
集合
《Java Core》学习笔记。集合这部分记录一下背后的数据结构实现,API随用随查即可
Java集合框架(framework)
Java最开始的发行版本中,集合只有Vector, Stack, Hashtable, BitSet,并提供了Enumeration接口以供遍历集合(容器)中的内容
分离的集合接口和实现
Java中的集合设计是接口和实现分离的。以Queue接口为例(先进先出),它只包含了队列的一些常用操作的声明,具体实现是在各个实现类中(ArrayDeque和LinkedList)。通常只有在实际创建队列的时候才会用到实现类,而我们用接口类型来接收这个创建的对象
这里,接口不负责实现类的真实效率。其它以Abstract开头的类是为(库)集合的实现者准备的,如果我们想自己实现一个集合的数据结构,那么继承这些类要比直接去实现接口的所有方法更容易
Collection接口
// 接口中的两个基本方法
// 添加一个元素,添加成功返回true,失败返回false
boolean add(E element);
// 返回一个实现了Iterator接口的对象,通过这个对象来访问集合中的元素
Iterator<E> iterator();
Iterator
public interface Iterator<E>
{
// 调用next方法来访问下一个元素,在集合的结尾调用会抛出NoSuchElementException异常
E next();
// 如果还有元素则返回true
boolean hasNext();
// 删除上一次next()方法返回的元素,remove不能在next前调用,而且不能连续两次调用remove
void remove();
default void forEachRemaining(Consumer<? super E> action);
}
编译器就是将for-each循环转换为迭代器循环的模式,对于任意实现了Iterable接口的对象,都可以应用for-each循环。集合接口继承了这个接口
// 这个方法中的lambda表达式会应用在每个元素上,直到遍历完全部元素
iterator.forEachRemaining(element -> do something with element);
遍历的顺序和集合类型有关(ArrayList和HashMap)。迭代器的方法和Enumeration接口中的功能相同名字不同,设计者不喜欢那么长的名字所以设计了新接口
泛型工具方法
因为集合和迭代器都是泛型实现,所以可以写对应的工具方法
public static <E> boolean contains(Collection<E> c, Object obj)
{
for (E element : c)
if (element.equals(obj))
return true;
return false;
}
因为一些工具方法使用频率很高,所以库设计者在集合接口中声明了很多工具方法(实现类中具体实现)
// 这些方法基本就是见名知意(自解释)
int size()
boolean isEmpty()
boolean contains(Object obj)
boolean containsAll(Collection<?> c)
boolean equals(Object other)
boolean addAll(Collection<? extends E> from)
boolean remove(Object obj)
boolean removeAll(Collection<?> c)
void clear()
boolean retainAll(Collection<?> c)
Object[] toArray()
<T> T[] toArray(T[] arrayToFill)
AbstractCollection类中除了size iterator方法还是抽象类型,其它常规方法都有默认实现。现在这种实现方式稍显过时,应为可以在接口中写默认方法了
集合框架中的接口
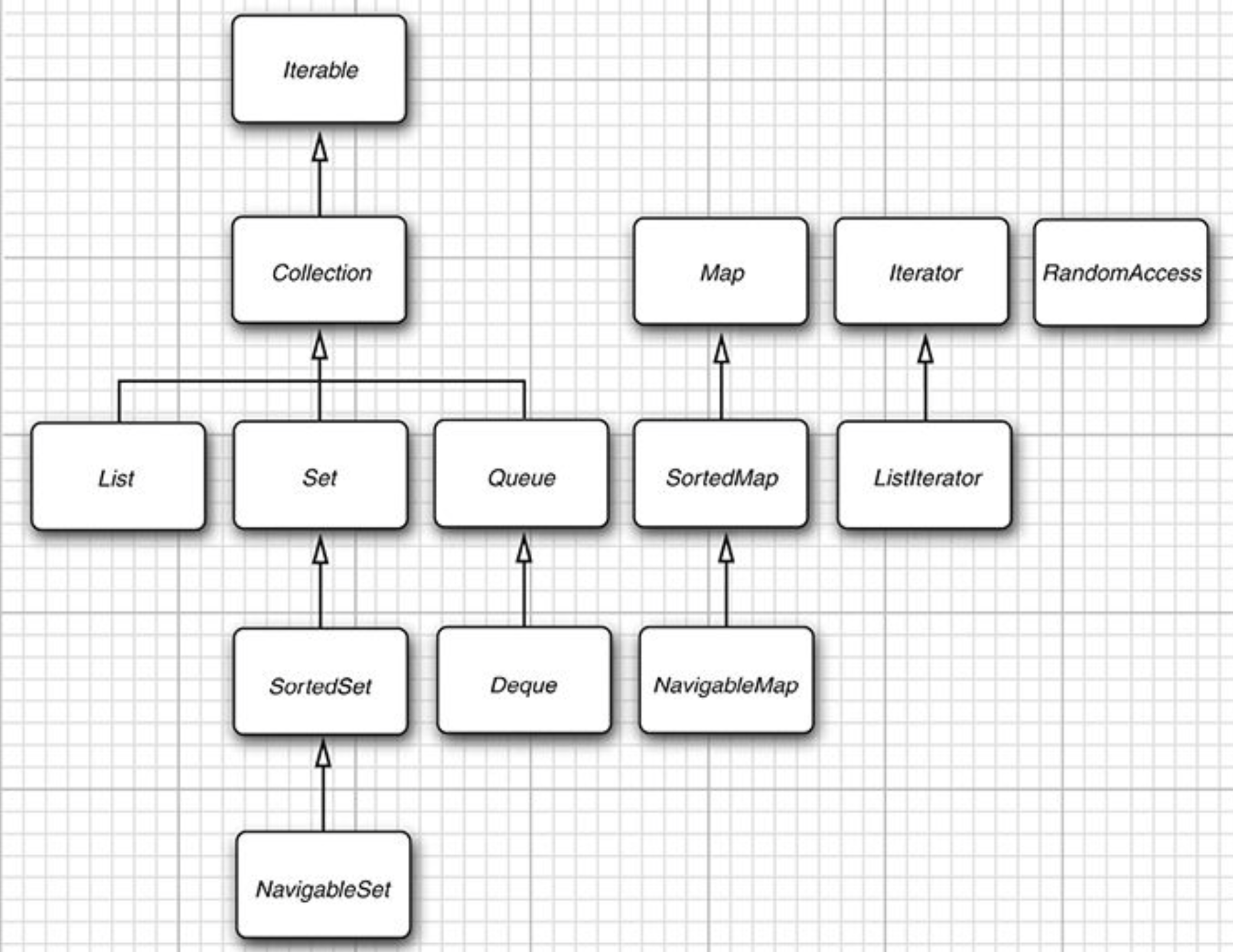
两个基本集合是Collection Map
Map(元素是键值对的形式)中的插入元素和读取元素
V put(K key, V value)
V get(K key)
List是有序集合,里面的元素有两种访问方式,即迭代器和下标索引。RandomAccess里面的元素可以用任何顺序访问,但是迭代器还是只能顺序访问
List提供的随机访问方法
void add(int index, E element)
void remove(int index)
E get(int index)
E set(int index, E element)
ListIterator接口是迭代器的子接口,它定义了一个add方法,在迭代位置前添加一个元素。在随机访问这部分,集合接口设计的并不好,因为List中数组实现的数据结构随机访问更快,而链表实现的数据结构随机访问很慢(应用迭代器访问),所以RandomAccess是一个标记接口,如果实现了这个接口,那么代表这个实现类有高效的随机访问方法
Set中的元素不能相同,比较两个Set相等的方法equals比较的是两个集合中的元素(不管顺序),如果所有元素相等,那么集合相等(使用hashCode)
为什么方法签名都一样也要独立设置一个Set接口?是为了让使用者设计专门接收Set类型的值的方法
SortedSet SortedMap接收Comparator对象用来排序,也有方法来获取子集合
Java6定义了NavigableSet NavigableMap,里面包含了在有序集合和Map中搜索、遍历的方法。TreeSet TreeMap类实现了这两个接口
具体的集合
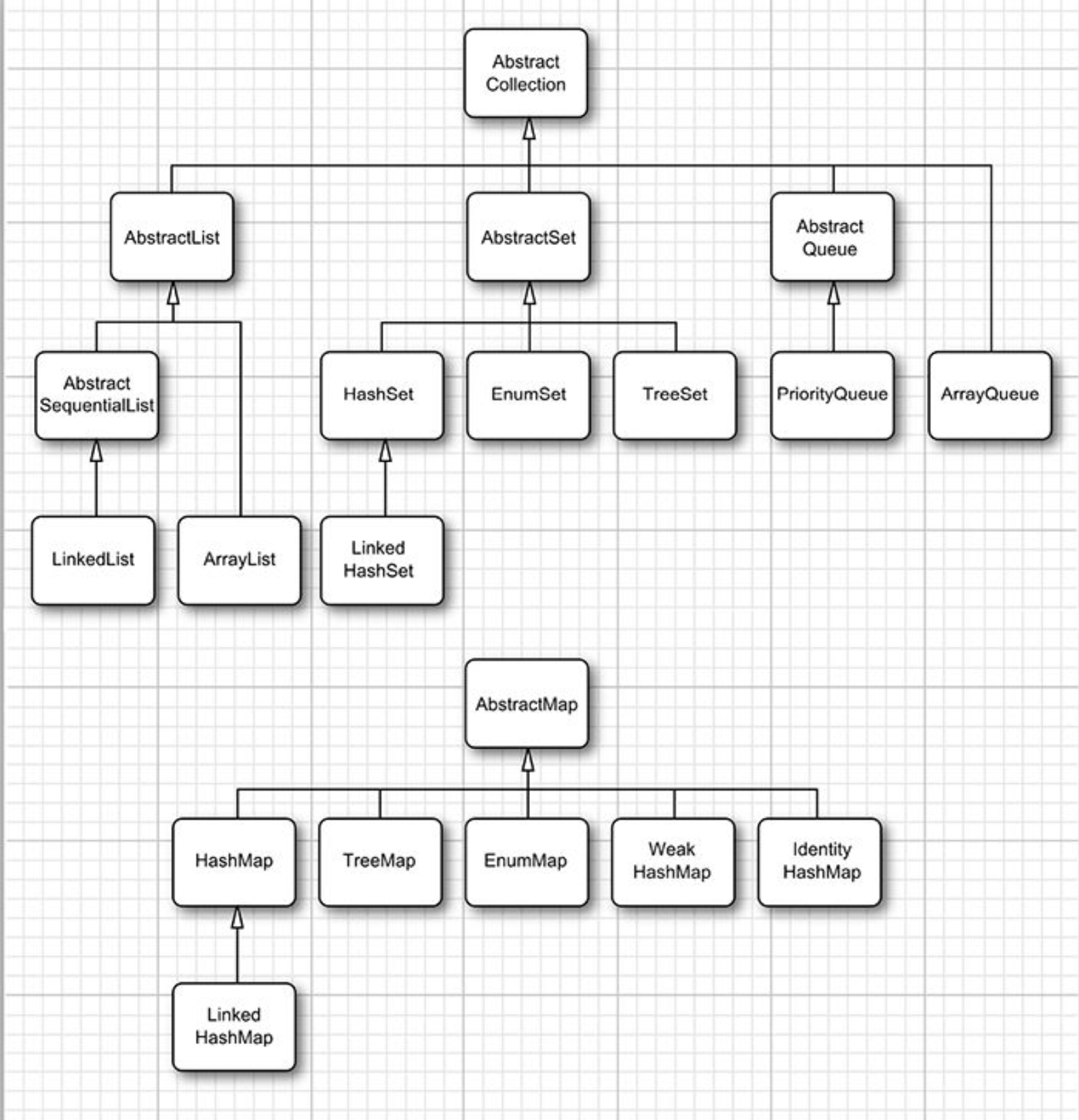
| 集合类型 | 描述 |
|---|---|
| ArrayList | (大小)动态伸缩的索引序列 |
| LinkedList | 任意位置高效插入和移除的有序序列 |
| ArrayDeque | 循环数组实现的双端队列 |
| HashSet | 不重复元素的无序集合 |
| TreeSet | 有序集合 |
| EnumSet | 枚举类型值的集合 |
| LinkedHashSet | 记得插入顺序的HashSet |
| PriorityQueue | 高效移除最小元素的集合 |
| HashMap | 存储键值对 |
| TreeMap | 键有序的Map |
| EnumMap | 键是枚举类型的Map |
| LinkedHashMap | 记得entry插入顺序的HashMap |
| WeakHashMap | 值可以被GC回收(如果没有使用)的HashMap |
| IdentityHashMap | 键使用==比较而不是equals |
LinkedList
在列表任意位置插入或删除元素对于数组和ArrayList来说效率都很低(元素要移动)。链表解决了这个问题,Java中的链表都是双向链表(保存前一个元素的引用)。在链表的任意位置插入元素应该使用迭代器(ListIterator中的add方法,其中还有previous方法,返回之前的一个元素。add方法只关心迭代器在集合中的位置,而remove方法关心迭代器的状态(不能删除)。set方法是将刚遍历的元素设置成新值)。当有两个迭代器在操作一个链表时,如果一个修改了链表那么在另一个迭代过程中会抛出异常。避免并发问题的办法(多个迭代器只做读操作,写操作只允许一个迭代器)
LinkedList中的get(int)方法最好别用(更不要在循环中使用)(一个小优化,如果给定参数大于1/2 size,那么从尾遍历),这是链表的数据结构决定的(每次都要从头找)
list.listIterator(n)方法可以直接放回从这个索引开始的迭代器,即next方法会返回这个索引值的元素
使用建议:没有任何根据数字索引来做的操作,高效的插入和删除
ArrayList
为什么用ArrayList而不用Vector(都是变长数组),因为后者是线程安全的(同步的),那么在单线程的情况下,同步操作会有性能浪费
HashSet
有高效查找的数据结构hash table,给每个对象计算一个hash码,查找操作就是hash码的比对
hashCode equals方法必须对应,即后者返回true,那么前者必须相等
Java中,hash table是用链表数组实现的,每个列表叫做桶(bucket),为了给一个对象在表中找到位置,过程就是使用hash码和数组长度取模,然后将其插到对应位置的链表上。如果运气好(桶中没有元素)则直接插入,否则(hash冲突)比较链表中其它元素
Java8中,链表的结构改为了平衡二叉树(如果hash算法很差导致hash冲突频繁时,会提高一些性能)
可以自己指定桶的大小,如果直到要插入的元素数量,那么选择这个数量的(75%-150%),一些研究表示素数会减少冲突(非结论性,Java实现是2的次方,即使给定值不是,也会补够)
hash表有load factor,即当hash表足够满时,会自动rehash(建立一个新的hash表,然后将旧元素重新hash之后插入新表,然后删除旧表)
HashSet就是根据hash表的原理设计的。它的迭代器是遍历桶的数组,因为hash无序,所以这个遍历也是无序的
TreeSet
和HashSet相似,但是它是有序集合。内部实现是红黑树(插入每个元素都会将其放入它的位置(字典顺序)),遍历也是有序遍历。TreeSet插入数据比HashMap慢,但是比要比较元素的链表和数组要(ArrayList)快。这个集合的元素必须实现Comparable接口,或者在构造器中传入一个Comparator对象
在Java6,TreeSet实现了NavigableSet接口,提供了向后遍历和定位元素的方法
Queue和Deque
deque就是双端队列,高效的对队头队尾元素进行插入和删除,在队列中间插入或删除元素是不允许的。Java6引入了Deque接口,ArrayDeque LinkedList实现了这个接口
优先级队列
优先级队列在元素被插入队列之后,会将其排序,所以取元素时也是有序的(每次调用remove方法,取出的都是最小的元素)。优先级队列使用堆(自适应(self-organizing)的二叉树,添加和删除操作使很少的元素进入根结点,在对元素排序时消耗不高)的数据结构实现。这个数据结构也是只能持有实现了Comparable接口的对象或者构造器中提供Comparator对象
典型的应用是工作(job)调度,每个工作都有一个优先级,插入方式是随机的,当一个工作开始,即优先级最高的工作被移除(传统来说1优先级最高,所以移除”最小“的)
Maps
Map就是用来根据key查找value的数据结构
基本的Map操作
HashMap TreeMap是两个实现了Map接口的通用Map类。前者是将key哈希之后存储,后者是使用key的排序来创建一个搜索树。如果不需要有序遍历key,那么还是使用HashMap更快
getOrDefault方法在key值找不到对应value时可以解决NPE问题。key必须是唯一的。forEach是遍历Map的最简单的方法,参数是lambda表达式
scores.forEach((k, v) ->
System.out.println("key=" + k + ", value=" + v));
更新Map中的Entry
插入(更新)Map中的值,一般来说就是put方法,但是如果事先key对应的value是null,则会有NPE,putIfAbsent方法调用,如果值不存在(null),那么插入一个默认值
API提供了一些merge的方法,比put的功能更多
// java8 其它的方法随用随看API吧
// 将旧值和新值做merge,merge的方法由第三个参数确定
default V merge(K key, V value, BiFunction<? super V,? super V,? extends V> remappingFunction)
default V compute(K key, BiFunction<? super K,? super V,? extends V> remappingFunction)
default V computeIfPresent(K key, BiFunction<? super K,? super V,? extends V> remappingFunction)
default V computeIfAbsent(K key, Function<? super K,? extends V> mappingFunction)
default void replaceAll(BiFunction<? super K,? super V,? extends V> function)
default V putIfAbsent(K key, V value)
Map Views
集合框架并没有把Map本身当作一个集合,但是可以获得Map的`views(它们实现了Collection接口或其子接口),即
Set<K> keySet()
Collection<V> values()
Set<Map.Entry<K, V>> entrySet()
如果在keySet中调用了remove方法,那么连同关联的value会一起删除,但是调用add方法会报错(插入一个没有value的key是没有意义的)
Weak Hash Maps
WeakHashMap的设计是为了解决一个问题:如果一个key值在程序中不再使用,那么其对应的键值对已经没有意义,即允许GC工作。但是GC会追踪的是live的对象,那么一旦map还是活着的,那么它所有的桶都是活着的且不会通知GC
WeakHashMap可以让GC知道只有Map对象一个引用的Entry,然后GC会回收它
工作原理:
Here are the inner workings of this mechanism. The WeakHashMap uses weak references to hold keys. A WeakReference object holds a reference to another object—in our case, a hash table key. Objects of this type are treated in a special way by the garbage collector. Normally, if the garbage collector finds that a particular object has no references to it, it simply reclaims the object. However, if the object is reachable only by a WeakReference, the garbage collector still reclaims the object, but places the weak reference that led to it into a queue. The operations of the WeakHashMap periodically check that queue for newly arrived weak references. The arrival of a weak reference in the queue signifies that the key was no longer used by anyone and has been collected. The WeakHashMap then removes the associated entry.
WeakHashMap使用weak reference来持有键。一个WeakReference对象中持有一个对象(键),这个类型的对象会被GC以一种特殊方式对待。一般来说,如果GC发现一个对象已经没有地方引用它了,那么它会回收这个对象。然而,如果一个对象只能被WeakReference对象引用,那么GC也会回收这个对象,但是将这个weak reference插入一个队列。WeakHashMap周期性地检查新来的weak references。这个weak references代表着它的key不再被任何地方引用并且已经被收集,然后WeakHashMap`会移除关联的entry
Linked Hash Sets and Maps
LinkedHashSet LinkedHashMap都会记录元素的插入顺序
LinkedHashMap<K, V>(initialCapacity, loadFactor, true)可以构造一个根据访问顺序而不是插入顺序来遍历的LinkedHashMap(每次调用get和put时,相关的entry会被移开当前位置然后放在linkedlist的最后面(桶的最后面))。访问顺序在实现(最少最近使用的原则)缓存是有用的
通过覆写protected boolean removeEldestEntry(Map.Entry<K, V> eldest)方法可以自定义移除的行为
Enumeration Sets and Maps
EnumSet内部实现就是位(bit)序列,如果对应的在set中出现,那么打开(turn on)位
// 用法
enum Weekday { MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY, SUNDAY };
EnumSet<Weekday> always = EnumSet.allOf(Weekday.class);
EnumSet<Weekday> never = EnumSet.noneOf(Weekday.class);
EnumSet<Weekday> workday = EnumSet.range(Weekday.MONDAY, Weekday.FRIDAY);
EnumSet<Weekday> mwf = EnumSet.of(Weekday.MONDAY, Weekday.WEDNESDAY, Weekday.FRIDAY);
var personInCharge = new EnumMap<Weekday, Employee>(Weekday.class);
Identity Hash Maps
IdentityHashMap的目的很特殊,它的key不是用hashCode计算出来的,而是System.identityHashCode计算出来的。这是Object.hashCode用来根据对象的内存地址算hash值的方法。此外,这个map比较对象使用==而不是equals方法。一般用来实现对象转换(traversal)算法,例如对象序列化(可以查看到底哪些对象被转换过)
Views and Wrappers
view也是一种集合,它实现了Collection Map接口,并且对原始的数据结构产生影响,例如keySet()返回的对象
小集合
// Java9提供了一些静态方法来通过指定元素构造一个set或list
List<String> names = List.of("Peter", "Paul", "Mary");
Set<Integer> numbers = Set.of(2, 3, 5);
// 构造map,这种方式key value都不能为null
Map<String, Integer> scores = Map.of("Peter", 2, "Paul", 3, "Mary", 5);
List和Set接口有11个of方法来获取list和set,函数参数是0~10个元素。Map接口不能提供这种方式(可变参数--key和value类型不一定相同),所以有ofEntries方法来接收Map.Entry<K, V>对象(使用静态方法entry(k, v)来创建)
这些方法产生的对象,对于每个元素都有一个成员变量持有,或者通过一个数组来保存。这些集合的对象是不可被修改的,如果想要一个可以修改的集合,可以将其传入其它的可变集合构造器中
// 返回一个实现了List接口的不可变对象,n个初始值为anObject的对象作为其内容
Collections.nCopies(n, anObject)
// 作为仅存储的对象,空间消耗很小
List<String> settings = Collections.nCopies(100, "DEFAULT");
Java9之前,可以通过new AbstractMap.SimpleImmutableEntry<>(first, second)来创建一个新的entry,现在调用Map.entry(first, second)即可(和上述代码里的entry相同)
Subranges
// 得到完整列表的子列表的view
// 索引是前闭后开
// 对子列表的所有操作都会反映在原列表上
List<Employee> group2 = staff.subList(10, 20);
// 如果是排序的列表或者集合,那么不能用索引,而是用比较顺序
// 取出的元素是大于给定参数小的,小于给定参数大的
SortedSet<E> subSet(E from, E to)
SortedSet<E> headSet(E to)
SortedSet<E> tailSet(E from)
// 如果是map,那么取出的元素是按key的范围
// NavigableSet接口定义的方法可以更细致地控制
NavigableSet<E> subSet(E from, boolean fromInclusive, E to, boolean
toInclusive)
NavigableSet<E> headSet(E to, boolean toInclusive)
NavigableSet<E> tailSet(E from, boolean fromInclusive)
不能修改的view
Collections类中有很多方法生成集合的unmodifiable views。这些view给存在的集合添加了运行时检查,如果集合的修改操作被检测到,会有异常产生,且集合不会被改变
// 每个方法都是定义在接口之上
Collections.unmodifiableCollection
Collections.unmodifiableList
Collections.unmodifiableSet
Collections.unmodifiableSortedSet
Collections.unmodifiableNavigableSet
Collections.unmodifiableMap
Collections.unmodifiableSortedMap
Collections.unmodifiableNavigableMap
Collections.unmodifiableList返回一个实现了List接口的对象,它的访问方法从原始集合获取数据,修改方法都被改写成抛出异常
不可修改的view不能让集合本身不可变
view包了一个接口(其类型是各个集合的内部类,实现了接口)。所以只能调用List的接口,而不能调用原始集合的全部方法(例如ArrayList和它的subList)
同步view
如果多线程访问集合,那么要保证集合不会被破坏
// 将map转换为一个同步的Map
// 保证get和set方法都是线程安全的
var map = Collections.synchronizedMap(new HashMap<String, Employee>());
Checked Views
检查性view可以debug由于泛型带来的引入错误类型数据进集合的问题
var strings = new ArrayList<String>();
// warning only, not an error,
// for compatibility with legacy code
ArrayList rawList = strings;
rawList.add(new Date()); // now strings contains a Date object!
List<String> safeStrings = Collections.checkedList(strings, String.class);
// view的add方法会检查插入的对象类型是否为给定类型
// 嵌套检查做不到 ArrayList<Pair<String>>,Pair的泛型没办法检查
A Note on Optional Operations
view的一些限制
- 只读
- 固定大小
- 支持移除但不支持插入
集合和迭代器接口中很多方法被描述为”optional operations“(针对view),理论上接口里声明的方法应该是必须实现的,更好的方法是单开接口给只读的view,但是会是现在接口数量的三倍。实际上各种view作为内部类并没有直接实现接口,而是继承了抽象集合类,所以并没有实现接口的所有方法
算法
为什么算法也是泛型实现的
一个方法,适应所有类型的集合
public static <T extends Comparable> T max(Collection<T> c)
{
if (c.isEmpty()) throw new NoSuchElementException();
Iterator<T> iter = c.iterator();
T largest = iter.next();
while (iter.hasNext())
{
T next = iter.next();
if (largest.compareTo(next) < 0)
largest = next;
}
return largest;
}
Java集合类的一般算法(排序,折半查找,其它工具方法)
排序和打乱
// 假设列表中的元素实现了Comparable接口
var staff = new LinkedList<String>();
fill collection
Collections.sort(staff);
// 根据自己提供的方法来排序
staff.sort(Comparator.comparingDouble(Employee::getSalary));
// 倒序
staff.sort(Comparator.reverseOrder())
staff.sort(Comparator.comparingDouble(Employee::getSalary).reversed()
Java实现的排序是把所有元素放在数组里(针对链表实现的集合),然后排序,然后再重新复制进集合
这里使用的排序算法比快排慢一点,但是它非常稳定(不会变动相等的元素)(雇员先按姓名排序,再按薪水排序,那么第二次排序时,第一次的顺序是被保留下来的)
一个list是可修改的,如果它支持set方法
一个list是可改变大小的,如果它支持add或remove
// 打乱顺序
ArrayList<Card> cards = . . .;
Collections.shuffle(cards);
// 如果提供的集合没有实现RandomAccess接口,那么会在数组中操作再复制进集合
Binary Search
这个方法要保证集合是排序过的
// 一个非负数(索引)被返回,如果是负数,那么没有匹配的元素
i = Collections.binarySearch(c, element);
i = Collections.binarySearch(c, element, comparator);
// 如果是负数,这个数可以用来得到一个位置,在这个位置插入元素不会影响现有的排序
insertionPoint = -i - 1;
折半查找最好应用于可以随机访问的集合,如果是链表实现的集合,还是线性查找
简单的算法
// select * from mohaoyi where age is null order by age,mima;
static <T extends Comparable<? super T>> T min(Collection<T> elements)
static <T extends Comparable<? super T>> T max(Collection<T> elements)
static <T> min(Collection<T> elements, Comparator<? super T> c)
static <T> max(Collection<T> elements, Comparator<? super T> c)
// copies all elements from a source list to the same positions in the target list.
// The target list must be at least as long as the source list.
static <T> void copy(List<? super T> to, List<T> from)
// sets all positions of a list to the same value.
static <T> void fill(List<? super T> l, T value)
// adds all values to the given collection and returns true if the collection changed as a result.
static <T> boolean addAll(Collection<? super T> c, T... values) 5
// replaces all elements equal to oldValue with newValue.
static <T> boolean replaceAll(List<T> l, oldValue, T newValue) 1.4
// returns the index of the first or last sublist of l equaling s, or -1 if no sublist of l equals s. For example, if l is [s, t, a, r] and s is [t, a, r], then both methods return the index 1.
static int indexOfSubList(List<?> l, List<?> s) 1.4
static int lastIndexOfSubList(List<?> l, List<?> s) 1.4
// swaps the elements at the given offsets.
static void swap(List<?> l, int i, int j) 1.4
// reverses the order of the elements in a list. For example, reversing the list[t, a, r] yields the list [r, a, t]. This method runs in O(n) time, where n is the length of the list.
static void reverse(List<?> l)
// rotates the elements in the list, moving the entry with index i to position(i + d) % l.size(). For example, rotating the list [t, a, r] by
2 yields the list [a, r, t]. This method runs in O(n) time, where n is
the length of the list.
static void rotate(List<?> l, int d) 1.4
// returns the count of elements in c that equal the object o.
static int frequency(Collection<?> c, Object o) 5
// returns true if the collections have no elements in common.
boolean disjoint(Collection<?> c1, Collection<?> c2) 5
// removes all matching elements.
default boolean removeIf(Predicate<? super E> filter) 8
// applies the operation to all elements of this list.
default void replaceAll(UnaryOperator<E> op) 8
批量操作
removeAll() retainAll() addAll()
这些操作可以应用在view上
在集合和数组之间做转换
String[] values = . . .;
var staff = new HashSet<>(List.of(values));
// 返回是Object[],不能直接转换为想要的数组类型
Object[] values = staff.toArray();
// 改动
String[] values = staff.toArray(new String[0])
staff.toArray(new String[staff.size()])
写自己的算法
如果要写自己的算法(方法),需要使用接口来实现方法,而不是具体的实现类
// 不建议
public void processItems(ArrayList<Item> items)
{
for (Item item : items)
do something with item
}
是否大部分集合接口都可以做这件事?顺序是否关键?如果都满足,那么可以使用List。但是如果顺序并不关键,那么
public void processItems(Collection<Item> items)
{
for (Item item : items)
do something with item
}
某些情况下,接收Iterable<Item>对象可能是更好的选择。Collection继承了这个接口
历史的集合
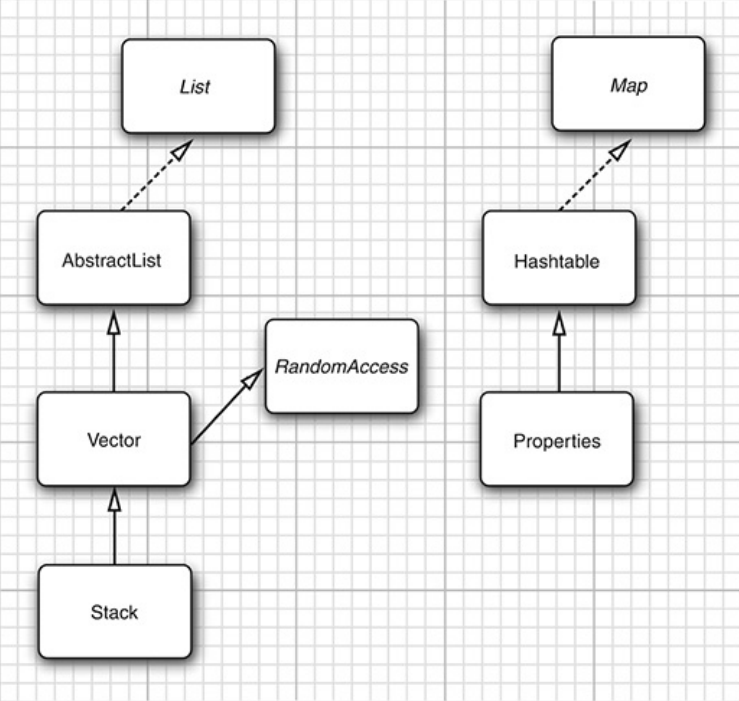
在集合框架存在之前的容器类。它们已经被合并到了集合框架中
Hashtable
和HashMap的设计目的相同,实现相同的接口,并且它也是线程安全的。如果不处理遗留代码,那么使用HashMap,并发要求使用ConcurrentHashMap
Enumerations
这个接口是用来遍历元素序列的,包含以下方法,和hasNext next相同
hasMoreElements
nextElement
如果遗留代码使用了这个接口,可以使用Collections.list来收集元素
// 例如LogManager(将logger的名字收集到了Enumeration)
LogManager.getLoggerNames().asIterator().forEachRemaining(n -> { . . . });
对于enumeration的参数,Collections.enumeration会产生一个enumeration对象
List<InputStream> streams = . . .;
// the SequenceInputStream constructor expects an enumeration
var in = new SequenceInputStream(Collections.enumeration(streams));

 浙公网安备 33010602011771号
浙公网安备 33010602011771号