springBoot 整合 kafka zookeeper spark实时监控消费 一秒内处理千万条数据
这里为了照顾菜鸟 小白 我用大量的 截图 以及白话阐述
1.环境:虚拟机 Linux7.X docker JDK11 zookeeper spark kafka 安装部署 全部都是 集成在docker中的 安装步骤关注我的相关文档 比较复杂 测试期间 可以部署单节点
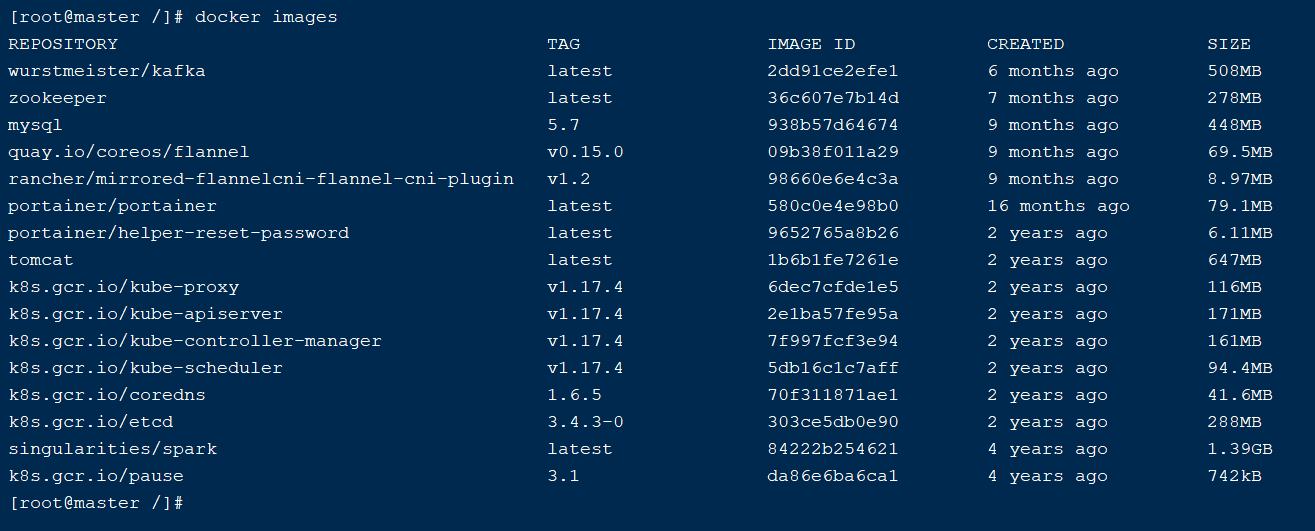
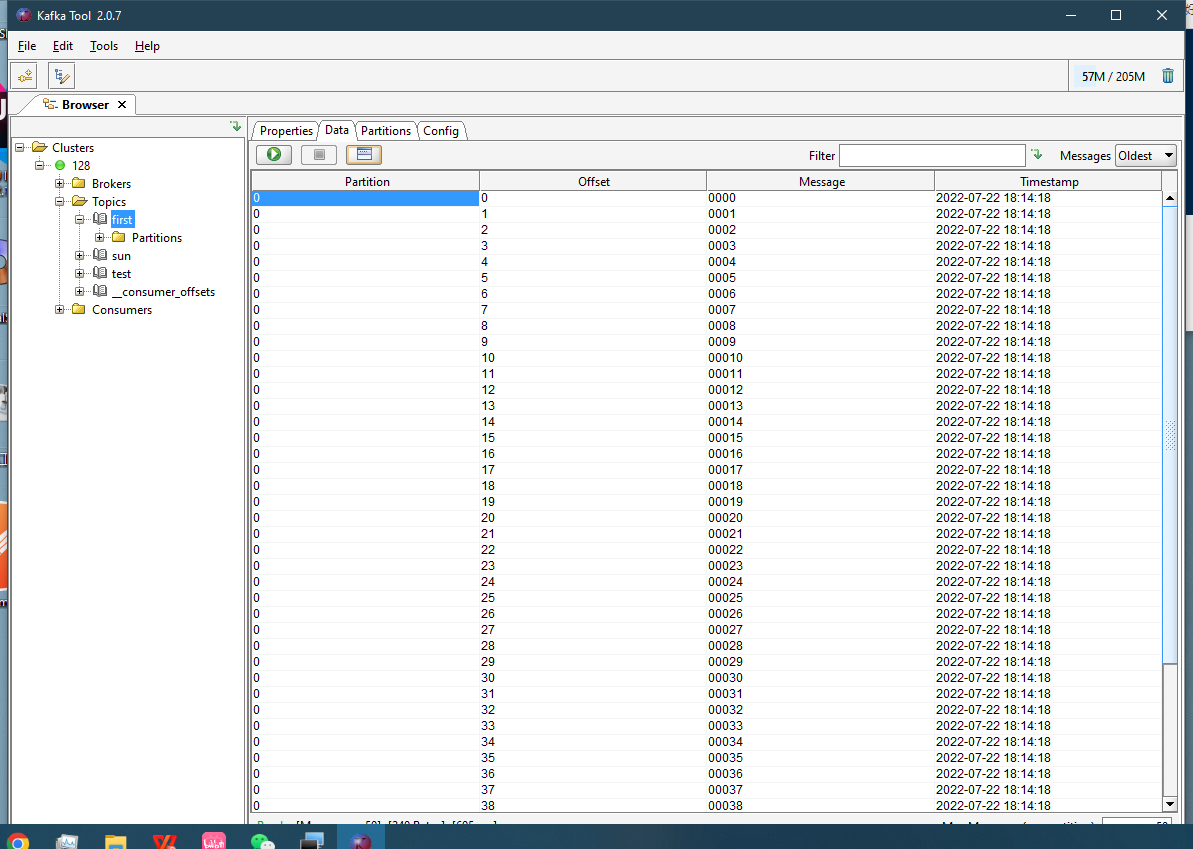
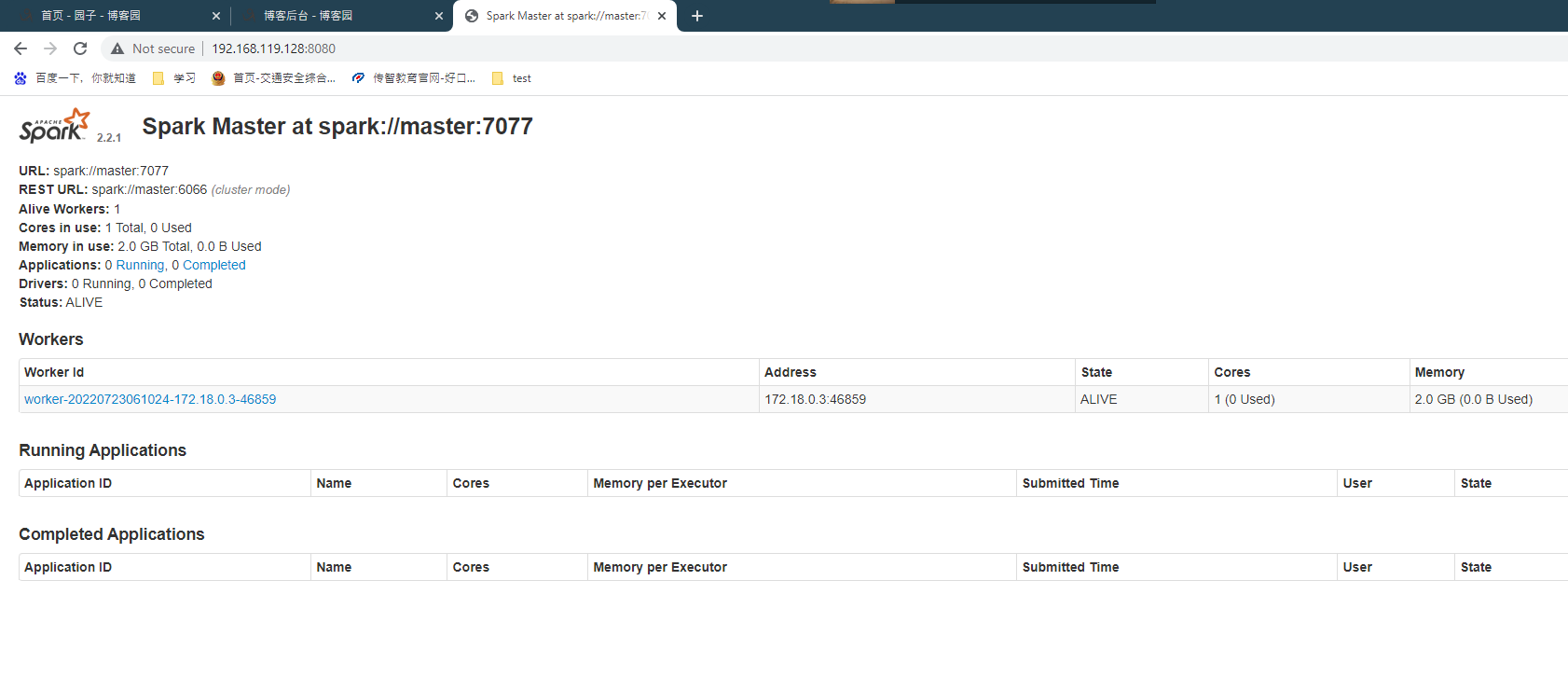
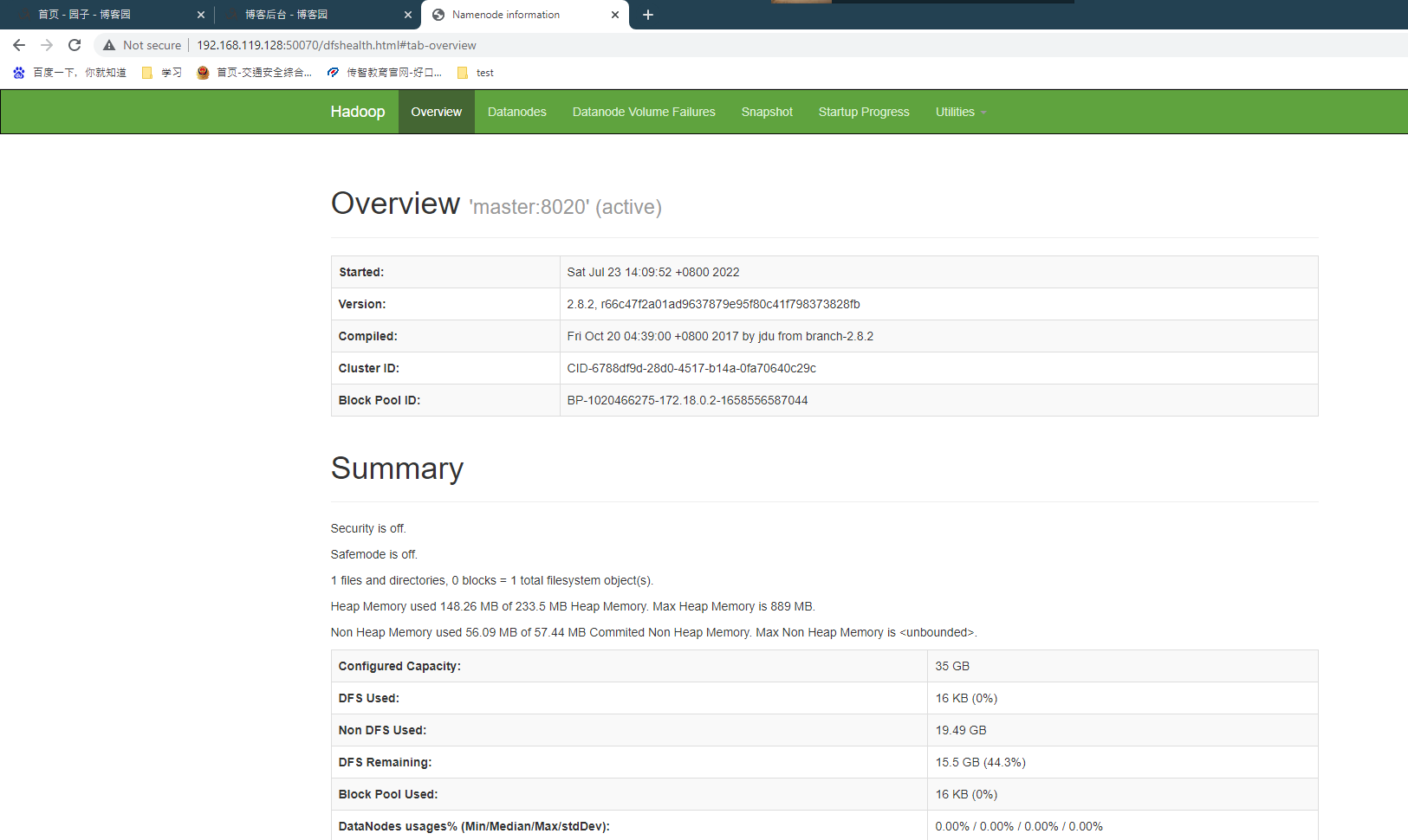
2.安装成功截图:
2.springboot 编写 生产者代码:
pom.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.6.7</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.atguigu</groupId>
<artifactId>springboot</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>springboot</name>
<description>springboot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
application.yml文件
spring:
application:
name: atguigu-springboot-kafka
kafka:
bootstrap-servers: 192.168.119.128:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
Java 代码
package com.example.demo;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.concurrent.ExecutionException;
@RestController
public class ProducerController {
/**
* Kafka 模板用来向 kafka 发送数据
*/
@Autowired
private KafkaTemplate<String, String> kafkaString;
@RequestMapping("/atguigu")
public String data(String msg) {
for (int i = 0; i <= 10; i++) {
ListenableFuture<SendResult<String, String>> send = kafkaString.send("first", msg + i);
try {
RecordMetadata recordMetadata = send.get().getRecordMetadata();
long offset = recordMetadata.offset();
String topic = recordMetadata.topic();
int partition = recordMetadata.partition();
System.out.println("offset==" + offset+"---------topic-----" + topic + "----------partition-----------" + partition);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
return "kafka生产数据success!";
}
}
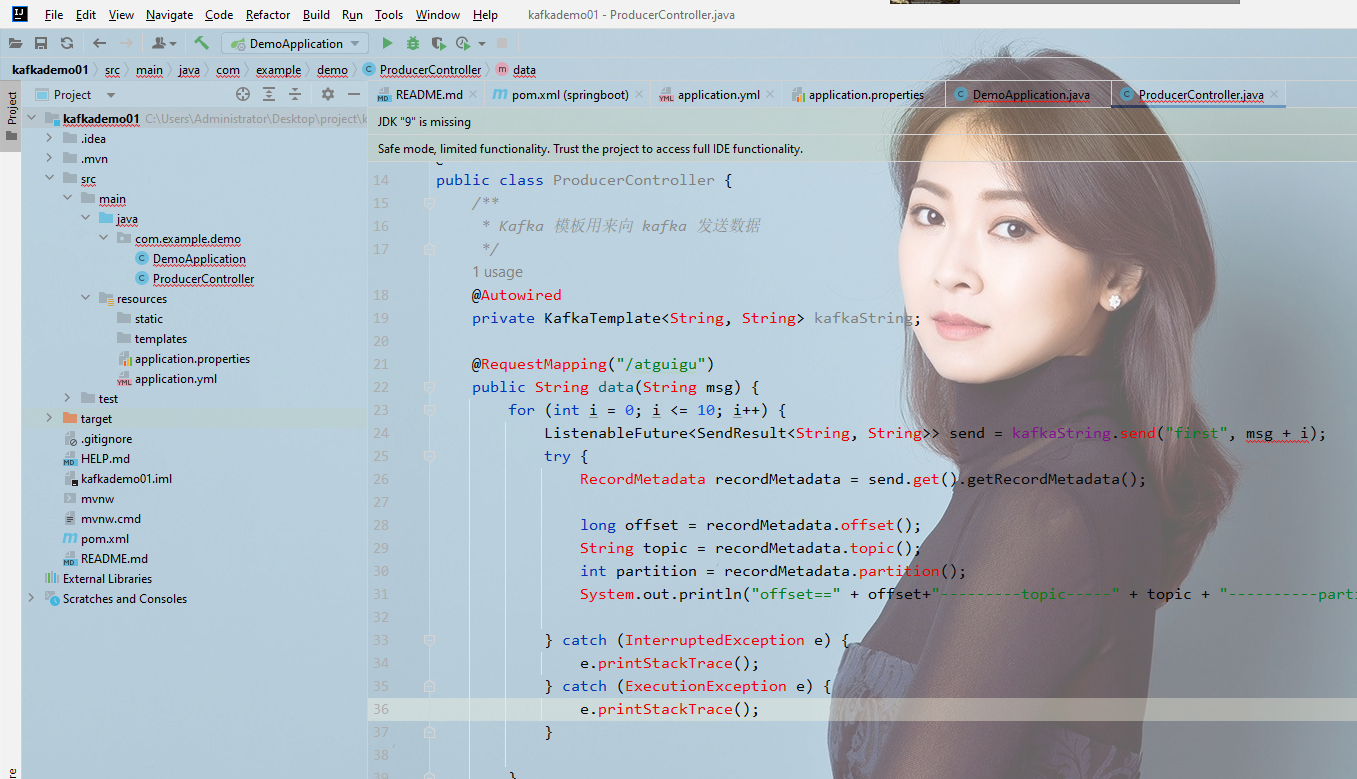
项目结构: 这个为什么我要截图 就怕你们按照这个启动不来
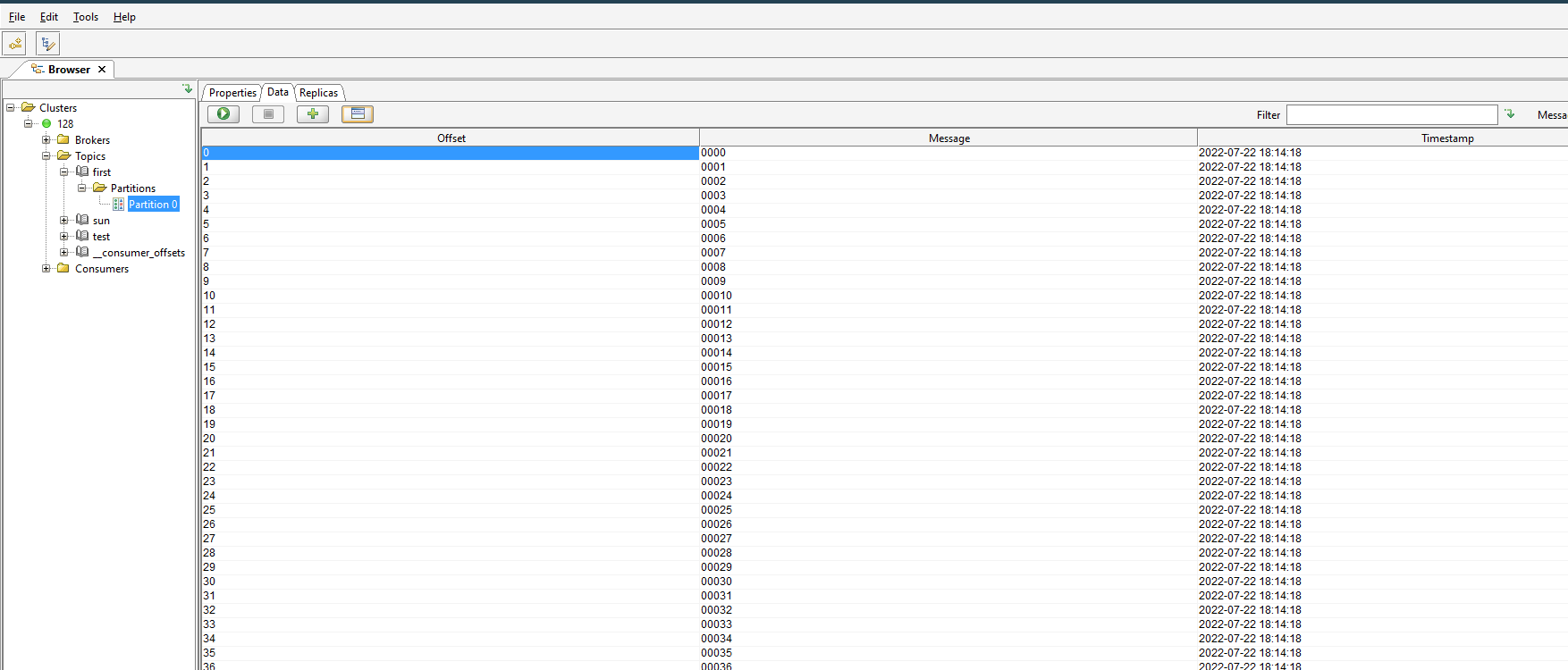
启动成功 往kafka里面推数据:
编写 spark消费中心:
注意:必须使用 JDK11 我当时出现各种问题 后来折腾两个小时
pom.xml文件 不要问 为什么 你就照这个复制 我已经测试测试成功 各个版本ok
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.heima.kafka</groupId>
<artifactId>kafka_book_demo</artifactId>
<version>1.0-SNAPSHOT</version>
<description>
Kafka学习
</description>
<properties>
<scala.version>2.11</scala.version>
<slf4j.version>1.7.21</slf4j.version>
<kafka.version>2.0.0</kafka.version>
<lombok.version>1.18.8</lombok.version>
<junit.version>4.11</junit.version>
<gson.version>2.2.4</gson.version>
<protobuff.version>1.5.4</protobuff.version>
<spark.version>2.3.1</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_${scala.version}</artifactId>
<version>${kafka.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>${gson.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>io.protostuff</groupId>
<artifactId>protostuff-core</artifactId>
<version>${protobuff.version}</version>
</dependency>
<dependency>
<groupId>io.protostuff</groupId>
<artifactId>protostuff-runtime</artifactId>
<version>${protobuff.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>${kafka.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.9.4</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.module</groupId>
<artifactId>jackson-module-scala_2.11</artifactId>
<version>2.9.5</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.58</version>
</dependency>
<!-- <dependency>-->
<!-- <groupId>org.apache.storm</groupId>-->
<!-- <artifactId>storm-core</artifactId>-->
<!-- <version>1.1.3</version>-->
<!-- </dependency>-->
<!-- <dependency>-->
<!-- <groupId>org.apache.storm</groupId>-->
<!-- <artifactId>storm-kafka</artifactId>-->
<!-- <version>1.1.3</version>-->
<!-- </dependency>-->
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
Java 代码:
package com.heima.kafka.spark;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
/**
* @Author dayuan
* Kafka整合Spark
*/
public class SparkStreamingFromkafka {
public static void main(String[] args) throws Exception {
SparkConf sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreamingFromkafka");
// SparkConf sparkConf = new SparkConf();
JavaStreamingContext streamingContext = new JavaStreamingContext(sparkConf, Durations.seconds(10));
Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put("bootstrap.servers", "192.168.119.128:9092");//多个可用ip可用","隔开
kafkaParams.put("key.deserializer", StringDeserializer.class);
kafkaParams.put("value.deserializer", StringDeserializer.class);
kafkaParams.put("group.id", "sparkStreaming");
Collection<String> topics = Arrays.asList("first");//配置topic,可以是数组
JavaInputDStream<ConsumerRecord<String, String>> javaInputDStream = KafkaUtils.createDirectStream(
streamingContext,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.Subscribe(topics, kafkaParams));
JavaPairDStream<String, String> javaPairDStream = javaInputDStream.mapToPair(new PairFunction<ConsumerRecord<String, String>, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(ConsumerRecord<String, String> consumerRecord) throws Exception {
return new Tuple2<>(consumerRecord.key(), consumerRecord.value());
}
});
javaPairDStream.foreachRDD(new VoidFunction<JavaPairRDD<String, String>>() {
@Override
public void call(JavaPairRDD<String, String> javaPairRDD) throws Exception {
javaPairRDD.foreach(new VoidFunction<Tuple2<String, String>>() {
@Override
public void call(Tuple2<String, String> tuple2)
throws Exception {
System.out.println(tuple2._2);
}
});
}
});
streamingContext.start();
streamingContext.awaitTermination();
System.out.println("spark监控智能中心启动成功!");
}
}
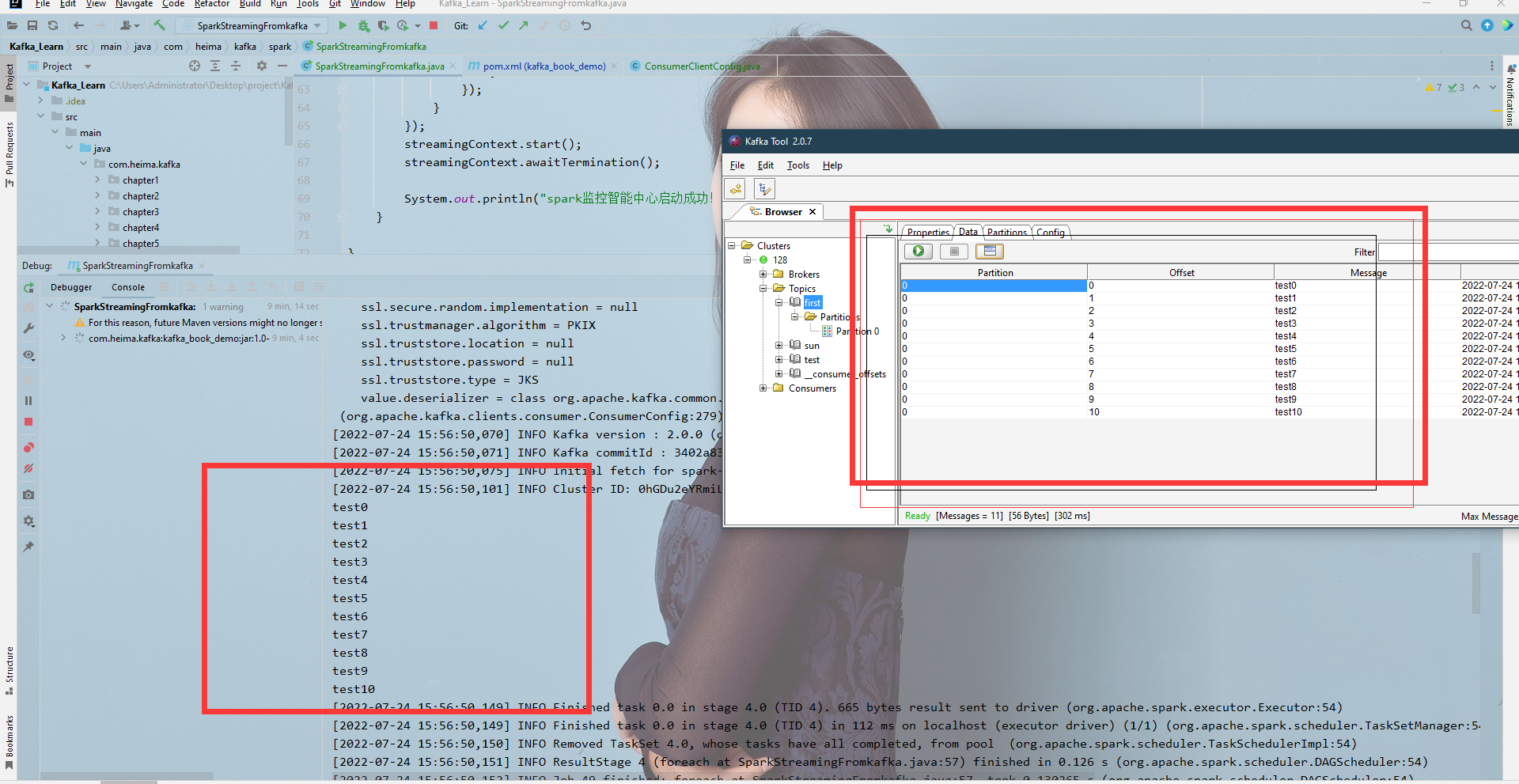
spark消费中心 测试

 浙公网安备 33010602011771号
浙公网安备 33010602011771号