
linux的简单使用
引言
linux是操作系统最典型的具体实现,本文章不求深度的讲解linux相关的知识,而是汇总一些在软件测试工作当中可能用到的操作
背景
- 软件开发和软件测试可能会用到
- linux是目前服务器最常用的操作系统
linux基础命令
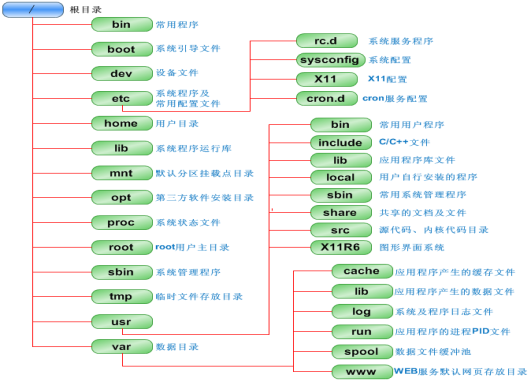
linux系统目录结构
查看系统的网络状态 —ifconfig
判断远端网络功能是否正常—ping
目录操作:查看目录— ls
目录操作:切换目录— cd
目录操作:查看路径—pwd
目录操作:创建目录— mkdir
文件操作:创建文件—touch
目录操作:删除目录—rm/rmdir
文件操作: 移动文件— mv
文件操作: 复制文件— cp
文件操作: 文件重命名—rename
文件编辑—vi
文件操作: 查看文件内容—cat/more/less
文件操作: 查看文件头/尾部内容—head /tail
查找文件命令 — find
查找包括字符串的文件 —grep
查看系统程序执行—ps
中止进程执行—kill
查看内存进程情况—top
压缩或解压文件 — gzip
压缩或解压文件 — tar
*.tar 用 tar –xvf 解压
*.gz 用 gzip -d或者gunzip 解压
*.tar.gz和*.tgz 用 tar –xzf 解压
*.bz2 用 bzip2 -d或者用bunzip2 解压
*.tar.bz2用tar –xjf 解压
*.Z 用 uncompress 解压
*.tar.Z 用tar –xZf 解压
*.rar 用 unrar 解压
*.zip 用 unzip 解压
显示指定的目录或文件所占用的磁盘空间—du
显示磁盘的使用状况—df
新建用户—useradd
删除用户—userdel
新增用户组——groupadd
删除用户组groupdel
修改密码——passwd
切换用户——su
grep grep_code grepfile* --color
ps -ef | grep java
管道符的使用
在Linux中,管道符(|) 是一种强大的命令组合工具,用于将前一个命令的输出直接作为后一个命令的输入。这种机制允许用户将多个简单命令组合成复杂的操作,大幅提升效率。以下是管道符的核心用法、经典场景及注意事项:
一、基本语法与原理
1. 语法格式
命令1 | 命令2 | 命令3 ...
- 工作流程:
命令1执行并产生输出- 管道符
|将输出传递给命令2作为输入 命令2处理输入并产生新的输出,依此类推...
2. 关键点
- 数据流单向流动:从左到右,不可逆向。
- 仅传递标准输出(stdout):错误输出(stderr)不会通过管道传递,需单独处理(如
2>&1)。
二、经典应用场景
1. 过滤与搜索
- 示例1:查找包含关键词的进程
ps -ef | grep java # 查找Java相关进程 - 示例2:统计目录下的文件数量
ls -l | wc -l # 统计当前目录文件行数(含总用量行)
2. 文本处理流水线
- 示例:提取日志中的错误信息并统计次数
cat app.log | grep ERROR | awk '{print $4}' | sort | uniq -ccat app.log:读取日志文件grep ERROR:过滤包含ERROR的行awk '{print $4}':提取第4列(假设为错误类型)sort | uniq -c:排序并统计重复次数
3. 实时监控与格式化
- 示例:监控CPU使用率并格式化输出
top -b -n 1 | grep Cpu | awk '{print "CPU使用率: " $2 "%" }'top -b -n 1:以批处理模式执行一次topgrep Cpu:提取CPU行awk:格式化输出为易读文本
4. 数据传输与压缩
- 示例:远程备份文件并压缩
tar -cvf - /data | ssh user@remote "cat > /backup/data.tar"tar -cvf - /data:将/data目录打包(-表示输出到标准输出)ssh ... "cat > /backup/data.tar":通过SSH将数据写入远程文件
三、高级技巧与组合命令
1. 多管道串联
- 示例:查找最大的10个文件并格式化输出
find / -type f -exec du -h {} + | sort -rh | head -n 10find / -type f -exec du -h {} +:递归查找所有文件并显示大小sort -rh:按大小降序排序(-h处理人类可读格式)head -n 10:取前10条
2. 结合xargs执行批量操作
- 示例:删除30天前的日志文件
find /var/log -type f -mtime +30 | xargs rm -ffind ... -mtime +30:查找30天前修改的文件xargs rm -f:将文件名作为参数传递给rm命令
3. 处理错误输出
- 示例:捕获并记录错误日志
command_that_might_fail 2>&1 | tee error.log2>&1:将错误输出(stderr)重定向到标准输出(stdout)tee error.log:同时输出到屏幕和文件
四、注意事项与常见陷阱
1. 管道命令的执行顺序
- 管道左侧的命令未执行完时,右侧命令可能已开始处理数据(流式处理)。
- 示例:
输出会逐行延迟1秒显示,而非等待全部输入后一次性处理。echo "1\n2\n3" | while read line; do sleep 1; echo $line; done
2. 管道中的变量作用域问题
- 在
bash中,管道右侧的命令会在子shell中执行,导致变量无法传递到父shell。 - 错误示例:
echo "hello" | var=$(cat); echo $var # 输出为空 - 正确方式(避免子shell):
var=$(echo "hello"); echo $var # 输出hello
3. 处理大量数据时的性能
- 管道链过长可能导致性能下降,可考虑:
- 使用临时文件分段处理
- 优先选择原生支持多阶段处理的工具(如
awk、sed)
五、管道符 vs 重定向符
| 符号 | 功能 | 示例 |
|---|---|---|
> |
输出重定向到文件 | ls > files.txt |
< |
文件内容作为命令输入 | wc -l < files.txt |
| |
命令输出作为另一个命令输入 | `ls -l |
>> |
追加输出到文件 | echo "text" >> log.txt |
2> |
重定向错误输出 | command 2> error.log |
2>&1 |
合并错误输出和标准输出 | command 2>&1 | grep "ERROR" |
六、实用案例:监控服务器负载
while true; do
uptime | awk -F'load average:' '{print $2}' | tr -d '\n' | tee -a load.log;
sleep 60;
done
- 每分钟记录一次系统负载到
load.log uptime:获取系统负载信息awk:提取负载值部分tr -d '\n':删除换行符tee -a load.log:同时输出到屏幕和追加到文件
总结
管道符是Linux命令行的核心工具之一,通过组合简单命令可以实现复杂功能。熟练掌握管道的使用能大幅提升运维效率,但需注意数据流方向、错误处理和性能问题。建议结合 grep、awk、sed、xargs 等工具深入实践,逐步构建强大的命令组合。
shell脚本语言
shell脚本在实际软件工程中的使用
在软件工程中,Shell脚本常用于自动化构建、部署、监控、测试等环节,以下是6个典型应用场景及代码实现:
1. 自动化部署脚本(Git拉取+服务重启)
#!/bin/bash
# 部署脚本:拉取代码 → 编译 → 重启服务
# 配置信息
APP_DIR="/opt/myapp"
GIT_REPO="git@github.com:user/myapp.git"
BRANCH="main"
LOG_FILE="/var/log/deploy.log"
# 日志函数
log() {
echo "[$(date '+%Y-%m-%d %H:%M:%S')] $1" >> $LOG_FILE
}
# 错误处理
handle_error() {
log "Error: $1"
echo "部署失败: $1"
exit 1
}
# 主流程
log "开始部署..."
# 拉取代码
cd $APP_DIR || handle_error "应用目录不存在"
git pull origin $BRANCH || handle_error "Git拉取失败"
# 编译(示例:Maven项目)
if [ -f "pom.xml" ]; then
mvn clean package -DskipTests || handle_error "编译失败"
fi
# 重启服务
systemctl restart myapp.service || handle_error "服务重启失败"
# 检查服务状态
sleep 5
if ! systemctl is-active --quiet myapp.service; then
handle_error "服务未正常启动"
fi
log "部署成功!"
echo "部署完成"
2. 定时备份脚本(数据库+文件)
#!/bin/bash
# 定时备份脚本:备份数据库和重要文件
# 配置信息
BACKUP_DIR="/data/backups"
DB_USER="root"
DB_PASS="password"
DB_NAME="mydb"
FILES_TO_BACKUP="/opt/myapp/config /var/www/html"
RETENTION_DAYS=7
# 创建备份目录
mkdir -p $BACKUP_DIR/$(date +%Y%m%d)
# 备份数据库
mysqldump -u$DB_USER -p$DB_PASS $DB_NAME > $BACKUP_DIR/$(date +%Y%m%d)/db_backup.sql
if [ $? -ne 0 ]; then
echo "数据库备份失败" >&2
exit 1
fi
# 备份文件
tar -czf $BACKUP_DIR/$(date +%Y%m%d)/files_backup.tar.gz $FILES_TO_BACKUP
if [ $? -ne 0 ]; then
echo "文件备份失败" >&2
exit 1
fi
# 删除旧备份
find $BACKUP_DIR -type d -mtime +$RETENTION_DAYS -exec rm -rf {} \;
echo "备份完成: $BACKUP_DIR/$(date +%Y%m%d)"
3. 服务监控与自动恢复
#!/bin/bash
# 服务监控脚本:检测服务状态,异常时自动重启
# 配置信息
SERVICE_NAME="nginx"
LOG_FILE="/var/log/service_monitor.log"
RESTART_THRESHOLD=3 # 连续失败次数触发重启
# 日志函数
log() {
echo "[$(date '+%Y-%m-%d %H:%M:%S')] $1" >> $LOG_FILE
}
# 检查服务状态
status=$(systemctl is-active $SERVICE_NAME)
if [ "$status" != "active" ]; then
log "服务 $SERVICE_NAME 未运行"
# 获取失败次数
FAIL_COUNT_FILE="/tmp/${SERVICE_NAME}_fail_count"
if [ -f "$FAIL_COUNT_FILE" ]; then
fail_count=$(cat $FAIL_COUNT_FILE)
else
fail_count=0
fi
# 累计失败次数
((fail_count++))
echo $fail_count > $FAIL_COUNT_FILE
# 达到阈值则重启
if [ $fail_count -ge $RESTART_THRESHOLD ]; then
log "尝试重启 $SERVICE_NAME (失败次数: $fail_count)"
systemctl restart $SERVICE_NAME
# 验证重启结果
sleep 2
if [ "$(systemctl is-active $SERVICE_NAME)" = "active" ]; then
log "$SERVICE_NAME 重启成功"
echo 0 > $FAIL_COUNT_FILE # 重置计数器
else
log "$SERVICE_NAME 重启失败,通知管理员"
# 发送邮件或消息通知管理员
echo "服务 $SERVICE_NAME 连续失败 $RESTART_THRESHOLD 次,重启失败!" | mail -s "服务告警" admin@example.com
fi
else
log "未达到重启阈值 (当前: $fail_count/$RESTART_THRESHOLD)"
fi
else
# 服务正常,重置计数器
if [ -f "/tmp/${SERVICE_NAME}_fail_count" ]; then
echo 0 > /tmp/${SERVICE_NAME}_fail_count
fi
log "$SERVICE_NAME 运行正常"
fi
4. 代码质量检查(结合Git Hooks)
#!/bin/bash
# Git提交前检查:代码格式、单元测试
# 配置信息
SOURCE_DIR="src"
TEST_DIR="test"
LOG_FILE="/var/log/code_check.log"
# 日志函数
log() {
echo "[$(date '+%Y-%m-%d %H:%M:%S')] $1" >> $LOG_FILE
}
# 检查代码格式(示例:Python)
log "开始代码格式检查..."
flake8 $SOURCE_DIR
if [ $? -ne 0 ]; then
log "代码格式检查失败"
echo "代码格式错误,请修复后再提交!" >&2
exit 1
fi
# 运行单元测试(示例:Python)
log "开始单元测试..."
pytest $TEST_DIR
if [ $? -ne 0 ]; then
log "单元测试失败"
echo "单元测试未通过,请修复后再提交!" >&2
exit 1
fi
log "代码检查通过"
echo "代码检查通过"
exit 0
5. 批量文件处理(日志分析)
#!/bin/bash
# 日志分析脚本:统计HTTP请求状态码分布
# 配置信息
LOG_DIR="/var/log/nginx"
OUTPUT_FILE="/tmp/nginx_stats_$(date +%Y%m%d).txt"
# 初始化输出文件
echo "HTTP状态码统计 $(date)" > $OUTPUT_FILE
echo "------------------------" >> $OUTPUT_FILE
# 统计各状态码数量
for file in $LOG_DIR/access.log*; do
if [ -f "$file" ]; then
echo "分析文件: $file"
# 提取状态码并统计
awk '{print $9}' "$file" | sort | uniq -c | sort -nr >> $OUTPUT_FILE
fi
done
# 计算总请求数
total=$(grep -v '^-' $OUTPUT_FILE | awk '{sum+=$1} END {print sum}')
echo "总请求数: $total" >> $OUTPUT_FILE
echo "日志分析完成,结果已保存到: $OUTPUT_FILE"
6. 环境初始化脚本(多服务配置)
#!/bin/bash
# 环境初始化脚本:配置开发环境依赖
# 配置信息
USERNAME="developer"
GROUPNAME="developers"
WORK_DIR="/workspace"
# 检查是否为root用户
if [ "$(id -u)" -ne 0 ]; then
echo "请使用root用户运行此脚本" >&2
exit 1
fi
# 创建用户和工作目录
useradd -m -g $GROUPNAME $USERNAME
mkdir -p $WORK_DIR
chown -R $USERNAME:$GROUPNAME $WORK_DIR
# 安装基础软件
echo "安装基础软件..."
apt-get update
apt-get install -y git vim wget curl
# 安装语言环境(示例:Python)
echo "安装Python环境..."
apt-get install -y python3 python3-pip python3-venv
# 配置SSH密钥
echo "配置SSH密钥..."
mkdir -p /home/$USERNAME/.ssh
chmod 700 /home/$USERNAME/.ssh
touch /home/$USERNAME/.ssh/authorized_keys
chmod 600 /home/$USERNAME/.ssh/authorized_keys
chown -R $USERNAME:$GROUPNAME /home/$USERNAME/.ssh
# 配置Docker(可选)
if [ "$1" = "--with-docker" ]; then
echo "安装Docker..."
apt-get install -y docker.io
usermod -aG docker $USERNAME
fi
echo "环境初始化完成!"
echo "用户: $USERNAME"
echo "工作目录: $WORK_DIR"
应用场景总结
- 自动化部署:减少人工操作,确保部署一致性。
- 定时任务:定期执行备份、清理等操作,避免人工遗漏。
- 监控告警:实时监测服务状态,异常时自动响应。
- 代码质量保障:集成到Git工作流中,防止低质量代码提交。
- 批量数据处理:高效分析日志、转换文件格式等。
- 环境标准化:快速搭建开发/测试/生产环境,减少配置差异。
最佳实践:
- 使用函数封装重复逻辑,提高脚本可读性;
- 添加错误处理和日志记录,便于问题排查;
- 通过参数化配置增强脚本灵活性;
- 先在测试环境验证,再应用到生产环境。
好的,我将逐行解释这个部署脚本的功能和实现逻辑。这个脚本的核心是自动化完成代码拉取、编译和服务重启的过程,并包含了错误处理和日志记录功能。
脚本解析
#!/bin/bash
# 部署脚本:拉取代码 → 编译 → 重启服务
# 配置信息
APP_DIR="/opt/myapp"
GIT_REPO="git@github.com:user/myapp.git"
BRANCH="main"
LOG_FILE="/var/log/deploy.log"
这部分是脚本的开头,主要做了两件事:
#!/bin/bash:指定脚本使用Bash shell执行- 定义了几个全局变量,用于存储部署所需的配置信息:
APP_DIR:应用程序的目录GIT_REPO:Git仓库地址BRANCH:要部署的分支LOG_FILE:日志文件路径
# 日志函数
log() {
echo "[$(date '+%Y-%m-%d %H:%M:%S')] $1" >> $LOG_FILE
}
# 错误处理
handle_error() {
log "Error: $1"
echo "部署失败: $1"
exit 1
}
这里定义了两个函数:
log():用于记录日志,会在每条日志前加上时间戳,并将内容追加到LOG_FILE指定的文件中handle_error():用于错误处理,它会记录错误日志,打印错误信息,然后终止脚本执行(返回状态码1)
# 主流程
log "开始部署..."
# 拉取代码
cd $APP_DIR || handle_error "应用目录不存在"
git pull origin $BRANCH || handle_error "Git拉取失败"
这是部署的第一个主要步骤:拉取代码。脚本会:
- 切换到应用目录(
cd $APP_DIR),如果目录不存在则调用handle_error终止脚本 - 执行
git pull命令从远程仓库拉取最新代码,如果失败则终止脚本
# 编译(示例:Maven项目)
if [ -f "pom.xml" ]; then
mvn clean package -DskipTests || handle_error "编译失败"
fi
这部分处理代码编译:
- 首先检查当前目录下是否存在
pom.xml文件(Maven项目的标识) - 如果存在,则执行
mvn clean package -DskipTests命令进行编译打包 -DskipTests参数表示跳过测试,这在生产环境部署中很常见- 如果编译失败,调用
handle_error终止脚本
# 重启服务
systemctl restart myapp.service || handle_error "服务重启失败"
# 检查服务状态
sleep 5
if ! systemctl is-active --quiet myapp.service; then
handle_error "服务未正常启动"
fi
这部分处理服务重启和状态检查:
- 使用
systemctl restart命令重启服务,如果失败则终止脚本 - 等待5秒(给服务足够的启动时间)
- 使用
systemctl is-active命令检查服务是否处于活跃状态 - 如果服务没有成功启动,调用
handle_error终止脚本
log "部署成功!"
echo "部署完成"
如果所有步骤都成功执行,脚本会记录成功日志并打印完成信息。
关键技术点说明
-
错误处理机制:脚本使用
|| handle_error的方式处理命令执行失败的情况,这是Bash中常用的错误处理模式。例如:command || handle_error "命令执行失败"这种写法的意思是:如果
command执行失败(返回非零状态码),则执行handle_error函数。 -
日志记录:脚本通过自定义的
log()函数实现日志记录,这样可以确保所有日志都有统一的时间戳格式,并且方便后续查看和分析。 -
服务状态检查:在重启服务后等待5秒再检查状态,这是一个简单但有效的方法,可以避免因为服务启动较慢而误判。
-
Maven项目编译:通过检查
pom.xml文件来判断是否为Maven项目,这是一种常见的项目类型识别方法。
这个脚本设计得很专业,包含了部署过程中的关键步骤和必要的错误处理,能够有效减少人工干预,提高部署效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号