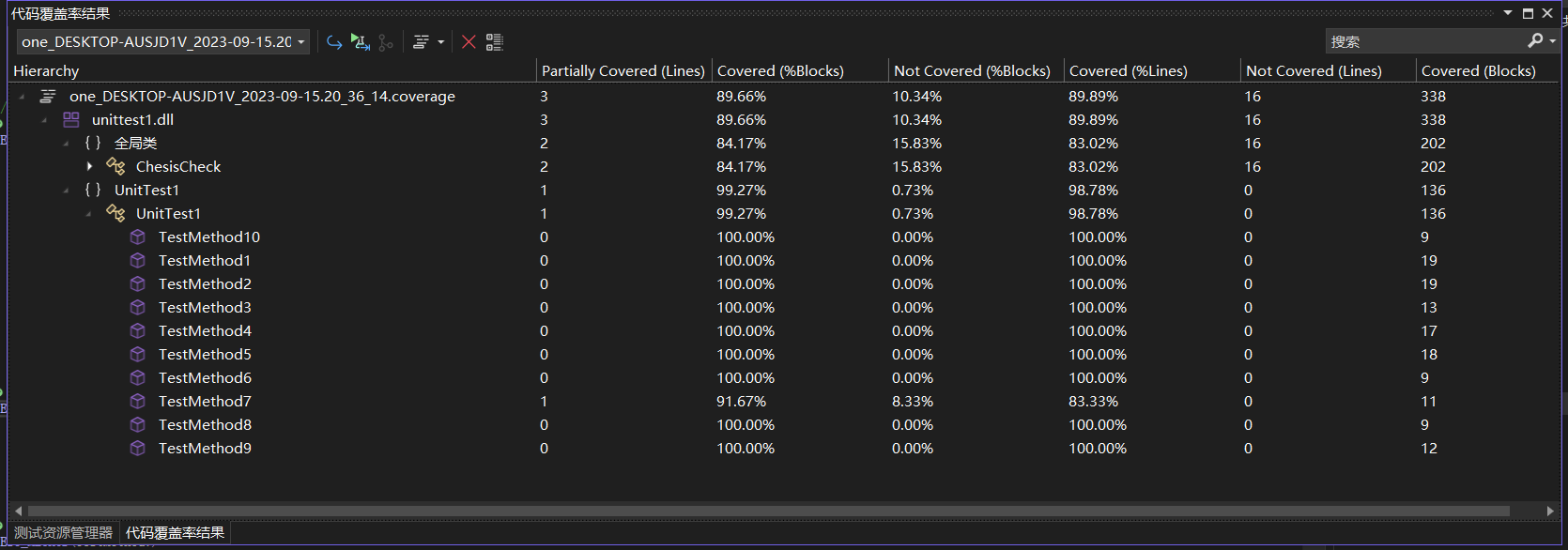
代码覆盖率
未覆盖的代码是控制异常代码
运行结果
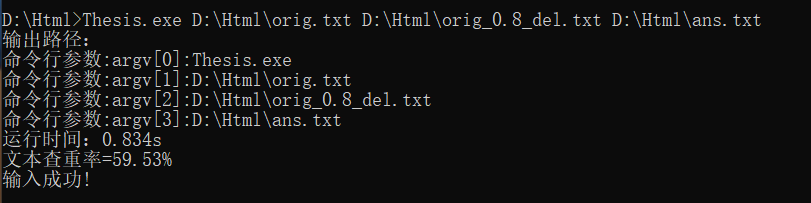
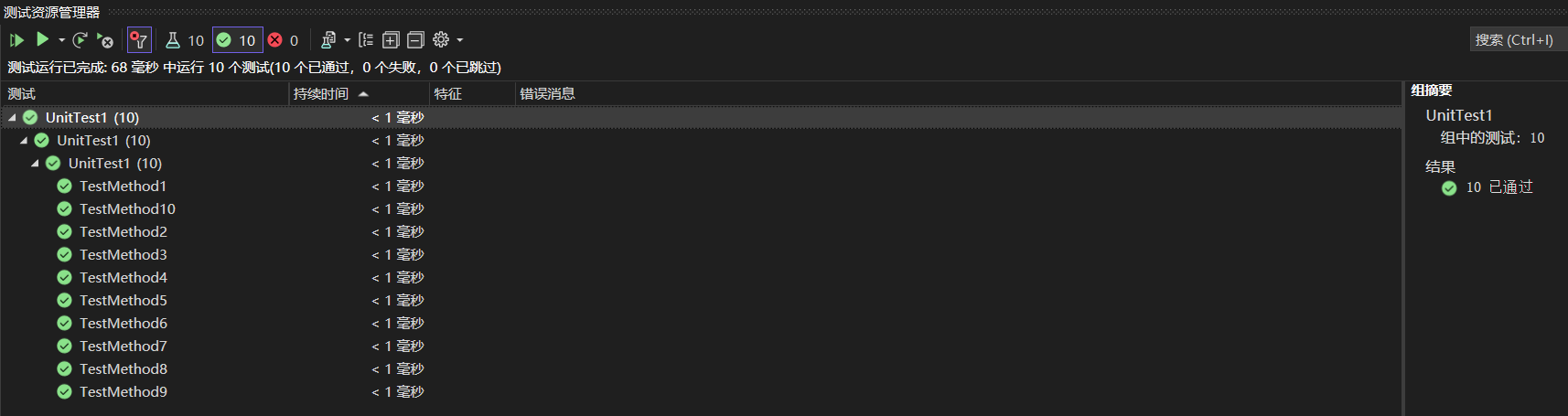
单元测试
测试两个相同的字符之间求的编辑距离是否为0
TEST_METHOD(TestMethod4)
{
ChesisCheck chesischeck;
string str1 = "abc";
string str2 = "abc";
wstring wstr1 = chesischeck.TransUTF8toUnicode(str1);
wstring wstr2 = chesischeck.TransUTF8toUnicode(str2);
float res = chesischeck.CalEditDIstance(wstr1, wstr2);
Assert::AreEqual(res, (float)0, L"testwarning");
}
测试转化“。”时得到的字符串是否为空
TEST_METHOD(TestMethod3)
{
ChesisCheck chesischeck;
string s1 = "。";
wstring w = chesischeck.TransUTF8toUnicode(s1);
bool isEmpty = w.empty();
Assert::AreEqual(isEmpty, (bool)false, L"testwarning");
}
测试两个相同的字符之间求的运算时间是否趋近于0
TEST_METHOD(TestMethod5)
{
clock_t start, end;
start = clock();
ChesisCheck chesischeck;
string str1 = "abc";
string str2 = "abc";
float ans = 0;
wstring wstr1 = chesischeck.TransUTF8toUnicode(str1);
wstring wstr2 = chesischeck.TransUTF8toUnicode(str2);
end = clock();
ans = 1.0 * (end - start) / CLOCKS_PER_SEC;
Assert::AreEqual(ans, (float)0, L"testwarning");
}
异常处理
输入文件不对,命令参数不对
ChesisCheck::ChesisCheck(const std::string& origTxtPath, const std::string& orig_addTxtPath, const std::string& ansTxtPath) :
origTxt(origTxtPath), orig_addTxt(orig_addTxtPath), ansTxt(ansTxtPath, std::ios::out | std::ios::app),
origTxtPath(origTxtPath), orig_addTxtPath(orig_addTxtPath), ansTxtPath(ansTxtPath)
{
destroy = true;
if (!origTxt.is_open() || !orig_addTxt.is_open() || !ansTxt.is_open()) {
cerr << "文件打开失败,请检查文件路径。" << std::endl;
throw runtime_error("文件打开失败");
}
}
进行文件读取时,文件不可读
float ChesisCheck::CalEditDIstance(const wstring& str1, const wstring& str2)
{
try {
auto len1 = str1.size();
auto len2 = str2.size();
vector<vector<int>> dp(len1 + 1, vector<int>(len2 + 1));
// KMP 算法
vector<int> lps(len1);
int len = 0;
int i = 1;
while (i < len1) {
if (static_cast<int>(str1[i]) == static_cast<int>(str1[len])) {
len++;
lps[i] = len;
i++;
}
else {
if (len != 0) {
len = lps[len - 1];
}
else {
lps[i] = 0;
i++;
}
}
}
for (int i = 1; i <= len1; i++) {
for (int j = 1; j <= len2; j++) {
if (static_cast<int>(str1[i - 1]) == static_cast<int>(str2[j - 1])) {
dp[i][j] = dp[i - 1][j - 1];
}
else {
dp[i][j] = min(min(dp[i][j - 1], dp[i - 1][j]), dp[i - 1][j - 1]) + 1;
}
}
}
return dp[len1][len2];
}
catch (const std::exception& e) {
std::cerr << "发生异常: " << e.what() << std::endl;
// 处理异常情况,例如返回一个特定的错误码或抛出新的异常
throw;
}
}
转码失败
wstring ChesisCheck::TransUTF8toUnicode(const string& str)
{
wstring ans;
int size = MultiByteToWideChar(CP_UTF8, 0, str.c_str(), -1, NULL, 0);
if (size > 0) {
unique_ptr<wchar_t[]> buffer(new wchar_t[size]);
if (MultiByteToWideChar(CP_UTF8, 0, str.c_str(), -1, buffer.get(), size) > 0) {
ans = buffer.get();
}
else {
// 转换失败,抛出异常或者进行其他错误处理
throw runtime_error("转换UTF-8到Unicode失败");
}
}
else {
// 转换失败,抛出异常或者进行其他错误处理
throw runtime_error("获取转换后字符串长度失败");
}
return ans;
}
注:运行文件时要么采用cmd的命令参数输入,要么在vs中手动输入命令行参数,否则程序会报错无法执行!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号